Neil Fraser: Writing: Differential Synchronization
Differential synchronization is a symmetrical algorithm employing an unending cycle of background difference (diff) and patch operations. There is no requirement that "the chickens stop moving so we can count them" which plagues server-side three-way merges.
Dual Shadow Method
Guaranteed Delivery Method
 Adaptive Timing
Adaptive Timing
Differential synchronization is a symmetrical algorithm employing an unending cycle of background difference (diff) and patch operations. There is no requirement that "the chickens stop moving so we can count them" which plagues server-side three-way merges.
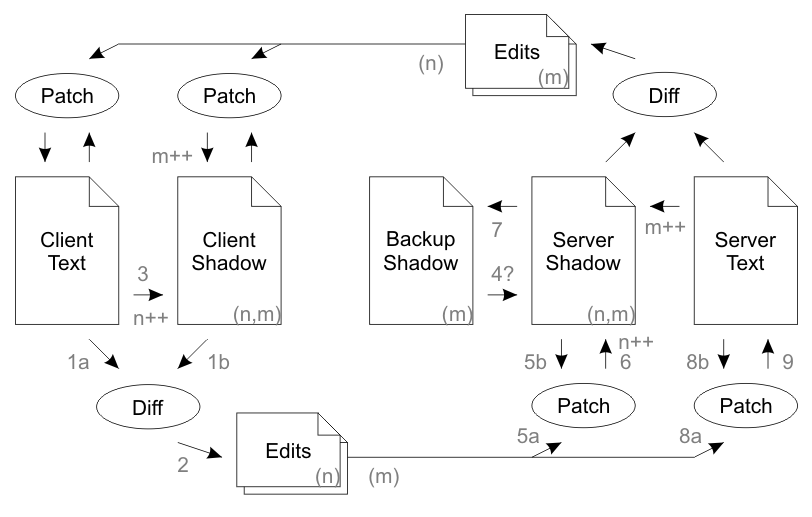
Dual Shadow Method
One such algorithm for plain-text is described in Diff Strategies, along with a set of optimizations to make diff significantly faster.
The patch operation is just as critical to the operation of the system. This system requires that patches be applied in and around text which may not exactly match the expected text. Furthermore, patches must be applied 'delicately', taking care not to overwrite changes which do not need to be overwritten. One such algorithm for plain-text is described in Fuzzy Patch, along with a set of optimizations to make patch significantly faster.
In a nutshell: Normal operation works identically to the Dual System Method described above. However in the case of packet loss, the edits are queued up in a stack and are retransmitted to the remote party on every sync until the remote party returns an acknowledgment of receipt. The server keeps two copies of the shadow, "Server Shadow" is the most up to date copy, and "Backup Shadow" is the previous version for use in the event that the previous transmission was not received.
Normal operation: Client Text is changed by the user. A Diff is computed between Client Text and Client Shadow to obtain a set of edits which were made by the user. These edits are tagged with a client version number ('n') relating to the version of Client Shadow they were created from. Client Shadow is updated to reflect the current value of Client Text, and the client version number is incremented. The edits are sent to the server along with the client's acknowledgment of the current server version number ('m') from the previous connection. The server's Server Shadow should match both the provided client version number and the provided server version number. The server patches the edits onto Server Shadow, increments the client version number of Server Shadow and takes a backup of Server Shadow into Backup Shadow. Finally the server then patches the edits onto Server Text. The process then repeats symmetrically from the server to the client, with the exception that the client doesn't take a backup shadow. During the return communication the server will inform the client that it received the edits for version 'n', whereupon the client will delete edits 'n' from the stack of edits to send.
Duplicate packet: The client appears to send Edits 'n' to the server twice. The first communication is processed normally and the response sent. Server Shadow's 'n' is incremented. The second communication contains an 'n' smaller than the 'n' recorded on Server Shadow. The server has no interest in edits it has already processed, so does nothing and sends back a normal response.
Lost outbound packet: The client sends Edits 'n' to the server. The server never receives it. The server never acknowledges receipt of the edit. The client leaves the edits in the outbound stack. After the connection times out, the client takes another diff, updates the 'n' again, and sends both sets of edits to the server. The stack of edits transmitted keeps increasing until the server eventually responds with acknowledgment that it got a certain version.
Lost return packet: The client sends Edits 'n' to the server. The server receives it, but the response is lost. The client leaves the edits in the outbound stack. After the connection times out, the client takes another diff, updates the 'n' again, and sends both sets of edits to the server. The server observes that the server version number 'm' which the client is sending does not match the server version number on Server Shadow. But both server and client version numbers do match the Backup Shadow. This indicates that the previous response must have been lost. Therefore the server deletes its edit stack and copies the Backup Shadow into Shadow Text (step 4). The server throws away the first edit because it already processed (same as a duplicate packet). The normal workflow is restored: the server applies the second edit, then computes and transmits a fresh diff to the client.
Out of order packet: The server appears to lose a packet, and one (or both) of the lost packet scenarios is played out. Then the lost packet arrives, and the duplicate packet scenario is played out.
Data corruption in memory or network: There are too many potential failure points to list, however if the shadow checksums become out of sync, or one side's version number skips into the future, the system will reinitialize itself. This will result in data loss for one side, but it will never result in an infinite loop of polling.
An adaptive system can continuously modify the network synchronization frequency for each client based on current activity. Hard-coded upper and lower limits would be defined to keep the cycle within a reasonable range (e.g. 1 second and 10 seconds respectively). User activity and remote activity would both decrease the time between updates (e.g. halving the period). Sending and receiving an empty update would increase the time between updates (e.g. increasing the period by one second). This adaptive timing automatically tunes the update frequency so that each client gradually backs off when activity is low, and quickly reengages when activity is high.
Try the demonstration of MobWrite, a web-based multi-user editor which uses this differential synchronization.
One limitation of differential synchronization as described here is that only one synchronization packet may be in flight at any given time. This would be a problem if there was very significant latency in the connection
Read full article from Neil Fraser: Writing: Differential Synchronization