Chord (peer-to-peer) - Wikipedia, the free encyclopedia
Chord specifies how keys are assigned to nodes, and how a node can discover the value for a given key by first locating the node responsible for that key.
Chord is one of the four original distributed hash table protocols, along with CAN, Tapestry, and Pastry.

http://blog.csdn.net/sparkliang/article/details/5679926
P2P(peer-to-peer)系统面临的一个根本问题就是如何有效的定位到存储特定数据项的节点。
实际上Chord协议仅支持一种操作:把一个给定的key映射到一个节点(node)上.
Chord使用了一致性hash算法[11](consistent hashing)的变体把Chord网络中的节点关联到特定而唯一的key上。一致性hash算法可以解决负载平衡(load balance)问题,因为它能保证系统中的每个节点都能接收到数量相当的key,并且当节点加入、离开系统时,减少数据的迁移。
实际上一致性hash算法可以保证:当节点离开时,仅需要迁移离开节点上的数据;当节点加入时,仅将加入节点的后继节点的部分数据迁移到新节点上;而不涉及到其它的节点和数据.
在Chord系统中,节点仅需要路由信息(routing information),关注少数其它节点。因为路由表是分布式的,一个节点执行查询时,需要和少数的其它节点通讯,稳定状态下,在一个有N个节点的系统中,每个节点仅需要维护O(logN)的节点信息,并且执行查询时仅需要和其它节点交互O(logN)的信息。当有节点加入、离开系统时,为了维护路由信息,Chord保证系统中节点之间的交互消息不会超过O(logN*logN)个。
Chord具有区别于其它P2P查找协议的3个特征:简单、正确性已经被证明和性能已经被证明。Chord简单有效,将key传递到目的节点仅需要路由O(logN)个节点。为了实现有效的路由,每个节点仅需要维护系统中O(logN)个节点的信息,并且在路由信息过期时,性能会优雅降级。这在实际中是很重要的,因为节点会随意的加入、离开系统,很难维持在O(logN) 的事件状态一致性。Chord协议中,每个节点仅有部分数据正确就能保证查询路由的正确性(尽管会变慢)。Chord具有简单的算法,能在动态的环境中维护路由信息。
Chord将key映射到节点上,而传统的名字和定位协议提供从key到value的直接映射。
负载均衡(Load balance) :Chord像一个分布式hash函数,最终将key散布在所有的节点上,这就在一定程度上提供了的天然的负载均衡能力。
去中心化(Decentralization) :Chord是完全分布式的,没有哪个节点是更重要的,这增强了健壮性,并使得Chord适合于松散组织的P2P应用。
可扩展性(Scalability) :Chord查询的复杂度随着节点数目N的log级别而增加(注:即O(logN)),因此适合应用在大规模系统中,并且不需要调整参数来达到这种可扩展性。
可用性(Availability) :Chord会自动调整内部表来反映新近加入节点和节点失效的情况,确保除了底层网络的严重失效外,负责key的节点总是可以查询到。这甚至在系统处于一个持续改变的状态时也是正确的。
灵活的命名规则(Flexible naming) :Chord对于要查找的key的结构没有施加任何的限制:Chord的key空间是扁平的(flat)。这就给应用程序与极大的灵活性来决定如何将他们自己的名字映射到Chord的key空间中。
4 基础Chord协议
https://github.com/sit/dht/wiki
Read full article from Chord (peer-to-peer) - Wikipedia, the free encyclopedia
Chord specifies how keys are assigned to nodes, and how a node can discover the value for a given key by first locating the node responsible for that key.
Chord is one of the four original distributed hash table protocols, along with CAN, Tapestry, and Pastry.
Using the Chord lookup protocol, nodes and keys are arranged in an identifier circle that has at most 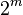 nodes, ranging from
nodes, ranging from  to
to  . (
. ( should be large enough to avoid collision.)
should be large enough to avoid collision.)
nodes, ranging from to . (should be large enough to avoid collision.)
Each node has a successor and a predecessor. The successor to a node is the next node in the identifier circle in a clockwise direction. The predecessor is counter-clockwise. If there is a node for each possible ID, the successor of node 0 is node 1, and the predecessor of node 0 is node ; however, normally there are "holes" in the sequence. For example, the successor of node 153 may be node 167 (and nodes from 154 to 166 do not exist); in this case, the predecessor of node 167 will be node 153.
; however, normally there are "holes" in the sequence. For example, the successor of node 153 may be node 167 (and nodes from 154 to 166 do not exist); in this case, the predecessor of node 167 will be node 153.
Since the successor (or predecessor) of a node may disappear from the network (because of failure or departure), each node records a whole segment of the circle adjacent to it, i.e., the  nodes preceding it and the nodes following it. This list results in a high probability that a node is able to correctly locate its successor or predecessor, even if the network in question suffers from a high failure rate.
nodes preceding it and the nodes following it. This list results in a high probability that a node is able to correctly locate its successor or predecessor, even if the network in question suffers from a high failure rate.
nodes preceding it and the nodes following it. This list results in a high probability that a node is able to correctly locate its successor or predecessor, even if the network in question suffers from a high failure rate.Basic query
The core usage of the Chord protocol is to query a key from a client (generally a node as well), i.e. to find  . The basic approach is to pass the query to a node's successor, if it cannot find the key locally. This will lead to a
. The basic approach is to pass the query to a node's successor, if it cannot find the key locally. This will lead to a 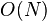 query time.
query time.
. The basic approach is to pass the query to a node's successor, if it cannot find the key locally. This will lead to a query time.Finger table
To avoid the linear search above, Chord implements a faster search method by requiring each node to keep a finger table containing up to entries. The  entry of node
entry of node  will contain
will contain  . The first entry of finger table is actually the node's immediate successor (and therefore an extra successor field is not needed). Every time a node wants to look up a key
. The first entry of finger table is actually the node's immediate successor (and therefore an extra successor field is not needed). Every time a node wants to look up a key  , it will pass the query to the closest successor of in its finger table (the "largest" one on the circle whose ID is smaller than ), until a node finds out the key is stored in its immediate successor.
, it will pass the query to the closest successor of in its finger table (the "largest" one on the circle whose ID is smaller than ), until a node finds out the key is stored in its immediate successor.
entries. The entry of node will contain . The first entry of finger table is actually the node's immediate successor (and therefore an extra successor field is not needed). Every time a node wants to look up a key , it will pass the query to the closest successor of in its finger table (the "largest" one on the circle whose ID is smaller than ), until a node finds out the key is stored in its immediate successor.
With such a finger table, the number of nodes that must be contacted to find a successor in an N-node network is 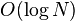 .
.
.P2P(peer-to-peer)系统面临的一个根本问题就是如何有效的定位到存储特定数据项的节点。
实际上Chord协议仅支持一种操作:把一个给定的key映射到一个节点(node)上.
Chord使用了一致性hash算法[11](consistent hashing)的变体把Chord网络中的节点关联到特定而唯一的key上。一致性hash算法可以解决负载平衡(load balance)问题,因为它能保证系统中的每个节点都能接收到数量相当的key,并且当节点加入、离开系统时,减少数据的迁移。
实际上一致性hash算法可以保证:当节点离开时,仅需要迁移离开节点上的数据;当节点加入时,仅将加入节点的后继节点的部分数据迁移到新节点上;而不涉及到其它的节点和数据.
在Chord系统中,节点仅需要路由信息(routing information),关注少数其它节点。因为路由表是分布式的,一个节点执行查询时,需要和少数的其它节点通讯,稳定状态下,在一个有N个节点的系统中,每个节点仅需要维护O(logN)的节点信息,并且执行查询时仅需要和其它节点交互O(logN)的信息。当有节点加入、离开系统时,为了维护路由信息,Chord保证系统中节点之间的交互消息不会超过O(logN*logN)个。
Chord具有区别于其它P2P查找协议的3个特征:简单、正确性已经被证明和性能已经被证明。Chord简单有效,将key传递到目的节点仅需要路由O(logN)个节点。为了实现有效的路由,每个节点仅需要维护系统中O(logN)个节点的信息,并且在路由信息过期时,性能会优雅降级。这在实际中是很重要的,因为节点会随意的加入、离开系统,很难维持在O(logN) 的事件状态一致性。Chord协议中,每个节点仅有部分数据正确就能保证查询路由的正确性(尽管会变慢)。Chord具有简单的算法,能在动态的环境中维护路由信息。
Chord将key映射到节点上,而传统的名字和定位协议提供从key到value的直接映射。
负载均衡(Load balance) :Chord像一个分布式hash函数,最终将key散布在所有的节点上,这就在一定程度上提供了的天然的负载均衡能力。
去中心化(Decentralization) :Chord是完全分布式的,没有哪个节点是更重要的,这增强了健壮性,并使得Chord适合于松散组织的P2P应用。
可扩展性(Scalability) :Chord查询的复杂度随着节点数目N的log级别而增加(注:即O(logN)),因此适合应用在大规模系统中,并且不需要调整参数来达到这种可扩展性。
可用性(Availability) :Chord会自动调整内部表来反映新近加入节点和节点失效的情况,确保除了底层网络的严重失效外,负责key的节点总是可以查询到。这甚至在系统处于一个持续改变的状态时也是正确的。
灵活的命名规则(Flexible naming) :Chord对于要查找的key的结构没有施加任何的限制:Chord的key空间是扁平的(flat)。这就给应用程序与极大的灵活性来决定如何将他们自己的名字映射到Chord的key空间中。
4 基础Chord协议
https://github.com/sit/dht/wiki
Read full article from Chord (peer-to-peer) - Wikipedia, the free encyclopedia