https://alibaba.github.io/Alibaba-Java-Coding-Guidelines/#logs
https://www.hollischuang.com/archives/3000
 


use
or <configuration debug="true">
log4j.debug
Automatically reloading configuration file upon modification
How to Instantly Improve Your Java Logging With 7 Logback Tweaks
#1: AsyncAppender can be 3.7x faster than the synchronous FileAppender. Actually, it’s the fastest way to log across all appenders.
Tweak #2: The default AsyncAppender can cause a 5 fold performance cut and even lose messages. Make sure to customize the queue size and discardingThreshold according to your needs.
Tweak #3: Naming the logger by class name provides 3x performance boost.
Tweak #4: Compared to the default pattern, using only the Level and Message fields provided 127k more entries per minute.
Tweak #5: Use prudent mode only when you absolutely need it to avoid a throughput decrease.
Tweak #6: Piping ConsoleAppender to a file provided 13% higher throughput than using FileAppender.
Tweak #7: Using a SiftingAppender can allow a 3.1x improvement in throughput.
http://javarevisited.blogspot.com/2011/05/top-10-tips-on-logging-in-java.html
10 tips on logging in Java
1) Use isDebugEnabled() for putting debug log in Java , it will save lot of string concatenation activity if your code run in production environment with production logging level instead of DEBUG logging level.
// May affect performance
Properties file in case of java.util.logging API for logging to use which java logging Formatter. Don’t forget to include Thread Name and fully qualified java class Name while printing logs because it would be impossible to find sequence of events if your code is executed by multiple threads without having thread name on it. In my opinion this is the most important tips you consider for logging in Java.
11) if you are using SLFJ for logging in java use parametrized version of various log methods they are faster as compared to normal method.
logger.debug("No of Orders " + noOfOrder + " for client : " + client); // slower
logger.debug("No of Executions {} for clients:{}", noOfOrder , client); // faster
1) Which information should you log?
2) Which information goes to which level of logging?
1) Never log sensitive information
3) Consistency
https://stackoverflow.com/questions/29523507/will-disabling-logback-console-appender-increase-performance-if-i-log-to-file-an/29524427#29524427
http://www.programering.com/a/MTM2EzMwATA.html
https://github.com/qos-ch/logback/pull/185
slf4j-logback-Appender进阶
Logback MDC issue
http://stackoverflow.com/questions/6073019/how-to-use-mdc-with-thread-pools
Custom Filters
http://bitingcode.blogspot.com/2012/01/logback-filters.html
http://sw1982.iteye.com/blog/468698
http://dbaplus.cn/news-21-633-1.html
1. [Mandatory] Do not use API in log system (Log4j, Logback) directly. API in log framework SLF4J is recommended to use instead, which uses Facade pattern and is conducive to keep log processing consistent.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger logger = LoggerFactory.getLogger(Abc.class);
2. [Mandatory] Log files need to be kept for at least 15 days because some kinds of exceptions happen weekly.
3. [Mandatory] Naming conventions of extended logs of an Application (such as RBI, temporary monitoring, access log, etc.):
appName_logType_logName.log
logType: Recommended classifications are stats, desc, monitor, visit, etc.
logName: Log description.
Benefits of this scheme: The file name shows what application the log belongs to, type of the log and what purpose is the log used for. It is also conducive for classification and search.
appName_logType_logName.log
logType: Recommended classifications are stats, desc, monitor, visit, etc.
logName: Log description.
Benefits of this scheme: The file name shows what application the log belongs to, type of the log and what purpose is the log used for. It is also conducive for classification and search.
Positive example:Name of the log file for monitoring the timezone conversion exception in mppserverapplication: mppserver_monitor_timeZoneConvert.logNote:It is recommended to classify logs. Error logs and business logs should be stored separately as far as possible. It is not only easy for developers to view, but also convenient for system monitoring.
4. [Mandatory] Logs at TRACE / DEBUG / INFO levels must use either conditional outputs or placeholders.
8. [Recommended] Level Warn should be used to record invalid parameters, which is used to track data when problem occurs. Level Error only records the system logic error, abnormal and other important error messages.
https://www.hollischuang.com/archives/3000
LogBack也是一个很成熟的日志框架,其实LogBack和Log4j出自一个人之手,这个人就是Ceki Gülcü。
logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是Log4j的一个改良版本。此外logback-classic完整实现SLF4J API使你可以很方便地更换成其它日记系统如Log4j或j.u.l。logback-access访问模块与Servlet容器集成提供通过Http来访问日记的功能。
Log4j2
前面介绍过Log4j,这里要单独介绍一下Log4j2,之所以要单独拿出来说,而没有和Log4j放在一起介绍,是因为作者认为,Log4j2已经不仅仅是Log4j的一个升级版本了,而是从头到尾被重写的,这可以认为这其实就是完全不同的两个框架。
不知道有多少人看过《阿里巴巴Java开发手册》,其中有一条规范做了『强制』要求:

说好了以上四种常用的日志框架是给Java应用提供的方便进行记录日志的,那为什么又不让在应用中直接使用其API呢?这里面推崇使用的SLF4J是什么呢?所谓的门面模式又是什么东西呢?
什么是日志门面
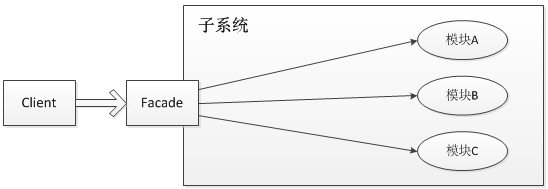
日志门面,是门面模式的一个典型的应用。
门面模式(Facade Pattern),也称之为外观模式,其核心为:外部与一个子系统的通信必须通过一个统一的外观对象进行,使得子系统更易于使用。

就像前面介绍的几种日志框架一样,每一种日志框架都有自己单独的API,要使用对应的框架就要使用其对应的API,这就大大的增加应用程序代码对于日志框架的耦合性。
为了解决这个问题,就是在日志框架和应用程序之间架设一个沟通的桥梁,对于应用程序来说,无论底层的日志框架如何变,都不需要有任何感知。只要门面服务做的足够好,随意换另外一个日志框架,应用程序不需要修改任意一行代码,就可以直接上线。
在软件开发领域有这样一句话:计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。而门面模式就是对于这句话的典型实践。
为什么需要日志门面
前面提到过一个重要的原因,就是为了在应用中屏蔽掉底层日志框架的具体实现。这样的话,即使有一天要更换代码的日志框架,只需要修改jar包,最多再改改日志输出相关的配置文件就可以了。这就是解除了应用和日志框架之间的耦合。
Use rotation policies
Debug Logging Tooluse
-Dlogback.debug=true to enable debugging of the logback setup.or <configuration debug="true">
log4j.debug
Automatically reloading configuration file upon modification
<configuration scan="true" scanPeriod="30 seconds" >
Given that
ReconfigureOnChangeFilter is invoked every time any logger is invoked, regardless of logger level, ReconfigureOnChangeFilteris absolutely performance critical. So much so that in fact, the check whether the scan period has elapsed or not, is too costly in itself. In order to improve performance, ReconfigureOnChangeFilter is in reality "alive" only once every N logging operations. Depending on how often your application logs, the value of N can be modified on the fly by logback. By default N is 16, although it can go as high as 2^16 (= 65536) for CPU-intensive applications.
In short, when a configuration file changes, it will be automatically reloaded but only after several logger invocations and after a delay determined by the scanning period.
How to Instantly Improve Your Java Logging With 7 Logback Tweaks
#1: AsyncAppender can be 3.7x faster than the synchronous FileAppender. Actually, it’s the fastest way to log across all appenders.
Tweak #2: The default AsyncAppender can cause a 5 fold performance cut and even lose messages. Make sure to customize the queue size and discardingThreshold according to your needs.
<appender name="ASYNC500" class="ch.qos.logback.classic.AsyncAppender"><queueSize>500</queueSize><discardingThreshold>0</discardingThreshold><appender-ref ref="FILE" /></appender>Tweak #4: Compared to the default pattern, using only the Level and Message fields provided 127k more entries per minute.
Tweak #5: Use prudent mode only when you absolutely need it to avoid a throughput decrease.
Tweak #6: Piping ConsoleAppender to a file provided 13% higher throughput than using FileAppender.
Tweak #7: Using a SiftingAppender can allow a 3.1x improvement in throughput.
http://javarevisited.blogspot.com/2011/05/top-10-tips-on-logging-in-java.html
10 tips on logging in Java
1) Use isDebugEnabled() for putting debug log in Java , it will save lot of string concatenation activity if your code run in production environment with production logging level instead of DEBUG logging level.
// May affect performance
Properties file in case of java.util.logging API for logging to use which java logging Formatter. Don’t forget to include Thread Name and fully qualified java class Name while printing logs because it would be impossible to find sequence of events if your code is executed by multiple threads without having thread name on it. In my opinion this is the most important tips you consider for logging in Java.
11) if you are using SLFJ for logging in java use parametrized version of various log methods they are faster as compared to normal method.
logger.debug("No of Orders " + noOfOrder + " for client : " + client); // slower
logger.debug("No of Executions {} for clients:{}", noOfOrder , client); // faster
1) Which information should you log?
2) Which information goes to which level of logging?
1) Never log sensitive information
3) Consistency
https://stackoverflow.com/questions/29523507/will-disabling-logback-console-appender-increase-performance-if-i-log-to-file-an/29524427#29524427
http://www.programering.com/a/MTM2EzMwATA.html
https://github.com/qos-ch/logback/pull/185
slf4j-logback-Appender进阶
Logback MDC issue
http://stackoverflow.com/questions/6073019/how-to-use-mdc-with-thread-pools
Custom Filters
http://bitingcode.blogspot.com/2012/01/logback-filters.html
public class MyFilter extends Filter<ILoggingEvent> { @Override public FilterReply decide(ILoggingEvent event) { if(event.getLevel() != Level.INFO) return FilterReply.DENY; if (event.getMessage().contains("hello")) return FilterReply.NEUTRAL; return FilterReply.DENY; }}TurboFilter objects are tied to the logging context. Hence, they are called not only when a given appender is used, but each and every time a logging request is issued. Their scope is wider than appender-attached filters.
1.TurboFilter会试图记录上下文环境。因此他们会在每次logging请求产生的时候调用,而不是一个指定的appender使用时才出现。
More importantly, they are called before the
LoggingEvent object creation. TurboFilter objects do not require the instantiation of a logging event to filter a logging request. As such, turbo filters are intended for high performance filtering of logging event, even before they are created
2.更重要的是,TurboFilter会在日志事件对象创建前调用。因此它具有更高性能的过滤日志事件,即使在事件被创建之前。
http://logback.qos.ch/manual/layouts.html#date
The second parameter specifies a timezone. For example, the '%date{HH:mm:ss.SSS, Australia/Perth} would print the time in the time zone of Perth, Australia, the world's most isolated city. Note that in the absence of the timezone parameter, the default timezone of the host Java platform is used. If the specified timezone identifier is unknown or misspelled, the GMT timezone is assumed as dictated by theTimeZone.getTimeZone(String) method specification.
http://dbaplus.cn/news-21-633-1.html
- 服务端提供日志记录接口,当客户端有事件时,直接调用日志记录接口将日志记录在服务器端。
- 服务端提供日志上传接口, 客户端先将日志暂存客户端本地,当达到一定的大小,网络环境允许的情况下, 通过上传接口,将日志文件打包压缩后上传。
第一种上传方式,时效性方面有一定的保障, 在网络环境允许的情况下,能及时的将信息记录到服务器,但是当埋点较多时,记录日志产生的流量会很大,占据很大的带宽,给用户带来损失。 同时, 前端的某些行为,如在某个activity停留时间等也无法通过这种在线的方式捕获。 还有一个重要的问题是, 由于客户端数据没有暂存机制, 当网络暂时无法使用时, 日志记录接口无法正常调用, 所有的日志也就随之丢失。 第二种方式,在时效性上较差,因为它需要等待数据累计到一定程度,或者网络允许的情况下,如在wifi情况下,才发送,但是占用的带宽相对较小, 对客户端动作的捕获较为灵活。
http://www.shuati123.com/blog/2016/08/01/how-to-design-logging/
Logs represent event, so all your logging should be based around the events.
eg. who click the button, the user ID, but do not log the age, because you can find it somewhere else!