https://www.somethingsimilar.com/2013/01/14/notes-on-distributed-systems-for-young-bloods/
there are failure conditions that are difficult to replicate on a single machine. Whether it’s because they only occur on dataset sizes much larger than can be fit on a shared machine, or in the network conditions found in datacenters, distributed systems tend to need actual, not simulated, distribution to flush out their bugs. Simulation is, of course, very useful.
Dapper and Zipkin were built for a reason.
Distributed systems are different because they fail often. When asked what separates distributed systems from other fields of software engineering, the new engineer often cites latency, believing that’s what makes distributed computation hard.
But they’re wrong. What sets distributed systems engineering apart is the probability of failure and, worse, the probability of partial failure. If a well-formed mutex unlock fails with an error, we can assume the process is unstable and crash it. But the failure of a distributed mutex’s unlock must be built into the lock protocol.
Systems engineers that haven’t worked in distributed computation will come up with ideas like “well, it’ll just send the write to both machines” or “it’ll just keep retrying the write until it succeeds”. These engineers haven’t completely accepted (though they usually intellectually recognize) that networked systems fail more than systems that exist on only a single machine and that failures tend to be partial instead of total. One of the writes may succeed while the other fails, and so now how do we get a consistent view of the data? These partial failures are much harder to reason about.
Switches go down, garbage collection pauses make leaders “disappear”, socket writes seem to succeed but have actually failed on the other machine, a slow disk drive on one machines causes a communication protocol in the whole cluster to crawl, and so on. Reading from local memory is simply more stable than reading across a few switches.
Design for failure.
there are failure conditions that are difficult to replicate on a single machine. Whether it’s because they only occur on dataset sizes much larger than can be fit on a shared machine, or in the network conditions found in datacenters, distributed systems tend to need actual, not simulated, distribution to flush out their bugs. Simulation is, of course, very useful.
Dapper and Zipkin were built for a reason.
Implement backpressure throughout your system. Backpressure is the signaling of failure from a serving system to the requesting system and how the requesting system handles those failures to prevent overloading itself and the serving system. Designing for backpressure means bounding resource utilization during times of overload and times of system failure. This is one of the basic building blocks of creating a robust distributed system.
Implementations of backpressure usually involve either the dropping of new messages on the floor, or the shipping of errors back to users (and incrementing a metric in both cases) when a resource becomes limited or failures occur. Timeouts and exponential back-offs on connections and requests to other systems are also essential.
Without backpressure mechanisms in place, cascading failure or unintentional message loss become likely. When a system is not able to handle the failures of another, it tends to emit failures to another system that depends on it.
# Find ways to be partially available. Partial availability is being able to return some results even when parts of your system is failing.
Search is an ideal case to explore here. Search systems trade-off between how good their results are and how long they will keep a user waiting. A typical search system sets a time limit on how long it will search its documents, and, if that time limit expires before all of its documents are searched, it will return whatever results it has gathered. This makes search easier to scale in the face of intermittent slowdowns, and errors because those failures are treated the same as not being able to search all of their documents. The system allows for partial results to be returned to the user and its resilience is increased.
And consider a private messaging feature in a web application. At some point, no matter what you do, enough storage machines for private messaging will be down at the same time that your users will notice. So what kind of partial failure do we want in this system?
This takes some thought. People are generally more okay with private messaging being down for them (and maybe some other users) than they are with all users having some of their messages go missing. If the service is overloaded or one of its machines are down, failing out just a small fraction of the userbase is preferable to missing data for a larger fraction. And, on top of that choice, we probably don’t want an unrelated feature, like public image upload, to be affected just because private messaging is having a problem. How much work are we willing to do to keep those failure domains separate?
Being able to recognize these kinds of trade-offs in partial availability is good to have in your toolbox.
# Metrics are the only way to get your job done. Exposing metrics (such as latency percentiles, increasing counters on certain actions, rates of change) is the only way to cross the gap from what you believe your system does in production and what it actually is doing. Knowing how the system’s behavior on day 20 is different from its behavior on day 15 is the difference between successful engineering and failed shamanism. Of course, metrics are necessary to understand problems and behavior, but they are not sufficient to know what to do next.
Use percentiles, not averages. Percentiles (50th, 99th, 99.9th, 99.99th) are more accurate and informative than averages in the vast majority of distributed systems.
Learn to estimate your capacity. You’ll learn how many seconds are in a day because of this. Knowing how many machines you need to perform a task is the difference between a long-lasting system, and one that needs to be replaced 3 months into its job. Or, worse, needs to be replaced before you finish productionizing it.
Consider tweets. How many tweet ids can you fit in memory on a common machine? Well, a typical machine at the end of 2012 has 24 GB of memory, you’ll need an overhead of 4-5 GB for the OS, another couple, at least, to handle requests, and a tweet id is 8 bytes. This is the kind of back of the envelope calculation you’ll find yourself doing. Jeff Dean’s Numbers Everyone Should Know slide is a good expectation-setter
Feature flags are how infrastructure is rolled out.
Suppose you’re going from a single database to a service that hides the details of a new storage solution. Using a feature flag, you can slowly ramp up writes to the new service in parallel to the writes to the old database to make sure its write path is correct and fast enough. After the write path is at 100% and backfilling into the service’s datastore is complete, you can use a separate feature flag to start reading from the service, without using the data in user responses, to check for performance problems. Another feature flag can be used to perform comparison checks on read of the data from the old system and the new one. And one final flag can be used to slowly ramp up the “real”.
By breaking up the deployment into multiple steps and affording yourself quick and partial reactions with feature flags, you make it easier to find bugs and performance problems as they occur during ramp up instead of at a “big bang” release time. If an issue occurs, you can just tamp the feature flag setting back down to a lower (perhaps, zero) setting immediately. Adjusting the rates lets you debug and experiment at different amounts of traffic knowing that any problem you hit isn’t a total disaster. With feature flags, you can also choose other migration strategies, like moving requests over on a per-user basis, that provide better insight into the new system. And when your new service is still being prototyped, you can use flags at a low setting to have your new system consume fewer resources.
Now, feature flags sound like a terrible mess of conditionals to a classically trained developer or a new engineer with well-intentioned training. And the use of feature flags means accepting that having multiple versions of infrastructure and data is a norm, not an rarity. This is a deep lesson. What works well for single-machine systems sometimes falters in the face of distributed problems.
Feature flags are best understood as a trade-off, trading local complexity (in the code, in one system) for global simplicity and resilience
Choose id spaces wisely. The space of ids you choose for your system will shape your system.
The more ids required to get to a piece of data, the more options you have in partitioning the data. The fewer ids required to get a piece of data, the easier it is to consume your system’s output.
Consider version 1 of the Twitter API. All operations to get, create, and delete tweets were done with respect to a single numeric id for each tweet. The tweet id is a simple 64-bit number that is not connected to any other piece of data. As the number of tweets goes up, it becomes clear that creating user tweet timelines and the timeline of other user’s subscriptions may be efficiently constructed if all of the tweets by the same user were stored on the same machine.
But the public API requires every tweet be addressable by just the tweet id. To partition tweets by user, a lookup service would have to be constructed. One that knows what user owns which tweet id. Doable, if necessary, but with a non-trivial cost.
An alternative API could have required the user id in any tweet look up and, initially, simply used the tweet id for storage until user-partitioned storage came online. Another alternative would have included the user id in the tweet id itself at the cost of tweet ids no longer being k-sortable and numeric.
Watch out for what kind of information you encode in your ids, explicitly and implicitly. Clients may use the structure of your ids to de-anonymize private data, crawl your system in ways you didn’t expect (auto-incrementing ids are a typical sore point), or a host of other things you won’t expect
# Exploit data-locality. The closer the processing and caching of your data is kept to its persistent storage, the more efficient your processing, and the easier it will be to keep your caching consistent and fast. Networks have more failures and more latency than pointer dereferences and
fread(3).
Of course, data-locality means being nearby in space, but it also means nearby in time. If multiple users are making the same expensive request at nearly the same time, perhaps their requests can be joined into one. If multiple instances of requests for the same kind of data are made near to one another, they could be joined into one larger request. Doing so often affords lower communication overheard and easier fault management. #
# Writing cached data back to persistent storage is bad. This happens in more systems than you’d think. Especially ones originally designed by people less experienced in distributed systems. Many systems you’ll inherit will have this flaw. If the implementers talk about “Russian-doll caching”, you have a large chance of hitting highly visible bugs. This entry could have been left out of the list, but I have a special hate in my heart for it. A common presentation of this flaw is user information (e.g. screennames, emails, and hashed passwords) mysteriously reverting to a previous value.
Computers can do more than you think they can. In the field today, there’s plenty of misinformation about what a machine is capable of from practitioners that do not have a great deal of experience.
At the end of 2012, a light web server had 6 or more processors, 24 GB of memory and more disk space than you can use. A relatively complex CRUD application in a modern language runtime on a single machine is trivially capable of doing thousands of requests per second within a few hundred milliseconds. And that’s a deep lower bound. In terms of operational ability, hundreds of requests per second per machine is not something to brag about in most cases.
Greater performance is not hard to come by, especially if you are willing to profile your application and introduce efficiencies based on your measurements.
Use the CAP theorem to critique systems. The CAP theorem isn’t something you can build a system out of. It’s not a theorem you can take as a first principle and derive a working system from. It’s much too general in its purview, and the space of possible solutions too broad.
However, it is well-suited for critiquing a distributed system design, and understanding what trade-offs need to be made. Taking a system design and iterating through the constraints CAP puts on its subsystems will leave you with a better design at the end. For homework, apply the CAP theorem’s constraints to a real world implementation of Russian-doll caching.
One last note: Out of C, A, and P, you can’t choose CA. #
# Extract services. “Service” here means “a distributed system that incorporates higher-level logic than a storage system and typically has a request-response style API”. Be on the lookout for code changes that would be easier to do if the code existed in a separate service instead of in your system.
An extracted service provides the benefits of encapsulation typically associated with creating libraries. However, extracting out a service improves on creating libraries by allowing for changes to be deployed faster and easier than upgrading the libraries in its client systems. (Of course, if the extracted service is hard to deploy, the client systems are the ones that become easier to deploy.) This ease is owed to the fewer code and operational dependencies in the smaller, extracted service and the strict boundary it creates makes it harder to “take shortcuts” that a library allows for. These shortcuts almost always make it harder to migrate the internals or the client systems to new versions.
The coordination costs of using a service is also much lower than a shared library when there are multiple client systems. Upgrading a library, even with no API changes needed, requires coordinating deploys of each client system. This gets harder when data corruption is possible if the deploys are performed out of order (and it’s harder to predict that it will happen). Upgrading a library also has a higher social coordination cost than deploying a service if the client systems have different maintainers. Getting others aware of and willing to upgrade is surprisingly difficult because their priorities may not align with yours.
The canonical service use case is to hide a storage layer that will be undergoing changes. The extracted service has an API that is more convenient, and reduced in surface area compared to the storage layer it fronts. By extracting a service, the client systems don’t have to know about the complexities of the slow migration to a new storage system or format and only the new service has to be evaluated for bugs that will certainly be found with the new storage layout.
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
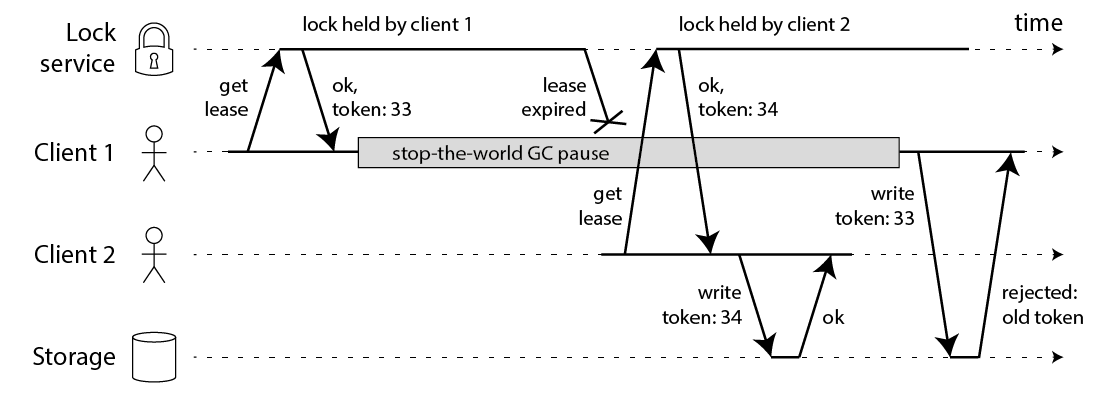
In this example, the client that acquired the lock is paused for an extended period of time while holding the lock – for example because the garbage collector (GC) kicked in. The lock has a timeout (i.e. it is a lease), which is always a good idea (otherwise a crashed client could end up holding a lock forever and never releasing it). However, if the GC pause lasts longer than the lease expiry period, and the client doesn’t realise that it has expired, it may go ahead and make some unsafe change.
This bug is not theoretical: HBase used to have this problem [3,4]. Normally, GC pauses are quite short, but “stop-the-world” GC pauses have sometimes been known to last forseveral minutes [5] – certainly long enough for a lease to expire. Even so-called “concurrent” garbage collectors like the HotSpot JVM’s CMS cannot fully run in parallel with the application code – even they need to stop the world from time to time [6].
And if you’re feeling smug because your programming language runtime doesn’t have long GC pauses, there are many other reasons why your process might get paused. Maybe your process tried to read an address that is not yet loaded into memory, so it gets a page fault and is paused until the page is loaded from disk. Maybe your disk is actually EBS, and so reading a variable unwittingly turned into a synchronous network request over Amazon’s congested network. Maybe there are many other processes contending for CPU, and you hit a black node in your scheduler tree. Maybe someone accidentally sent SIGSTOP to the process. Whatever. Your processes will get paused.
If you still don’t believe me about process pauses, then consider instead that the file-writing request may get delayed in the network before reaching the storage service. Packet networks such as Ethernet and IP may delay packets arbitrarily, and they do [7]: in a famous incident at GitHub, packets were delayed in the network for approximately 90 seconds [8]. This means that an application process may send a write request, and it may reach the storage server a minute later when the lease has already expired.
Even in well-managed networks, this kind of thing can happen. You simply cannot make any assumptions about timing, which is why the code above is fundamentally unsafe, no matter what lock service you use.
Making the lock safe with fencing
The fix for this problem is actually pretty simple: you need to include a fencing token with every write request to the storage service. In this context, a fencing token is simply a number that increases (e.g. incremented by the lock service) every time a client acquires the lock. This is illustrated in the following diagram:
However, this leads us to the first big problem with Redlock: it does not have any facility for generating fencing tokens. The algorithm does not produce any number that is guaranteed to increase every time a client acquires a lock. This means that even if the algorithm were otherwise perfect, it would not be safe to use, because you cannot prevent the race condition between clients in the case where one client is paused or its packets are delayed.
And it’s not obvious to me how one would change the Redlock algorithm to start generating fencing tokens. The unique random value it uses does not provide the required monotonicity. Simply keeping a counter on one Redis node would not be sufficient, because that node may fail. Keeping counters on several nodes would mean they would go out of sync. It’s likely that you would need a consensus algorithm just to generate the fencing tokens. (If only incrementing a counter was simple.)
Using time to solve consensus
The only purpose for which algorithms may use clocks is to generate timeouts, to avoid waiting forever if a node is down. But timeouts do not have to be accurate: just because a request times out, that doesn’t mean that the other node is definitely down – it could just as well be that there is a large delay in the network, or that your local clock is wrong. When used as a failure detector, timeouts are just a guess that something is wrong. (If they could, distributed algorithms would do without clocks entirely, but then consensus becomes impossible [10]. Acquiring a lock is like a compare-and-set operation, which requires consensus [11].)
Note that Redis uses
gettimeofday, not a monotonic clock, to determine the expiry of keys. The man page for gettimeofday explicitly says that the time it returns is subject to discontinuous jumps in system time – that is, it might suddenly jump forwards by a few minutes, or even jump back in time (e.g. if the clock is stepped by NTP because it differs from a NTP server by too much, or if the clock is manually adjusted by an administrator). Thus, if the system clock is doing weird things, it could easily happen that the expiry of a key in Redis is much faster or much slower than expected.
For algorithms in the asynchronous model this is not a big problem: these algorithms generally ensure that their safety properties always hold, without making any timing assumptions [12]. Only liveness properties depend on timeouts or some other failure detector. In plain English, this means that even if the timings in the system are all over the place (processes pausing, networks delaying, clocks jumping forwards and backwards), the performance of an algorithm might go to hell, but the algorithm will never make an incorrect decision.
However, Redlock is not like this. Its safety depends on a lot of timing assumptions: it assumes that all Redis nodes hold keys for approximately the right length of time before expiring; that the network delay is small compared to the expiry duration; and that process pauses are much shorter than the expiry duration.
Breaking Redlock with bad timings
Let’s look at some examples to demonstrate Redlock’s reliance on timing assumptions. Say the system has five Redis nodes (A, B, C, D and E), and two clients (1 and 2). What happens if a clock on one of the Redis nodes jumps forward?
- Client 1 acquires lock on nodes A, B, C. Due to a network issue, D and E cannot be reached.
- The clock on node C jumps forward, causing the lock to expire.
- Client 2 acquires lock on nodes C, D, E. Due to a network issue, A and B cannot be reached.
- Clients 1 and 2 now both believe they hold the lock.
A similar issue could happen if C crashes before persisting the lock to disk, and immediately restarts. For this reason, the Redlock documentation recommends delaying restarts of crashed nodes for at least the time-to-live of the longest-lived lock. But this restart delay again relies on a reasonably accurate measurement of time, and would fail if the clock jumps.
Okay, so maybe you think that a clock jump is unrealistic, because you’re very confident in having correctly configured NTP to only ever slew the clock. In that case, let’s look at an example of how a process pause may cause the algorithm to fail:
- Client 1 requests lock on nodes A, B, C, D, E.
- While the responses to client 1 are in flight, client 1 goes into stop-the-world GC.
- Locks expire on all Redis nodes.
- Client 2 acquires lock on nodes A, B, C, D, E.
- Client 1 finishes GC, and receives the responses from Redis nodes indicating that it successfully acquired the lock (they were held in client 1’s kernel network buffers while the process was paused).
- Clients 1 and 2 now both believe they hold the lock.
Note that even though Redis is written in C, and thus doesn’t have GC, that doesn’t help us here: any system in which the clients may experience a GC pause has this problem. You can only make this safe by preventing client 1 from performing any operations under the lock after client 2 has acquired the lock, for example using the fencing approach above.
A long network delay can produce the same effect as the process pause. It perhaps depends on your TCP user timeout – if you make the timeout significantly shorter than the Redis TTL, perhaps the delayed network packets would be ignored, but we’d have to look in detail at the TCP implementation to be sure. Also, with the timeout we’re back down to accuracy of time measurement again!
If you need locks only on a best-effort basis (as an efficiency optimization, not for correctness), I would recommend sticking with the straightforward single-node locking algorithm for Redis (conditional set-if-not-exists to obtain a lock, atomic delete-if-value-matches to release a lock), and documenting very clearly in your code that the locks are only approximate and may occasionally fail. Don’t bother with setting up a cluster of five Redis nodes.
On the other hand, if you need locks for correctness, please don’t use Redlock. Instead, please use a proper consensus system such as ZooKeeper, probably via one of the Curator recipes that implements a lock. (At the very least, use a database with reasonable transactional guarantees.) And please enforce use of fencing tokens on all resource accesses under the lock.