Video service over Http Live Streaming for mobile devices, which…
has limited memory/storage
suffers from the unstable network connection and variable bandwidth, and needs midstream quality adjustments.
Solution
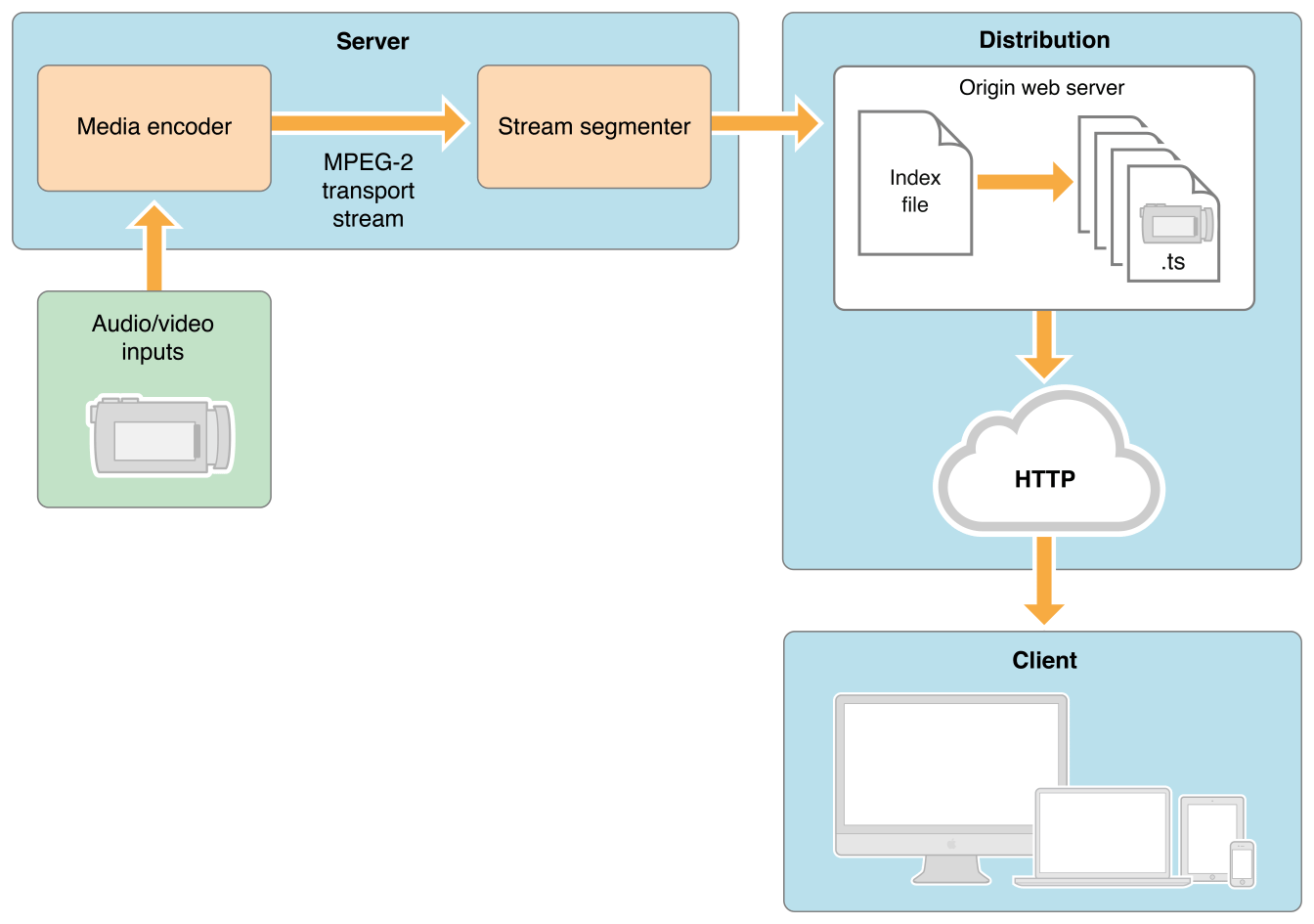
Server-side: In a typical configuration, a hardware encoder takes audio-video input, encodes it as H.264 video and AAC audio, and outputs it in an MPEG-2 Transport Stream
the stream is then broken into a series of short media files (.ts possibly 10s) by a software stream segmenter.
The segmenter also creates and maintains an index(.m3u8) file containing a list of the media files.
Both the media fils and the index files are published on the web server.
Client-side: client reads the index, then requests the listed media files in order and displays them without any pauses or gaps between segments.
Architecture
https://code.fb.com/ios/under-the-hood-broadcasting-live-video-to-millions/ Public figures on Facebook can have millions of followers all trying to watch a video at once; creating new tricks for load balancing became our goal. To begin rolling out live video for more people, we’re taking the latency in live broadcasts down to few seconds by enabling RTMP playback. We’re hoping that these low-latency broadcasts will make the experience more engaging for broadcasters and viewers alike. No high-scale system likes traffic spikes, especially this many requests coming in at once. When it happens, we call it a “thundering herd” problem — too many requests can stampede the system, causing lag, dropout, and disconnection from the stream.
The best way to stop the stampede is to never let it through the gates, so to speak. Instead of having clients connecting directly to the live stream server, there’s a network of edge caches distributed around the globe. A live video is split into three-second HLS segments in our implementation. These segments are sequentially requested by the video player displaying the broadcast. The segment request is handled by one of the HTTP proxies in an edge data center that checks to see whether the segment is already in an edge cache. If the segment is in cache, it’s returned directly from there. If not, the proxy issues an HTTP request to the origin cache, which is another cache layer with the same architecture. If the segment is not in origin cache, then it needs to request it to the server handling that particular stream. Then the server returns the HTTP response with the segment, which is cached in each layer, so following clients receive it faster. With this scheme, more than 98 percent of segments are already in an edge cache close to the user, and the origin server receives only a fraction of requests.
The solution works well, except that at our scale there was some leakage — about 1.8 percent of requests were getting past the edge cache. When you’re dealing with a million viewers, that’s still a large number. To make sure there was no failure at the origin level, we applied a technique called request coalescing. People typically watch regular, non-live videos at different times. You can see the traffic spike coming if something is viral, so the minute-to-minute need to balance the load isn’t there. With live video, a large number of people watch the same video at the same time with potentially no notice, which creates a load problem and a cache problem. People request the same video segment at the same time, and it may not be in cache yet. Without a thundering herd prevention plan, the edge cache would return a cache miss for all the client requests, and all of them would go to origin cache, and all the way to the live stream server. This would mean that a single server would receive a huge number of requests. To prevent that, the edge cache returns a cache miss for the first request, and it holds the following requests in a queue. Once the HTTP response comes from the server, the segment is stored in the edge cache, and the requests in the queue are responded from the edge as cache hits. This effectively handles the thundering herd, reducing the load to origin. The origin cache in turn runs the same mechanism to handle requests from multiple edge caches — the same object can be requested from an edge cache in Chicago and an edge cache in Miami.
Bringing latency down
Where building Live for Facebook Mentions was an exercise in making sure the system didn’t get overloaded, building Live for people was an exercise in reducing latency. People who aren’t public figures are more likely to be broadcasting to a small, interactive group. It was important to us that people be able to have near real-time conversations without an awkward data transmission delay. To bring latency down to a two- to three-second transmission, we decided to use RTMP.
RTMP is a streaming protocol that maintains a persistent TCP connection between the player and the server during the whole broadcast. Unlike HLS, RTMP uses a push model. Instead of the player requesting each segment, the server continuously sends video and audio data. The client can still issue pause and resume commands when the person requests it or when the player is not visible. In RTMP, the broadcast is split into two streams: a video stream and an audio stream. The streams are split into chunks of 4 KB, which can be multiplexed in the TCP connection, i.e., video and audio chunks are interleaved. At a video bit rate of 500 Kbps, each chunk is only 64 ms long, which, compared with HLS segments of 3 seconds each, produces smoother streaming across all components. The broadcaster can send data as soon as it has encoded 64 ms of video data; the transcoding server can process that chunk and produce multiple output bit rates. The chunk is then forwarded through proxies until it reaches the player. The push model plus small chunks reduce the lag between broadcaster and viewer by 5x, producing a smooth and interactive experience. Most of the live stream products use HLS because it’s HTTP-based and easy to integrate with all existing CDNs. But because we wanted to implement the best live streaming product, we decided to implement RTMP by modifying nginx-rtmp module, and developed an RTMP proxy. The lessons learned from the HLS path also allowed us to implement an RTMP architecture that effectively scales to millions of broadcasters.
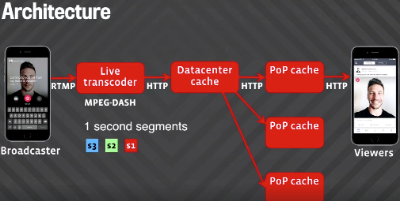
They started with HLS, HTTP Live Streaming. It’s supported by the iPhone and allowed them to use their existing CDN architecture.
Simultaneously began investigating RTMP (Real-Time Messaging Protocol), a TCP based protocol. There’s a stream of video and a stream of audio that is sent from the phone to the Live Stream servers.
Advantage: RTMP has lower end-end latency between the broadcaster and viewers. This really makes a difference an interactive broadcast where people are interacting with each other. Then lowering latency and having a few seconds less delay makes all the difference in the experience.
Disadvantage: requires a whole now architecture because it’s not HTTP based. A new RTMP proxy need to be developed to make it scale.
Also investigating MPEG-DASH (Dynamic Adaptive Streaming over HTTP).
Advantage: compared to HLS it is 15% more space efficient.
Advantage: it allows adaptive bit rates. The encoding quality can be varied based on the network throughput.
Spiky traffic cause problems in the caching system and the load balancing system.
Caching Problems
A lot of people may want to watch a live video at the same time. This is your classic Thundering Herd problem.
The spiky traffic pattern puts pressure on the caching system.
Video is segmented into one second files. Servers that cache these segments may overload when traffic spikes.
Global Load Balancing Problem
Facebook has points of presence (PoPs) distributed around the world. Facebook traffic is globally distributed.
The challenge is preventing a spike from overloading a PoP.
How Does It Scale?
There is one point of multiplication between the datacenter cache and the many PoP caches. Users access PoP caches, not the datacenter, and there are many PoP caches distributed around the world.
Another multiplication factor is within each PoP.
Within the PoP there are two layers: a layer of HTTP proxies and a layer of cache.
Viewers request the segment from a HTTP proxy. The proxy checks if the segment is in cache. If it’s in cache the segment is returned. If it’s not in cache a request for the segment is sent to the datacenter.
Different segments are stored in different caches so that helps with load balancing across different caching hosts.
Protecting The Datacenter From The Thundering Herd
What happens when all the viewers are requesting the same segment at the same time?
If the segment is not in cache one request will be sent to the datacenter for each viewer.
Request Coalescing. The number of requests is reduced by adding request coalescing to the PoP cache. Only the first request is sent to the datacenter. The other requests are held until the first response arrives and the data is sent to all the viewers.
New caching layer is added to the proxy to avoid the Hot Server problem.
All the viewers are sent to one cache host to wait for the segment, which could overload the host.
The proxy adds a caching layer. Only the first request to the proxy actually makes a request to the cache. All the following requests are served directly from the proxy.
PoPs Are Still At Risk - Global Load Balancing To The Rescue
So the datacenter is protected from the Thundering Herd problem, but the PoPs are still at risk. The problem with Live is the spikes are so huge that a PoP could be overloaded before the load measure for a PoP reaches the load balancer.
Each PoP has a limited number of servers and connectivity. How can a spike be prevented from overloading a PoP?
A system called Cartographer maps Internet subnetworks to PoPs. It measure the delay between each subnet and each PoP. This is the latency measurement.
The load for each PoP is measured and each user is sent to the closest PoP that has enough capacity. There are counters in the proxies that measure how much load they are receiving. Those counters are aggregated so we know the load for each PoP.
Now there’s an optimization problem that respects capacity constraints and minimizes latency.
With control systems there’s a delay to measure and a delay to react.
They changed the load measurement window from 1.5 minutes to 3 seconds, but there’s still that 3 second window.
The solution is to predict the load before it actually happens.
A capacity estimator was implemented that extrapolates the previous load and the current load of each PoP to the future load.
How can a predictor predict the load will decrease if the load is currently increasing?
Cubic splines are used for the interpolation function.
The first and second derivative are taken. If the speed is positive the load is increasing. If the acceleration is negative that means the speed is decreasing and it will eventually be zero and start decreasing.
Cubic splines predict more complex traffic patterns than linear interpolation.
Avoiding oscillations. This interpolation function also solves the oscillation problem.
The delay to measure and react means decisions are made on stale data. The interpolation reduces error, predicting more accurately, and reduces oscillations. So the load can be closer to the capacity target
Currently prediction is based on the last three intervals where each interval is 30 seconds. Almost instantaneous load.
Testing
You need to be able to overload a PoP.
A load testing service was built that is globally distributed across the PoPs that simulates live traffic.
Able to simulate 10x production load.
Can simulate a viewer that is requesting one segment at a time.
This system helped reveal and fix problems in the capacity estimator, to tune parameters, and to verify the caching layer solves the Thundering Herd problem.
Upload Reliability
Uploading a video in real-time is challenging.
Take, for an example, an upload that has between 100 and 300 Kbps of available bandwidth.
Audio requires 64 Kbps of throughput.
Standard definition video require 500 Kbps of throughput.
Adaptive encoding on the phone is used to adjust for the throughput deficit of video + audio. The encoding bit-rate of the video is adjusted based on the available network bandwidth.
The decision for the upload bitrate is done in the phone by measuring uploaded bytes on the RTMP connection and it does a weighted average of the last intervals.
Future Direction
Investigating a push mechanism rather than the request-pull mechanism, leveraging HTTP/2 to push to the PoPs before segments have been requested.
An interesting post by Facebook engineering shares information on these challenges and the design approaches they took: Facebook’s system uses Content Delivery Network (CDN) architecture with a two-layer caching of the content, with the edge cache closest to the users and serving 98 percent of the content. This design aims to reduce the load from the backend server processing the incoming live feed from the broadcaster. Another useful optimization for further reducing the load on the backend is request coalescing, whereby when many followers (in the case of celebs it could reach millions!) are asking for some content that’s missing in the cache (cache miss), only one instance request will proceed to the backend to fetch the content on behalf of all to avoid a flood.
A stateless architecture is easy to scale horizontally and only requires simple round-robin load balancing.
What’s not to love? Perhaps the increased latency from the roundtrips to the database. Or maybe the complexity of the caching layer required to hide database latency problems. Or even the troublesome consistency issues.
But what of stateful services? Isn’t preserving identity by shipping functions to data instead of shipping data to functions a better approach?
You’ll recognize most of the ideas--Sticky Sessions, Data Shipping Paradigm, Function Shipping Paradigm, Data Locality, CAP, Cluster Membership, Gossip Protocols, Consistent Hashing, DHT
Orlean It’s based on an inherently stateful distributed virtual Actor model; a highly available Gossip Protocol is used for cluster membership; and a two tier system of Consistent Hashing plus a Distributed Hash Table is used for work distribution. With this approach Orleans can rebalance a cluster when a node fails, or capacity is added/contracted, or a node becomes hot. The result is Halo was able to run a stateful Orleans cluster in production at 90-95% CPU utilization across the cluster.
Stateless Services Are Wasteful
The problem is our applications do have state and we are hitting limits where one database doesn’t cut it anymore. In response we’re sharding relational databases or using NoSQL databases. This gives up strong consistency which causes part of the database abstraction to leak into services.
Data Shipping Paradigm
A client makes a service request. The service talks to the database and the database replies with some data. The service does some computation. A reply is sent to the client. And then the data disappears from the service.
The next request will be load balanced to a different machine and the whole process happens all over again.
It’s wasteful to repeatedly pull resources into load balanced services for applications that involve chatty clients operating over a session over a period of time. Examples: games,
Stateful Services Are Easier To Program
Data Locality. The idea that requests are shipped to the machine holding the data that it needs to operate on. Benefits:
Low latency. Don’t have to hit the database for every single request. The database only needs to be accessed if the data falls out of memory. The number of network accesses is reduced.
Data intensive applications. If a client needs to operate a bunch of data it will all be accessible so a response can be returned quickly.
Function Shipping Paradigm
A client makes a request or starts a session the database is accessed one time to get the data and the data then moves into the service.
Once the request has been handled the data is left on the service. The next time the client makes a request the request is routed to the same machine so it can operate on data that’s already in memory.
Avoided are extra trips to the database which reduces latency. Even if the database is down the request can be handled.
Statefulness leads to more highlyavailable and stronger consistency models.
In the CAP world where we have different levels of consistency that we operate against, some are more available than others. When there’s a partition CP systems chose consistency over availability and AP systems chose availability over consistency.
If we want to have more highly available systems under AP we get Write From Read, Monotonic Read, Monotonic Write. (for definitions)
If we have sticky connections where the data for a single user is on a single machine then you can have stronger consistency guarantees like Read Your Writes, Pipelined Random Access Memory.
Werner Vogel 2007: Whether or not read-your-write, session and monotonic consistency can be achieved depends in general on the "stickiness" of clients to the server that executes the distributed protocol for them. If this is the same server every time than it is relatively easy to guarantee read-your-writes and monotonic reads. This makes it slightly harder to manage load balancing and fault-tolerance, but it is a simple solution. Using sessions, which are sticky, makes this explicit and provides an exposure level that clients can reason about.
Sticky connections give clients an easier model to reason about. Instead of worrying about data being pulled into lots of different machines and having to worry about concurrency, you just have the client talking to the same server, which is easier to think about and is a big help when programming distributed systems.
Building Sticky Connections
A client makes a request to a cluster of servers and the request is always routed to the same machine.
Simplest way is to open up a persistent HTTP connection or a TCP connection.
Easy to implement because a connection means you are always talking to the same machine.
Problem: Once the connection breaks the stickiness is gone and the next request will be load balanced to another server.
Problem: load balancing. There’s an implicit assumption that all the sticky sessions last for about the same amount of time and generating about the same amount of load. This is not generally the case. It’s easy to overwhelm a single server with too many connections if they dog pile onto a server, if connections last a long time, or a lot of work is done for each connection.
Backpressure must be implemented so a server can break connections when they are overwhelmed. This causes the client to reconnect to a hopefully less burdened server. You can also load balance based on the amount of resources free to spread work out more equitably.
Something a little smarter is to implement routing in a cluster. A client can talk to any server in a cluster which routes the client to the server containing the correct data. Two capabilities are required:
Cluster membership. Who is in my cluster? How do we determine what machines are available to talk to?
Work distribution. How is load distributed across the cluster?
Gossip Protocols - Emphasise Availability
Gossip protocols spread knowledge through the group by sending messages.
The messages talk about who they can talk to and who’s alive and who’s dead. Each machine on its own will figure out from the data it collects its world view of who is in the cluster.
In a stable state all the machines in the cluster will converge on having the same world view of who is alive and dead.
In the case of network failures, network partitions, or when capacity is added or deleted, different machines in the cluster can have different worldviews of who is the cluster.
There’s a tradeoff. You have high availability because no coordination is necessary, every machine can make decisions based on its own worldview, but your code has to be able to handle the uncertainty of getting routed to different nodes during failures.
Consensus Systems - Emphasise Consistency
All nodes in the cluster will have the exact same worldview.
The consensus system controls the ownership of everyone in the cluster. When the configuration changes all the nodes update their worldview based on the consensus system that holds the true cluster membership.
Problem: if the consensus system is not available then nodes can’t route work because they don’t know who’s in the cluster.
Problem: it will be slower because coordination is added to the system.
If you need highly availability consensus systems are to be avoided unless they are really necessary..
Work Distribution
Work distribution refers to how work is moved throughout the cluster.
There are three types of work distribution systems: Random Placement, Consistent Hashing, Distributed Hash Tables.
Random Placement
Sounds dumb but it can be effective. It works in scenarios where there’s a lot of data and queries operating on a large amount of data that’s distributed around the cluster.
A write goes to any machine that has capacity.
A read requires querying every single machine in the cluster to get the data back.
This isn’t a sticky connection, but it is a stateful service. It’s a good way to build in-memory indexes and caches.
Consistent Hashing - Deterministic Placement
Deterministic placement of requests to a node based on a hash, perhaps the session ID, or user ID, depending on how the workload is to be partitioned.
As nodes get mapped to the cluster, requests are mapped to the ring, and you walk right to find the node that’s going to execute the request.
Databases like Cassandra often use this approach because of the deterministic placement.
Problem: hotspots.
A lot of requests can end up being hashed to the same node and that node is overwhelmed with the traffic. Or a node can be slow, perhaps a disk is going bad, and it is overwhelmed with even normal amounts of requests.
Consistent hashing doesn’t allow work to be moved as a way of cooling down the hotspots.
So you have to allocate enough space in your cluster to run with enough headroom to tolerate deterministic placement and the fact that work can’t be moved.
This additional capacity is an additional cost the must be absorbed even in the normal case.
Distributed Hash Table (DHT) - Non Deterministic Placement
A hash is used to lookup in a distributed hash table to locate where the work should be sent to. The DHT holds references to nodes in the cluster.
This is nondeterministic because nothing is forcing work to go to a particular node. It’s easy to to remap a client so it goes to some other node if a node becomes unavailable or becomes too hot.
Three Example Stateful Services In The Real World
Facebook’s Scuba - Random Fanouts On Writes
Scuba is a fast scalable distributed in-memory database used for code regression and analysis, bug reporting, revenue, and performance debugging. (more info)
It has to be very fast and always available.
The thought is it uses static cluster membership, though this is not explicitly stated in the paper.
Scuba uses random fanouts on writes. On reads every single machine is queried. All the results are returned and composed by the machine that is running the query and the results are returned to the user.
In the real world machines are unavailable so queries are run with best effort availability. If not all the nodes are available queries return a result over the data that is available, along with statistics about what percentage of the data they processed. The user can decide if the results meet a high enough threshold for quality.
Sticky connections aren’t used, but the data is in-memory so the lookups are very fast.
Ringpop is a node.js library implementing application-layer sharding. (more info)
Uber has the concept of a trip. To start a trip a user orders a car which requires the rider information and location information, data is updated during the trip throughout the ride, and the payment must be processed at the end of the trip.
It would be inefficient for each of these updates to be load balanced to a different stateless server every time. The data would constantly be persisted to the database and then pulled back in again. This introduces a lot of latency and extra load on the database.
The design implements routing logic so all the requests for a user can be directed to a single machine.
The Swim Gossip Protocol is used to maintain cluster membership. It’s an AP cluster membership protocol so it’s not guaranteed to be always correct. Availability was chosen over correctness because it’s more important that a user can always order a car.
Consistent hashing is used to route work throughout the cluster. This has the hot node problem and the only remedy is to add more capacity, even if other nodes are under utilized.
Orleans is a runtime and programming model for building distributed systems based on the Actor Model. (more info)
Orleans came out of Microsoft Research from the Extreme Computing Group. The presenter (Caitie McCaffrey) worked with the group to productize Orleans in the process of shipping Halo 4. All the Halo 4 services were rebuilt primarily on Orleans.
Actors are the core unit of computation. Actors communicate with each other using asynchronous messages throughout the cluster. When an Actor receives a message it can do one or more of the following: send one or more messages, update it’s internal state, create new Actors.
In a cluster based on the Actor model what you have is a bunch of state machines running, so the Actor model is inherently stateful if they are persisting state between requests.
In Halo 4 they would deploy a cluster of machines and Orleans took care of the rest.
A request would go to any machine in the cluster. The cluster would look up where the Actor lived in the cluster and route the message to the Actor.
Hundreds of thousands of Actors run on a single machine in the cluster.
A gossip protocol is used for cluster membership in order to be highly available. Since Orleans was open sourced a Zookeeper implementation was created, which is slower.
For work distribution Orleans uses a combination of consistent hashing + distributed hash tables.
When a request for an Actor is sent to the cluster the Orleans runtime will calculate a consistent hash on the Actor ID. The hash maps to a machine with a distributed hash table for that ID.
The distributed hash table for the Actor knows which machine contains the Actor for the specified ID.
After consulting the DHT, the request is routed to the appropriate machine.
Consistent hashing is used to find the Actor DHT, so it’s a deterministic operation. The location of the DHT in the cluster will not change. And since the amount of data in the DHT is small and the Actor DHTs are evenly distributed, hotspots are not a big concern.
What Actors are doing is not evenly distributed and balanced.
Orleans has the ability to automatically rebalance clusters. The entry in the DHT can be updated to point to a new machine when:
A session dies.
A machine failed so a new machined must be assigned.
An Actor was evicted from memory because nobody was talking to it.
A machine gets too hot so Orleans moves the Actor to a different machine with more capacity so the hot machine doesn’t fail.
The rebalancing feature of Orleans is a core reason why the Orleans cluster could be run in production at 90-95% CPU utilization across the cluster. Being able to move work around in a non-deterministic fashion means you can use all the capacity of a box.
This approach may not work for a database, but it does work great for pulling state into services.
What Can Go Wrong
Unbounded Data Structures
In stateful systems unbounded data structures are a good way to die. Examples: unbounded queues, unbounded in-memory structure.
It’s something we don’t have to think about often in stateless services because they can recover from these kind of transient failures.
In a stateful service a service can get a lot of requests so explicit bounds must be put on data structures or they may keep growing. Then you may run out of memory or your garbage collector may stop the world and the node may look dead (I would also add locks can be held for a long time as data structures grow).
Clients are not your friends. Clients won’t do what you want them to do. Machines can die because of the implicit assumption we won’t run out of memory or clients will only send a reasonable amount of data. Code must protect themselves against their clients.
Memory Management
Because data is being persisted in memory for the lifetime of a session, perhaps minutes, hours, or even days, memory will move into the longest lived generation of garbage collection. That memory is generally more expensive to collect, especially if there are references spanning generations.
You have to be more aware of how memory works in stateful services and you need to actually know how your garbage collector is running.
Or you could write everything in unmanaged code like C++, so you don’t have to deal with the garbage collector problem.
Orleans runs the .NET CLR, which is a garbage collected environment and they did run into cross generational garbage collection problems.
It was handled by tuning the garbage collector.
It was also handled by realizing a lot of unnecessary state was persisted. You have to be careful about what you are persisting because there is an associated cost.
Reloading State
Typically in a stateless service the database must be queried for each request so the latency must be tuned to account for the round trip to the database. Or you can use a cache to make it faster.
In a stateful service there are a variety of different times state can be reloaded: first connection, recovering from crashes, deploying new code.
First Connection
Generally the most expensive connection because there is no data on the node. All the data must be pulled into the database so requests can be handled.
This could take a long time, so you want to be very careful what you load on startup. You don’t want a high latency hit for a request that just happens to land on the first connection.
In testing make use of percentiles. Your average latency will look good because you don’t have to round trip to the database every time. The first connection latency may spike and you don’t want to miss that.
On a first connection if the client times out because access to the database is slow you continue trying to load from the database because you know the client will retry again. The next access by the client will be fast because the data will likely be in memory. In a stateless service you can’t make this kind of optimization.
In Halo, for example, when a game started the first connection would sometimes timeout. Perhaps the user had a lot game state or the connection was loaded. So they kept pulling in the data in and when the gamebox retried the request would succeed. The latency wasn’t user noticeable, especially given the pretty animation the user was watching.
Recovering From Crashes
If you have to rehydrate an entire box after recovering from a crash that could be expensive if you are not lazily loading all the Actors. Sometimes you can get away with lazy loading and sometimes you can't.
Deploying New Code
To deploy new code you have to take down an entire box and bring it back up another box. It can be a problem if you don’t have non-deterministic placement or dynamic clustering membership.
Facebook’s Scuba product had the restart problem because it was an in-memory database storing a lot of data that was persisted to hard disk.
On a crash or a deploy they would take down the machine that was currently running, spin up a new machine, then read everything from disk. This took hours per machine. And because of their SLAs Facebook had to do a slow rolling update of their cluster that took up to 12 hours.
A crash doesn’t happen all that often so a slow restart is not that big a concern. We would like code deploys to happen frequently so we can iterate faster, try new ideas, do less risky deployments.
Facebook made the key observation that you can decouple the memory lifetime from the process lifetime, especially in a stateful service.
When Facebook wanted to deploy new code, and they knew it was a safe shutdown and memory wasn’t corrupted, they would: stop taking requests, copy data from the currently running process to shared memory, shutdown the old process, bring up the new process, then the data from shared memory would be copied back into the process memory space, and then requests would restart.
This process takes minutes so a cluster restart is now in the order of two hours instead of 12 hours. Now it’s possible to deploy new code more frequently than was previously possible.
Twitter is considering implementing this strategy for a stateful index that when a whole machine is restarted has to talk to their Manhattan database, which is really slow compared to memory.
You need to copy all files which are present in that directory to your laptop. I've done this successfully many times. I run the analyser on the server using
The org.eclipse.mat.api:suspects argument creates a ZIP file containing the leak suspect report. This argument is optional.
The org.eclipse.mat.api:overview argument creates a ZIP file containing the overview report. This argument is optional.
The org.eclipse.mat.api:top_components argument creates a ZIP file containing the top components report. This argument is optional.
Normally, what I use is ParseHeapDump.sh included within Eclipse Memory Analyzer and described here, and I do that onto one our more beefed up servers (download and copy over the linux .zip distro, unzip there). The shell script needs less resources than parsing the heap from the GUI, plus you can run it on your beefy server with more resources (you can allocate more resources by adding something like -vmargs -Xmx40g -XX:-UseGCOverheadLimit to the end of the last line of the script. For instance, the last line of that file might look like this after modification
Run it like ./path/to/ParseHeapDump.sh ../today_heap_dump/jvm.hprof
After that succeeds, it creates a number of "index" files next to the .hprof file.
After creating the indices, I try to generate reports from that and scp those reports to my local machines and try to see if I can find the culprit just by that (not just the reports, not the indices). Here's a tutorial on creating the reports.
org.eclipse.mat.api:overview and org.eclipse.mat.api:top_components
If those reports are not enough and if I need some more digging (i.e. let's say via oql), I scp the indices as well as hprof file to my local machine, and then open the heap dump (with the indices in the same directory as the heap dump) with my Eclipse MAT GUI. From there, it does not need too much memory to run.
EDIT: I just liked to add two notes :
As far as I know, only the generation of the indices is the memory intensive part of Eclipse MAT. After you have the indices, most of your processing from Eclipse MAT would not need that much memory.
Doing this on a shell script means I can do it on a headless server (and I normally do it on a headless server as well, because they're normally the most powerful ones). And if you have a server that can generate a heap dump of that size, chances are, you have another server out there that can process that much of a heap dump as well.
Important note: ParseHeapDump.sh is packaged with the Linux version only, not the OSX version -- eclipse.org/mat/downloads.php