https://docs.microsoft.com/en-us/azure/architecture/patterns/cqrs

https://www.future-processing.pl/blog/cqrs-simple-architecture/

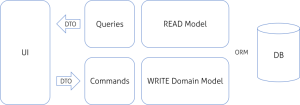
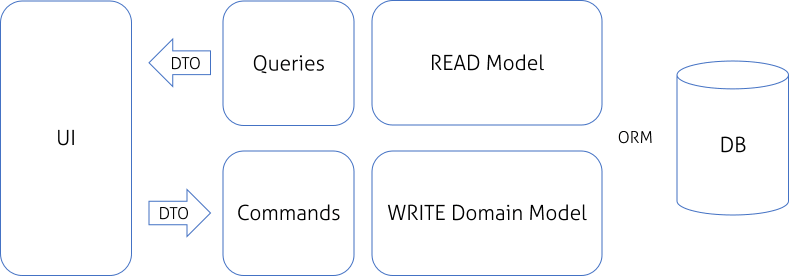
Command and Query Responsibility Segregation (CQRS) Pattern
Segregate operations that read data from operations that update data by using separate interfaces. This pattern can maximize performance, scalability, and security; support evolution of the system over time through higher flexibility; and prevent update commands from causing merge conflicts at the domain level.
The query model for reading data and the update model for writing data may access the same physical store, perhaps by using SQL views or by generating projections on the fly. However, it is common to separate the data into different physical stores to maximize performance, scalability, and security; as shown in Figure 3.
Figure 3 - A CQRS architecture with separate read and write stores
The read store can be a read-only replica of the write store, or the read and write stores may have a different structure altogether. Using multiple read-only replicas of the read store can considerably increase query performance and application UI responsiveness, especially in distributed scenarios where read-only replicas are located close to the application instances. Some database systems, such as SQL Server, provide additional features such as failover replicas to maximize availability.
Separation of the read and write stores also allows each to be scaled appropriately to match the load. For example, read stores typically encounter a much higher load that write stores.
CQRS stands for Command Query Responsibility Segregation. At its heart is the notion that you can use a different model to update information than the model you use to read information. For some situations, this separation can be valuable, but beware that for most systems CQRS adds risky complexity.
The mainstream approach people use for interacting with an information system is to treat it as a CRUD datastore.
https://www.future-processing.pl/blog/cqrs-simple-architecture/
This is typical N-Layer architecture as all of us probably know. If we want to add some CQS here, we can “simply” separate business logic into Commands and Queries:

If you are working with legacy codebase this is probably the hardest step as separating side-effects from reads in spaghetti code is not easy. In the same time this step is probably the most beneficial one; it gives you an overview where your side effects are performed.
Command – First of all,firing command is the only way to change the state of our system. Commands are responsible for introducing allchanges to the system. If there was no command, the state of the system remains unchanged! Command should not return any value. I implement it as a pair of classes: Command and CommandHandler. Command is just a plain object that is used by CommandHandler as input value (parameters) for some operation it represents. In my vision command is simply invoking particular operations in Domain Model (not necessarily one operation per command).
Query – Analogically, query is a READ operation. It reads the state of the system, filters, aggregates and transforms data to deliver it in the most useful format. It can be executed multiple times and will not affect the state of the system. I used to implement them as one class with some Execute (…) method, but now I think that separation to Query and QueryHandler/QueryExecutor may be useful.
Model became the Domain Model. By the Model I understand a group of containers for data while Domain Model encapsulates essential complexity of business rules
the command is responsible for changing state of our system, the essential complexity should be placed in the Domain Model.
After short period of time it will be quite obvious that Domain Model that works well for writing is not necessarily perfect for reading. It is not a huge discovery that it would be easier to read data from some specialized model:
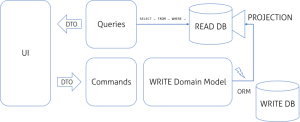
Now the problem is that we still have READ and WRITE model separated only at the logical level as both of them shares common database. That means we have separated READ model but most likely it is virtualized by some DB Views, in better case Materialized Views. This solution is OK if our system is not suffering from performance issues and we remember to update our queries along with WRITE model changes.
The next step is to introduce fully separated data models:
The next step is to introduce fully separated data models:

CQRS != EVENT SOURCING
Event Sourcing is an idea that was presented along with CQRS, and is often identified as a part of CQRS. The idea of ES is simple: our domain is producing events that represent every change made in system. If we take every event from the beginning of the system and replay them on initial state, we will get to the current state of the system. It works similarly to transactions on our bank accounts; we can start with empty account, replay every single transaction and (hopefully) get the current balance. So, if we have stored all events, we can always get the current state of the system.
I like to think about my WRITE model as about the heart of the system. This is my domain model, it makes business decisions, it is important. The fact that it makes business decisions is crucial here, because it defines major responsibility of this model: it represents the true state of the system, the state that can be used to make valuable decisions. This model is the only source of truth.
Read Model
We were forced to pre calculate some data for reports to keep it fast. That was an quite interesting, because in fact we have introduced a cache. And from my point of view this is the best definition of READ model: it is a legitimate cache. Cache that is there by design, and is not introduced because we have to release project and non-functional requirements are not met.
If your project is small and most of your reads can be efficiently made against WRITE model, it will be a waste of time and computing power to create copy. But if your WRITE model is stored as a series of events, it would be useful to have every required data available without replaying all events from scratch. This process is called Eager Read Derivation and from my point of view it is one of the most complex things in CQRS
https://www.codeproject.com/Articles/555855/Introduction-to-CQRS
http://www.cnblogs.com/netfocus/p/5184182.html
https://www.codeproject.com/Articles/555855/Introduction-to-CQRS
http://www.cnblogs.com/netfocus/p/5184182.html
CQRS架构由于本身只是一个读写分离的思想,实现方式多种多样。比如数据存储不分离,仅仅只是代码层面读写分离,也是CQRS的体现;然后数据存储的读写分离,C端负责数据存储,Q端负责数据查询,Q端的数据通过C端产生的Event来同步,这种也是CQRS架构的一种实现。今天我讨论的CQRS架构就是指这种实现。另外很重要的一点,C端我们还会引入Event Sourcing+In Memory这两种架构思想,我认为这两种思想和CQRS架构可以完美的结合,发挥CQRS这个架构的最大价值。
CQRS架构,则完全秉持最终一致性的理念。这种架构基于一个很重要的假设,就是用户看到的数据总是旧的。对于一个多用户操作的系统,这种现象很普遍。比如秒杀的场景,当你下单前,也许界面上你看到的商品数量是有的,但是当你下单的时候,系统提示商品卖完了。其实我们只要仔细想想,也确实如此。因为我们在界面上看到的数据是从数据库取出来的,一旦显示到界面上,就不会变了。但是很可能其他人已经修改了数据库中的数据。这种现象在大部分系统中,尤其是高并发的WEB系统,尤其常见。
所以,基于这样的假设,我们知道,即便我们的系统做到了数据的强一致性,用户还是很可能会看到旧的数据。所以,这就给我们设计架构提供了一个新的思路。我们能否这样做:我们只需要确保系统的一切添加、删除、修改操作所基于的数据是最新的,而查询的数据不必是最新的。这样就很自然的引出了CQRS架构了。C端数据保持最新、做到数据强一致;Q端数据不必最新,通过C端的事件异步更新即可。所以,基于这个思路,我们开始思考,如何具体的去实现CQ两端。看到这里,也许你还有一个疑问,就是为何C端的数据是必须要最新的?这个其实很容易理解,因为你要修改数据,那你可能会有一些修改的业务规则判断,如果你基于的数据不是最新的,那意味着判断就失去意义或者说不准确,所以基于老的数据所做的修改是没有意义的。