Caching
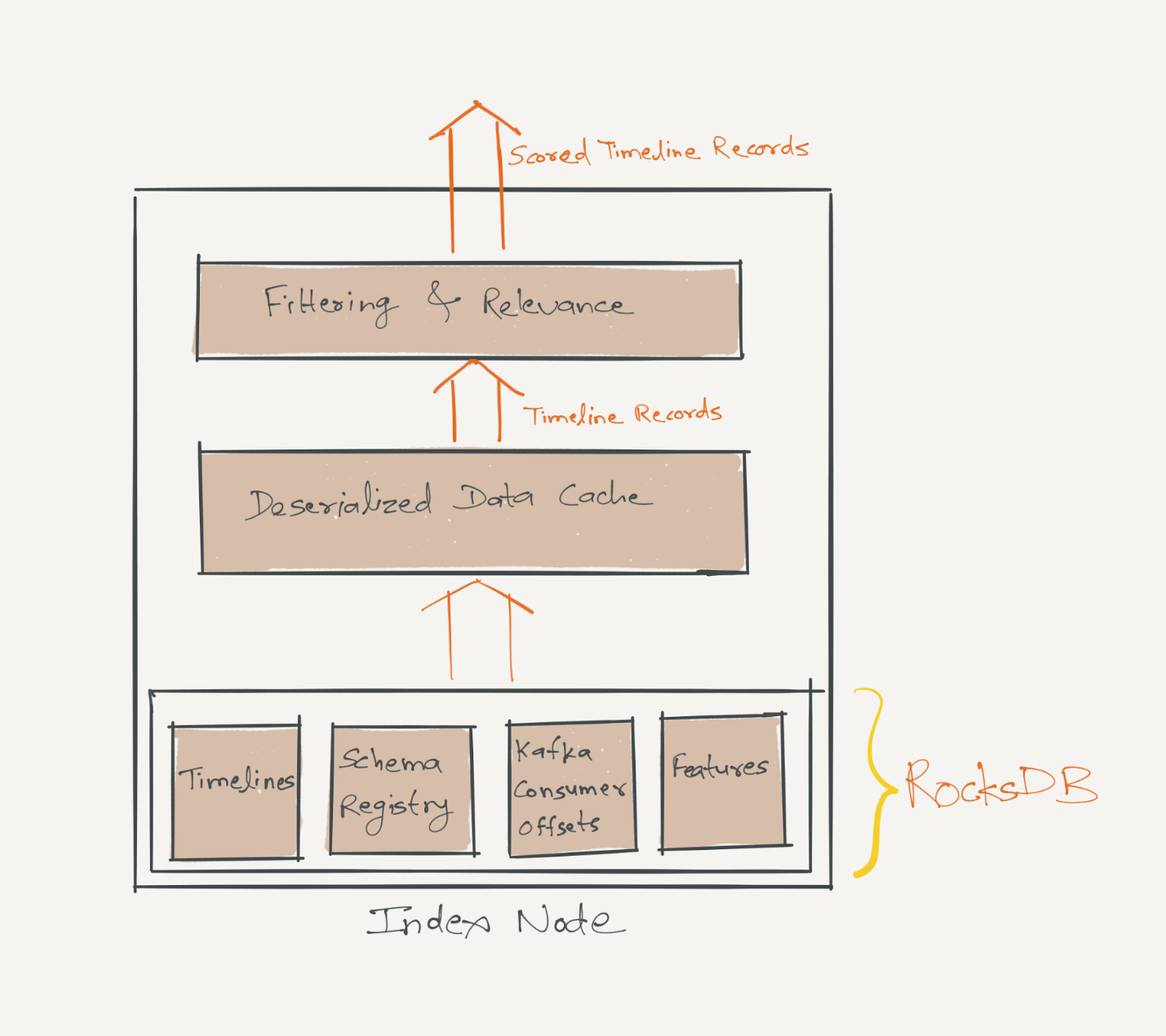
We realized that deserialization was a major bottleneck in serving requests. To optimize latency, each node maintains a read/write-through cache of deserialized content records. Our implementation uses the open source
Guava cache and leverages its functionalities such as the read-through LRU behaviour, limiting the total memory utilization by the size of the key-space or by computing "weights" of entities being cached.
Utilizing this cache effectively is mission-critical for FollowFeed. This translates to two requirements:
(1) The cache should provide high performance.
We usually deploy each index node with a large JVM footprint to cache as much data as possible. Experiments showed that due to the large size of this cache, concurrent evictions and reads became expensive. So using Guava’s configs, we partitioned the cache internally into multiple sub-caches. This optimization allows concurrent access to those sub-caches and also speeds up evictions.
(2) Good controls over what kind of data gets cached or gets evicted.
The memory used by the index node cache depends on two factors: the total number of timeline keys and the total number of records that are cached. Many timeline keys don’t have any records associated with them in the cache, because some members may not have shared new content in the feed for the past few days or may not have shared content of a certain type in the last few days. It is desirable to have good control over which timeline keys get evicted from the cache—those that have a non-empty list of records associated with them, or otherwise.
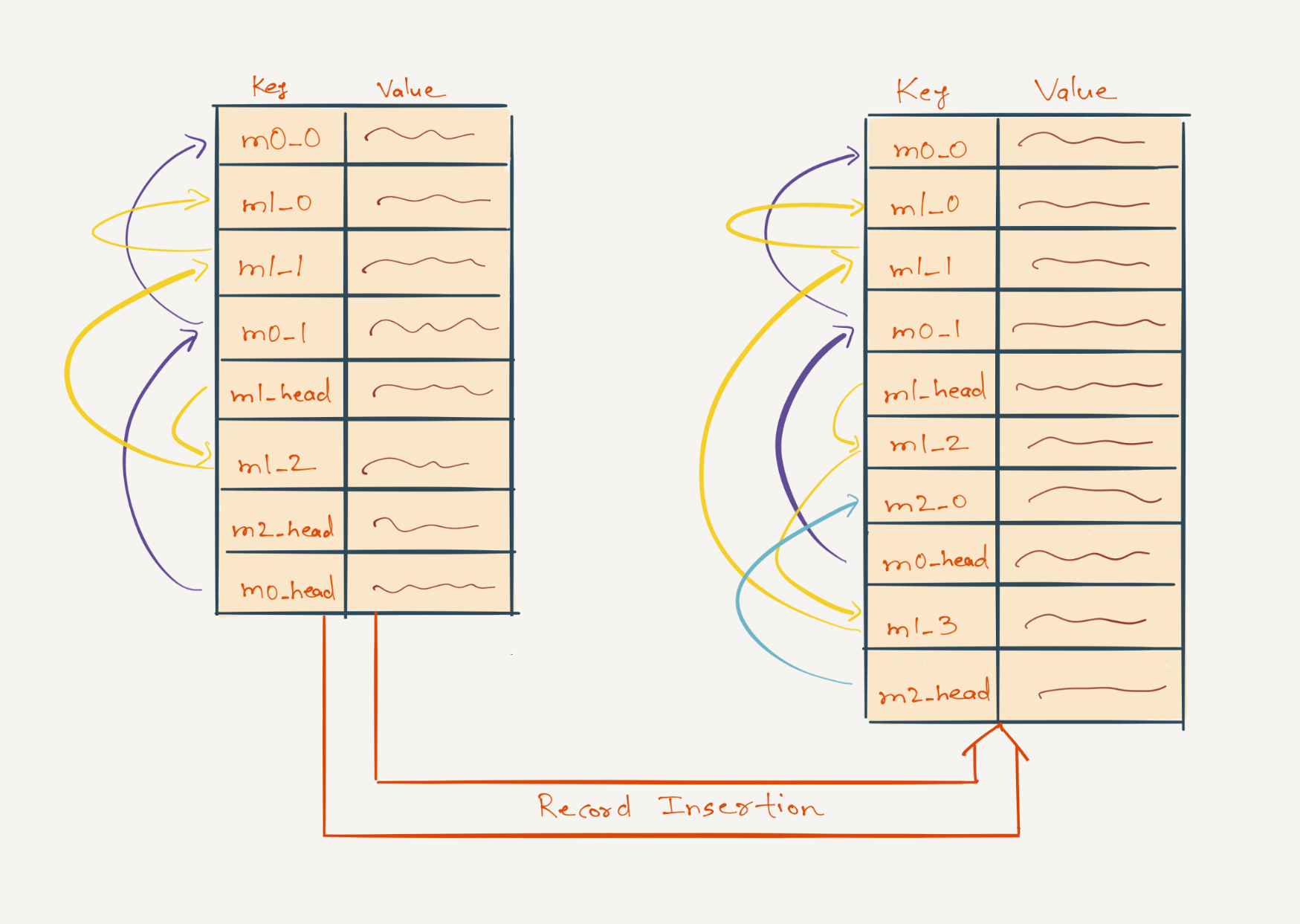
To achieve this, we use two instances of the Guava cache: one instance is called the fat cache, the other is called the skinny cache. The fat cache holds timeline keys and a non-empty list of records associated with each one of them, the skinny cache contains keys that don't have any records associated with them. The fat cache’s holding capacity is defined in terms of its ‘weight’—the total number of records it's holding, whereas the skinny cache’s holding capacity is defined in terms of its ‘size’—the total number of keys it's holding. By sizing these two instances well, we could reach the right effectiveness of caching and eviction.
Schema awareness
FollowFeed uses
Avro as the serialization protocol for data storage. Since Avro needs reader and writer schema instances for ser/deser, we needed a schema registry that stored all versions of schemas with which the data was serialized and persisted. We chose to make the index node schema aware, which means that along with timelines, each index node also persists a Schema Registry of Avro schemas in RocksDB. This registry is used to serialize and deserialize content records. There is also an in-memory deserialized object representation of this registry to allow fast access to schema objects.
FollowFeed performs such filtering logic on records retrieved from the Guava cache. Records that pass filtering then become input to the relevance algorithms.
Relevance Computation
A key feature of FollowFeed is highly performant online relevance which ranks tens of thousands of content records per request. Low latencies are achieved by performing this relevance computation in parallel on index nodes that are serving a query. Each index node persists and caches relevance features of different entity and content types. These features are imperative in building a valid feature vector for ranking. A feature vector can be imagined as a mapping of content record onto an n-dimensional vector of numerical features.
One of the approaches we considered was to use an in-house scoring library. This library is essentially an inventory of data transformation and scoring modules, with a control flow that (1) generates a feature vector by performing a series of data transformations that parse a content record and create intermediate feature representations, and then (2) applies a regression (scoring) function to the feature vector and the model coefficient vector which is provided as input to the library. The result of the scoring function is the relevance score of the content record. Since FollowFeed scores millions of content records per second, we need the scoring function to be as efficient as possible. The data transformation steps in this library were heavy on iteration, hash-based lookups and intermediate data representation marshalling, thus these steps proved to be a bottleneck in achieving our latency SLA. At the same time, the ability to easily configure a few parameters to test and iterate through a variety of data transformations and relevance models implemented in a well-tested Java library was quite appealing. So, we came up with a new solution that retained the interface and configurability of this library, but made the implementation more efficient.
The solution was to auto-generate optimized Java code for the data transformation and scoring steps. The code generation mechanism can be thought of as being analogous to the optimization passes performed by a multi-pass compiler. However, a compiler’s optimization pass can strictly only observe the code flow without any knowledge of the inputs that may be provided to the program. Since we know the schemas of content records, and the exact data transformations and regressions that we need to perform, we can generate significantly optimized code that has certain assumptions about the input baked in. For the mobile feed use case, the optimized Java code takes about 50 microseconds (p99) to perform relevance computations on one content record, which is 15 times faster than the scoring library mentioned in the previous paragraph.
Ingestion Path
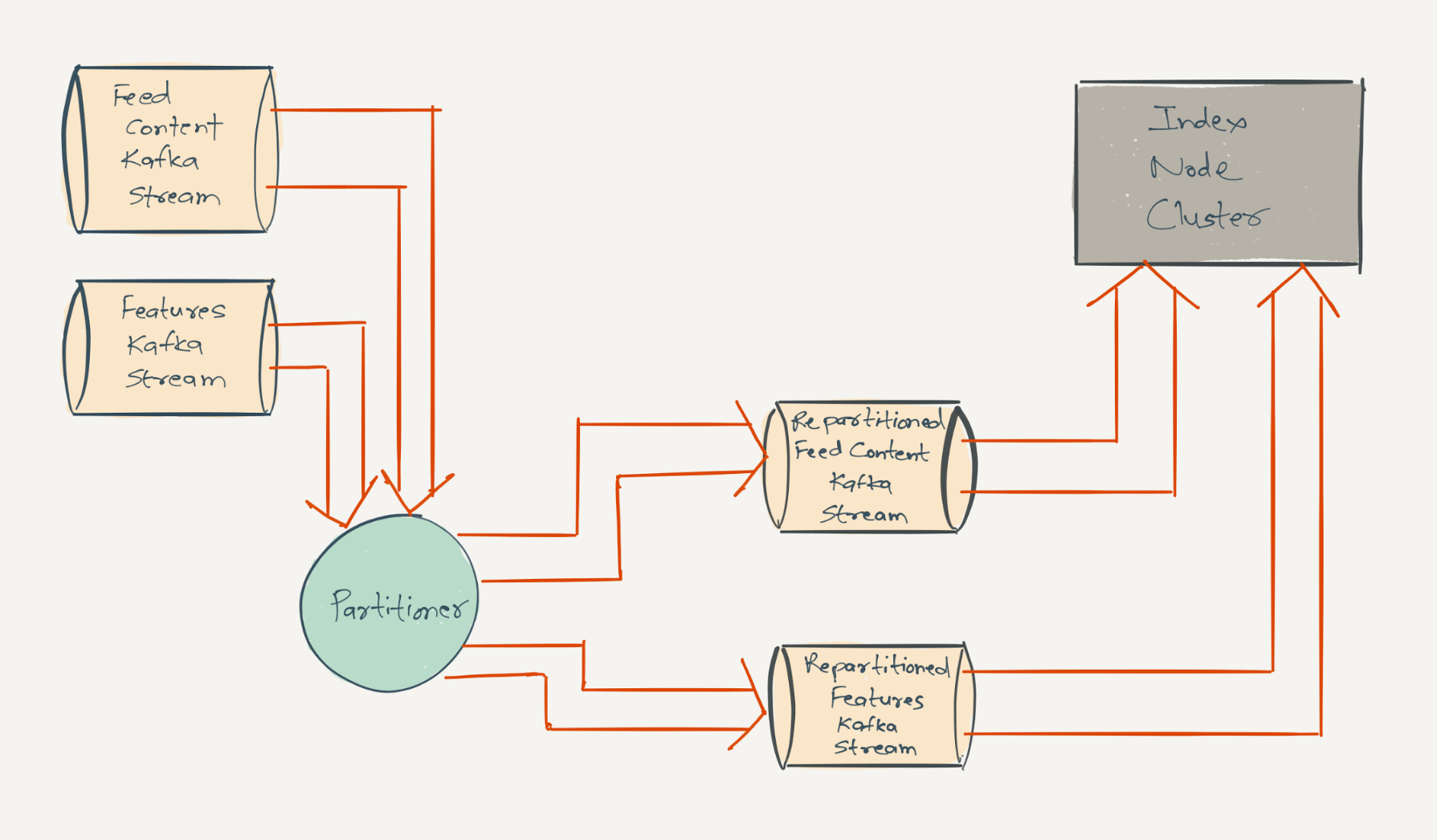
FollowFeed is designed to be eventually consistent, so all data ingestion is done asynchronously through Kafka. All the timeline data is present in a feed Kafka stream, which is a stream of all content records on LinkedIn—shares, likes, comments by members and by non-member entities such as companies, schools, etc. We have created an intermediary service called Partitioner, which consumes from the content record’s Kafka stream and republishes those events into another Kafka topic using a custom partitioning function. The resulting Kafka topic’s partition range matches the partition range of FollowFeed's index node cluster.
To consume timeline data, an index node simply subscribes to the same partition range of the Kafka topic as the partition range of timeline data that it’s hosting. The use of Kafka for data ingestion into index nodes allows us to consume the data for a given partition into multiple replica index nodes thereby allowing us to easily add more replicas for a given partition set. Relevance features are similarly re-partitioned and ingested from a different Kafka stream.
As we will see below, the ease of adding more replicas results in high availability and read scalability, since all replicas serve read traffic. Also as you can probably guess at this point, the custom partitioning function used to re-partition feed events on the ingestion path is the same as the partitioning function used to route real-time queries to index nodes.
Query Path
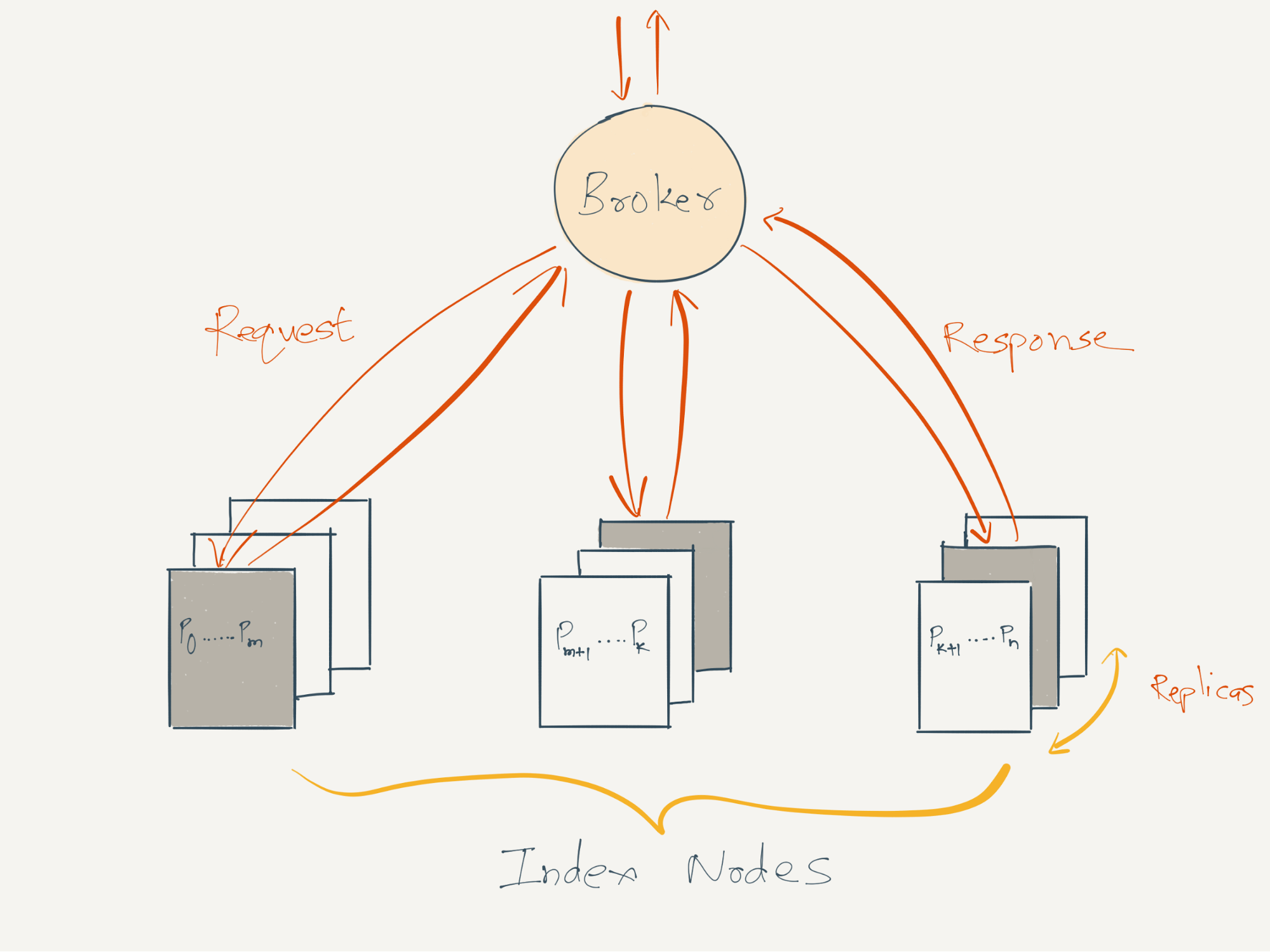
A feed query from a client is routed to the index nodes using a fan-out service called the
Broker. The broker receives feed requests from a midtier service, each request includes (1) a list of entities that are of interest to the viewer, (2) use case specific filtering criteria, (3) number of content records that should be returned, and (4) viewer specific data that would be used for use case specific filtering. The broker transmutes the entities and content types it received into timeline keys and packages these timeline keys into requests for the index nodes. These requests are fanned out to the index node cluster in two steps: (1) The broker determines a mapping between the timeline keys and the partitions they belong to using the same custom partitioning function which is used on the ingestion path. (2) The broker is aware of the mapping between partitions/replicas and index nodes via
D2, which is a library that provides name service and dynamic load balancing functionality using
Zookeeper. Thus, the broker can now fan out requests to the appropriate index node.
The request received by an index node includes (1) a list of timeline keys whose records needs to be retrieved, (2) time range of the records that should be considered for filtering and relevance scoring, (3) number of scored timeline records that should be returned, (4) viewer specific data that would be used for filtering and (5) use case specific filtering criteria. The index node performs a batch-get and retrieves a list of content records from the underlying cache/storage using these parameters. These records undergo business logic specific filtering, and then get scored and ranked using relevance function. From the resulting ranked list of records, the requested number of records with the highest scores are returned from each index node to the broker.
Replicas in the index node cluster are set up in master-master mode. So, all replicas serve real-time read traffic.
The broker then performs a pass of business logic specific deduplication and diversity related filtering. This additional pass of filtering (besides the filtering already performed by index nodes) is required to filter out records that are too similar to each other but were returned by different index nodes. Finally, the broker sorts the filtered list of records using relevance scores, and returns the requested number of records with the highest scores to the client.
Multi Data Center
In the multi-data center world, different viewers can be
sticky-routed to different data centers. It’s imperative that a viewer’s feed requests should be served as efficiently as possible—preferably from the data center that the viewer is sticky-routed to. This means that the timeline data of the entities that the viewer is interested in should be available in the data center locally. Since this set of entities keeps evolving continuously, we decided to replicate and store timeline data of all entities in all data centers. This is achieved by ingesting data from an aggregated Kafka stream that includes content records published from all data centers.
The size of FollowFeed’s index node clusters currently in production is primarily a function of the read traffic, so the index node cluster sizes can be different in different data centers according to the percentage of the read traffic being sticky-routed to those data centers. Each data center hosts the Partitioner service that consumes the feed updates' Kafka stream and re-partitions events. Similarly, the broker nodes routes queries to the appropriate index nodes according to the index node cluster configuration in that specific data center.
A/B Testing
A/B testing support is baked through-out the FollowFeed stack by integrating with
XLNT—Linkedin’s A/B testing platform. We routinely A/B test multiple relevance models at the same time on different segments of the members, a relevance model can be chosen per viewer using a variety of criteria.
Operations: Debugging and Performance
Besides read scalability, A/B testing support, etc., a key focus during building FollowFeed was to bake operability into the system before it was launched in production.
This started with treating the persisted state mission critical and translated into the following requirements:
- Monitoring of state: Monitoring includes real-time breakdown of the characteristics of data such as the count/rate of different content types, content types in cache versus persisted state, and also alerts on the state to catch any significant departures from the norms, etc.
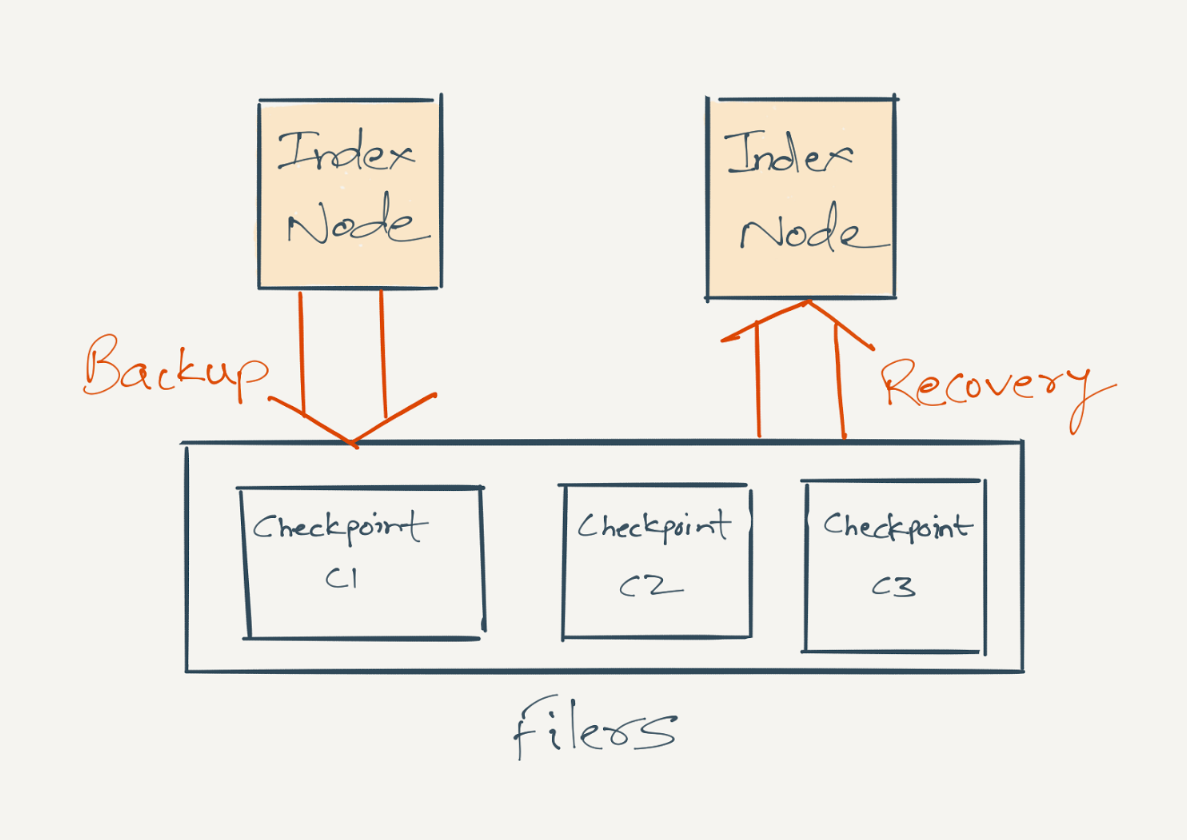
- Recovery: Every stateful system needs the right tools to recover from state corruption. We implement this through reliable checkpointing of timeline data and recovery through backups. Data on individual storage nodes is backed up incrementally at fixed intervals to network-attached storage filers, which provide reliability through data redundancy. Backups are used to bootstrap index nodes, to bring FollowFeed clusters in new data centers online, create more replicas, etc. We also backup Kafka consumer's offsets so that during recovery, the index node can consume from Kafka from the right log offset.
- Reliable admin tools: One-off admin tasks that affect the state should not result in outages. Tools for cluster rebalancing and re-sizing have been designed such that in case of errors the intermediate states can be safely rolled back. These tools are also continuously tested in the staging environment. We also have well-tested admin commands to retrieve and manage the state on the index nodes such as commands to (1) obtain data from the cache or the database for a specified member id, content type and time range, (2) delete cherry-picked data from the cache and/or database, (3) delete the caches entirely, (4) turn the kafka consumption on or off, etc. These tools and commands are dummy-proofed using sufficient warnings and override requirements.
Predictable Performance 24x7
- To ensure that disk and network heavy operations such as backups do not interfere with real-time performance, we have a dedicated a set of index nodes that are used only for ingesting and backing up data. These nodes do not serve real-time traffic and are used for periodic backups. These nodes also host more partitions than the nodes that are serving real-time traffic.
- The request/response loop between the broker and index nodes is asynchronous, which helps utilize broker threads more efficiently.
- We have set an SLA on the p99 latency at the broker. If a request to the broker resulted in a request fan-out to n number of index nodes, then the broker needs to wait for responses from all of these n index nodes. In this case, higher latencies at any of these index nodes impacts the latency at the broker. To optimize this, we have put a lot of emphasis on optimizing the index node’s performance through Read-Copy-Update synchronization, concurrency control through fine-grained locking, garbage generation and collection optimization, Java cache and RocksDB configuration, TCP tunings, avoiding connection churn, page flush and swappiness optimization, etc.
- To further mitigate the impact of higher latency percentiles at the index nodes, the broker fires duplicate requests to 1, 2, or 3 replica index nodes (all of these nodes are hosting the same set of partitions) with appropriate time-outs inserted between firing of each duplicate request. The Broker waits for responses from each of the duplicate requests and terminates the in-flight requests as soon as a response is received.
- We leverage D2 to gracefully degrade performance in case a node gets overwhelmed with queries or its performance degrades during normal operations. D2 assigns and dynamically evaluates certain scores per broker and index node, and drops requests if the score drops below a pre-configured threshold.
- Performance regressions are caught as early as possible: We log and plot timeouts and errors, and there are routine performance tests before deploying newer builds to production that compare timeouts and errors of the new build against the last known good build.
- Email alerts are fired if the quality of service degrades in production due to decrease in throughput, increase in latency, exceptions, etc.
- At times, systems see performance and timeout issues for certain requests that are not reflected in the percentile graphs. One functionality that has helped us immensely in tracking down such corner case performance (and functionality) issues is to enable TRACE level logging for certain viewers’ requests using a dynamic config. The viewer specific logging also avoids log spam and a sudden drop in performance that typically happens when log levels are changed for the entire process through a JMX “backdoor” call.
Conclusion
LinkedIn's newsfeed has come a long way, from just being a chronological set of records to using complex relevance algorithms to rank these records. To cater to these requirements and to support more feed queries due to an increasing user base, LinkedIn's newsfeed infrastructure has changed significantly during this time—from a generic search based solution to a more feed-optimized indexing solution. We recently finished ramping all traffic from Sensei-based architecture to FollowFeed and we have seen significant improvement in key metrics:
- FollowFeed’s p99 latency for the mobile news feed is around 140ms which is five times faster than Sensei. As a result of this, we also saw 150ms improvement in p90 page load latency.
- FollowFeed can host roughly 20 times more data than Sensei.
- FollowFeed migration resulted in reducing overall capex cost by 50 percent compared to Sensei.