https://io-meter.com/2017/08/06/from-immutable-to-lsmt/
 Push
Push
 Immutable Tree
Immutable Tree
Immutable Stack
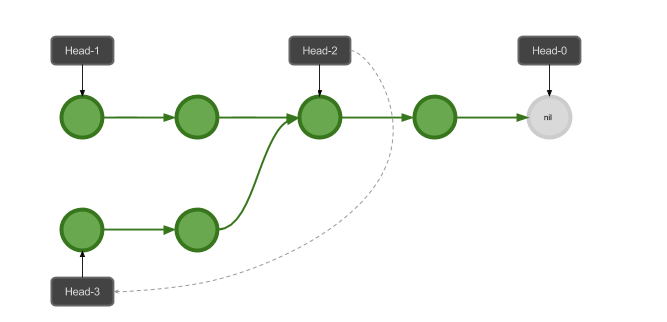
首先来看第一个例子。我们知道 Stack (栈)是一种先进后出的容器,它支持两种基本操作:
- 在栈顶插入一个元素
- 从栈顶取出一个元素
在这个基础上,我们想要实现另外两个功能,从而使得我们的栈具有实现撤销功能(或者说快速查询之前版本的能力)。 具体来说就是:
- 每一次插入和删除操作之后,可以为当前栈中元素的内容指定一个 History ID
- 指定之前的某一个 History ID,可以快速的恢复栈在那一时刻包含元素的状态
从新的位置开始插入其它的元素呢?其实只是在栈中开启一个新的分支:
Push
可以看到,我们的 Immutable Stack 相比传统链栈的实现,唯一的区别就是每次改变 HEAD 指针的时候, 我们都用构造一个新的指针来代替,这样通过原来的 HEAD 指针,我们访问到的总是栈在原来时刻的状态, 而从新的指针开始,得到的就是新的状态了。
这一实现方案可以说是相当优雅的。为了实现纪录历史的功能,我们每次操作只多消耗一个 HEAD 指针的空间。 我们把这些 HEAD 指针保存在某一容器中,未来就可以通过其与 History ID 的对应关系来查找它们, 而恢复一个 History ID 所指代的状态快照,只需要从对应的 HEAD 指针开始访问就好了,是一个非常省时且简单的操作。
Immutable Tree
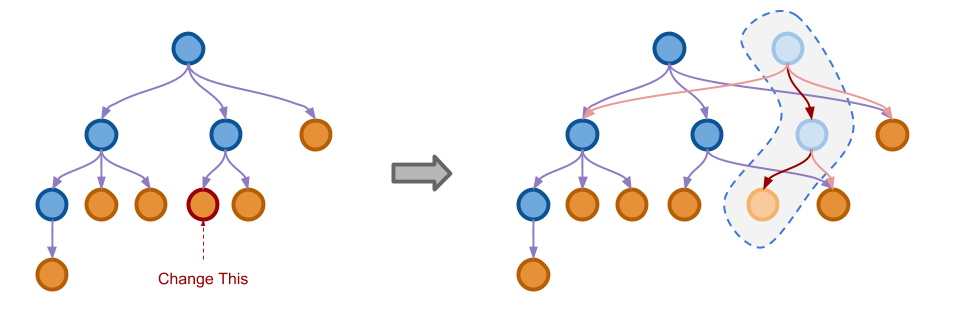
在很多应用中,除了上面的三种操作,撤销功能也是非常重要的。也就是说,我们有时候想要容易地将树的状态恢复到之前的一个纪录。 如前文所述,由于不可变数据结构每次都会产生新的对象,它的一大应用就是实现撤销的功能。但是对于一棵树来说, 如果每次都把每个节点复制并保存下来,在时间和空间花费上都非常不经济。这个问题就是我们的 Immutable Tree 数据结构要解决的问题。
下图展示了解决空间消耗问题的一种思路:
Immutable Tree
可以看到,当左边树的一个叶子节点被修改之后,我们既不全盘复制所有的节点,也不在原来的节点上进行修改, 而是仅仅将被修改位置一直到根节点的一条路径复制出来再进行修改。在右边虚线圈中的几个节点就是新生成的节点, 这些节点仍然会有指向原来节点的指针,只有被修改路径上的指针是指向新的节点。
使用这种技巧,每次我们只会复制一条路径上的几个节点,比复制全部节点已经有很大提高了。 新产生的对象和原来的对象共享了绝大部分内部节点,而每次修改一定会产生一个新的根节点。 使用不同的根节点作为开始,我们访问到的就是树在不同时刻的状态。
关于无锁数据结构(Lock-free Data Structure)的一些知识是必要的。
简单来说,无锁数据结构是一类可以安全地使用多线程并发访问和修改的数据结构, 而它们从设计上避免使用锁这一同步工具,在某些应用场合下相比使用加锁的数据结构具有更好的访问性能, 也避免了因为锁的存在而产生的死锁和 CPU 停顿问题,因此被广泛应用于强并发、高实时性要求的领域