Rows are Ordered by key in Memtable. and then columns corresponding to a row key are also ordered.
The Local Coordinator
The local coordinator receives the write request from the client and performs the following:
Firstly, the local coordinator determines which nodes are responsible for storing the data:
The first replica is chosen based on hashing the primary key using the Partitioner; Murmur3Partitioner is the default.
Other replicas are chosen based on the replication strategy defined for the keyspace. In a production cluster this is most likely the NetworkTopologyStrategy.
The local coordinator determines whether the write request would modify an associated materialized view.
If write request modifies materialized view
When using materialized views it’s important to ensure that the base table and materialized view are consistent, i.e. all changes applied to the base table MUST be applied to the materialized view. Cassandra uses a two-stage batch log process for this:
one batch log on the local coordinator ensuring that an update is made on the base table to a Quorum of replica nodes
one batch log on each replica node ensuring the update is made to the corresponding materialized view.
The process on the local coordinator looks as follows:
Create batch log. To ensure consistency, the batch log ensures that changes are applied to a Quorum of replica nodes, regardless of the consistently level of the write request. Acknowledgement to the client is still based on the write request consistency level.
The write request is then sent to all replica nodes simultaneously.
If write request does not modify materialized view
The write request is then sent to all replica nodes simultaneously.
In both cases the total number of nodes receiving the write request is determined by the replication factor for the keyspace.
Replica Nodes
Replica nodes receive the write request from the local coordinator and perform the following:
Write data to the Commit Log. This is a sequential, memory-mapped log file, on disk, that can be used to rebuild MemTables if a crash occurs before the MemTable is flushed to disk.
Write data to the MemTable. MemTables are mutable, in-memory tables that are read/write. Each physical table on each replica node has an associated MemTable.
If the write request is a DELETE operation (whether a delete of a column or a row), a tombstone marker is written to the Commit Log and MemTable to indicate the delete.
If row caching is used, invalidate the cache for that row. Row cache is populated on read only, so it must be invalidated when data for that row is written.
Acknowledge the write request back to the local coordinator.
The local coordinator waits for the appropriate number of acknowledgements from the replica nodes (dependent on the consistency level for this write request) before acknowledging back to the client.
If write request modifies materialized view
Keeping a materialized view in sync with its base table adds more complexity to the write path and also incurs performance overheads on the replica node in the form of read-before-write, locks and batch logs.
The replica node acquires a lock on the partition, to ensure that write requests are serialised and applied to base table and materialized views in order.
The replica node reads the partition data and constructs the set of deltas to be applied to the materialized view. One insert/update/delete to the base table may result in one or more inserts/updates/deletes in the associated materialized view.
Write data to the Commit Log.
Create batch log containing updates to the materialized view. The batch log ensures the set of updates to the materialized view is atomic, and is part of the mechanism that ensures base table and materialized view are kept consistent.
Store the batch log containing the materialized view updates on the local replica node.
Send materialized view updates asynchronously to the materialized view replica (note, the materialized view partition could be stored on the same or a different replica node to the base table).
The materialized view replica node will apply the update and return an acknowledgement to the base table replica node.
The same process takes place on each replica node that stores the data for the partition key.
Flushing MemTables
MemTables are flushed to disk based on various factors, some of which include:
commitlog_total_space_in_mb is exceeded
memtable_total_space_in_mb is exceeded
‘Nodetool flush’ command is executed
Etc.
Each flush of a MemTable results in one new, immutable SSTable on disk. After the flush, an SSTable (Sorted String Table) is read-only. As with the write to the Commit Log, the write to the SSTable data file is a sequential write operation. An SSTable consists of multiple files, including the following:
Serialise and write the data to the SSTable Data File
Write the Compression File (if compression is used)
Write the Statistics File
Purge the written data from the Commit Log
Unavailable Replica Nodes and Hinted Handoff
When a local coordinator is unable to send data to a replica node due to the replica node being unavailable, the local coordinator stores the data either in its local system.hints table (prior to Cassandra v3.0) or in a local flat file (from Cassandra v3.0 onwards); this process is known as Hinted Handoff and is configured in cassandra.yaml. Hint data is stored for a default period of 3 hours, configurable using the max_hint_window_in_ms property in cassandra.yaml. If the replica node comes back online within the hinted handoff window the local coordinator will send the data to the replica node, otherwise the hint data is discarded and the replica node will need to be repaired.
Write Path Advantages
The write path is one of Cassandra’s key strengths: for each write request one sequential disk write plus one in-memory write occur, both of which are extremely fast.
During a write operation, Cassandra never reads before writing (with the exception of Counters and Materialized Views), never rewrites data, never deletes data and never performs random I/O.
When a write occurs, Cassandra stores the data in a memory structure called memtable, and to provideconfigurable durability, it also appends writes to the commit log on disk. The commit log receives every write made to a Cassandra node, and these durable writes survive permanently even if power fails on a node. The memtable is a write-back cache of data partitions that Cassandra looks up by key. The memtable stores writes in sorted order until reaching a configurable limit, and then is flushed.
Cassandra is a column-family* store. A column-family store ensures data locality at the partition level, not the column level. In a database like Cassandra a partition is a group of rows and columns split up by a specified partition key, then clustered together by specified clustering column(s) (optional). To query Cassandra, you must know, at a minimum, the partition key in order to avoid full scans of your data.
All data for a given partition in Cassandra is guaranteed to be on the same node and in a given file (SSTable) in the same location within that file. The one thing to note here is that depending on your compaction strategy, the partition can be split across multiple files on disk, so data locality on disk is not a guarantee.
Column stores lend themselves to, and are designed for, analytic workloads. Because each column is in the same location on disk, they can read all information for a given column across many/all rows incredibly fast. This comes at the cost of very slow writes which usually need to be done in batch loads to avoid drastic performance implications.
Column-family stores,like Cassandra, are a great choice if you have high throughput writes and want to be able to linearly scale horizontally. Reads that use the partition key are incredibly fast as the partition key defines where the data resides. The downfall here is that if you need to do any sort of ad-hoc query, a full scan of all data is required.
* The term "column-family" comes from the original storage engine that was a key/value store, where the value was a "family" of column/value tuples. There was no hard limit on the number of columns that each key could have. In Cassandra this was later abstracted into "partitions", then eventually the storage engine was modified to match the abstraction.
After investigation, we found the JVM garbage collector (GC) contributed a lot to the latency spikes. We defined a metric called GC stall percentage to measure the percentage of time a Cassandra server was doing stop-the-world GC (Young Gen GC) and could not serve client requests. Here’s another graph that shows the GC stall percentage on our production Cassandra servers. It was 1.25% during the lowest traffic time windows, and could be as high as 2.5% during peak hours.
Apache Cassandra is a distributed database with it’s own LSM tree-based storage engine written in Java. We found that the components in the storage engine, like memtable, compaction, read/write path, etc., created a lot of objects in the Java heap and generated a lot of overhead to JVM. To reduce the GC impact from the storage engine, we considered different approaches and ultimately decided to develop a C++ storage engine to replace existing ones.
We did not want to build a new storage engine from scratch, so we decided to build the new storage engine on top of RocksDB.
Consistency levels in Cassandra can be configured to manage availability versus data accuracy. You can configure consistency on a cluster, datacenter, or per individual read or write operation. Consistency among participating nodes can be set globally and also controlled on a per-operation basis. Within cqlsh, use CONSISTENCY, to set the consistency level for all queries in the current cqlsh session. For programming client applications, set the consistency level using an appropriate driver. For example, using the Java driver, call QueryBuilder.insertInto with setConsistencyLevel to set a per-insert consistency level.
Used in multiple datacenter clusters to strictly maintain consistency at the same level in each datacenter. For example, choose this level if you want a read to fail when a datacenter is down and the QUORUM cannot be reached on that datacenter.
QUORUM
A write must be written to the commit log and memtable on a quorum of replica nodes across all datacenters.
Used in either single or multiple datacenter clusters to maintain strong consistency across the cluster. Use if you can tolerate some level of failure.
LOCAL_QUORUM
Strong consistency. A write must be written to the commit log and memtableon a quorum of replica nodes in the same datacenter as the coordinator. Avoids latency of inter-datacenter communication.
Used in multiple datacenter clusters with a rack-aware replica placement strategy, such as NetworkTopologyStrategy, and a properly configured snitch. Use to maintain consistency locally (within the single datacenter). Can be used withSimpleStrategy.
A write must be sent to, and successfully acknowledged by, at least one replica node in the local datacenter.
In a multiple datacenter clusters, a consistency level of ONE is often desirable, but cross-DC traffic is not. LOCAL_ONE accomplishes this. For security and quality reasons, you can use this consistency level in an offline datacenter to prevent automatic connection to online nodes in other datacenters if an offline node goes down.
ANY
A write must be written to at least one node. If all replica nodes for the given partition key are down, the write can still succeed after a hinted handoff has been written. If all replica nodes are down at write time, an ANY write is not readable until the replica nodes for that partition have recovered.
Provides low latency and a guarantee that a write never fails. Delivers the lowest consistency and highest availability.
Read Consistency Levels
Level
Description
Usage
ALL
Returns the record after all replicas have responded. The read operation will fail if a replica does not respond.
Provides the highest consistency of all levels and the lowest availability of all levels.
EACH_QUORUM
Not supported for reads.
QUORUM
Returns the record after a quorum of replicas from all datacenters has responded.
Used in either single or multiple datacenter clusters to maintain strong consistency across the cluster. Ensures strong consistency if you can tolerate some level of failure.
LOCAL_QUORUM
Returns the record after a quorum of replicas in the current datacenter as the coordinator has reported. Avoids latency of inter-datacenter communication.
Used in multiple datacenter clusters with a rack-aware replica placement strategy (NetworkTopologyStrategy) and a properly configured snitch. Fails when using SimpleStrategy.
ONE
Returns a response from the closest replica, as determined by the snitch. By default, a read repair runs in the background to make the other replicas consistent.
Provides the highest availability of all the levels if you can tolerate a comparatively high probability of stale data being read. The replicas contacted for reads may not always have the most recent write.
TWO
Returns the most recent data from two of the closest replicas.
Similar to ONE.
THREE
Returns the most recent data from three of the closest replicas.
Similar to TWO.
LOCAL_ONE
Returns a response from the closest replica in the local datacenter.
Same usage as described in the table about write consistency levels.
SERIAL
Allows reading the current (and possibly uncommitted) state of data without proposing a new addition or update. If a SERIAL read finds an uncommitted transaction in progress, it will commit the transaction as part of the read. Similar to QUORUM.
To read the latest value of a column after a user has invoked a lightweight transactionto write to the column, use SERIAL. Cassandra then checks the inflight lightweight transaction for updates and, if found, returns the latest data.
LOCAL_SERIAL
Same as SERIAL, but confined to the datacenter. Similar to LOCAL_QUORUM.
INSERT and UPDATE statements using the IF clause support lightweight transactions, also known as Compare and Set (CAS). A common use for lightweight transactions is an insertion operation that must be unique, such as a cyclist's identification. Lightweight transactions should not be used casually, as the latency of operations increases fourfold due to the due to the round-trips necessary between the CAS coordinators.
Cassandra supports non-equal conditions for lightweight transactions. You can use <, <=, >, >=, != and IN operators in WHERE clauses to query lightweight tables.
It is important to note that using IF NOT EXISTS on an INSERT, the timestamp will be designated by the lightweight transaction, and USING TIMESTAMP is prohibited.
Perform a CAS operation against a row that does exist by adding the predicate for the operation at the end of the query. For example, reset Roxane Knetemann's firstname because of a spelling error.
cqlsh> UPDATE cycling.cyclist_name
SET firstname = ‘Roxane’
WHERE id = 4647f6d3-7bd2-4085-8d6c-1229351b5498IF firstname = ‘Roxxane’;
Note: You can also use IF EXISTS or any other IF <CONDITION>.
UPDATEpayments SETamount = 10.00
WHEREpayment_date = 2016-11-02 12:23:34Z
ANDcustomer_id = 123
IF amount = 12.00
This simple IF NOT EXISTS isn’t free. Under the hood it triggers a lightweight transaction (also known as CAS for Compare And Set).
It’s called lightweight because it doesn’t imply locking as it’s the case in traditional (SQL) databases.
Lightweight doesn’t mean free either. In fact such queries require a read and a write and they also need to reach consensus among all the replicas.
In Cassandra the consensus is reached by implementing the Paxos algorithm
The leader role is not a master role (any node can act as a leader or more accurately as a proposer).
Briefly the proposer picks a proposal number and sends it to the participating replicas. (Remember the number of replicas is determined by the keyset’s replication factor). If the proposal number is the highest the replica has seen, the replica promises to not accept any earlier proposal (i.e. a proposal with a smaller number).
If the majority promises to accept the proposal, the leader may proceed with its proposal. However if a replica replies with another value for that proposal it’s the value the leader must propose.
This gives the linearisable or serial property because if a leader interrupts an on-going proposal it must complete it before proposing its own value.
Cassandra uses Paxos to implement a Compare-And-Set operation so it needs to intertwin read and writes into the Paxos protocol.
SERIAL CONSISTENCY LEVELS
The read consistency is called the serial consistency and is set using the SERIAL CONSISTENCY command. It can take only 2 values:
SERIAL
LOCAL_SERIAL
The only difference is when Cassandra uses several datacenters. LOCAL_SERIAL runs Paxos only in the local datacenter whereas SERIAL runs it accross all datacenters.
The SERIAL CONSISTENCY command is only available for conditional updates (UPDATE or INSERT with the IF statement).
The last thing is if we want to consider any on-going lightweight transactions when reading a value. In this case we want to read the value of any on-going transaction.
This can be done by setting the read consistency level to SERIAL. This is the regular consistency level, the one set with the CONSISTENCY command (not the serial consistency) and it applies to read queries only (i.e. SELECT statements).
Remove an element from a set using the subtraction (-) operator.
cqlsh> UPDATE cycling.cyclist_career_teams
SET teams = teams - {'WOMBATS - Womens Mountain Bike & Tea Society'} WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;
Remove all elements from a set by using the UPDATE or DELETE statement.
A set, list, or map needs to have at least one element because an empty set, list, or map is stored as a null set.
cqlsh> UPDATE cyclist.cyclist_career_teams SET teams = {} WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;DELETE teams FROM cycling.cyclist_career_teams WHERE id = 5b6962dd-3f90-4c93-8f61-eabfa4a803e2;
http://distributeddatastore.blogspot.com/2013/07/cassandra-using-merkle-trees-to-detect.html Cassandra's implementation of Merkle tree (org.apache.cassandra.utils.MerkleTree) uses perfect binary tree where each leaf contains the hash of a row value and each parent node contains hash of its right and left child. In a perfect binary tree all the leaves are at the same level or at same depth. A perfect binary tree of depth h contains 2^h leaves. In other terms if a range contains n tokens then the Merkle tree representing it contains log(n)levels.
When nodetool repair command is executed, the target node specified with -h option in the command, coordinates the repair of each column family in each keyspace. A repair coordinator node requests Merkle tree from each replica for a specific token range to compare them. Each replica builds a Merkle tree by scanning the data stored locally in the requested token range. The repair coordinator node compares the Merkle trees and finds all the sub token ranges that differ between the replicas and repairs data in those ranges.
A replica node builds a Merkle tree for each column family to represent hashes of rows in a given token range. A token range can contain up to 2^127 tokens when RandomPartitioner is used. Merkle tree of depth 127 is required which contains 2^127 leaves. Cassandra builds a compact version of Merkle tree of depth 15 to reduce the memory usage to store the tree and to minimize the amount of data required to transfer Merkle tree to another node. It expands the tree until a given token range is split in to 32768 sub ranges. In the compact version of tree, each leaf represents hash of all rows in its respective sub range. Regardless of their size and split, two Merkle trees can be compared if they have same hash depth.
For example, the token range (0, 256], contains 256 sub ranges (0, 1], (1, 2]...(255, 256] each containing single token. A perfect binary tree of depth 8 is required to store all 256 sub range hashes at leaves. A compact version of tree with depth 3 for the same range contains only 8 leaves representing hashes of sub ranges (0, 32], (32, 64] ... (224, 256] each containing 32 tokens. Each leaf hash in this compact version of tree is a computed hash of all the nodes under it in the perfect binary tree of depth 8.
RandomPartitioner distributes keys uniformly , so the Merkle tree is constructed recursively by splitting the given token range in to two equal sub ranges until maximum number of sub ranges are reached. A root node is added with the given token range (left, right] and the range is split in to two halves at a token which is at the midpoint of the range. A left child node is added with range (left, midpoint] and a right child node is added with range covering (midpoint, right]. The process is repeated until required number of leaves (sub ranges) added to the tree.
Next row hashes are added to the Merkle tree in sorted order. Each row's hash value is computed by calculating MD5 digest of row value which includes row's column count, column names and column values but not the row key and row size. The deleted rows (tombstones) hashes are also added to the tree which include the delete timestamps. Row hashes are added to Merkle tree leaves based on their tokens. If a leaf's sub range contains multiple rows, its hash is computed by combining hashes of all rows covered by its range using XOR operation. Non leaf nodes hashes are computed by performing XOR on hashes of their respective children.
Comparing Merkle trees
Two Merkle trees are compared if both of them cover the same token range regardless of their size. The trees are compared recursively starting at root hash. If root hashes match in both the trees then all the data blocks in the tree's token range are consistent between replicas. If root hashes disagree, then the left child hashes are compared followed next by right child hashes. The comparison proceeds until all the token ranges that differ between the two trees are calculated. https://wiki.apache.org/cassandra/AntiEntropy
The key difference in Cassandra's implementation of anti-entropy is that the Merkle trees are built per column family, and they are not maintained for longer than it takes to send them to neighboring nodes. Instead, the trees are generated as snapshots of the dataset during major compactions: this means that excess data might be sent across the network, but it saves local disk IO, and is preferable for very large datasets.
Merkle trees limit the amount of data transferred when synchronizing. The general assumptions are:
Network I/O is more expensive than local I/O + computing the hashes.
Transferring the entire sorted key space is more expensive than progressively limiting the comparison over several steps.
The key spaces have fewer discrepancies than similarities.
As a consequence of the new tool's verbose output, the output payload is less compact than sstable2json. However, the enriched structure of the 3.0 storage engine, is displayed. What is apparent is that there is less repeated data, which leads to a dramatically reduced SSTable storage footprint.
Looking at the output, note that clustering, timestamp and ttl information are now presented at the row level, instead of repeating in individual cells. This change is a large factor in optimizing disk space. While column names are present in each cell, the full column names are not stored for each cell as previously
sstabledump’s JSON representation is more verbose than sstable2json. sstabledump also provides an alternative ‘debug’ output format that is more concise than its json counterpart. While initially difficult to understand, it is a more compact and convenient format for advanced users to grok the contents of an SSTable.
The number you refer to is the number of the SSTable (I think it is technically called generation). Specifically, the format of the filename is:
CFName-Generation-SSTableFormat-ComponentFile
In you case:
CFName = la
Generation = 275x
SSTableFormat = BIG
ComponentFile = Data.db, TOC.txt, etc...
You can't really tell if the last SSTable contains all the data you need. The space on disk consumed by old generations may be released only if data in not referenced anymore (snapshots comes to mind), and their tombstones age is greater than the gc_grace_seconds.
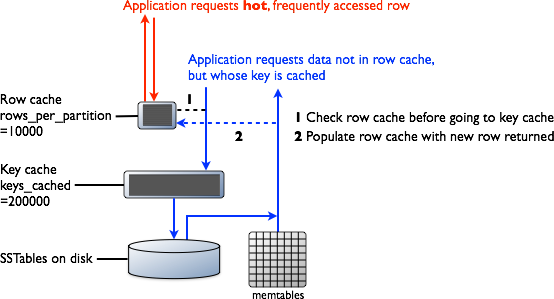
Cache in C* https://teddyma.gitbooks.io/learncassandra/content/caching/data_caching.html Cassandra includes integrated caching and distributes cache data around the cluster for you. The integrated cache solves the cold start problem by virtue of saving your cache to disk periodically and being able to read contents back in when it restarts. So you never have to start with a cold cache.
How Does Caching Work?
2One read operation hits the row cache, returning the requested row without a disk seek. The other read operation requests a row that is not present in the row cache but is present in the partition key cache. After accessing the row in the SSTable, the system returns the data and populates the row cache with this read operation.
Logically separate heavily-read data into discrete tables.
Key caching is enabled by default in Cassandra, and high levels of key caching are recommended for most scenarios. Cases for row caching are more specialized, but whenever it can coexist peacefully with other demands on memory resources, row caching provides the most dramatic gains in efficiency.
Key Cache
The key cache holds the location of keys in memory on a per-column family basis. For column family level read optimizations, turning this value up can have an immediate impact as soon as the cache warms. Key caching is enabled by default, at a level of 200,000 keys.
Row Cache
Unlike the key cache, the row cache holds the entire contents of the row in memory. It is best used when you have a small subset of data to keep hot and you frequently need most or all of the columns returned. For these use cases, row cache can have substantial performance benefits.
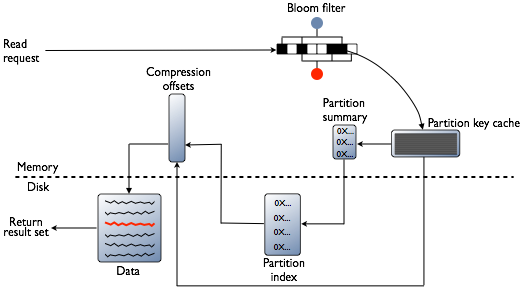
To understand the role of this cache, we must remind how data lookup is made by Cassandra. The read request arrives first to Bloom filter. It decides if needed data can be stored in one of managed SSTables. If it's not the case, the action stops. If it is, Cassandra asks partition key cache where partition holding the data begins in the SSTables. Thanks to that, Cassandra goes directly to the row containing expected data. Without the use of key cache, Cassandra should look first at index and scan in to find good key range for the queried data.
Row caching in Cassandra
The second type of cache concerns all columns of data and it's called row cache. It puts a part of partition into memory. In consequence, if asked data is already kept in row cache, Cassandra doesn't make operations described previously (asking key cache, reading row from disk).
However, row cache should be used carefully. First of all, if one of stored rows changes, it and its partition must be invalidated from cache. So, row cache should privilege rows frequently read but not frequently modified. In additional, in the versions before 2.1, row cache worked by whole partition. It means that whole partition had to be stored in the cache. And if its size was bigger than the size of available cache memory, the row never was cached. Since 2.1 release, it has changed. Now we can configure row cache to kept only specific number of rows.
Counter cache in Cassandra
Another cache type is counter cache, related to counter columns. Its role consists to help locks contention for frequently updated cells of counter type. As other cache types, this one is configurable in the same manne
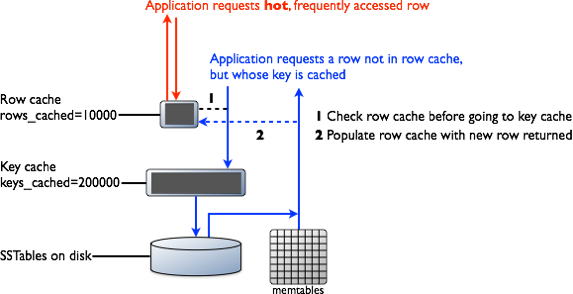
Key cache helps C* know where a particular partition begins in the SStables. This means that C* does not have to read anything to determine the right place to seek to in the file to begin reading the row. This is good for almost all use cases because it speeds up reads considerably by potentially removing the need for an IOP in the read-path.
Row Cache has a much more limited use case. Row cache pulls entire partitions into memory. If any part of that partition has been modified, the entire cache for that row is invalidated. For large partitions this means the cache can be frequently caching and invalidating big pieces of memory. Because you really need mostly static partitions for this to be useful, for most use cases it is recommended that you do not use Row Cache.
Checks if the in-memory memtable cache still contain the data (if it is not yet flushed to SSTable)
If enabled, row cache
BloomFilter (for each SSTable)
Key cache
Partition Summary
SSTables
A generic diagram that (I hope) summarize !
Cassandra read path diagram
A little vocabulary
SSTable
SSTables are immutable, not written to again after the memtable is flushed. Thus, a partition is typically stored across multiple SSTable files.
For each SSTables, cassandra create one Partition Index, Partition Summary and BloomFilter
Memtable
When a write occurs, Cassandra stores the data in a structure in memory, the memtable, and also appends writes to the commit log on disk. The memtable stores writes until reaching a limit, and then is flushed.
Cassandra flushes memtables to disk, creating SSTables when the commit log space threshold has been exceeded
Partition Index :
A list of primary keys and the start position of data
Partition summary
A subset of the partition index (in memory). By default, 1 partition key out of every 128 is sampled.
Caches
Row cache :
The row cache is similar to a traditional cache like memcached. When a row is accessed, the entire row is pulled into memory, merging from multiple SSTables if necessary, and cached, so that further reads against that row can be satisfied without hitting disk at all.
While storing the row cache off-heap, Cassandra has to deserialize a partition into heap to read from it, so we have to take care about partition size.
The row cache is not write-through. If a write comes in for the row, the cache for it is invalidated and is not be cached again until it is read again.
The Key Cache stores keys and their locations in each SStable in heap memory. Since keys are typically small, you can store a large cache without using much RAM.
Cassandra writes changed data (insert, update or delete columns) to a commitlog
Cassandra append changed data to commitlog
commitlog acts as a crash recovery log for data
Write operation will never consider successful at least until the changed data is appended to commitlog
Cassandra periodically sync the write-behind cache for commitlog to disk every CommitLogSyncPeriodInMS (Default: 1000ms)
The sequential write is fast since there is no disk seek time
Put commitlog in a separate drive to reduce I/O contention with SSTable reads/writes
Not easy to achieve in today's cloud computing offerings
Data will not be lost once commitlog is flushed out to file
Cassandra replay commitLog log after Cassandra restart to recover potential data lost within 1 second before the crash
Cassandra also writes the data to a in memory structure Memtable
Memtable is an in-memory cache with content stored as key/column
Memtable data are sorted by key
Each ColumnFamily has a separate Memtable and retrieve column data from the key
Flushing: Once Memtable is full, the sorted data is written out sequentially to disk as SSTables (Sorted String Table)
Flushed SSTable files are immutable and no changes cane be done
Numerous SSTables will be created on disk for a column family
Later changes to the same key after flushing will be written to a different SSTables
Row read therefore requires reading all existing SSTables for a Column Family to locate the latest value
SStables will be merged once it reaches some threshold to reduce read overhead
Each SSTable composes of 3 files
Bloom Filter: For read optimization, it determines whether this SSTable contains the requested key
Index: Index the data location by the key
Data: The column data
Unlike relational database, data changes does not write back to the original data files. It does not involve data read or random disk access. Both commitlog and SSTable are flushed to disk as a new file with sequential write. Hence Cassandra writes data very fast.
A file holding the CRC32 for chunks in an a uncompressed file.
SSTable Index Summary (SUMMARY.db)
A sample of the partition index stored in memory
SSTable Table of Contents (TOC.txt)
A file that stores the list of all components for the SSTable TOC
Secondary Index (SI_.*.db)
Built-in secondary index. Multiple SIs may exist per SSTable
The SSTables are files stored on disk. The naming convention for SSTable files has changed with Cassandra 2.2 and later to shorten the file path. The data files are stored in a data directory that varies with installation. For each keyspace, a directory within the data directory stores each table. For example,/data/data/ks1/cf1-5be396077b811e3a3ab9dc4b9ac088d/la-1-big-Data.db represents a data file. ks1 represents the keyspace name to distinguish the keyspace for streaming or bulk loading data. A hexadecimal string, 5be396077b811e3a3ab9dc4b9ac088d in this example, is appended to table names to represent unique table IDs.
Cassandra creates a subdirectory for each table, which allows you to symlink a table to a chosen physical drive or data volume. This provides the capability to move very active tables to faster media, such as SSDs for better performance, and also divides tables across all attached storage devices for better I/O balance at the storage layer.
Cassandra uses a storage structure similar to a Log-Structured Merge Tree, unlike a typical relational database that uses a B-Tree. Cassandra avoids reading before writing. Read-before-write, especially in a large distributed system, can result in large latencies in read performance and other problems. For example, two clients read at the same time; one overwrites the row to make update A, and the other overwrites the row to make update B, removing update A. This race condition will result in ambiguous query results - which update is correct?
To avoid using read-before-write for most writes in Cassandra, the storage engine groups inserts and updates in memory, and at intervals, sequentially writes the data to disk in append mode. Once written to disk, the data is immutable and is never overwritten. Reading data involves combining this immutable sequentially-written data to discover the correct query results. You can use Lightweight transactions (LWT) to check the state of the data before writing. However, this feature is recommended only for limited use.
https://docs.datastax.com/en/cassandra/3.0/cassandra/dml/dmlIndexInternals.html Non-primary keys play no role in ordering the data in storage, thus querying for a particular value of a non-primary key column results in scanning all partitions. Scanning all partitions generally results in a prohibitive read latency, and is not allowed.
Secondary indexes can be built for a column in a table. These indexes are stored locally on each node in a hidden table and built in a background process. If a secondary index is used in a query that is not restricted to a particular partition key, the query will have prohibitive read latency because all nodes will be queried. A query with these parameters is only allowed if the query option ALLOW FILTERING is used. This option is not appropriate for production environments. If a query includes both a partition key condition and a secondary index column condition, the query will be successful because the query can be directed to a single node partition.
This technique, however, does not guarantee trouble-free indexing, so know when and when not to use an index. In the example shown above, an index on the age could be used, but a better solution is to create a materialized view or additional table that is ordered by age.
As with relational databases, keeping indexes up to date uses processing time and resources, so unnecessary indexes should be avoided. When a column is updated, the index is updated as well. If the old column value still exists in the memtable, which typically occurs when updating a small set of rows repeatedly, Cassandra removes the corresponding obsolete index entry; otherwise, the old entry remains to be purged by compaction. If a read sees a stale index entry before compaction purges it, the reader thread invalidates it???.
The tombstones go through Cassandra's write path, and are written to SSTables on one or more nodes. The key difference feature of a tombstone: it has a built-in expiration date/time. At the end of its expiration period (for details see below) the tombstone is deleted as part of Cassandra's normal compaction process.
You can also mark a Cassandra record (row or column) with a time-to-live value. After this amount of time has ended, Cassandra marks the record with a tombstone, and handles it like other tombstoned records.
In a multi-node cluster, Cassandra can store replicas of the same data on two or more nodes. This helps prevent data loss, but it complicates the delete process. If a node receives a delete for data it stores locally, the node tombstones the specified record and tries to pass the tombstone to other nodes containing replicas of that record. But if one replica node is unresponsive at that time, it does not receive the tombstone immediately, so it still contains the pre-delete version of the record. If the tombstoned record has already been deleted from the rest of the cluster befor that node recovers, Cassandra treats the record on the recovered node as new data, and propagates it to the rest of the cluster. This kind of deleted but persistent record is called a zombie.
To prevent the reappearance of zombies, Cassandra gives each tombstone a grace period. The purpose of the grace period is to give unresponsive nodes time to recover and process tombstones normally. If a client writes a new update to the tombstoned record during the grace period, Cassandra overwrites the tombstone. If a client sends a read for that record during the grace period, Cassandra disregards the tombstone and retrieves the record from other replicas if possible.
When an unresponsive node recovers, Cassandra uses hinted handoff to replay the database mutationsthe node missed while it was down. Cassandra does not replay a mutation for a tombstoned record during its grace period. But if the node does not recover until after the grace period ends, Cassandra may miss the deletion.
After the tombstone's grace period ends, Cassandra deletes the tombstone during compaction.
The grace period for a tombstone is set by the property gc_grace_seconds. Its default value is 864000 seconds (ten days). Each table can have its own value for this property.
https://docs.datastax.com/en/cassandra/3.0/cassandra/dml/dmlWritePatterns.html It is important to consider how the write operations will affect the read operations in the cluster. The type of compaction strategy Cassandra performs on your data is configurable and can significantly affect read performance. Using the SizeTieredCompactionStrategy or DateTieredCompactionStrategy tends to cause data fragmentation when rows are frequently updated. The LeveledCompactionStrategy (LCS) was designed to prevent fragmentation under this condition. https://teddyma.gitbooks.io/learncassandra/content/model/where_is_data_stored.html For efficiency, Cassandra does not repeat the names of the columns in memory or in the SSTable???
Over time, Cassandra may write many versions of a row in different SSTables. Each version may have a unique set of columns stored with a different timestamp. As SSTables accumulate, the distribution of data can require accessing more and more SSTables to retrieve a complete row.
The Write Path
When a write occurs, Cassandra stores the data in a structure in memory, the memtable, and also appends writes to the commit log on disk.
The memtable is a write-back cache of data partitions that Cassandra looks up by key. The more a table is used, the larger its memtable needs to be. Cassandra can dynamically allocate the right amount of memory for the memtable or you can manage the amount of memory being utilized yourself. The memtable, unlike a write-through cache, stores writes until reaching a limit, and then is flushed.
When memtable contents exceed a configurable threshold, the memtable data, which includes indexes, is put in a queue to be flushed to disk. To flush the data, Cassandra sorts memtables by partition key and then writes the data to disk sequentially. The process is extremely fast because it involves only a commitlog append and the sequential write.
Data in the commit log is purged after its corresponding data in the memtable is flushed to the SSTable. The commit log is for recovering the data in memtable in the event of a hardware failure.
SSTables are immutable, not written to again after the memtable is flushed. Consequently, a partition is typically stored across multiple SSTable files So, if a row is not in memtable, a read of the row needs look-up in all the SSTable files??. This is why read in Cassandra is much slower than write.
Periodically, the rows stored in memory are streamed to disk into structures called SSTables. At certain intervals, Cassandra compacts smaller SSTables into larger SSTables. If Cassandra encounters two or more versions of the same row during this process, Cassandra only writes the most recent version to the new SSTable. After compaction, Cassandra drops the original SSTables, deleting the outdated rows.
Most Cassandra installations store replicas of each row on two or more nodes. Each node performs compaction independently. This means that even though out-of-date versions of a row have been dropped from one node, they may still exist on another node.
This is why Cassandra performs another round of comparisons during a read process. When a client requests data with a particular primary key, Cassandra retrieves many versions of the row from one or more replicas. The version with the most recent timestamp is the only one returned to the client ("last-write-wins").
Note:Some database operations may only write partial updates of a row, so some versions of a row may include some columns, but not all. During a compaction or write, Cassandra assembles a complete version of each row from the partial updates, using the most recent version of each column.
Cassandra processes data at several stages on the read path to discover where the data is stored, starting with the data in the memtable and finishing with SSTables:
Check the memtable
Check row cache, if enabled
Checks Bloom filter
Checks partition key cache, if enabled
Goes directly to the compression offset map if a partition key is found in the partition key cache, or checks the partition summary if not
If the partition summary is checked, then the partition index is accessed
Locates the data on disk using the compression offset map
Fetches the data from the SSTable on disk
Read request flow
Row cache and Key cache request flow
Memtable
If the memtable has the desired partition data, then the data is read and then merged with the data from the SSTables. The SSTable data is accessed as shown in the following steps.
A write to a Cassandra node first hits the CommitLog (sequential). (Then Cassandra stores values to column-family specific, in-memory data structures called Memtables. The Memtables are flushed to disk whenever one of the configurable thresholds is exceeded. (1, datasize in memtable. 2, # of objects reach certain limit, 3, lifetime of a memtable expires.))
The data folder contains a subfolder for each keyspace. Each subfolder contains three kind of files:
Data files: An SSTable (nomenclature borrowed from Google) stands for Sorted Strings Table and is a file of key-value string pairs (sorted by keys).
Index file: (Key, offset) pairs (points into data file)
CFS stores file data in Apache Cassandra®. This allows for reuse of Cassandra features and offers scalability, high availability and great operational simplicity. Just as Cassandra is shared-nothing, CFS is shared-nothing as well. It scales linearly with the number of nodes in either performance and capacity.
Because Cassandra was not designed to store huge blobs of binary data as single cells, files in CFS have to be split into blocks and subblocks. Subblocks are each 2 MB large by default. A block is stored in a table partition. A subblock is stored in a table cell. The inodes table stores file metadata such as name and attributes and a list of block identifiers.
In order to achieve high availability, AWS resources should be hosted in multiple availability zones. Hosting in multiple availability zones allows you to ensure that if one goes down, your app will stay up and running.
One of the primary benefits of Cassandra is that it automatically shards your data across multiple nodes. It even manages to scale almost linearly, so doubling the number of nodes give you nearly double the capacity.
Placing nodes across multiple availability zones makes your Cassandra cluster more available and resilient to availability zone outages.
No additional storage is needed to run on multiple AZs and the cost increase is minimal. Traffic between AZs isn’t free but for most use cases this isn’t a major concern.
A replication factor of 3 combined with using 3 availability zones is a good starting point for most use cases. This enables your Cassandra cluster to be self-contained.
AWS has done a great job at keeping the latency between availability zones low. Especially if you use an instance with network performance set to “high” and have enhanced networking enabled.
In the insert statement as we have mentioned a primary key but set a non-primary-key column to null a row should be inserted into the table. We did the similar thing with update statement. We should be able to verify this with a select statement.
Apparently cassandra deletes a row if all of its non primary key fields are set to null if that row was inserted with a update statement.
UPDATE table_name SET field = false WHERE key = 55 IF EXISTS;
This will ensure that your update is a true update and not an upsert.
I am trying to model many-to-many relationships in Cassandra something like Item-User relationship. User can like many items and item can be bought by many users. Let us also assume that the order in which the "like" event occurs is not a concern and that the most used query is simply returning the "likes" based on item as well as the user.
An alternative would be to store a collection of ItemID in the User table to denote the items liked by that user and do something similar in the Items table in CQL3.
Questions
Are there any hits in performance using the collection? I think they translate to composite columns? So the read pattern, caching and other factors should be similar?
Are collections less performant for write heavy applications? Is updating the collection frequently less performant?
There are a couple of advantages of using wide rows over collections that I can think of:
The number of elements allowed in a collection is 65535 (an unsigned short). If it's possible to have more than that many records in your collection, using wide rows is probably better as that limitation is much higher (2 billion cells (rows * columns) per partition).
When reading a collection column, the entire collection is read every time. Compare this to wide row where you can limit the number of rows being read in your query, or limit the criteria of your query based on clustering key (i.e. date > 2015-07-01).
Because whatsapp doesn’t store any of user messages, the messages just ‘pass-thru’ the server to the devices. The local store of the device is the canonical data store for messages. One small variant is, for the chatters offline the messages are encrypted and stored in the server for a period of 30 days before it is discarded².
When additional capacity is required, more machines can simply be added to the cluster. When new machines join the cluster, Cassandra takes care of rebalancing the existing data so that each node in the expanded cluster has a roughly equal share. Also, the performance of a Cassandra cluster is directly proportional to the number of nodes within the cluster. As you keep on adding instances, the read and write throughput will keep increasing linearly.


 https://www.datastax.com/dev/blog/maximizing-cache-benefit-with-cassandra
https://www.datastax.com/dev/blog/maximizing-cache-benefit-with-cassandra


 Unlike relational database, data changes does not write back to the original data files. It does not involve data read or random disk access. Both commitlog and SSTable are flushed to disk as a new file with sequential write. Hence Cassandra writes data very fast.
https://docs.datastax.com/en/cassandra/3.0/cassandra/dml/dmlHowDataWritten.html
Unlike relational database, data changes does not write back to the original data files. It does not involve data read or random disk access. Both commitlog and SSTable are flushed to disk as a new file with sequential write. Hence Cassandra writes data very fast.
https://docs.datastax.com/en/cassandra/3.0/cassandra/dml/dmlHowDataWritten.html