In distributed systems, retries are inevitable. From network errors to replication issues and even outages in downstream dependencies, services operating at a massive scale must be prepared to encounter, identify, and handle failure as gracefully as possible.
Utilizing these properties, the Uber Insurance Engineering team extended Kafka’s role in our existing event-driven architecture by using non-blocking request reprocessing and dead letter queues (DLQ) to achieve decoupled, observable error-handling without disrupting real-time traffic. This strategy helps our opt-in Driver Injury Protection program run reliably in more than 200 cities, deducting per-mile premiums per trip for enrolled drivers.
The backend of Driver Injury Protection sits in a Kafka messaging architecture that runs through a Java service hooked into multiple dependencies within Uber’s larger microservices ecosystem. For the purpose of this article, however, we focus more specifically on our strategy for retrying and dead-lettering, following it through a theoretical application that manages the pre-order of different products for a booming online business.
In this model, we want to both a) make a payment and b) create a separate record capturing data for each product pre-order per user to generate real-time product analytics. This is analogous to how a single Driver Injury Protection trip premium processed by our program’s back-end architecture has both an actual charge component and a separate record created for reporting purposes.
A quick and simple solution for implementing retries is to use a feedback cycle at the point of the client call. For example, if the Payment Service in Figure 1 is experiencing prolonged latency and starts throwing timeout exceptions, the shop service would continue to call makePayment under some prescribed retry limit—perhaps with some backoff strategy—until it succeeds or another stop condition is reached.
Retrying requests in this type of system is very straightforward. As with the main processing flow, a separate group of retry consumers will read off their corresponding retry queue. These consumers behave like those in the original architecture, except that they consume from a different Kafka topic. Meanwhile, executing multiple retries is accomplished by creating multiple topics, with a different set of listeners subscribed to each retry topic. When the handler of a particular topic returns an error response for a given message, it will publish that message to the next retry topic below it, as depicted in Figures 3 and 4.
Finally, the DLQ is defined as the end-of-the-line Kafka topic in this design. If a consumer of the last retry topic still does not return success, then it will publish that message to the dead letter topic. From there, a number of techniques can be employed for listing, purging, and merging from the topic, such as creating a command-line tool backed by its own consumer that uses offset tracking. Dead letter messages are merged to re-enter processing by being published back into the first retry topic. This way, they remain separate from, and are unable to impede, live traffic.
It is important not to simply re-attempt failed requests immediately one after the other; doing so will amplify the number of calls, essentially spamming bad requests. Rather, each subsequent level of retry consumers can enforce a processing delay, in other words, a timeout that increases as a message steps down through each retry topic. This mechanism follows a leaky bucket pattern where flow rate is expressed by the blocking nature of the delayed message consumption within the retry queues. Consequently, our queues are not so much retry queues as they are delayed processing queues, where the re-execution of error cases is our best-effortdelivery: handler invocation will occur at least after the configured timeout but possibly later.
The following cases are handled identically in librdkafka:
entire cluster is down
no leader for partition
no active connection to the partition leader
In all these cases the message(s) remain in the partition's queue waiting for an active connection to the partition leader. The client will perform metadata refreshes at regular intervals to check if the leader has changed, and it will also try to reconnect (forever) to any brokers that are down.
Unresponsive brokers
When the producer sends a ProduceRequest to the broker it will put the message(s) on the wait-response queue (waitresp). The ProduceRequest's protocol timeout is set to the timeout of the first message in the ProduceRequest batch, i.e., the oldest message. (The message timeout is based on message.timeout.ms, the timeout scanner runs roughly once per second (sub-second timeouts are thus meaningless)). If no response is received from the broker within the request timeout the request fails and the message(s) in the request are failed, the RD_KAFKA_RESP_ERR__TIMED_OUT error will be propagated through the delivery report. No retries will be made at this point since the message.timeout.ms has been reached. On the other hand, if the connection is closed before a response is received and before the timeout hits, then metadata is refreshed (to find out if there is a new partition leader that will take over from the down broker) and the messages are put back on the partition queue for a future retransmission. Do note though that this retransmission does not increment the retry count; retries are incremented for temporary server-side errors, not connection losses (which might just be a sign of network instability).
Temporary server-side errors
For temporary errors returned by the broker, such asERR_REQUEST_TIMED_OUT, the request is retried in its entirety and the retry counter is incremented by one.
In streaming systems, like Kafka, we cannot skip messages and come back to them later. Once we move the pointer, called offset in Kafka, of current message we cannot go back. Just for simplicity let’s assume that the consumer offset is remembered just after successful message processing. In such situation we cannot take the next message unless we process the current successfully. If processing single message fails constantly it stops system from handling next messages. It is obvious we would like to avoid such scenario because very often failure of one message handling does not imply failure of next messages handling. Moreover, after longer time, for example one hour, the processing of failed messages may succeed for various reason. On of them can be, that the system we are depending on, is up once again. What can we do then to improve this naive implementation?
On message processing failure we can publish a copy of the message to another topic and wait for the next message. Let’s call the new topic the ‘retry_topic’. The consumer of the ‘retry_topic’ will receive the message from the Kafka and then will wait some predefined time, for example one hour, before starting the message processing. This way we can postpone next attempts of the message processing without any impact on the ‘main_topic’ consumer. If processing in the ‘retry_topic’ consumer fails we just have to give up and store the message in the ‘failed_topic’ for further manual handling of this problem. The ‘main_topic’ consumer code may look like this:
voidconsumeMainTopicWithPostponedRetry(){
while (true) {
Message message = takeNextMessage("main_topic");
try {
process(message);
} catch (Exception ex) {
publishTo("retry_topic");
LOGGER.warn("Message processing failure. Will try once again in the future.", ex);
}
}
}
The aforementioned approach looks good, but there are still some elements to improve. The depending system may be down for longer time than we expected. To solve the problem we should retry many times before we finally give up. In order to avoid flooding the external system or overusing the CPU because of the retry logic, we can increase the interval for subsequent attempts. Let’s improve the logic!
Assuming we want to have the following retrying strategy:
Every 5 minutes — 2 times
Then after 30 minutes — 3 times
Then after 1 hour only one time
Then we skip the message
We can represent it as a sequence of values: 5m, 5m, 30m, 30m, 30m, 1h. It also means that we have maximum 6 retries, because the sequence has 6 elements.
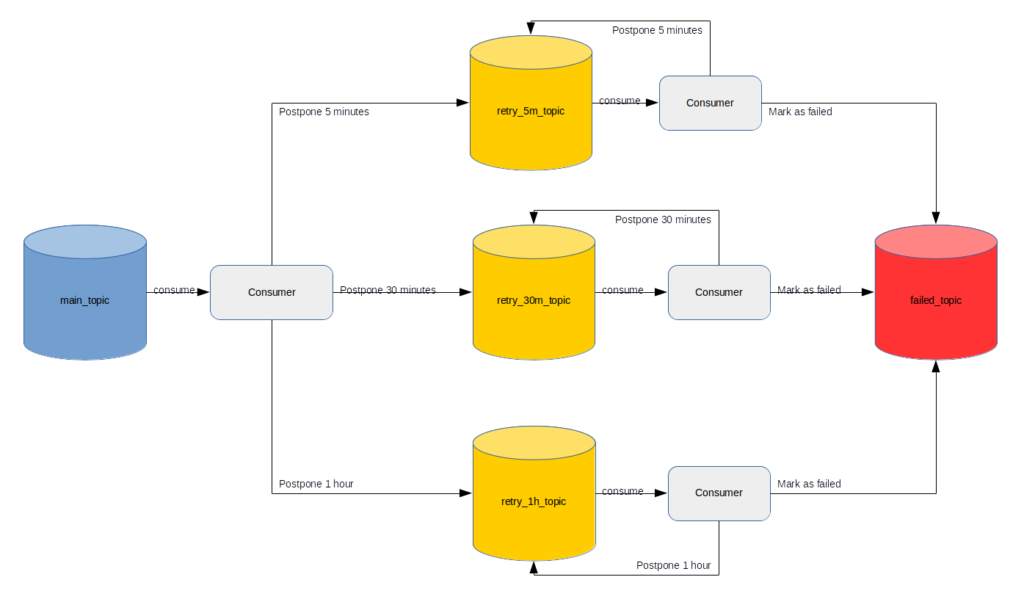
Now we can create 3 separate topics for retry logic handling, each for only one delay value:
‘retry_5m_topic’ — for retry in 5 minutes
‘retry_30m_topic’ — for retry in 30 minutes
‘retry_1h_topic’ — for retry in 1 hour
The message routing algorithm is very similar like in the previous approach. It only extends it from 1 to 3 available delay values and allows to retry predefined number of times.
Now let’s consider the following scenario. One new message was written to the topic ‘main_topic’. If the processing of this message fails, then we should try once again in 5 minutes, since 5m is the first value in the Retries Sequence. How can we do it? We should write a new message to the ‘retry_5m_topic’ that wraps the failed message and adds 2 fields:
‘retry_number’ with value 1
‘retry_timestamp’ with value calculated as now + 5 minutes
It means that that the ‘main_topic’ consumer delegates the responsibility of the failed message processing to another component. The ‘main_topic’ consumer is not blocked and can take the next message. The ‘retry_5m_topic’ consumer will receive the message published by the ‘main_topic’ consumer immediately. It has to read the ‘retry_timestamp’ value from the message and wait until that moment, blocking the thread. After the thread wakes up, it will try to process the message once again. If successfully then we can take the next available message. Otherwise we have to try once again because the Retries Sequence has 6 elements and current retry was the first. What we have to do is to clone the message, increment the ‘attempt_number’ value (it will be 2) and set the ‘retry_timestamp’ value as now + 5 minutes (because the second value in the Retries Sequence is 5m). The message clone will be published to the ‘retry_5m_topicv once again. You can notice that on each message processing failure, the copy of the message will be routed to one of ‘retry_5m_topic’, ‘retry_30m_topic’ or ‘retry_1h_topic’ topics. The very important thing is not to mix messages in one topic with ‘retry_timestamp’ property calculated from different delay values. If we reach the last element in the Retries Sequence it means that it was the last attempt. Now it’s time to say “stop”. We will write the message to the ‘failed_topic’ and treat this message as not processed. Someone has to handle it manually or we just forget about it. The picture below may help you to understand the message flow
Messages can be consumed from topic partitions in sequential order only
You cannot skip messages and come back to them later
If you want to postpone processing of some messages you can republish them to separate topics, one for each delay value
Processing failed messages can be achieved by cloning the message and republishing it to one of retry topics with updated information about attempt number and next retry timestamp
Consumers of retry topics should block the thread unless it is time to process the message
Messages in retry topics are naturally organized in the chronological order, sorted by the ‘retry_timestamp’ field
In Apache Kafka, the consumer group concept is a way of achieving two things:
Having consumers as part of the same consumer group means providing the“competing consumers” pattern with whom the messages from topic partitions are spread across the members of the group. Each consumer receives messages from one or more partitions (“automatically” assigned to it) and the same messages won’t be received by the other consumers (assigned to different partitions). In this way, we can scale the number of the consumers up to the number of the partitions (having one consumer reading only one partition); in this case, a new consumer joining the group will be in an idle state without being assigned to any partition.
Having consumers as part of different consumer groups means providing the “publish/subscribe” patternwhere the messages from topic partitions are sent to all the consumers across the different groups. It means that inside the same consumer group, we’ll have the rules explained above, but across different groups, the consumers will receive the same messages. It’s useful when the messages inside a topic are of interest for different applications that will process them in different ways. We want all the interested applications to receive all the same messages from the topic.
Another great advantage of consumers grouping is the rebalancing feature. When a consumer joins a group, if there are still enough partitions available (i.e. we haven’t reached the limit of one consumer per partition), a re-balancing starts and the partitions will be reassigned to the current consumers, plus the new one. In the same way, if a consumer leaves a group, the partitions will be reassigned to the remaining consumers.
A shared message queue system allows for a stream of messages from a producer to reach a single consumer. Each message pushed to the queue is read only once and only by one consumer. Subscribers pull messages (in a streaming or batch fashion) from the end of a queue being shared amongst them. Queueing systems then remove the message from the queue one pulled successfully.
Drawbacks:
Once one consumer pulls a message, it is erased from the queue.
Message queues are better suited to imperative programming, where the messages are much like commands to consumers belonging to the same domain, than event-driven programming, where a single event can lead to multiple actions from the consumers’ end, varying from domain to domain.
While multiple consumers may connect to the shared queue, they must all fall in the same logical domain and execute the same functionality. Thus, the scalability of processing in a shared message queue is limited by a single domain for consumption.
Publish-Subscribe Systems
The publish-subscribe model allows for multiple publishers to publish messages to topics hosted by brokers which can be subscribed to by multiple subscribers. A message is thus broadcast to all the subscribers of a topic.
Drawbacks:
The logical segregation of the publisher from the subscriber allows for a loosely-coupled architecture, but with limited scale. Scalability is limited as each subscriber must subscribe to every partition in order to access the messages from all partitions. Thus, while traditional pub-sub models work for small networks, the instability increases with the growth in nodes.
The side effect of the decoupling also shows in the unreliability around message delivery.
As every message is broadcast to all subscribers, scaling the processing of the streams is difficult as the subscribers are not in sync with one another.
How Kafka bridges the two models?
Kafka builds on the publish-subscribe model with the advantages of a message queuing system. It achieves this with:
the use of consumer groups
message retention by brokers
When consumers join a group and subscribe to a topic, only one consumer from the group actually consumes each message from the topic. The messages are also retained by the brokers in their topic partitions, unlike traditional message queues.
Multiple consumer groups can read from the same set of topics, and at different times catering to different logical application domains. Thus, Kafka provides both the advantage of high scalability via consumers belonging to the same consumer group and the ability to serve multiple independent downstream applications simultaneously.
Consumer Groups
Consumer groups give Kafka the flexibility to have the advantages of both message queuing and publish-subscribe models. Kafka consumers belonging to the same consumer group share a group id. The consumers in a group then divides the topic partitions as fairly amongst themselves as possible by establishing that each partition is only consumed by a single consumer from the group.
If all consumers are from the same group, the Kafka model functions as a traditional message queue would. All the records and processing is then load balanced Each message would be consumed by one consumer of the group only. Each partition is connected to at most one consumer from a group.
When multiple consumer groups exist, the flow of the data consumption model aligns with the traditional publish-subscribe model. The messages are broadcast to all consumer groups.
There also exist exclusive consumers, which happen to be consumer groups having only one consumer. Such a consumer must be connected to all the partitions it requires.
Ideally, the number of partitions is equal to the number of consumers. Should the number of consumers be greater, the excess consumers are idle, wasting client resources. If the number of partitions is greater, some consumers will read from multiple partitions which should not be an issue unless the ordering of messages is important to the use case. Kafka does not guarantee ordering of messages between partitions. It does provide ordering within a partition. Thus, Kafka can maintain message ordering by a consumer if it is subscribed to only a single partition. Messages can also be ordered using the key to be grouped by during processing.
Kafka also eliminates issues around the reliability of message delivery by having the option of acknowledgements in the form or offset commits of delivery sent to the broker to ensure it has reached the subscribed groups. As partitions can only have a one to one or many to one relationship to consumers in a consumer group, the replication of a message within a consumer group is avoided as a given message is reaching only one consumer in the group at a time.
Rebalancing
As a consumer group scales up and down, the running consumers split the partitions up amongst themselves. Rebalancing is triggered by a shift in ownership between a partition and consumer which could be caused by the crash of a consumer or broker or the addition of a topic or partition. It allows for safe addition or removal of consumer from the system.
On start up, a broker is marked as the coordinator for the subset of consumer groups which receive the RegisterConsumer Request from consumers and returns the RegisterConsumer Response containing the list of partitions they should own. The coordinator also starts failure detection to check if the consumers are alive or dead. When the consumer fails to send a heartbeat to the coordinator broker before the session timeout, the coordinator marks the consumer as dead and a rebalance is set in place to occur. This session time period can be set using the session.timeout.ms property of the Kafka service. The heartbeat.interval.ms property makes healthy consumers aware of the occurrence of a rebalance so as to re-send RegisterConsumer requests to the coordinator.
For example, assuming consumer C2 of Group A suffers a failure, C1 and C3 will briefly pause consumption of messages from their partitions and the partitions will be up for reassignment between them. Taking from the earlier example when the consumer C2 is lost, the rebalancing process is triggered and the partitions are re-assigned to the other consumers in the group. Group B consumers remain unaffected from the occurrences in Group A.
MirrorMaker is a stand-alone tool for copying data between two Apache Kafka clusters. It is a Kafka consumer and producer hooked together.
Data is read from topics in the origin cluster and written to a topic with the same name in the destination cluster. You can run many such mirroring processes to increase throughput and for fault-tolerance (if one process dies, the others will take overs the additional load).
Caveat 1: One of the principal benefits of an Event Driven Architecture is the decoupling of event producers and consumers, allowing for much more flexible and evolvable systems. Relying on a synchronous Request-Reply semantics is the exact opposite, where the requestor and replyer are tightly coupled. Hence it should be used only when needed.
Caveat 2: If synchronous Request-Reply is required, an HTTP-based protocol is much simpler and more efficient than using an asynchronous channel like Apache Kafka.
Event Driven Architectures in general and Apache Kafka specifically have gained lots of attention lately. To realize the full benefits of an Event Driven Architecture, the event delegation mechanism must be inherently asynchronous. There may however be some specific use cases/flows where a Synchronous Request-Reply semantics is needed. This blog post shows how to realize Request Reply using Apache Kafka.
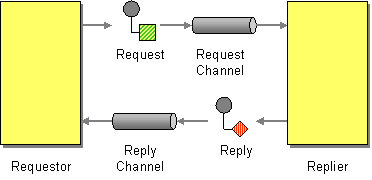
Apache Kafka is by design inherently asynchronous. Hence Request-Reply semantics is not natural in Apache Kafka. This challenge is however not new. The Request Reply Enterprise Integration Pattern provides a proven mechanism for synchronous message exchange over asynchonous channels:
The Return Address pattern complements Request Reply with a mechanism for the requestor to specify to which address the reply should be sent:
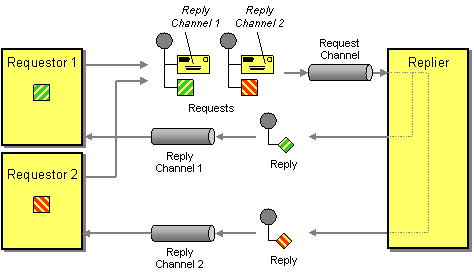
Recently, Spring Kafka added support for the Request Reply pattern out-of-the box. Let’s have a look at how that support works:
Kafka implements several request types that cannot immediately be answered with a response. Examples:
A produce request with acks=all cannot be considered complete until all in-sync replicas have acknowledged the write and we can guarantee it will not be lost if the leader fails.
A fetch request with min.bytes=1 won’t be answered until there is at least one new byte of data for the consumer to consume. This allows a “long poll” so that the consumer need not busy wait checking for new data to arrive.
These requests are considered complete when either (a) the criteria they requested is complete or (b) some timeout occurs.
The number of these asynchronous operations in flight at any time scales with the number of connections, which, for Kafka, is often tens of thousands.
Old Purgatory Design
The request purgatory consists of a timeout timer and a hash map of watcher lists for event driven processing. A request is put into the purgatory when it is not immediately satisfiable because of unmet conditions. A request in the purgatory is completed later when the conditions are met or is forced to be completed (timeout) when it passed beyond the time specified in the timeout parameter of the request. In the old design, it used Java DelayQueue to implement the timer.
When a request is completed, the request is not deleted from the timer or watcher lists immediately. Instead, completed requests are deleted as they were found during condition checking. When the deletion does not keep up, the server may exhaust JVM heap and cause OutOfMemoryError.
To alleviate the situation, a separate thread, called the reaper thread, purges completed requests from the purgatory when the number of requests (either pending or completed) in the purgatory exceeds the configured number. The purge operation scans the timer queue and all watcher lists to find completed requests and deletes them.
By setting this configuration parameter low, the server can virtually avoid the memory problem. However, the server must pay a significant performance penalty if it scans all lists too frequently.
The goal of the new design is to allow immediate deletion of a completed request and reduce the load of expensive purge process significantly. It requires cross referencing of entries in the timer and the requests. Also it is strongly desired to have O(1) insert/delete cost since insert/delete operation happens for each request/completion.
A major drawback of a simple timing wheel is that it assumes that a timer request is within the time interval of n * u from the current time. If a timer request is out of this interval, it is an overflow. A hierarchical timing wheel deals with such overflows. It is a hierarchically organized timing wheels that delegate overflows to upper level wheels. The lowest level has the finest time resolution. Time resolutions become coarser as we move up the hierarchy. If the resolution of a wheel at one level is uand the size is n, the resolutions should be n * u in the second level, n2 * u in the third level, and so on. At each level overflows are delegated to the wheel in one level higher. When the wheel in the higher level ticks, it reinsert timer tasks to the lower level. An overflow wheel can be created on-demand. When a bucket in an overflow bucket expires, all tasks in it are reinserted into the timer recursively. The tasks are then moved to the finer grain wheels or be executed. The insert (start-timer) cost is O(m) where m is the number of wheels, which is usually very small compared to the number of requests in the system, and the delete (stop-timer) cost is still O(1).
A timer task instance saves a link cell in itself when enqueued to a timer queue. When a task is completed or canceled, the list is updated using the link cell saved in the task itself.
Driving Clock using DelayQueue
A simple implementation may use a thread that wakes up every unit time and does the ticking, which checks if there is any task in the bucket. The unit time of the purgatory is 1ms (u = 1ms). This can be wasteful if requests are sparse at the wheel at the lowest level. This is usually the case because the majority of requests are satisfied before inserted into the wheel at the lowest level. It would be nice if a thread wakes up only when there is a non-empty bucket to expire. The new purgatory does so by using java.util.concurrent.DelayQueue similarly to the old implementation, but we enqueue task buckets instead of individual tasks. This design has a performance advantage. The number of items in DelayQueue is capped by the number of buckets, which is usually much smaller than the number of tasks, thus the number of offer/poll operations to the priority queue inside DelayQueue will be significantly smaller.
In the new design, we use Hierarchical Timing Wheels for the timeout timer and DelayQueue of timer buckets to advance the clock on demand. Completed requests are removed from the timer queue immediately with O(1) cost. The buckets remain in the delay queue, however, the number of buckets is bounded. And, in a healthy system, most of the requests are satisfied before timeout, and many of the buckets become empty before pulled out of the delay queue. Thus, the timer should rarely have the buckets of the lower interval. The advantage of this design is that the number of requests in the timer queue is the number of pending requests exactly at any time. This allows us to estimate the number of requests need to be purged. We can avoid unnecessary purge operation of the watcher lists. As the result we achieve a higher scalability in terms of request rate with much better CPU usage.
In the case of round robin strategy: catch the error and retry sending the message. The library will eventually proceed to the next available broker and succeed.
In the case of hashing strategy: catch the error, choose a different key and retry sending the message. Hopefully this results in choosing a partition of a reachable broker.
In the case of manual strategy: you have much more freedom because you choose the partition. You can mark the partition leader (k1 in this case) as unavailable for some time, so you can send messages only to partitions of reachable leaders.
https://blog.pragmatists.com/retrying-consumer-architecture-in-the-apache-kafka-939ac4cb851a On message processing failure we can publish a copy of the message to another topic and wait for the next message. Let’s call the new topic the ‘retry_topic’. The consumer of the ‘retry_topic’ will receive the message from the Kafka and then will wait some predefined time, for example one hour, before starting the message processing. This way we can postpone next attempts of the message processing without any impact on the ‘main_topic’ consumer. If processing in the ‘retry_topic’ consumer fails we just have to give up and store the message in the ‘failed_topic’ for further manual handling of this problem.
Messages can be consumed from topic partitions in sequential order only
You cannot skip messages and come back to them later
If you want to postpone processing of some messages you can republish them to separate topics, one for each delay value
Processing failed messages can be achieved by cloning the message and republishing it to one of retry topics with updated information about attempt number and next retry timestamp
Consumers of retry topics should block the thread unless it is time to process the message
Messages in retry topics are naturally organized in the chronological order, sorted by the ‘retry_timestamp’ field
When we are talking about performance of Kafka Producer, we are really talking about two different things:
latency: how much time passes from the time KafkaProducer.send() was called until the message shows up in a Kafka broker.
throughput: how many messages can the producer send to Kafka each second.
Kafka Producer allows to send message batches. Suppose that due to network roundtrip times, it takes 2ms to send a single Kafka message. By sending one message at a time, we have latency of 2ms and throughput of 500 messages per second. But suppose that we are in no big hurry, and are willing to wait few milliseconds and send a larger batch – lets say we decided to wait 8ms and managed to accumulate 1000 messages. Our latency is now 10ms, but our throughput is up to 100,000 messages per second! Thats the main reason I love microbatches so much. By adding a tiny delay, and 10ms is usually acceptable even for financial applications, our throughput is 200 times greater. This type of trade-off is not unique to Kafka, btw. Network and storage subsystem use this kind of “micro batching” all the time.
Sometimes latency and throughput interact in even funnier ways. One day Ted Malaska complained that with Flafka, he can get 20ms latency when sending 100,000 messages per second, but huge 1-3s latency when sending just 100 messages a second. This made no sense at all, until we remembered that to save CPU, if Flafka doesn’t find messages to read from Kafka it will back off and retry later. Backoff times started at 0.5s and steadily increased. Ted kindly improved Flume to avoid this issue in FLUME-2729.
Anyway, back to the Kafka Producer. There are few settings you can modify to improve latency or throughput in Kafka Producer:
batch.size – This is an upper limit of how many messages Kafka Producer will attempt to batch before sending – specified in bytes (Default is 16K bytes – so 16 messages if each message is 1K in size). Kafka may send batches before this limit is reached (so latency doesn’t change by modifying this parameter), but will always send when this limit is reached. Therefore setting this limit too low will hurt throughput without improving latency. The main reason to set this low is lack of memory – Kafka will always allocate enough memory for the entire batch size, even if latency requirements cause it to send half-empty batches.
linger.ms – How long will the producer wait before sending in order to allow more messages to get accumulated in the same batch. Normally the producer will not wait at all, and simply send all the messages that accumulated while the previous send was in progress (2 ms in the example above), but as we’ve discussed, sometimes we are willing to wait a bit longer in order to improve the overall throughput at the expense of a little higher latency. In this case tuning linger.ms to a higher value will make sense. Note that if batch.size is low and the batch if full before linger.ms time passes, the batch will send early, so it makes sense to tune batch.size and linger.ms together.
Other than tuning these parameters, you will want to avoid waiting on the future of the send method (i.e. the result from Kafka brokers), and instead send data continuously to Kafka. You can simply ignore the result (if success of sending messages is not critical), but its probably better to use a callback. You can find an example of how to do this in my github (look at produceAsync method).
If sending is still slow and you are trying to understand what is going on, you will want to check if the send thread is fully utilized through jvisualsm (it is called kafka-producer-network-thread) or keep an eye on average batch size metric. If you find that you can’t fill the buffer fast enough and the sender is idle, you can try adding application threads that share the same producer and increase throughput this way.
Another concern can be that the Producer will send all the batches that go to the same broker together when at least one of them is full – if you have one very busy topic and others that are less busy, you may see some skew in throughput this way.
Sometimes you will notice that the producer performance doesn’t scale as you add more partitions to a topic. This can happen because, as we mentioned, there is a send buffer for each partition. When you add more partitions, you have more send buffers, so perhaps the configuration you set to keep the buffers full before (# of threads, linger.ms) is no longer sufficient and buffers are sent half-empty (check the batch sizes). In this case you will need to add threads or increase linger.ms to improve utilization and scale your throughput.
Event-at-a-time processing (not microbatch) with millisecond latency
Stateful processing including distributed joins and aggregations
A convenient DSL
Windowing with out-of-order data using a DataFlow-like model
Distributed processing and fault-tolerance with fast failover
Reprocessing capabilities so you can recalculate output when your code changes
No-downtime rolling deployments
In terms of implementation Kafka Streams stores this derived aggregation in a local embedded key-value store (RocksDB by default, but you can plug in anything). The output of the job is exactly the changelog of updates to this table. This changelog is used for high-availability of the computation, but it’s also an output that can be consumed and transformed by other Kafka Streams processing or loaded into another system using Kafka Connect.
Architecturally this idea of supporting local storage was already present in Apache Samza and I wrote about it before primarily from a systems real time analytics architecture point of view. The key new thing in Kafka Streams is that the table concept isn’t just a low-level facility, it’s a first class citizen just as streams themselves are. Streams are represented by the KStream class in the programming DSL provided by Kafka Streams, and tables by the KTable class. They share a lot of the same operations, and can be converted back and forth just as the table/stream duality suggests, but, for example, an aggregation on a KTable will automatically handle that fact that it is made up of updates to the underlying values
Those who closely follow the stream processing area may have heard of the idea of “event time” that has been really eloquently discussed by the folks on the Google Dataflow team. The question they grappled with was how to do windowed operations on streams if events can arrive out of order. This problem of out-of-order data is quite unavoidable in most distributed settings since we simply can’t guarantee order over data being generated in different data centers or on different devices.
Always causes data re-partitioning:groupBy always causes data re-partitioning. If possible use groupByKey instead, which will re-partition data only if required.
Group the records of this KStream on a new key that is selected using the provided KeyValueMapper and default serializers and deserializers. Grouping a stream on the record key is required before an aggregation operator can be applied to the data (cf. KGroupedStream). The KeyValueMapper selects a new key (with should be of the same type) while preserving the original values. If the new record key is null the record will not be included in the resulting KGroupedStreamBecause a new key is selected, an internal repartitioning topic will be created in Kafka. This topic will be named "${applicationId}-XXX-repartition", where "applicationId" is user-specified in StreamsConfig via parameter APPLICATION_ID_CONFIG, "XXX" is an internally generated name, and "-repartition" is a fixed suffix. You can retrieve all generated internal topic names via KafkaStreams.toString().
All data of this stream will be redistributed through the repartitioning topic by writing all records to it, and rereading all records from it, such that the resulting KGroupedStream is partitioned on the new key.
This operation is equivalent to calling selectKey(KeyValueMapper) followed by groupByKey(). If the key type is changed, it is recommended to use groupBy(KeyValueMapper, Serde, Serde) instead.
void to(StreamPartitioner<? super K,? super V> partitioner,
java.lang.String topic)
Materialize this stream to a topic using default serializers specified in the config and a customizable StreamPartitioner to determine the distribution of records to partitions. The specified topic should be manually created before it is used (i.e., before the Kafka Streams application is started).
https://howtoprogram.xyz/2016/06/04/write-apache-kafka-custom-partitioner/ A topic now can be divided into many partitions depended on our application business logic. Partitions data can be stored on different machines of the cluster. And each partition of the topic can be consumed by different consumers of a consumer group.
By default, Apache Kafka producer will distribute the messages to different partitions by round-robin fashion. This producer class, registered with our custom partitioner: props.put("partitioner.class", "com.howtoprogram.kafka.custompartitioner.KafkaUserCustomPatitioner") http://cmcurtintech.blogspot.com/2013/03/custom-partitioners-for-kafka-080.html public class OrganizationPartitioner implements Partitioner { public OrganizationPartitioner(VerifiableProperties props) { } public int partition(String key, int a_numPartitions) { long organizationId = Long.parseLong(key); return (int) (organizationId % a_numPartitions); } } Yes. Using the Simple Consumer you can define which partition to listen on and which offset to start reading from.
Grouping (i.e., repartitioning) and aggregation of the KStream API was significantly changed to be aligned with the KTable API. Instead of using a single method with many parameters, grouping and aggregation is now split into two steps. First, a KStream is transformed into a KGroupedStream that is a repartitioned copy of the original KStream. Afterwards, an aggregation can be performed on the KGroupedStream, resulting in a new KTable that contains the result of the aggregation.
Thus, the methods KStream#aggregateByKey(...), KStream#reduceByKey(...), and KStream#countByKey(...) were replaced by KStream#groupBy(...) and KStream#groupByKey(...) which return a KGroupedStream. While KStream#groupByKey(...) groups on the current key, KStream#groupBy(...) sets a new key and re-partitions the data to build groups on the new key. The new class KGroupedStream provides the corresponding methods aggregate(...), reduce(...), and count(...).
KStreamstream=builder.stream(...);Reducerreducer=newReducer(){/* ... */};// old APIKTablenewTable=stream.reduceByKey(reducer,name);// new API, Group by existing keyKTablenewTable=stream.groupByKey().reduce(reducer,name);// or Group by a different keyKTableotherTable=stream.groupBy((key,value)->value).reduce(reducer,name);
Create a KTable for the specified topic. The default "auto.offset.reset" strategy and default key and value deserializers as specified in the config are used. Input records with null key will be dropped.Note that the specified input topic must be partitioned by key. If this is not the case the returned KTable will be corrupted.
The resulting KTable will be materialized in a local KeyValueStore with the given storeName. However, no internal changelog topic is created since the original input topic can be used for recovery (cf. methods of KGroupedStream and KGroupedTable that return a KTable).
To query the local KeyValueStore it must be obtained via KafkaStreams#store(...):
Both KTables must have the same number of partitions (this is called co-partitioned).
Option 1: Local join with GlobalKTables
Most of the time, the reference data is small enough to fit in memory or disk, so it is more efficient to have a copy of the reference data on each node instead of doing a distributed join, as doing a distributed join will require shuffling data across the network.
From Kafka 0.10.2.0, Kafka Streams comes with the concept of a GlobalKTable, which is exactly this, a KTable where each node in the Kafka Stream topology has a complete copy of the reference data, so joins are done locally.
Unfortunately KTable to GlobalKTable joins are not yet supported, it will come in Kafka 0.11.0.0 (or once this ticket is done).
Option 2: Distributed left outer join
But what if the KTables that you want to join are huge?
To start with, we will need to repartition one of the KTables so both topics are keyed by the same attribute. This way the rows that we need to join will end up in the same node.
KTable is a representation of Changelog, which does not contain a record with the same key twice. This means that if KTable encounters a record with the same key in the table, it will simply replace the old record with the current record.
KStream<Integer, PageView> views = builder.stream(Serdes.Integer(), new PageViewSerde(), Constants.PAGE_VIEW_TOPIC);
KStream<Integer, Search> searches = builder.stream(Serdes.Integer(), new SearchSerde(), Constants.SEARCH_TOPIC);
KTable<Integer, UserProfile> profiles = builder.table(Serdes.Integer(), new ProfileSerde(), Constants.USER_PROFILE_TOPIC, "profile-store");
If you live in a world of microservices, you are probably aiming to build really small services that have their own database which no other service can peek into, and that publishes events into some messaging infrastructure.
This gives you a nice loosely coupled architecture where services can come and go, be rewritten or retired, and new functionality can be build without having to touch the working services.
Apache Kafka is often chosen as the messaging infrastructure for microservices, due to its unique scalability, performance and durability characteristics. It supports both queue and topic semantics and clients are able to replay old messages if they want to.
Send a weekly email to clients holding trading positions in any US stock.
Third, Kafka Streams take care of sharding the work, each instance able to prepare and send the emails for a subset of the clients. This brings scalability, plus it removes the additional coordination component.
Alex's answer is correct. There is no hard maximum but there are several limitations you will hit. Both limitations are actually in the number of partitions not in the number of topics, so a single topic with 100k partitions would be effectively the same as 100k topics with one partition each.
The first limitation is that each partition is physically represented as a directory of one or more segment files. So you will have at least one directory and several files per partition. Depending on your operating system and filesystem this will eventually become painful. However this is a per-node limit and is easily avoided by just adding more total nodes in the cluster.
The second limitation is Zookeeper which is used for per-partition configuration information and leadership elections. Zookeeper is basically a non-sharded in-memory database, and it will eventually be exhausted.
However in practice neither of these should ever become an issue. Virtually every time I have talked with someone doing this the reason is that they would like to have a topic for each user on a website and use the topic for live serving (e.g. a request from their website would read from Kafka). I believe what these people are really looking for is key-value store with range-scans like Cassandra.
If you are actually using Kafka as a log or messaging system you should not need millions of topics or partitions. The number of partitions should scale only with the number of consuming machines not with any characteristic of the data. The recommended approach is to have a single topic and partition it by user_id, this will give you locality and order by user. In other words you get a stronger ordering guarantee than you would if you had one topic per user and it is vastly more efficient.
First, I was thinking to create as many topic as per user meaning each user would have each topic (What problem will this cause? My max estimate is that I will have around 1~5 million topics)
I would advise against modeling like this.
Google around for "kafka topic limits", and you will find the relevant considerations for this subject. I think you will find you won't want to make millions of topics.
Second, If I decide to go for topics based on operation and partition by random hash of users id
Yes, have a single topic for these messages and then route those messages based on the relevant field, like user_id or conversation_id. This field can be present as a field on the message and serves as the ProducerRecordkey that is used to determine which partition in the topic this message is destined for. I would not include the operation in the topic name, but in the message itself.
if there was a problem with one user not consuming message currently, will the all user in the partition have to wait ? What would be the best way to structure this situation?
This depends on how the users are consuming messages. You could set up a timeout, after which the message is routed to some "failed" topic. Or send messages to users in a UDP-style, without acks. There are many ways to model this, and it's tough to offer advice without knowing how your consumers are forwarding messages to your clients.
Also, if you are using Kafka Streams, make note of the StreamPartitioner interface. This interface appears in KStream and KTable methods that materialize messages to a topic and may be useful in a chat applications where you have clients idling on a specific TCP connection.
 https://crossoverjie.top/2018/10/11/kafka/kafka-product/
https://crossoverjie.top/2018/10/11/kafka/kafka-product/{kind=link}