The Photos application is one of Facebook’s most popular features. Up to date, users have uploaded over 15 billion photos which makes Facebook the biggest photo sharing website. For each uploaded photo, Facebook generates and stores four images of different sizes, which translates to a total of 60 billion images and 1.5PB of storage. The current growth rate is 220 million new photos per week, which translates to 25TB of additional storage consumed weekly. At the peak there are 550,000 images served per second. These numbers pose a significant challenge for the Facebook photo storage infrastructure.
NFS photo infrastructure
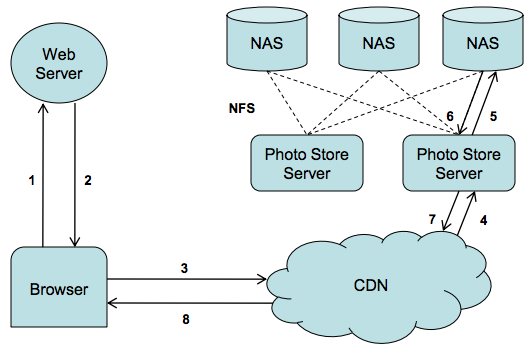
The old photo infrastructure consisted of several tiers:
Upload tier receives users’ photo uploads, scales the original images and saves them on the NFS storage tier.
Photo serving tier receives HTTP requests for photo images and serves them from the NFS storage tier.
NFS storage tier built on top of commercial storage appliances.
Since each image is stored in its own file, there is an enormous amount of metadata generated on the storage tier due to the namespace directories and file inodes. The amount of metadata far exceeds the caching abilities of the NFS storage tier, resulting in multiple I/O operations per photo upload or read request. The whole photo serving infrastructure is bottlenecked on the high metadata overhead of the NFS storage tier, which is one of the reasons why Facebook relies heavily on CDNs to serve photos.
Cachr: a caching server tier caching smaller Facebook “profile” images.
NFS file handle cache – deployed on the photo serving tier eliminates some of the NFS storage tier metadata overhead
Haystack Photo Infrastructure
The new photo infrastructure merges the photo serving tier and storage tier into one physical tier.
It implements a HTTP based photo server which stores photos in a generic object store called Haystack. The main requirement for the new tier was to eliminate any unnecessary metadata overhead for photo read operations, so that each read I/O operation was only reading actual photo data (instead of filesystem metadata). Haystack can be broken down into these functional layers:
HTTP server Photo Store Haystack Object Store Filesystem Storage
Each storage blade provides around 10TB of usable space, configured as a RAID-6 partition managed by the hardware RAID controller. RAID-6 provides adequate redundancy and excellent read performance while keeping the storage cost down. The poor write performance is partially mitigated by the RAID controller NVRAM write-back cache. Since the reads are mostly random, the NVRAM cache is fully reserved for writes. The disk caches are disabled in order to guarantee data consistency in the event of a crash or a power loss.
Storage
Haystack is deployed on top of commodity storage blades. The typical hardware configuration of a 2U storage blade is:
2 x quad-core CPUs
16GB – 32GB memory
hardware raid controller with 256MB – 512MB of NVRAM cache
12+ 1TB SATA drives
Each storage blade provides around 10TB of usable space, configured as a RAID-6 partition managed by the hardware RAID controller. RAID-6 provides adequate redundancy and excellent read performance while keeping the storage cost down. The poor write performance is partially mitigated by the RAID controller NVRAM write-back cache. Since the reads are mostly random, the NVRAM cache is fully reserved for writes. The disk caches are disabled in order to guarantee data consistency in the event of a crash or a power loss.
Filesystem
Haystack object stores are implemented on top of files stored in a single filesystem created on top of the 10TB volume. Photo read requests result in read() system calls at known offsets in these files, but in order to execute the reads, the filesystem must first locate the data on the actual physical volume. Each file in the filesystem is represented by a structure called an inode which contains a block map that maps the logical file offset to the physical block offset on the physical volume.
For large files, the block map can be quite large depending on the type of the filesystem in use. Block based filesystems maintain mappings for each logical block, and for large files, this information will not typically fit into the cached inode and is stored in indirect address blocks instead, which must be traversed in order to read the data for a file. There can be several layers of indirection, so a single read could result in several I/Os depending on whether or not the indirect address blocks are cached.
Extent based filesystems maintain mappings only for contiguous ranges of blocks (extents). A block map for a contiguous large file could consist of only one extent which would fit in the inode itself. However, if the file is severely fragmented and its blocks are not contiguous on the underlying volume, its block map can grow large as well.
With extent based filesystems, fragmentation can be mitigated by aggressively allocating a large chunk of space whenever growing the physical file. Currently, the filesystem of choice is XFS, an extent based filesystem providing efficient file preallocation.
Haystack Object Store
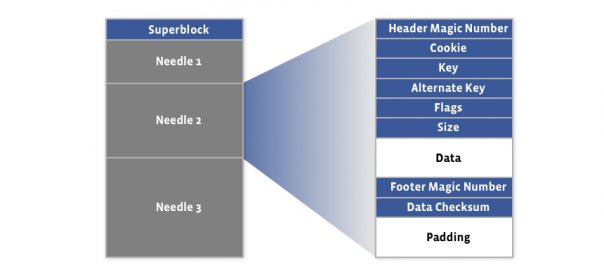
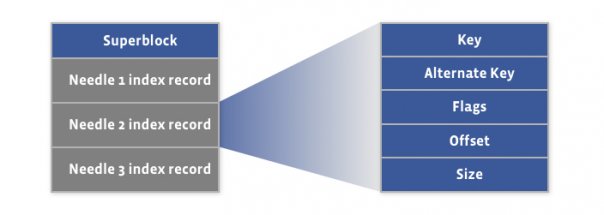
Haystack is a simple log structured (append-only) object store containing needles representing the stored objects. A Haystack consists of two files – the actual haystack store file containing the needles, plus an index file. The following figure shows the layout of the haystack store file:
The first 8KB of the haystack store is occupied by the superblock. Immediately following the superblock are needles, with each needle consisting of a header, the data, and a footer:
A needle is uniquely identified by its <Offset, Key, Alternate Key, Cookie> tuple, where the offset is the needle offset in the haystack store. Haystack doesn’t put any restriction on the values of the keys, and there can be needles with duplicate keys. Following figure shows the layout of the index file:
There is a corresponding index record for each needle in the haystack store file, and the order of the needle index records must match the order of the associated needles in the haystack store file.
The index file provides the minimal metadata required to locate a particular needle in the haystack store file. Loading and organizing index records into a data structure for efficient lookup is the responsibility of the Haystack application (Photo Store in our case). The index file is not critical, as it can be rebuilt from the haystack store file if required. The main purpose of the index is to allow quick loading of the needle metadata into memory without traversing the larger Haystack store file, since the index is usually less than 1% the size of the store file.
Haystack Write Operation
A Haystack write operation synchronously appends new needles to the haystack store file. After the needles are committed to the larger Haystack store file, the corresponding index records are then written to the index file.
Since the index file is not critical, the index records are written asynchronously for faster performance.
The index file is also periodically flushed to the underlying storage to limit the extent of the recovery operations caused by hardware failures.
In the case of a crash or a sudden power loss, the haystack recovery process discards any partial needles in the store and truncates the haystack store file to the last valid needle.
Next, it writes missing index records for any trailing orphan needles at the end of the haystack store file.
Haystack doesn’t allow overwrite of an existing needle offset, so if a needle’s data needs to be modified, a new version of it must be written using the same <Key, Alternate Key, Cookie> tuple. Applications can then assume that among the needles with duplicate keys, the one with the largest offset is the most recent one.
Haystack Read Operation
The parameters passed to the haystack read operation include the needle offset, key, alternate key, cookie and the data size.
Haystack then adds the header and footer lengths to the data size and reads the whole needle from the file. The read operation succeeds only if the key, alternate key and cookie match the ones passed as arguments, if the data passes checksum validation, and if the needle has not been previously deleted (see below).
Haystack Delete Operation
The delete operation is simple – it marks the needle in the haystack store as deleted by setting a “deleted” bit in the flags field of the needle.
However, the associated index record is not modified in any way so an application could end up referencing a deleted needle. A read operation for such a needle will see the “deleted” flag and fail the operation with an appropriate error. The space of a deleted needle is not reclaimed in any way. The only way to reclaim space from deleted needles is to compact the haystack (see below).
Photo Store Server
Photo Store Server is responsible for accepting HTTP requests and translating them to the corresponding Haystack store operations.
In order to minimize the number of I/Os required to retrieve photos, the server keeps an in-memory index of all photo offsets in the haystack store file.
At startup, the server reads the haystack index file and populates the in-memory index.
With hundreds of millions of photos per node (and the number will only grow with larger capacity drives), we need to make sure that the index will fit into the available memory. This is achieved by keeping a minimal amount of metadata in memory, just the information required to locate the images.
When a user uploads a photo, it is assigned a unique 64-bit id. The photo is then scaled down to 4 different sizes. Each scaled image has the same random cookie and 64-bit key, and the logical image size (large, medium, small, thumbnail) is stored in the alternate key. The upload server then calls the photo store server to store all four images in the Haystack. The in-memory index keeps the following information for each photo:
Haystack uses the open source Google sparse hash data structure to keep the in-memory index small, since it only has 2 bits of overhead per entry.
Photo Store Write/Modify Operation
A write operation writes photos to the haystack and updates the in-memory index with the new entries.
If the index already contains records with the same keys then this is a modification of existing photos and only the index records offsets are modified to reflect the location of the new images in the haystack store file.
Photo store always assumes that if there are duplicate images (images with the same key) it is the one stored at a larger offset which is valid.
Photo Store Read Operation
The parameters passed to a read operation include haystack id and a photo key, size and cookie.
The server performs a lookup in the in-memory index based on the photo key and retrieves the offset of the needle containing the requested image. If found it calls the haystack read operation to get the image. As noted above haystack delete operation doesn’t update the haystack index file record. Therefore a freshly populated in-memory index can contain stale entries for the previously deleted photos. Read of a previously deleted photo will fail and the in-memory index is updated to reflect that by setting the offset of the particular image to zero.
Photo Store Delete Operation
After calling the haystack delete operation the in-memory index is updated by setting the image offset to zero signifying that the particular image has been deleted.
Compaction
Compaction is an online operation which reclaims the space used by the deleted and duplicate needles (needles with the same key).
It creates a new haystack by copying needles while skipping any duplicate or deleted entries. Once done it swaps the files and in-memory structures.
HTTP Server
The HTTP framework we use is the simple evhttp server provided with the open source libevent library. We use multiple threads, with each thread being able to serve a single HTTP request at a time. Because our workload is mostly I/O bound, the performance of the HTTP server is not critical.
Summary
Haystack presents a generic HTTP-based object store containing needles that map to stored opaque objects.
Storing photos as needles in the haystack eliminates the metadata overhead by aggregating hundreds of thousands of images in a single haystack store file.
This keeps the metadata overhead very small and allows us to store each needle’s location in the store file in an in-memory index.
This allows retrieval of an image’s data in a minimal number of I/O operations, eliminating all unnecessary metadata overhead.
Haystack was designed for sharing photos on Facebook where data is written once, read often, never modified and rarely deleted.
The disadvantages of a traditional POSIX based filesystem are directories and per file metadata.
For the Photos application most of this metadata, such as permissions, is unused and thereby wastes storage capacity.
Yet the more significant cost is that the file’s metadata must be read from disk into memory in order to find the file itself. Several disk operations were necessary to read a single photo : one(or typically more) to translate the filename into inode number, another to read the inode from disk, and a final one to read the file itself.
Given the above disadvantages of a traditional approach, Haystack was designed to achieve 4 major goals:
High throughput and low latency: Haystack achieves high throughput and low latency by requiring at most one disk operation per read. It is accomplished by keeping all metadata in main memory, which is made practical by dramatically reducing per photo metadatanecessary to find a photo on the disk.
Fault-tolerant : Haystack replicates each photo in geographically distinct locations.
Cost-effective: In Haystack, each usable terabyte costs ~28% less and processes ~4x more reads per second than an equivalent terabyte on a NAS appliance.
Simple: As Haystack was a new system (at the time the paper was published), lacking years of production testing, particular attention was taken to keep it simple.
Previous Design (NFS-based)
CDNs (Content Delivery Networks) do effectively serve the hottest photos - profile pictures and photos that have been recently uploaded
- but a social networking site like Facebook also generates a large number of requests for less popular (often older) content, which is referred to as the long tail.
To reduce disk operations we let the Photo Store servers explicitly cache file handles returned by the NAS appliances. When reading a file for the first time a Photo Store server opens a file normally but also caches the filename to file handle mapping in memcache.
However, that only addresses part of the problem as it relies on the NAS appliance having all of its inodes in main memory, an expensive requirement for traditional filesystems.
To achieve a better price/performance point, the authors decided to build a custom storage system that reduces the amount of filesystem metadata per photo so that having enough main memory is dramatically more cost-effective than buying more NAS appliances.
Design of Haystack
Facebook uses a CDN to serve popular images and leverages Haystack to respond to photo requests in the long tail efficiently. Haystack takes a straightforward approach: it stores multiple photos in a single file and therefore maintains very large files.
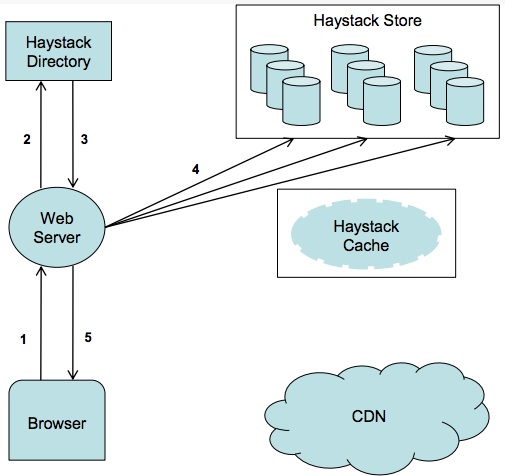
The Haystack architecture consists of 3 core components: the Haystack Store, Haystack Directory, and Haystack Cache.
The Store encapsulates the persistent storage system for photos and is the only component that manages the filesystem metadata for photos. When Haystack stores a photo on a logical volume, the photo is written to all corresponding physical volumes.
The Directory maintains the logical to physical mapping along with other application metadata, such as the logical volume where each photo resides and the logical volumes with free space.
The Cache functions as the internal CDN, which shelters the Store from requests for the most popular photos and provides insulation if upstream CDN nodes fail and need to refetch content.
Having an internal caching infrastructure provided the ability to reduce dependence on external CDNs.
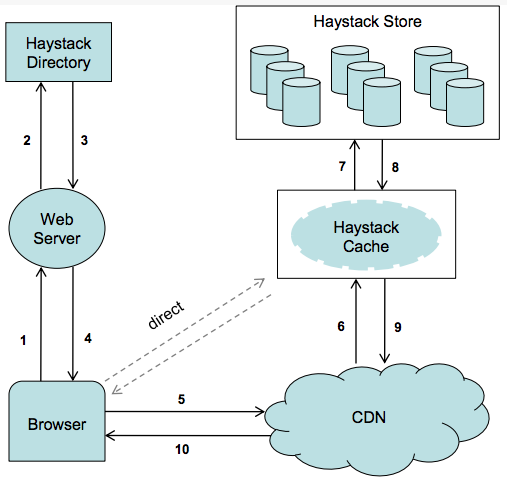
A typical URL that directs the browser to the CDN looks like the following:
The first part of the URL specifies from which CDN to fetch the photo. The CDN can lookup the photo internally using only the last part of the URL. If the CDN cannot locate the photo then it strips the CDN address from the URL and contacts the Cache. The Cache does a similar lookup to find the photo. Photo requests that go directly to the Cache have a similar workflow except that the URL is missing the CDN specific information.
Haystack Directory
The Directory serves 4 major functions:
Provides a mapping from logical volumes to physical volumes.
Load balances writes across logical volumes and reads across physical volumes.
Determines whether a photo request should be handled by the CDN or by the Cache.
Identifies those logical volumes that are read-only wither because of operational reasons or because those volumes have reached their storage capacity.
The Directory stores its information in a replicated database accessed via a PHP interface that leverages memcache to reduce latency.
Haystack Cache
The Cache is organized as a distributed hash table and a photo’s id is used as the key to locate cached data.
It caches a photo only if 2 conditions are met:
The request comes directly from a user and not the CDN (post-CDN caching is ineffective as it is unlikely that a request that misses in the CDN would hit in the internal cache).
The photo is fetched from a write-enabled Store machine (photos are most heavily accessed soon after they are uploaded and filesystems for high workloads perform better when doing either reads or writes but not both).
Haystack Store
The interface to Store machines is intentionally basic. Reads make very specific and well contained requests asking for a photo with a given id, for a certain logical volume,and from a particular physical Store machine. The machine returns the photo if it is found. Otherwise, the machine returns an error.
This knowledge is the keystone of the Haystack design: retrieving the filename,offset and size for a particular photo without needing disk operations. A Store machine keeps open file descriptors for each physical volume that it manages and also an in-memory mapping of photo ids to the filesystem metadata (i.e. the file, offset and size in bytes) critical for retrieving that photo.
Photo Read
When a Cache machine requests a photo it supplies the logical volume id, key, alternate key, and cookie to the Store machine. The cookie is a number embedded in the URL for a photo. The cookie’s value is randomly assigned by and stored in the Directory at the time that photo is uploaded. The cookie effectively eliminates attacks aimed at guessing valid URLs for photos.
The Store machine seeks to the appropriate offset in the volume file, reads the entire needle from disk (whose size it can calculate ahead of time), and verifies the cookie and the integrity of the data. If these checks pass then the Store machine returns the photo to the Cache machine.
Photo Write
When uploading a photo into Haystack web servers provide the logical volume id, key, alternate key, cookie, and data to Store machines. Each machine synchronously appends needle images to its physical volume files and updates in-memory mappings as needed.
Photo Delete
A Store machine sets the delete flag in both the in-memory mapping and synchronously in the volume file.
The Index File
While in theory a machine can reconstruct its in-memory mappings by reading all of its physical volumes, doing so is time-consuming as the amount of data(terabytes worth) has to all be read from disk. Index files allow a Store machine to build its in-memory mappings quickly, shortening restart time.
Restarting using the index is slightly more complicated . The complications arise because index files are updated asynchronously, meaning that index files may represent stale checkpoints. When we write a new photo the Store machine synchronously appends a needle to the end of the volume file and asynchronously appends a record to the index file. When we delete a photo, the Store machine synchronously sets the flag in that photo’s needle without updating the index file. These design decisions allow write and delete operations to return faster because they avoid additional synchronous disk writes.
Needles without corresponding index records are referred to as orphans. We can quickly identify orphans because the last record in the index file corresponds to the last non-orphan needle in the volume file.
Since index records do not reflect deleted photos, a Store machine may retrieve a photo that has in fact been deleted. To address this issue, after a Store machine reads the entire needle for a photo, that machine can then inspect the delete flag. If a needle is marked as deleted the Store machine updates its in-memory mapping accordingly and notifies the Cache that the object was not found.
Compaction is an online operation that reclaims the space used by deleted and duplicate needles (needles with the same key and alternate key). A Store machine compacts a volume file by copying needles into a new file while skipping any duplicate or deleted entries. During compaction, deletes go to both files.
Batch upload
Since disks are generally better at performing large sequential writes instead of small random writes, uploads are batched whenever possible. Fortunately, many users upload entire albums to Facebook instead of single pictures, providing an obvious opportunity to batch the photos in an album together.
The number of Haystack photos written is 12 times the number of photos uploaded since the application scales each image to 4 sizes and saves each size in 3 different locations.
这个架构采用CDN作为图片缓存,底层使用基于NAS的存储,Photo Store Server 通过NFS挂载NAS中的图片文件提供服务。用户的图片请求首先调度到最近的CDN节点,如果CDN缓存命中,直接将图片内容返回用户;否则CDN请求后端的存储系统,缓存并将图片内容返回用户。Facebook的经验表明,SNS社交网站中CDN缓存的效果有限,存在大量的”长尾”请求。虽然user profile图片请求的CDN命中率高达99.8%,但是其它图片请求CDN命中率只有92%,大约1/10的请求最后落到了后端的存储系统。这个架构的问题如下:
Facebook relies heavily on memcached to minimize their database load. They of course use in memory hash table running on 64 bits machines, efficient serialization, multi-threading, compression and polling drivers. What’s interesting with this approach is that the switches connected to all the memcached server become the bottleneck ! To alleviate this problem, they perform client-side throttling.
Database
They avoid like the plague shared architecture so they can manage failures more efficiently (basically avoiding storing non-static and heavily referenced data in a central database). They use services and memcached for global queries. In order to scale across multiple data centers, they replicate as well their memcached data to deal with race condition http://muratbuffalo.blogspot.com/2010/12/finding-needle-in-haystack-facebooks.html When the browser requests a photo, the webserver uses the Directory to construct a URL for the photo, which includes the physical as well as logical volume information. Each Store machine manages multiple physical volumes. Each volume holds millions of photos. A physical volume is simply a very large file (100 GB) saved as "/hay/haystack-logical volumeID". Haystack is a log-structured append-only object store. A Store machine can access a photo quickly using only the id of the corresponding logical volume and the file offset at which the photo resides. This knowledge is the keystone of the Haystack design: retrieving the filename, offset, and size for a particular photo without needing disk operations. A Store machine keeps open file descriptors for each physical volume that it manages and also an in-memory mapping of photo ids to the filesystem metadata (i.e., file, offset and size in bytes) critical for retrieving that photo. Each photo stored in the file is called a needle.
XFS has two main advantages for Haystack. First, the blockmaps for several contiguous large files can be small enough to be stored in main memory. Second, XFS provides efficient file preallocation, mitigating fragmentation and reining in how large block maps can grow. Figure 3 shows the architecture of the Haystack system. It consists of 3 core components: the Haystack Store, Haystack Directory, and Haystack Cache. The Store's capacity is organized into physical volumes. Physical volumes are further grouped into logical volumes. When Haystack stores a photo on a logical volume, the photo is written to all corresponding physical volumes for redundancy. The Directory maintains the logical to physical mapping along with other application metadata, such as the logical volume where each photo resides and the logical volumes with free space. The Cache functions as an internal CDN, another level of caching to back up the CDN. http://yaseminavcular.blogspot.com/2010/11/finding-needle-in-haystack-facebooks.html Take away from previous design
Focusing only on caching has limited impact on reducing disk operations for long tail
CDN are not effective for long tail
Would GoogleFS like system be useful ?
Lack of correct RAM/disk ratio in current system
Haystack Solution:
use XFS (extend base file system)
reduce metadata size per picture so all metadata can fit into RAM
store multiple photos per file
so very good price/performance point -better off than buying more NAS appliances
holding all regular size metadata in RAM would be way expensive
design your own CDN (Haystack Cache)
uses distributed hash table
in requested photo can not be find in cache, fetches from Haystack store
This challenge is made more difficult because the data set is not easily partitionable.
Partition is good.
Memcache and MySQL
what we call creation time locality dominates the workload -- a data item is likely to be accessed if it has been recently created.
Given the overall lack of spatial locality, pulling several kilobytes of data into a block cache to answer such queries just pollutes the cache and contributes to the lower overall hit rate in the block cache of a persistent store. http://www.shuatiblog.com/blog/2015/09/02/Facebook-photo-storage/ https://code.facebook.com/posts/685565858139515/needle-in-a-haystack-efficient-storage-of-billions-of-photos/
Old architecture
3 tiers design:
Upload tier receives users’ photo uploads, scales the original images and saves them on the NFS storage tier.
Photo serving tier receives HTTP requests for photo images and serves them from the NFS storage tier.
NFS storage tier built on top of commercial storage appliances. Network File System (NFS) is a distributed file system protocol originally developed by Sun Microsystems in 1984, allowing a user on a client computer to access files over a network much like local storage is accessed.
problem
there is an enormous amount of metadata
… so much that is exceeds the caching abilities of the NFS storage tier, resulting in multiple I/O operations per photo upload or read request
Solution
relies heavily on CDNs to serve photos.
Cachr: a caching server tier caching Facebook “profile” images.
NFS file handle cache – deployed on the photo serving tier eliminates some of the NFS storage tier metadata overhead
Haystack Photo Infrastructure
The new photo infrastructure merges the photo serving and storage tier into one physical tier. It implements a HTTP based photo server which stores photos in a generic object store called Haystack.
Goal: eliminate any unnecessary metadata overhead for photo read operations, so that each read I/O operation was only reading actual photo data
5 main functional layers:
HTTP server
Photo Store
Haystack Object Store
Filesystem
Storage
The commodity machine HW typically is 2x quadcore CPU + 32GB RAM + 512MB NV-RAM cache + 12TB SATA drives. Non-volatile random-access memory (NVRAM) is random-access memory that retains its information when power is turned off (non-volatile).
This is in contrast to dynamic random-access memory (DRAM) and static random-access memory (SRAM)
So each storage blade is around 10TB. Configured as RAID-6 partition.
RAID 6, also known as double-parity RAID, uses two parity stripes on each disk. It allows for two disk failures within the RAID set before any data is lost.
Pros:
adequate redundancy
excellent read performance
low storage cost down
Cons:
The poor write performance is partially mitigated by the RAID controller NVRAM write-back cache. Since the reads are mostly random, the NVRAM cache is fully reserved for writes.
The disk caches are disabled in order to guarantee data consistency in the event of a crash or a power loss.
Traditional NFS based desgin (Each image stored as a file) has metadata bottleneck: large metadata size severely limits the metadata hit ratio.
Explain more about the metadata overhead
For the Photos application most of this metadata, such as permissions, is unused and thereby wastes storage capacity. Yet the more significant cost is that the file’s metadata must be read from disk into memory in order to find the file itself. While insignificant on a small scale, multiplied over billions of photos and petabytes of data, accessing metadata is the throughput bottleneck.
Solution
Eliminates the metadata overhead by aggregating hundreds of thousands of images in a single haystack store file.
Architecture
Data Layout
index file (for quick memory load) + haystack store file containing needles.
index file layout
haystack store file
CRUD Operations
Create: write to store file and then async write index file, because index is not critical