The Architecture of Open Source Applications (Volume 2): Scalable Web Architecture and Distributed Systems
The Architecture of Open Source Applications (Volume 2): Scalable Web Architecture and Distributed Systems
Availability
Performance
Reliability: A system needs to be reliable, such that a request for data will consistently return the same data. In the event the data changes or is updated, then that same request should return the new data. Users need to know that if something is written to the system, or stored, it will persist and can be relied on to be in place for future retrieval. Scalability
Manageability: Designing a system that is easy to operate is another important consideration. The manageability of the system equates to the scalability of operations: maintenance and updates. Things to consider for manageability are the ease of diagnosing and understanding problems when they occur, ease of making updates or modifications, and how simple the system is to operate. (I.e., does it routinely operate without failure or exceptions?)
Cost
services, redundancy, partitions, and handling failure
Services
When considering scalable system design, it helps to decouple functionality and think about each part of the system as its own service with a clearly defined interface.
For these types of systems, each service has its own distinct functional context, and interaction with anything outside of that context takes place through an abstract interface, typically the public-facing API of another service.
Deconstructing a system into a set of complementary services decouples the operation of those pieces from one another.
This abstraction helps establish clear relationships between the service, its underlying environment, and the consumers of that service.
Creating these clear delineations can help isolate problems, but also allows each piece to scale independently of one another.
This sort of service-oriented design for systems is very similar to object-oriented design for programming.
such a scenario makes it easy to see how longer writes will impact the time it takes to read the images (since they two functions will be competing for shared resources).
Depending on the architecture this effect can be substantial. Even if the upload and download speeds are the same (which is not true of most IP networks, since most are designed for at least a 3:1 download-speed:upload-speed ratio), read files will typically be read from cache, and writes will have to go to disk eventually (and perhaps be written several times in eventually consistent situations). Even if everything is in memory or read from disks (like SSDs), database writes will almost always be slower than reads.
Another potential problem with this design is that a web server like Apache or lighttpd typically has an upper limit on the number of simultaneous connections it can maintain (defaults are around 500, but can go much higher) and in high traffic, writes can quickly consume all of those. Since reads can be asynchronous, or take advantage of other performance optimizations like gzip compression or chunked transfer encoding, the web server can switch serve reads faster and switch between clients quickly serving many more requests per second than the max number of connections (with Apache and max connections set to 500, it is not uncommon to serve several thousand read requests per second). Writes, on the other hand, tend to maintain an open connection for the duration for the upload, so uploading a 1MB file could take more than 1 second on most home networks, so that web server could only handle 500 such simultaneous writes.
Figure 1.2: Splitting out reads and writes
Planning for this sort of bottleneck makes a good case to split out reads and writes of images into their own services, shown inFigure 1.2. This allows us to scale each of them independently (since it is likely we will always do more reading than writing), but also helps clarify what is going on at each point. Finally, this separates future concerns, which would make it easier to troubleshoot and scale a problem like slow reads.
The advantage of this approach is that we are able to solve problems independently of one another—we don't have to worry about writing and retrieving new images in the same context. Both of these services still leverage the global corpus of images, but they are free to optimize their own performance with service-appropriate methods (for example, queuing up requests, or caching popular images—more on this below). And from a maintenance and cost perspective each service can scale independently as needed, which is great because if they were combined and intermingled, one could inadvertently impact the performance of the other as in the scenario discussed above.
determine the system needs (heavy reads or writes or both, level of concurrency, queries across the data set, ranges, sorts, etc.), benchmark different alternatives, understand how the system will fail, and have a solid plan for when failure happens.
Redundancy
ensuring that multiple copies or versions are running simultaneously can secure against the failure of a single node.
Creating redundancy in a system can remove single points of failure and provide a backup or spare functionality if needed in a crisis.
For example, in our image server application, all images would have redundant copies on another piece of hardware somewhere (ideally in a different geographic location in the event of a catastrophe like an earthquake or fire in the data center), and the services to access the images would be redundant, all potentially servicing requests. (See Figure 1.3.) (Load balancers are a great way to make this possible, but there is more on that below).
Figure 1.3: Image hosting application with redundancy
Partitions
When it comes to horizontal scaling, one of the more common techniques is to break up your services into partitions, or shards. The partitions can be distributed such that each logical set of functionality is separate; this could be done by geographic boundaries, or by another criteria like non-paying versus paying users. The advantage of these schemes is that they provide a service or data store with added capacity.
In our image server example, it is possible that the single file server used to store images could be replaced by multiple file servers, each containing its own unique set of images.
Of course there are challenges distributing data or functionality across multiple servers. One of the key issues is data locality; in distributed systems the closer the data to the operation or point of computation, the better the performance of the system. Therefore it is potentially problematic to have data spread across multiple servers, as any time it is needed it may not be local, forcing the servers to perform a costly fetch of the required information across the network.
Another potential issue comes in the form of inconsistency. When there are different services reading and writing from a shared resource, potentially another service or data store, there is the chance for race conditions—where some data is supposed to be updated, but the read happens prior to the update—and in those cases the data is inconsistent.
scaling access to the data
As they grow, there are two main challenges: scaling access to the app server and to the database. In a highly scalable application design, the app (or web) server is typically minimized and often embodies a shared-nothing architecture. This makes the app server layer of the system horizontally scalable. As a result of this design, the heavy lifting is pushed down the stack to the database server and supporting services; it's at this layer where the real scaling and performance challenges come into play.
Caches
Caches can exist at all levels in architecture, but are often found at the level nearest to the front end, where they are implemented to return data quickly without taxing downstream levels. browser caches, cookies, and URL rewriting
Global Cache
Distributed Cache
Facebook then use a global cache that is distributed across many servers (see "Scaling memcached at Facebook"), such that one function call accessing the cache could make many requests in parallel for data stored on different Memcached servers. This allows them to get much higher performance and throughput for their user profile data, and have one central place to update data (which is important, since cache invalidation and maintaining consistency can be challenging when you are running thousands of servers).
Typically, proxies are used to filter requests, log requests, or sometimes transform requests (by adding/removing headers, encrypting/decrypting, or compression).
Proxies are also immensely helpful when coordinating requests from multiple servers, providing opportunities to optimize request traffic from a system-wide perspective. One way to use a proxy to speed up data access is to collapse the same (or similar) requests together into one request, and then return the single result to the requesting clients. This is known as collapsed forwarding.
Another great way to use the proxy is to not just collapse requests for the same data, but also to collapse requests for data that is spatially close together in the origin store (consecutively on disk).
It is worth noting that you can use proxies and caches together, but generally it is best to put the cache in front of the proxy, for the same reason that it is best to let the faster runners start first in a crowded marathon race. This is because the cache is serving data from memory, it is very fast, and it doesn't mind multiple requests for the same result. But if the cache was located on the other side of the proxy server, then there would be additional latency with every request before the cache, and this could hinder performance.
Indexes
An index makes the trade-offs of increased storage overhead and slower writes (since you must both write the data and update the index) for the benefit of faster reads. Indexes can also be used to create several different views of the same data.
Database index, solr: inverted index for text search
Load Balancers
There are many different algorithms that can be used to service requests, including picking a random node, round robin, or even selecting the node based on certain criteria, such as memory or CPU utilization. Load balancers can be implemented as software or hardware appliances. One open source software load balancer that has received wide adoption is HAProxy).
One of the challenges with load balancers is managing user-session-specific data. One way around this can be to make sessions sticky so that the user is always routed to the same node, but then it is very hard to take advantage of some reliability features like automatic failover. If a system only has a couple of a nodes, systems like round robin DNS may make more sense since load balancers can be expensive and add an unneeded layer of complexity. Load balancers also provide the critical function of being able to test the health of a node, such that if a node is unresponsive or over-loaded, it can be removed from the pool handling requests, taking advantage of the redundancy of different nodes in your system.
Queues
another important part of scaling the data layer is effective management of writes. achieving performance and availability requires building asynchrony into the system; a common way to do that is with queues. This kind of synchronous behavior can severely degrade client performance; the client is forced to wait, effectively performing zero work, until its request can be answered. Queues enable clients to work in an asynchronous manner, providing a strategic abstraction of a client's request and its response.
In an asynchronous system the client requests a task, the service responds with a message acknowledging the task was received, and then the client can periodically check the status of the task, only requesting the result once it has completed. While the client is waiting for an asynchronous request to be completed it is free to perform other work, even making asynchronous requests of other services
-- retry request Queues also provide some protection from service outages and failures. For instance, it is quite easy to create a highly robust queue that can retry service requests that have failed due to transient server failures. It is more preferable to use a queue to enforce quality-of-service guarantees than to expose clients directly to intermittent service outages, requiring complicated and often-inconsistent client-side error handling.
以我们的图像服务器为例,将曾经储存在单一的文件服务器的图片重新保存到多个文件服务器中是可以实现的,每个文件服务器都有自己惟一的图片集。(见图表1.4。)这种构架允许系统将图片保存到某个文件服务器中,在服务器都即将存满时,像增加硬盘一样增加额外的服务器。这种设计需要一种能够将文件名和存放服务器绑定的命名规则。一个图像的名称可能是映射全部服务器的完整散列方案的形式。或者可选的,每个图像都被分配给一个递增的 ID,当用户请求图像时,图像检索服务只需要保存映射到每个服务器的 ID 范围(类似索引)就可以了。
Interestingness is what Flickr calls the criteria used for selecting which photos are shown in Explore. All photos are given an Interestingness "score" that can also be used to sort any image search on Flickr. The top 500 photos ranked by Interestingness are shown in Explore. Interestingness rankings are calculated automatically by a secret computer algorithm. The algorithm is often referred to by name as the Interestingness algorithm. Although the algorithm is secret, Flickr has stated that many factors go into calculating Interestingness including: a photo's tags, how many groups the photo is in, views, favorites, where click-throughs are coming from, who comments on a photo and when, and more. The velocity of any of those components is a key factor. For example, getting 20 comments in an hour counts much higher than getting 20 comments in a week.
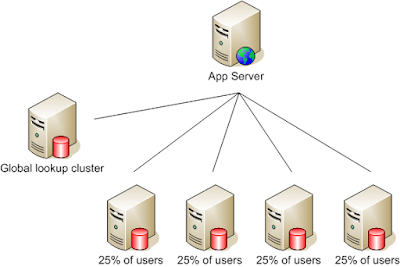
Shards are set up in Active Master-Master Ring Replication
a)Done by sticking a user to a server in a shard
b)Shard assignments are from a random number for new accounts
2.Global Ring
Lookup Ring
For stuff that can’t be for a shard
3.PHP logic to connect to the shards and keep the data consistent
3.Search Farm
问题:一般读写比例是:80/20,或者90/10。那从读方面优化,大家还记得有哪些常用的技巧吗?
(Yang)cdn
(Shirley)cache, replica
问题:replica和duplicate是一样的吗?
Database duplication generally refers to restoring a physical backup of a database to a different server (preferably using RMAN). That is normally done periodically to refresh lower environments from production.
Database replication generally refers to the process of copying a subset of data from one database to another on an ongoing basis. Replication generally implies that the data is being copied from one production database to another production database (or a test database to a test database, etc.)
附上解释:A federated database system is a type of meta-database management system (DBMS), which transparently maps multiple autonomous database systems into a single federated database.