https://medium.com/netflix-techblog/scaling-event-sourcing-for-netflix-downloads-episode-1-6bc1595c5595
How Streaming Playback Works
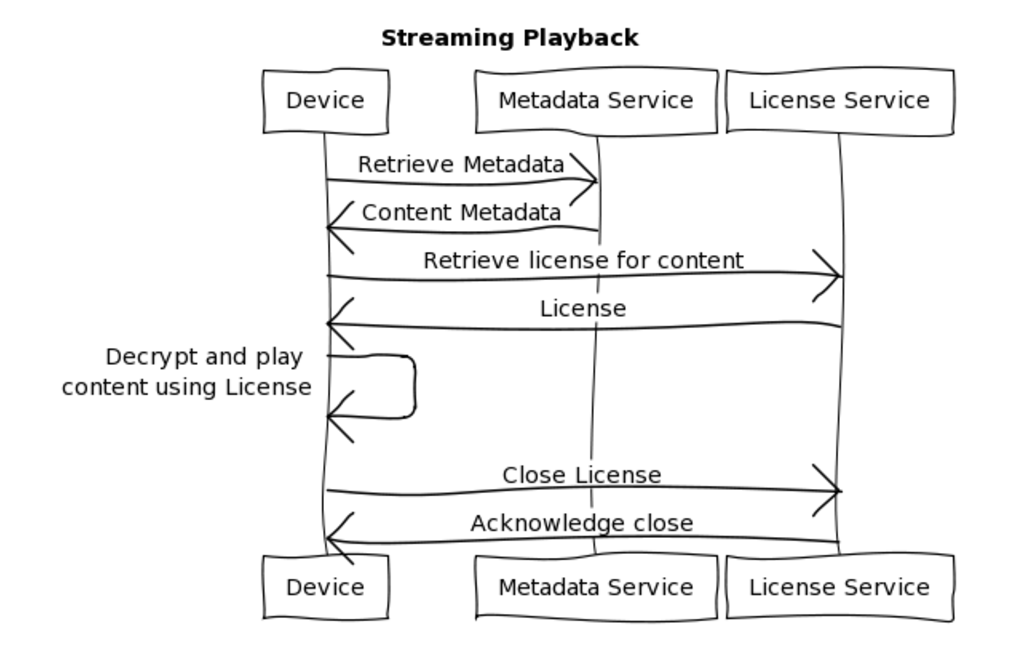 To play a title, the member’s device retrieves all the metadata associated with the content. The response object is known as the Playback Context, and includes data such as the image assets for the content and the URLs for streaming the content
To play a title, the member’s device retrieves all the metadata associated with the content. The response object is known as the Playback Context, and includes data such as the image assets for the content and the URLs for streaming the content
The streamed data is encrypted with Digital Rights Management (DRM) technology and must be decrypted before it can be watched. This is done through the process of licensing, where a device can request a license for a particular title, and the license is then used to decrypt the content on that device. In the streaming case, the license is short-lived, and only able to be used once. When the member finishes watching the content, the license is considered consumed and no longer able to be used for playback.
Netflix supports several different DRM technologies to enable licensing for the content. Each of these live in their own microservice, requiring independent scaling and deployment tactics.
To reduce the risks to availability and resiliency, and to allow for flexible scaling, the licensing services have traditionally been stateless.
https://medium.com/netflix-techblog/scaling-event-sourcing-for-netflix-downloads-episode-2-ce1b54d46eec
https://www.alexecollins.com/event-sourcing-vs-crud/
https://github.com/eventuate-local/eventuate-local
https://github.com/cer/event-sourcing-examples
How Streaming Playback Works
The streamed data is encrypted with Digital Rights Management (DRM) technology and must be decrypted before it can be watched. This is done through the process of licensing, where a device can request a license for a particular title, and the license is then used to decrypt the content on that device. In the streaming case, the license is short-lived, and only able to be used once. When the member finishes watching the content, the license is considered consumed and no longer able to be used for playback.
Netflix supports several different DRM technologies to enable licensing for the content. Each of these live in their own microservice, requiring independent scaling and deployment tactics.
To reduce the risks to availability and resiliency, and to allow for flexible scaling, the licensing services have traditionally been stateless.
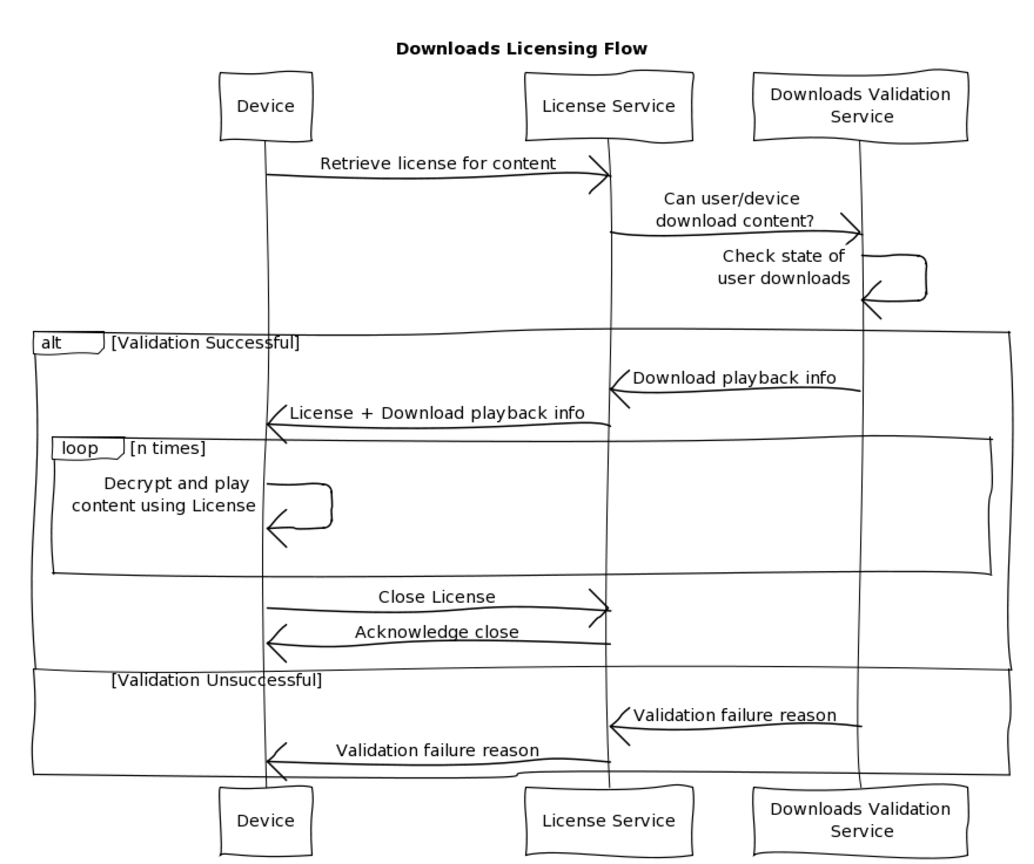
The license used for downloaded content is also different from streaming — it may be persisted on the device for a longer period of time, and can be reused over multiple playback sessions.
Every time a member presses play on the downloaded content, the application queues up session events to provide information on the viewing experience, and sends those up the next time the member goes online. After a defined duration for each title however, the original license retrieved with the downloaded content expires. At this point, depending on the content, it may be possible to renew the license, which requires the device to ask the back-end for a renewed license. This renewal is also validated against the business rules for downloads and, if successful, allows the content to continue to be played offline. Once the member deletes the content, the license is securely closed (released) which ensures the content can no longer be played offline.
Anyone who’s familiar with relational databases knows that the phrases ‘flexible’ and ‘easy to change’ are not overly true with regards to the underlying table schema. There are ways to change the schema, but they are not easily accessible, require a deep knowledge of SQL, and direct interaction with the database. In addition, once the data is mutated you lose valuable context to the cause of the change and what the previous state was.
Document oriented NoSQL databases are known for providing such flexibility to change, and we quickly moved in that direction as a means to provide a flexible and scalable solution
The document model provides us with the flexibility we need for the data model, but doesn’t provide us with the traceability to determine what caused the data mutation. Given the longevity of the data, we wanted the ability to look back in time to debug a change in state.
Martin Fowler describes the basic pattern as follows: “The fundamental idea of Event Sourcing is that of ensuring every change to the state of an application is captured in an event object, and that these event objects are themselves stored in the sequence they were applied for the same lifetime as the application state itself.”
- Event Sourcing, by Martin Fowler
- Pattern: Event Sourcing, by Chris Richardson
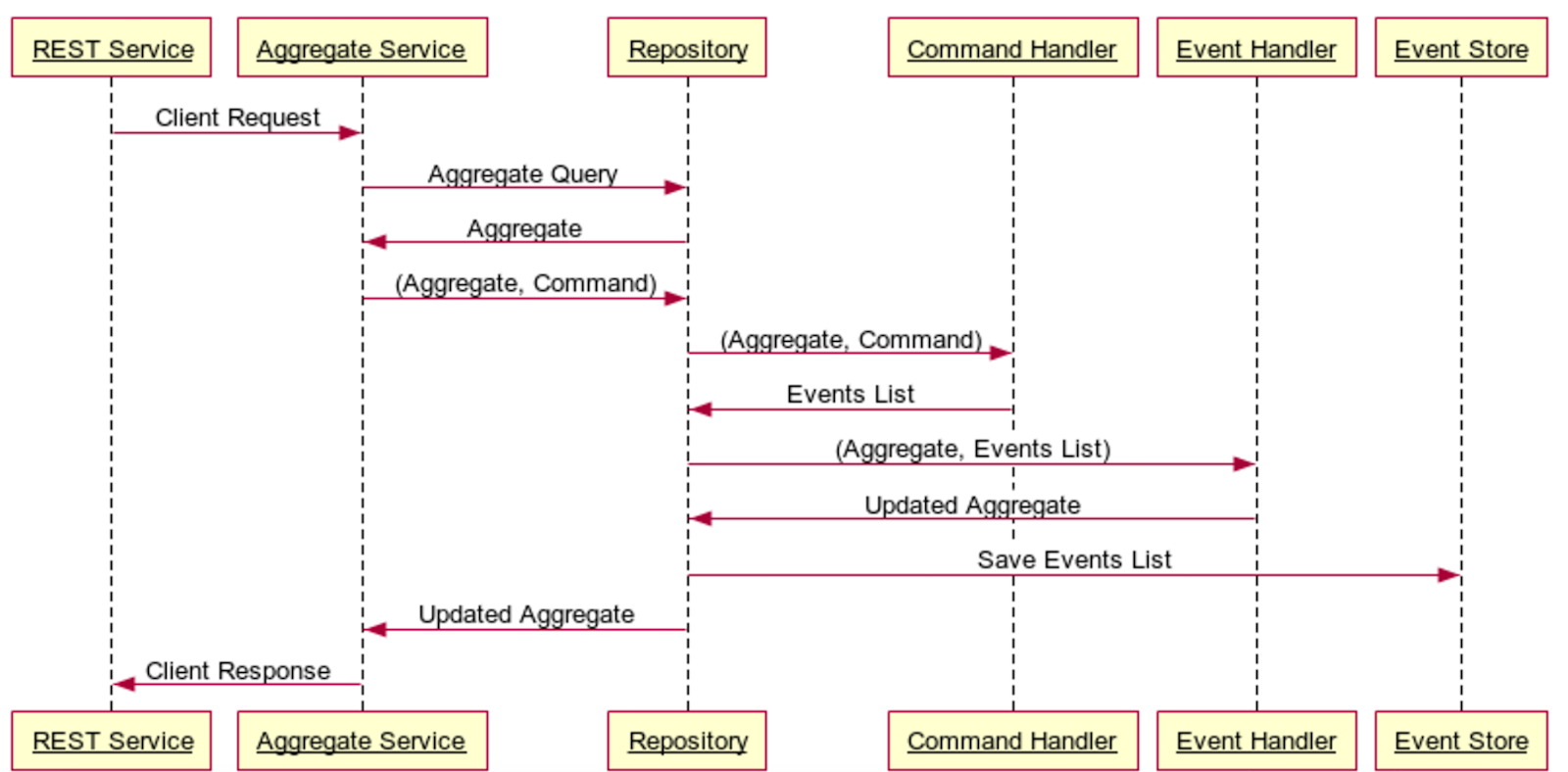
- A Command represents the client request to change the state of the Aggregate. The Command is used by the Command Handler to determine how to create a list of Events needed to satisfy the Command.
- An Event is an immutable representation of a change of state for the Aggregate, i.e., the action taken to change the state. Events are always represented in the past tense.
- An Aggregate is the aggregated representation of the current state of the domain model. The Aggregate takes a stream of events and determines how to represent the aggregated data for the requested business logic purpose.
- The REST Service is the application layer that accepts requests from the client and passes them on to the Aggregate Service.
- The Aggregate Service handles client requests. The Aggregate Service queries for existing Aggregates and if one does not exist, can create an empty Aggregate. The Aggregate Service then generates the Command associated with the request and passes the Command, along with the Aggregate, to the Command Handler.
- The Command Handler takes the Aggregate and the Command and assesses, based on state transition validity checks, whether or not the Command can be applied to the Aggregate in its current state. If the state transition is valid, the Command Handler creates an Event and passes the Event and Aggregate to the Event Handler.
- The Event Handler applies the Events to the Aggregate, resulting in a new Aggregate state, and passes the list of Events to the Repository Service.
- The Repository Service manages state by applying the newly created Events to the Aggregate. The events are then saved to the Event Store, resulting in the new state of the Aggregate to be available in our system.
- The Event Store is an abstracted interaction for event read/write functionality with the backing database.
https://www.alexecollins.com/event-sourcing-vs-crud/
- The ability to recreate historical state.
- Performance (events are typically smaller than the aggregate).
- Simplified testing (due to functional nature of events and their application to the aggregate).
IMHO, the first question you should ask before you use ES, is do I need historical state? You may well do, if you are doing accounting or financial transactions for examples, but the majority of domains won't need it.
ES comes with a significant complexity burden vs CRUD. This leads to potentially increased development and runtime costs.
- You need somewhere to store your events. There aren't a great number of commercial or OSS solutions, but as you're not using your tried and tested RDMS or NoSQL solution, you'll need to take time to evaluate those solutions. Alternatively, you can develop an in-house solution (as we did with MongoDB).
- You'll need to make sure that you've tested that no side-effects occur, e.g. you don't send another email, when you re-create the aggregate.
- ES can be faster as you're often only doing append only operations. However, if you have an aggregate that has 100s or 1000s of events during its lifetime, to prevent problems with read operations, you'll need to be capturing snapshots. That means writing and testing the code.
- If you have a type of aggregate that can have 1000s of event per aggregate, you'll need to consider your data retention policy. When and how will you archive data from your runtime/working set? You retention policy is probably different for each type of aggregate. You will need a lot more disk space than CRUD.
- If you need to perform any queries on your aggregate, you won't be able to do this without re-creating it. This means that queries will need to be written programmatically.
- If you need to patch an aggregate at runtime, e.g. to fix an issue, do you know how you'll do this?
- As ES is a paradigm shift, you might want to consider the cognitive load that this might put on new developers. I'd note that it just take a bit of time for someone to understand it.
- What happens when you change the domain model? Say you have a command that adds VAT, but you code assuming 20% VAT, and then the rate of VAT changes?
The framework persists events in an
EVENTS table in the SQL database and subscribes to events in Kafka. A change data capture component tails the database transaction log and publishes each event to Kafka. There is a Kafka topic for each aggregate type.
Eventuate Local has a change data capture (CDC) component that
- tails the MySQL transaction log
- publishes each event inserted into the
EVENTStable to Kafka topic for the event’s aggregate.