http://ingest.tips/2015/01/21/handling-large-messages-kafka/
https://www.quora.com/How-do-I-send-Large-messages-80-MB-in-Kafka
The Kafka producer API allows the user to compute the message’s partition from the message key. The result is based on the number of partitions currently hosted in the cluster (DefaultPartitioner in Kafka 1.0).
https://eng.uber.com/reliable-reprocessing/http://www.jdon.com/49366
Unblocked batch processing
Decoupling
Configurability
Observability
Flexibility
https://www.quora.com/How-do-I-send-Large-messages-80-MB-in-Kafka
- The best way to send large messages is not to send them at all. If shared storage is available (NAS, HDFS, S3), placing large files on the shared storage and using Kafka just to send a message about the file’s location is a much better use of Kafka.
- The second best way to send large messages is to slice and dice them. Use the producing client to split the message into small 10K portions, use partition key to make sure all the portions will be sent to the same Kafka partition (so the order will be preserved) and have the consuming client sew them back up into a large message.
- Kafka producer can be used to compress messages. If the original message is XML, there’s a good chance that the compressed message will not be very large at all. Use compression.codec and compressed.topics configuration parameters in the producer to enable compression. GZip and Snappy are both supported.
Large messages are not an afterthought, they have impact on overall design of the cluster and the topics:
- Performance: As we’ve mentioned, benchmarks indicate that Kafka reaches maximum throughput with message size of around 10K. Larger messages will show decreased throughput. Its important to remember this when doing capacity planning for a cluster.
- Available memory and number of partitions: Brokers will need to allocate a buffer the size of replica.fetch.max.bytes for each partition they replicate. So if replica.fetch.max.bytes = 1MB and you have 1000 partitions, that will take around 1GB of RAM. Do the math and make sure the number of partitions * the size of the largest message does not exceed available memory, or you’ll see OOM errors. Same for consumers and fetch.message.max.bytes – make sure there’s enough memory for the largest message for each partition the consumer replicates. This may mean that you end up with fewer partitions if you have large messages, or you may need servers with more RAM.
- Garbage collection - I did not personally see this issue, but I think its a reasonable concern. Large messages may cause longer garbage collection pauses (as brokers need to allocate large chunks), keep an eye on the GC log and on the server log. If long GC pauses cause Kafka to lose the zookeeper session, you may need to configure longer timeout values for zookeeper.session.timeout.ms.
The Kafka producer API allows the user to compute the message’s partition from the message key. The result is based on the number of partitions currently hosted in the cluster (DefaultPartitioner in Kafka 1.0).
When a Kafka message containing a chunk is received, it is kept locally and not returned to the user (as one would see no benefit in getting just a part of the payload). Only when all chunks have been collected are they assembled together into a single message and returned to the user.
Cleaning up this store might be needed after offset-changing operations, as seeking into a position between chunks could have returned a full message, when the user intended to seek to a later point (after the head of the message). Example: for a six chunk message, we already have received chunks 1, 2, and 3. After seeking to position three again, we’d have consumed chunks: 3 (again), 4, 5 and 6 (the new ones). This means that all chunks have been received, while chunks 1 and 2 were received before the seek operation, and should have not been made available to the user. In the previous diagrams, the offset to seek for would be `N+1`.
https://eng.uber.com/reliable-reprocessing/http://www.jdon.com/49366
In distributed systems, retries are inevitable. From network errors to replication issues and even outages in downstream dependencies, services operating at a massive scale must be prepared to encounter, identify, and handle failure as gracefully as possible.
While retrying at the client level with a feedback cycle can be useful, retries in large-scale systems may still be subject to:
- Clogged batch processing. When we are required to process a large number of messages in real time, repeatedly failed messages can clog batch processing. The worst offenders consistently exceed the retry limit, which also means that they take the longest and use the most resources. Without a success response, the Kafka consumer will not commit a new offset and the batches with these bad messages would be blocked, as they are re-consumed again and again, as illustrated in Figure 2, below.
- Difficulty retrieving metadata. It can be cumbersome to obtain metadata on the retries, such as timestamps and nth retry.
If requests continue to fail retry after retry, we want to collect these failures in a DLQ for visibility and diagnosis. A DLQ should allow listing for viewing the contents of the queue, purging for clearing those contents, and merging for reprocessing the dead-lettered messages, allowing comprehensive resolution for all failures affected by a shared issue. At Uber, we needed a retry strategy that would reliably and scalably afford us these capabilities .
Processing in separate queues
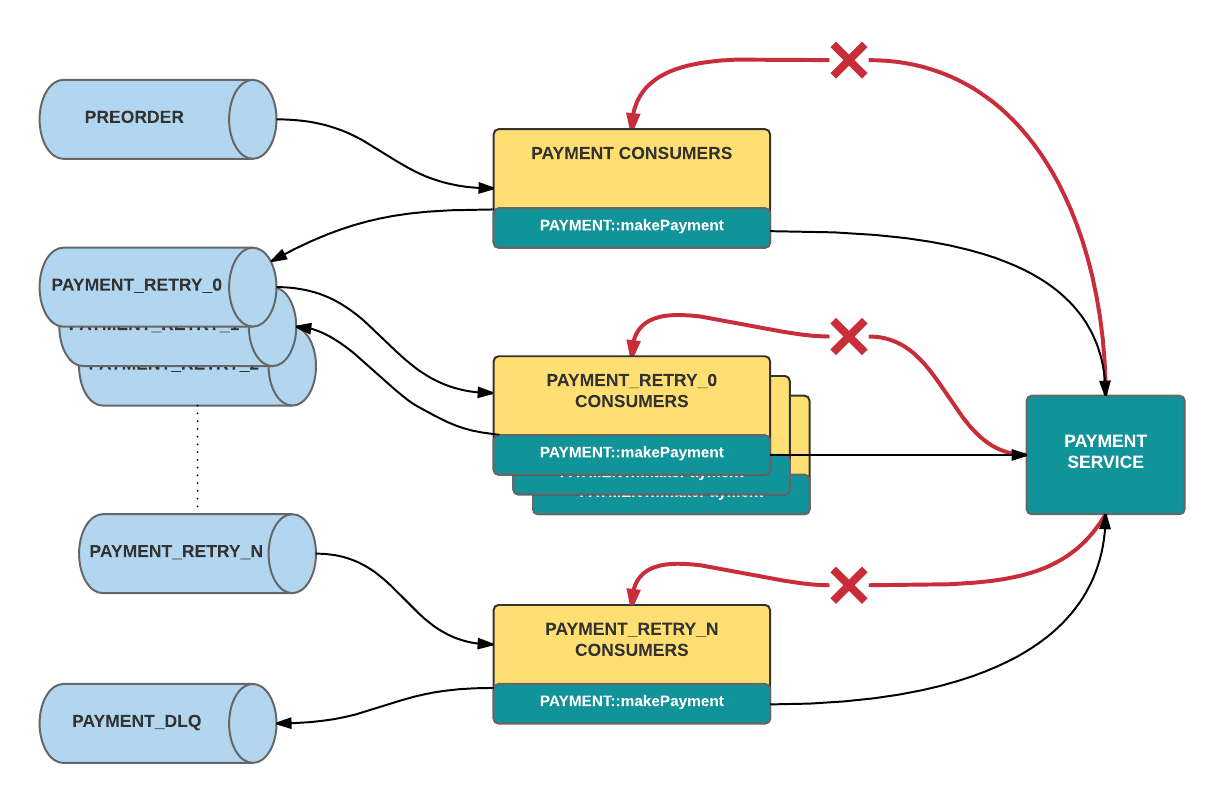
To address the problem of blocked batches, we set up a distinct retry queue using a separately defined Kafka topic. Under this paradigm, when a consumer handler returns a failed response for a given message after a certain number of retries, the consumer publishes that message to its corresponding retry topic. The handler then returns true to the original consumer, which commits its offset.
Retrying requests in this type of system is very straightforward. As with the main processing flow, a separate group of retry consumers will read off their corresponding retry queue. These consumers behave like those in the original architecture, except that they consume from a different Kafka topic. Meanwhile, executing multiple retries is accomplished by creating multiple topics, with a different set of listeners subscribed to each retry topic. When the handler of a particular topic returns an error response for a given message, it will publish that message to the next retry topic below it, as depicted in Figures 3 and 4.
Finally, the DLQ is defined as the end-of-the-line Kafka topic in this design. If a consumer of the last retry topic still does not return success, then it will publish that message to the dead letter topic. From there, a number of techniques can be employed for listing, purging, and merging from the topic, such as creating a command-line tool backed by its own consumer that uses offset tracking. Dead letter messages are merged to re-enter processing by being published back into the first retry topic. This way, they remain separate from, and are unable to impede, live traffic.

Figure 4: Errors trickle down levels of retry topics until landing in the DLQ.
It is important not to simply re-attempt failed requests immediately one after the other; doing so will amplify the number of calls, essentially spamming bad requests. Rather, each subsequent level of retry consumers can enforce a processing delay, in other words, a timeout that increases as a message steps down through each retry topic. This mechanism follows a leaky bucket pattern where flow rate is expressed by the blocking nature of the delayed message consumption within the retry queues. Consequently, our queues are not so much retry queues as they are delayed processing queues, where the re-execution of error cases is our best-effort delivery: handler invocation will occur at least after the configured timeout but possibly later.
Decoupling
Configurability
Observability
Flexibility