https://rockset.com/blog/aggregator-leaf-tailer-an-architecture-for-live-analytics-on-event-streams/
ALT: Real-Time Analytics Without Pipelines
The ALT architecture addresses these shortcomings of Lambda architectures. The key component of ALT is a high-performance serving layer that serves complex queries, and not just key-value lookups. The existence of this serving layer obviates the need for complex data pipelines.
The ALT architecture described:
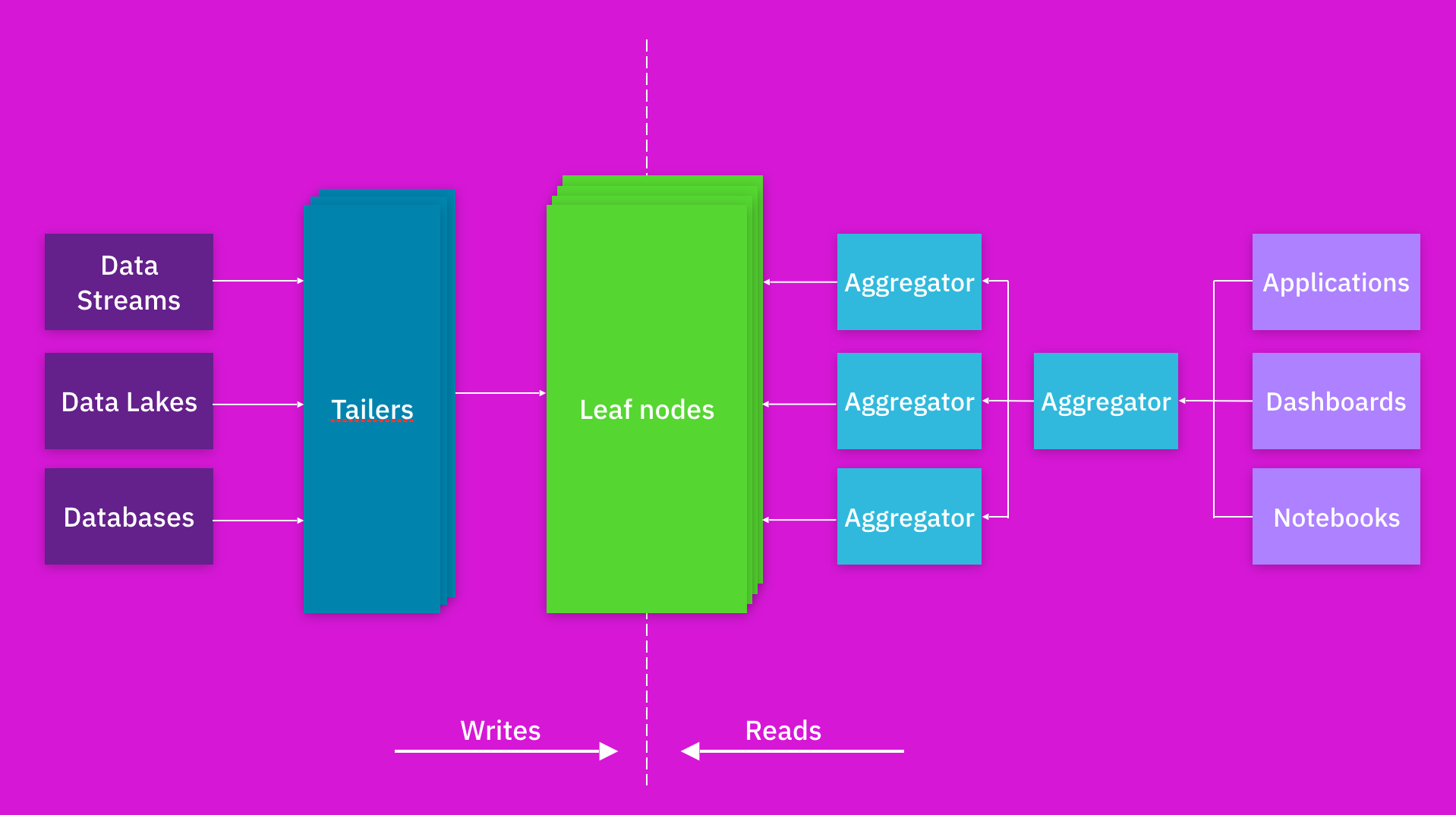
The Tailer pulls new incoming data from a static or streaming source into an indexing engine. Its job is to fetch from all data sources, be it a data lake, like S3, or a dynamic source, like Kafka or Kinesis.
The Leaf is a powerful indexing engine. It indexes all data as and when it arrives via the Tailer. The indexing component builds multiple types of indexes—inverted, columnar, document, geo, and many others—on the fields of a data set. The goal of indexing is to make any query on any data field fast.
The scalable Aggregator tier is designed to deliver low-latency aggregations, be it columnar aggregations, joins, relevance sorting, or grouping. The Aggregators leverage indexing so efficiently that complex logic typically executed by pipeline software in other architectures can be executed on the fly as part of the query.
The ALT architecture enables the app developer or data scientist to run low-latency queries on raw data sets without any prior transformation. A large portion of the data transformation process can occur as part of the query itself. How is this possible in the ALT architecture?
Indexing is critical to making queries fast. The Leaves maintain a variety of indexes concurrently, so that data can be quickly accessed regardless of the type of query—aggregation, key-value, time series, or search. Every document and field is indexed, including both value and type of each field, resulting in fast query performance that allows significantly more complex data processing to be inserted into queries.
Queries are distributed across a scalable Aggregator tier. The ability to scale the number of Aggregators, which provide compute and memory resources, allows compute power to be concentrated on any complex processing executed on the fly.
The Tailer, Leaf, and Aggregator run as discrete microservices in disaggregated fashion. Each Tailer, Leaf, or Aggregator tier can be independently scaled up and down as needed. The system scales Tailers when there is more data to ingest, scales Leaves when data size grows, and scales Aggregators when the number or complexity of queries increases. This independent scalability allows the system to bring significant resources to bear on complex queries when needed, while making it cost-effective to do so.
The most significant difference is that the Lambda architecture performs data transformations up front so that results are pre-materialized, while the ALT architecture allows for query on demand with on-the-fly transformations.
Why ALT Makes Sense Today
While not as widely known as the Lambda architecture, the ALT architecture has been in existence for almost a decade, employed mostly on high-volume systems.
Facebook’s
Multifeed architecture has been using the ALT methodology since 2010, backed by the open-source
RocksDB engine, which allows large data sets to be indexed efficiently.
LinkedIn’s
FollowFeed was redesigned in 2016 to use the ALT architecture. Their previous architecture, like the Lambda architecture discussed above, used a pre-materialization approach, also called fan-out-on-write, where results were precomputed and made available for simple lookup queries. LinkedIn's new ALT architecture uses a query on demand or fan-out-on-read model using RocksDB indexing instead of Lucene indexing. Much of the computation is done on the fly, allowing greater speed and flexibility for developers in this approach.
Rockset uses RocksDB as a foundational data store and implements the ALT architecture (see
white paper) in a cloud service.
The ALT architecture clearly has the performance, scale, and efficiency to handle real-time use cases at some of the largest online companies. Why has it not been used as widely till recently? The short answer is that “indexing” software is traditionally costly, and not commercially viable, when data size is large. That ruled out many smaller organizations from pursuing an ALT, query-on-demand approach in the past. But the current state of technology—the combination of powerful indexing software built on open-source RocksDB and favorable
cloud economics—has made ALT not only commercially feasible today, but an elegant architecture for real-time data processing and analytics.
https://engineering.linkedin.com/blog/2016/03/followfeed--linkedin-s-feed-made-faster-and-smarter