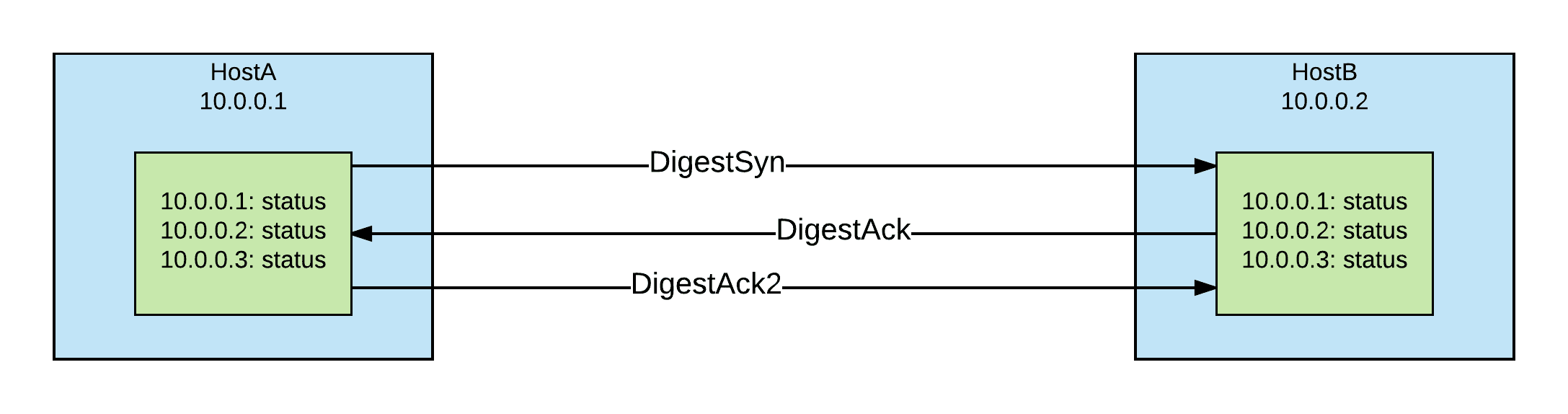
 States are just collection of versioned key/value, so if there's newer version, which means the value is changed. Cassandra Gossip won't send out all the states out for syncing. It sends out version digests and only exchange the states that are out of date. Here is the process:
States are just collection of versioned key/value, so if there's newer version, which means the value is changed. Cassandra Gossip won't send out all the states out for syncing. It sends out version digests and only exchange the states that are out of date. Here is the process:

- DigestSynMessage:
- HostA sends out GossipeDigestSynMessage every second. It contains the largest version of local states.
- HostB receives this message, it sort and compare the versions with local ones. Then it knows which local states are out of date, which ones are newer than remote status (HostA). Then it build following message, tells HostA these information:
- DigestAckMessage:
- Basically
digest_list contains status that HostB need from HostA. state_map contains status information that NodeA need. In this example, HostB doesn't have the latest info from HostA, HostA doesn't have the latest info from HostB, HostC status are up to date for both hosts.
- When HostA gets the message, it apply the
state_map to local states. And then build following message with the list from digest_list.
- DigestAck2Message
- HostB receives the message, and simply update local state with the information from
state_map.
- HostA sends out GossipeDigestSynMessage every second. It contains the largest version of local states.
- HostB receives this message, it sort and compare the versions with local ones. Then it knows which local states are out of date, which ones are newer than remote status (HostA). Then it build following message, tells HostA these information:
- Basically
digest_listcontains status that HostB need from HostA.state_mapcontains status information that NodeA need. In this example, HostB doesn't have the latest info from HostA, HostA doesn't have the latest info from HostB, HostC status are up to date for both hosts. - When HostA gets the message, it apply the
state_mapto local states. And then build following message with the list fromdigest_list.
- HostB receives the message, and simply update local state with the information from
state_map.
Each host contains a state_map, which contains state information for each host in the cluster. Each host has the same data structure, Gossip protocol is to sync these states across the cluster. Each state is an versioned key/value. Every host keeps it's own AtomicInteger version variable, and get bumped whenever a state is changed.
state_map, which contains state information for each host in the cluster. Each host has the same data structure, Gossip protocol is to sync these states across the cluster. Each state is an versioned key/value. Every host keeps it's own AtomicInteger version variable, and get bumped whenever a state is changed.HeartBeat and Failure Detection
Generation
Generation never change after Cassandra process starts. It's actually the current time when Cassandra starts.
Version
- HeartBeat Version is the most frequently changing state. Each host increases it's local heartbeat version before sending out
GossipDigestSyn. And this state needs to be spread out to all nodes with Gossip. So lots of Gossip traffic is for HeartBeat.
- Cassandra failure detection is implemented with HeartBeat information. Each host keeps new heartbeat version arriving time windows for any other nodes. For example, here is how HostA detects HostB down:

- For every second, HostA bumps the version number and send it out to one host:
- It could be sent (or pull) to HostB directly (like version 1, 3, 6)
- It could be sent (or pull) to other node and then sent to NodeB (like version 4, 5)
- Or very likely, the heartbeat version is already up to date (like version 2). It will be dropped.
- The heartbeat version is increasing but not continuously. Because other state value might also change and bump the globle version too.
- Currently, Cassandra keeps the last 1000 time windows. For a normal environment without network issue, the
mean() for time windows interval is about 1 ~ 1.1 seconds. 1 second means every heartbeat is synced. 1.1 means about 1 in 10 heartbeat isn't synced before new heartbeat version arrived.
- When no update time interval is bigger than
mean() * ln(10) * phi_convict_threshold, that host will be marked as dead. Default phi_convict_threshold is 8, ln(10) x 8 = 2.3 x 8 = 18.4. Which means even in best case, the failure detection delay is 18seconds, typically it's about 20 seconds 18.4 x 1.1 = 20.3.
GossipDigestSyn. And this state needs to be spread out to all nodes with Gossip. So lots of Gossip traffic is for HeartBeat.- It could be sent (or pull) to HostB directly (like version 1, 3, 6)
- It could be sent (or pull) to other node and then sent to NodeB (like version 4, 5)
- Or very likely, the heartbeat version is already up to date (like version 2). It will be dropped.
- The heartbeat version is increasing but not continuously. Because other state value might also change and bump the globle version too.
- Currently, Cassandra keeps the last 1000 time windows. For a normal environment without network issue, the
mean()for time windows interval is about 1 ~ 1.1 seconds. 1 second means every heartbeat is synced. 1.1 means about 1 in 10 heartbeat isn't synced before new heartbeat version arrived. - When no update time interval is bigger than
mean() * ln(10) * phi_convict_threshold, that host will be marked as dead. Defaultphi_convict_thresholdis 8,ln(10) x 8 = 2.3 x 8 = 18.4. Which means even in best case, the failure detection delay is 18seconds, typically it's about 20 seconds18.4 x 1.1 = 20.3.
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-cassandra3x3/index.html