https://blog.scrapinghub.com/2015/08/05/distributed-frontera-web-crawling-at-large-scale
Hubs are web pages that contain a large number of outgoing links to authority sites. For example, Reddit, the DMOZ Directory and Hacker News are hubs because they point to a lot of pages with authoritative content. Authorities are sites that obtain a high authority score, determined by the relevant information on the page and its authoritative sources
 Read full article from Algo Ramblings: Design a web crawler
Read full article from Algo Ramblings: Design a web crawler
TODO:http://www.ijcaonline.org/volume15/number7/pxc3872629.pdf
http://www.slideshare.net/gnap/design-and-implementation-of-a-high-performance-distributed-web-crawler
https://benbernardblog.com/the-tale-of-creating-a-distributed-web-crawler/
Given a seed URL, the crawler needed to auto-discover the value of the missing fields for a particular record. So if a web page didn't contain the information that I was looking for, the crawler needed to follow outbound links, until the information was found.
It needed to be some kind of crawler-scraper hybrid, because it had to simultaneously follow outbound links and extract specific information from web pages.
The scraped data needed to be stored somewhere, most likely in a database.
http://www.1point3acres.com/bbs/thread-148865-1-1.html
2. consistent hashing
3. assign task with a random delay
Algo Ramblings: Design a web crawler
Crawler basic algorithm
General architecture
What pages should the crawler download ?
How should the crawler refresh pages ?
How should the load on the visited web sites be minimized ?
How should the crawling process be parallelized ?
http://baozitraining.org/blog/design-a-basic-web-crawler/
the internet could be abstracted as a directed graph, with each page as a node and hyperlinks as an edge.
How to crawl?
BFS is normally used.
Decide what you want to crawl?
Scope: crawl whole internet or just company web site.
Having a few websites in your crawler’s most frequent list to crawl, such as some authoritative news website, etc
You should have lots of fetchers living on many host classes. Use machine learning to predict which websites are most likely to have frequent update, put those into the fetchers’ priority queue.
Hot to track what your fetchers have crawled?
You don’t want your fetchers to crawl some website over and over again while other websites don’t get crawled at all. There are many ways to achieve this. For example, your scheduler should generate non-duplicate jobs for fetchers. Or,
your fetchers could keep track off the last visited time for each URL. Note, due to the scalability, a consistent hashmap is needed.
Respect the standard?
If a crawler sees a robots.txt on a site, it should skip crawling it.
You need to have some ways to execute those javascript and get the URL.
How to rank:
Page rank algorithm
Forget about the fact that you’re dealing with billions of pages. How would you design this system if it were just a small number of pages? You should have an understanding of how you would solve the simple, small case in order to understand how you would solve the bigger case.
2. Now, think about the issues that occur with billions of pages. Most likely you can’t fit
the data on one machine. How will you di
http://blog.semantics3.com/how-we-built-our-almost-distributed-web-crawler/
Data Structure
We use priority search based graph traversal for our web crawling. Its basically breadth first search, but we use a priority queue instead of a queue to determine which URL to crawl next.
==> BFS+score, so we will crawl important pages/sites more timely.
We assign an importance score to each URL which we discover and then crawl them accordingly.
We use Redis sorted sets to store the priority associated with each URL and hashes to store the visited status of the discovered URLs. This, of course, comes with a large memory footprint.
A possible alternative would be to use Bloom filters.
==> False positive actually means that the bloom filter will tell you that you have already visited a URL but you actually haven't. The consequent of this is that you will miss crawling web pages rather than crawling the same page twice.
Recrawling
Since one of the tasks we do is in building price histories of products, recrawling of pages needs to be done intelligently.
We want to recrawl products that frequently change prices frequently (duh) as compared to pages that don’t really change their price.
Hence a brute-force complete recrawl doesn’t really make sense.
We use a power law distribution (some pages are crawled more frequently than other pages) for recrawling products, with pages ranked based on their importance (using signals ranging from previous price history changes to how many reviews they have).
Another challenge is in page discovery (eg: if a new product has been launched, how quickly can we have it in our system).
===> if the crawler is built for companies site, we can provide api so client can add or manually crawl new added pages.
Check resource from https://www.linkedin.com/pulse/20140831103409-27984489-designing-a-search-engine-design-patterns-for-crawlers
http://www.jiuzhang.com/problem/44/
http://blog.baozitraining.org/2014/08/how-to-design-basic-web-crawler.htm
Keep in mind a production web crawler could be very sophisticated and normally takes a few teams weeks/months to develop. The interviewer would not expect you to cover all the detail, but you should be able to mention some key design perspectives.
Coding
https://github.com/jefferyyuan/500lines/tree/master/crawler
http://itsumomono.blogspot.com/2015/08/crawling.html
DNS resolution is a well-known bottleneck in web crawling. DNS resolution may entail multiple requests and round-trips across the internet, requiring seconds and sometimes even longer.
http://systemdesigns.blogspot.com/2015/12/web-crawling-system.html

 - State
- State

3. 有人通知




http://www.cnblogs.com/javanerd/p/5121472.html

TODO:
http://nlp.stanford.edu/IR-book/html/htmledition/web-crawling-and-indexes-1.html
fb面经题web crawler讨论
https://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=436948
给你10K个机器,然后1B的url,机器之间不能通信,问你怎么样每个机器才能平均的分任务
http://www.1point3acres.com/bbs/thread-268942-1-1.html
帖子的楼主在3楼说了一下面试时被面试官引导的方向
“思路就是每台机器都从起始点开始,然后对拿到的url做hash,事先规定好每台机器都只做那些hash value的job,如果hash的值跟当前机器的预定值不一样就skip,一样才继续crawl”
10k机器,都从起点开始,可是起点hash之后只会对应到一台机器,按照^说的方向,那其他所有机器都不用爬就一直空闲下去了
我理解其实就是一致性哈希啊。但是在分配任务之前,需要找到这1B个link,对它们做hash啊。这个事情并不能分布式的做
这是经典的distributed hash table 问题. 从root url开始,下载webpage,从这个page里提取embedded url links, distribute 每个link 到对应负责任的machine. In general, 毎个机器接收url links from peers, 看是否已经访问过,没有的话,放入work queue, 有个thread 专门从queue取url, download page, extract urls, distributes to other machines
如果只能遍历所有数据,一共10K台机器,一起遍历,没有数据库能承受这么大的load。有两种解决方法:
1 分拆数据库,按照hash range拆分,然后每一百个机器对应一个数据库instance
2 在crawler之前加一层,叫dispatcher,有比如100个,每个dispatcher负责一个range,分配任务给下面的crawler。
当然还要继续考虑dispatcher down了怎么办
比如有1 billion url需要定期的crawl。简单的做法,每个url一个hash,hash的取值范围就是1 到 1billion。把hash分成10K个组,每个组一个range。这个range就是一个partition,或者叫shard。每台机器就负责一个shard。
更好的做法可以参考consistency hash,或者直接用cassandra存取这些URLs。可以到几百上千的node,支持10K机器没啥问题
Hubs are web pages that contain a large number of outgoing links to authority sites. For example, Reddit, the DMOZ Directory and Hacker News are hubs because they point to a lot of pages with authoritative content. Authorities are sites that obtain a high authority score, determined by the relevant information on the page and its authoritative sources
Storing the spider log in Kafka allowed us to replay the log out of the box, which can be useful when changing crawling strategy on the fly. We were able to set up partitions by domain name, which made it easier to ensure that each domain was downloaded at most by one spider.
We used the consumer offset feature to track the position of the spider and provide new messages slightly ahead of time in order to prevent topic overload by deciding if the spider was ready to consume more.
The main advantage of this design is real-time operation. The crawling strategy can be changed without having to stop the crawl. It’s worth mentioning that the crawling strategy can be implemented as a separate module. This module would contain the logic for ordering URLs and stopping crawls, as well as the scoring model.
Distributed Frontera is polite to web hosts by design because each host is downloaded by only one spider process. This is achieved by Kafka topic partitioning. All distributed Frontera components are written in Python. Python is much simpler to write than C++ or Java, the two most common languages for large-scale web crawlers.
Crawler will dequeue the url json from queue and checks if the url already cached in couchbase url bucket or has to be reextracted. If it is not available, page is fetched via the proxy servers.
Once a page is available, raw page is stored in AWS S3 and an entry is made into url bucket. Then, extractor will extract two things, one set of documents and next set of url(s). Data is stored in couchbase data bucket and next set of url(s) are checked if it has to be crawled. Next set url(s) can also contain, required headers and also can carry data map to next level. Then, they are added to the same queue.
TODO:http://www.ijcaonline.org/volume15/number7/pxc3872629.pdf
http://www.slideshare.net/gnap/design-and-implementation-of-a-high-performance-distributed-web-crawler
https://benbernardblog.com/the-tale-of-creating-a-distributed-web-crawler/
Given a seed URL, the crawler needed to auto-discover the value of the missing fields for a particular record. So if a web page didn't contain the information that I was looking for, the crawler needed to follow outbound links, until the information was found.
It needed to be some kind of crawler-scraper hybrid, because it had to simultaneously follow outbound links and extract specific information from web pages.
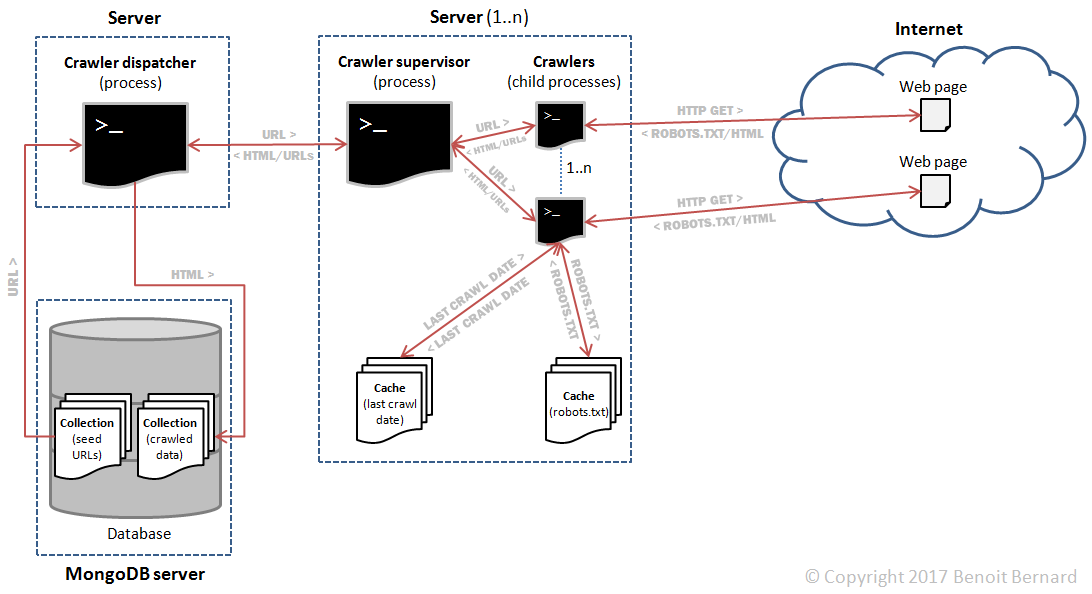
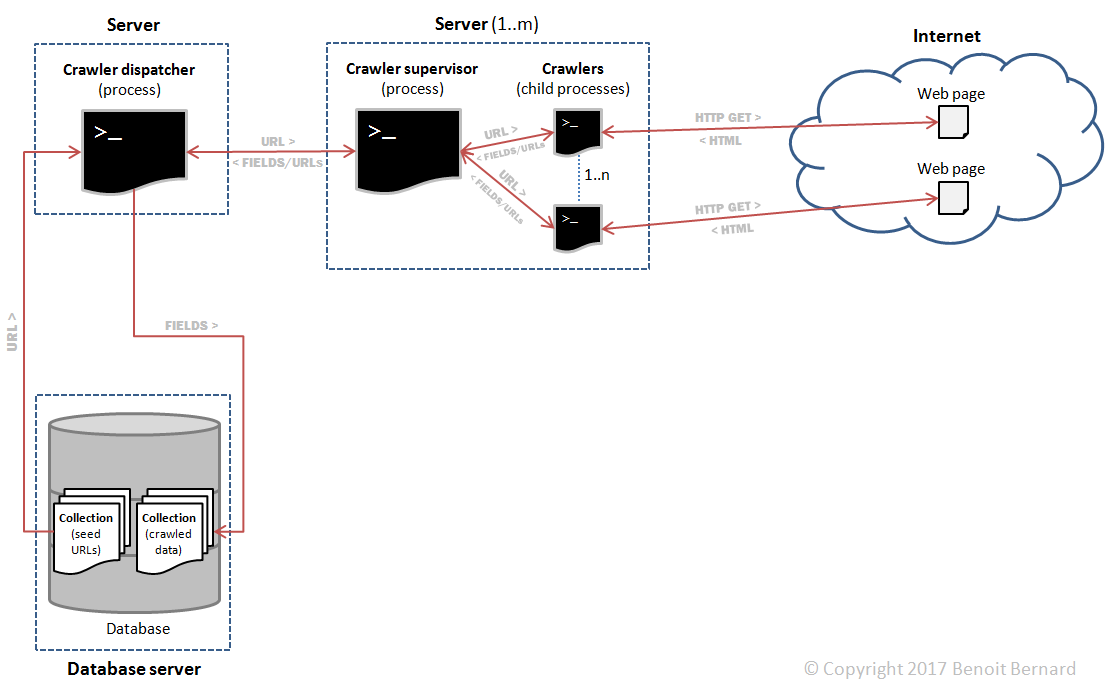
The main components were:
- A crawler dispatcher, responsible for dispatching URLs to be crawled to the m crawler supervisors, and for collecting results (fields) from them.
- m crawler supervisors, responsible for supervising n child processes. Those child processes would perform the actual crawling. I'll refer to them as crawlers for convenience.
- A database server, responsible for storing the initial seed URLs as well as the extracted fields.
4. Pirate. Design Wikipedia crawler.
followup 1: No global status.
followup 2: deal with machine failure
followup 3: make the wiki site unaware of this crawler.
1. distributed bfs2. consistent hashing
3. assign task with a random delay
Algo Ramblings: Design a web crawler
Crawler basic algorithm
- Remove a URL from the unvisited URL list
- Determine the IP Address of its host name
- Download the corresponding document
- Extract any links contained in it.
- If the URL is new, add it to the list of unvisited URLs
- Process the downloaded document
- Back to step 1
General architecture
What pages should the crawler download ?
How should the crawler refresh pages ?
How should the load on the visited web sites be minimized ?
How should the crawling process be parallelized ?
http://baozitraining.org/blog/design-a-basic-web-crawler/
the internet could be abstracted as a directed graph, with each page as a node and hyperlinks as an edge.
How to crawl?
BFS is normally used.
Decide what you want to crawl?
Scope: crawl whole internet or just company web site.
Having a few websites in your crawler’s most frequent list to crawl, such as some authoritative news website, etc
You should have lots of fetchers living on many host classes. Use machine learning to predict which websites are most likely to have frequent update, put those into the fetchers’ priority queue.
Hot to track what your fetchers have crawled?
You don’t want your fetchers to crawl some website over and over again while other websites don’t get crawled at all. There are many ways to achieve this. For example, your scheduler should generate non-duplicate jobs for fetchers. Or,
your fetchers could keep track off the last visited time for each URL. Note, due to the scalability, a consistent hashmap is needed.
Respect the standard?
If a crawler sees a robots.txt on a site, it should skip crawling it.
You need to have some ways to execute those javascript and get the URL.
How to rank:
Page rank algorithm
Forget about the fact that you’re dealing with billions of pages. How would you design this system if it were just a small number of pages? You should have an understanding of how you would solve the simple, small case in order to understand how you would solve the bigger case.
2. Now, think about the issues that occur with billions of pages. Most likely you can’t fit
the data on one machine. How will you di
http://blog.semantics3.com/how-we-built-our-almost-distributed-web-crawler/
Data Structure
We use priority search based graph traversal for our web crawling. Its basically breadth first search, but we use a priority queue instead of a queue to determine which URL to crawl next.
==> BFS+score, so we will crawl important pages/sites more timely.
We assign an importance score to each URL which we discover and then crawl them accordingly.
We use Redis sorted sets to store the priority associated with each URL and hashes to store the visited status of the discovered URLs. This, of course, comes with a large memory footprint.
A possible alternative would be to use Bloom filters.
==> False positive actually means that the bloom filter will tell you that you have already visited a URL but you actually haven't. The consequent of this is that you will miss crawling web pages rather than crawling the same page twice.
Recrawling
Since one of the tasks we do is in building price histories of products, recrawling of pages needs to be done intelligently.
We want to recrawl products that frequently change prices frequently (duh) as compared to pages that don’t really change their price.
Hence a brute-force complete recrawl doesn’t really make sense.
We use a power law distribution (some pages are crawled more frequently than other pages) for recrawling products, with pages ranked based on their importance (using signals ranging from previous price history changes to how many reviews they have).
Another challenge is in page discovery (eg: if a new product has been launched, how quickly can we have it in our system).
===> if the crawler is built for companies site, we can provide api so client can add or manually crawl new added pages.
Check resource from https://www.linkedin.com/pulse/20140831103409-27984489-designing-a-search-engine-design-patterns-for-crawlers
http://www.jiuzhang.com/problem/44/
如果让你来设计一个最基本的Web Crawler,该如何设计?需要考虑的因素有哪些?
没有标准答案。需要尽可能的回答出多一点的考虑因素。
面试官角度:
这个问题是面试中常见的设计类问题。实际上如果你没有做过相关的设计,想要回答出一个让面试官满意的结果其实并不是很容易。该问题并不局限于你在去面试搜索引擎公司时可能会问到。这里,我们从Junior Level和Senior Level两个角度来解答这个问题。
1. 如何抽象整个互联网
Junior: 抽象为一个无向图,网页为节点,网页中的链接为有向边。
Senior: 同上。
2. 抓取算法
Junior: 采用BFS的方法,维护一个队列,抓取到一个网页以后,分析网页的链接,扔到队列里。
Senior: 采用优先队列调度,区别于单纯的BFS,对于每个网页设定一定的抓取权重,优先抓取权重较高的网页。对于权重的设定,考虑的因素有:1. 是否属于一个比较热门的网站 2. 链接长度 3. link到该网页的网页的权重 4. 该网页被指向的次数 等等。
进一步考虑,对于热门的网站,不能无限制的抓取,所以需要进行二级调度。首先调度抓取哪个网站,然后选中了要抓取的网站之后,调度在该网站中抓取哪些网页。这样做的好处是,非常礼貌的对单个网站的抓取有一定的限制,也给其他网站的网页抓取一些机会。
3. 网络模型
Junior: 多线程抓取。
Senior: 分别考虑单机抓取和分布式抓取的情况。对于Windows的单机,可以使用IOCP完成端口进行异步抓取,该种网络访问的方式可以最大程度的利用闲散资源。因为网络访问是需要等待的,如果简单的同时开多个线程,计算机用于线程间切换的耗费会非常大,这种用于处理抓取结果的时间就会非常少。IOCP可以做到使用几个线程就完成几十个线程同步抓取的效果。对于多机的抓取,需要考虑机器的分布,如抓取亚洲的站点,则用在亚洲范围内的计算机等等。
4. 实时性
Junior: 无需回答
Senior: 新闻网页的抓取一般来说是利用单独的爬虫来完成。新闻网页抓取的爬虫的权重设置与普通爬虫会有所区别。首先需要进行新闻源的筛选,这里有两种方式,一种是人工设置新闻源,如新浪首页,第二种方式是通过机器学习的方法。新闻源可以定义链接数非常多,链接内容经常变化的网页。从新闻源网页出发往下抓取给定层级限制的网页所得到,再根据网页中的时间戳信息判断,就可以加入新闻网页。
5. 网页更新
Junior: 无需回答。
Senior: 网页如果被抓下来以后,有的网页会持续变化,有的不会。这里就需要对网页的抓取设置一些生命力信息。当一个新的网页链接被发现以后,他的生命力时间戳信息应该是被发现的时间,表示马上需要被抓取,当一个网页被抓取之后,他的生命力时间戳信息可以被设置为x分钟以后,那么,等到x分钟以后,这个网页就可以根据这个时间戳来判断出,他需要被马上再抓取一次了。一个网页被第二次抓取以后,需要和之前的内容进行对比,
如果内容一致,则延长下一次抓取的时间,如设为2x分钟后再抓取,直到达到一个限制长度如半年或者三个月(这个数值取决于你爬虫的能力)。如果被更新了,则需要缩短时间,如,x/2分钟之后再抓取。Keep in mind a production web crawler could be very sophisticated and normally takes a few teams weeks/months to develop. The interviewer would not expect you to cover all the detail, but you should be able to mention some key design perspectives.
How to abstract the internet?
You should quickly realize the internet could be abstracted as a directed graph, with each page as a node and hyperlinks as an edge.
How to crawl?
BFS is normally used. However, DFS is also used in some situation, such as if your crawler has already established a connection with the website, it might just DFS all the URLs within this website to save some handshaking overhead.
Decide what you want to crawl?
Internet is huge thus your graph is huge. It is almost impossible to crawl the entire internet since it is keep growing every sec. Google probably has 60 trillion while Bing has 30 trillion, roughly speaking.
Some strategy used in practice includes
a) Having a few websites in your crawler’s most frequent list to crawl, such as some authoritative news website, etc
b) You should have lots of fetchers living on many host classes. Use machine learning to predict which websites are most likely to have frequent update, put those into the fetchers’ priority queue.
Hot to track what your fetchers have crawled?
You don’t want your fetchers to crawl some website over and over again while other websites don’t get crawled at all. There are many ways to achieve this. For example, your scheduler should generate non-duplicate jobs for fetchers. Or, your fetchers could keep track off the last visited time for each URL. Note, due to the scalability, a consistent hashmap is needed.
Respect the standard?
If a crawler sees a robots.txt on a site, it should skip crawling it. However, if this happens a lot for a fetcher, it is doing less work on the run. Some optimization could be let the fetcher pick some other sites to crawl to reduce the overhead of spawning a fetcher.
Sometime, URL on a website is not easy to extract. For example, some URLs are generated by javascript. You need to have some ways to execute those javascript and get the URL.
[Reference]
https://github.com/jefferyyuan/500lines/tree/master/crawler
http://itsumomono.blogspot.com/2015/08/crawling.html
Robustness: avoid fetching an infinite number of pages in a particular domain.
Politeness: Web servers have both implicit and explicit policies regulating the rate at which a crawler can visit them.
Distributed:
Scalable:
Performance and efficiency: CPU, storage and network bandwidth.
Quality:be biased towards fetching “useful” pages first.
Freshness: continuous mode: it should obtain fresh copies of previously fetched pages.
Extensible: e.g. new data formats, new fetch protocols.
begin with a seed set
Check already fetched -- The simplest implementation for this would
use a simple fingerprint such as a checksum. https://en.wikipedia.org/wiki/Checksum
A more sophisticated test would use shingles
URL filter is used to determine whether the extracted URL should be excluded from the frontier based on one of several tests.
Many hosts on theWeb place certain portions of their websites off-limits to crawling, under a standard known as the Robots Exclusion Protocol. This is done by placing a file with the name robots.txt at the root of the URL hierarchy at the site. maintaining a cache of robots.txt files
URL should be normalized in the following sense: often the HTML encoding of a link from a web page p indicates the target of that link relative to the page p.
Finally, the URL is checked for duplicate elimination. When the URL is added to the frontier, it is assigned a priority based on which it is eventually removed from the frontier for fetching.
Certain housekeeping tasks are typically performed by a dedicated thread.
This thread is generally quiescent except that it wakes up once every few seconds to log crawl progress statistics (URLs crawled, frontier size, etc.), decide whether to terminate the crawl, or (once every few hours of crawling) checkpoint the crawl.
In checkpointing, a snapshot of the crawler’s state (say the URL frontier) is committed to disk. In the event of a catastrophic crawler
failure, the crawl is restarted from the most recent checkpoint.
Documents change over time and so, in the context of continuous crawling, we must be able to delete their outdated fingerprints/shingles from the content-seen set(s). In order to do so, it is necessary to save the fingerprint/shingle of the document in the URL frontier, along with the URL itself.
DNS resolution is a well-known bottleneck in web crawling. DNS resolution may entail multiple requests and round-trips across the internet, requiring seconds and sometimes even longer.
DNS cache, are generally synchronous.
This means that once a request is made to the Domain Name Service, other crawler threads at that node are blocked until the first request is completed. To circumvent this, most web crawlers implement their own DNS resolver as a component of the crawler.
Thread executing the resolver code sends a message to the DNS server and then performs a timed wait: it resumes either when being signaled by another thread or when a set time quantum expires. A single, separate DNS thread listens on the standard DNS port (port 53) for incoming response packets from the name service.
Upon receiving a response, it signals the appropriate crawler thread (in this case, i) and hands it the response packet if i has not yet resumed because its time quantum has expired. A crawler thread that resumes because its wait time quantum has expired retries for a fixed number of attempts, sending out a new message to the DNS server and performing
a timed wait each time; the designers of Mercator recommend of the order
of five attempts. The time quantum of the wait increases exponentially with
each of these attempts; Mercator started with one second and ended with
roughly 90 seconds, in consideration of the fact that there are host names
that take tens of seconds to resolve partitioning by terms, also known as global index organization, and partitioning by documents,
The URL frontier
high-quality pages that change frequently should be
prioritized for frequent crawling. Thus, the priority of a page should be a
function of both its change rate and its quality (using some reasonable quality
estimate). The combination is necessary because a large number of spam
pages change completely on every fetch
The second consideration is politeness: we must avoid repeated fetch requests
to a host within a short time span.
A common heuristic is to insert a
gap between successive fetch requests to a host that is an order of magnitude
larger than the time taken for the most recent fetch from that host.
Its goals are to ensure that (i) only one connection is open at a time to any
host; (ii) a waiting time of a few seconds occurs between successive requests
to a host and (iii) high-priority pages are crawled preferentially.
In the former, the dictionary of index terms is partitioned into subsets, each subset residing at a node.
Along with the terms at a node, we keep the postings for those terms. A
query is routed to the nodes corresponding to its query terms. In principle,
this allows greater concurrency since a stream of queries with different query
terms would hit different sets of machines.
In practice, partitioning indexes by vocabulary terms turns out to be nontrivial.
Multi-word queries require the sending of long postings lists between
sets of nodes for merging, and the cost of this can outweigh the greater concurrency.
Load balancing the partition is governed not by an a priori analysis
of relative term frequencies, but rather by the distribution of query terms
and their co-occurrences, which can drift with time or exhibit sudden bursts.
Achieving good partitions is a function of the co-occurrences of query terms
and entails the clustering of terms to optimize objectives that are not easy to
quantify. Finally, this strategy makes implementation of dynamic indexing
more difficult.
A more common implementation is to partition by documents: each node
contains the index for a subset of all documents. Each query is distributed to
all nodes, with the results fromvarious nodes being merged before presentation
to the user. This strategy trades more local disk seeks for less inter-node
communication. One difficulty in this approach is that global statistics used
in scoring – such as idf – must be computed across the entire document collection
even though the index at any single node only contains a subset of
the documents. These are computed by distributed “background” processes
that periodically refresh the node indexes with fresh global statistics
slave。Bloom Filter放到master的内存里,而被访问过的url放到运行在master上的Redis里,这样保证所有操作都是O(1)。
我感觉这相当于统筹分配任务:
Master:读写task list这种工作需要统一交给一个master机器来做,这样能保持数据的一致性,也更便于管理,所以也就需要这个机器读写速度快,稳定。
Slave:而slave做的就是爬数据,把爬到的东西传回到master里面。 多一个,少一个,甚至坏一个都不太影响整个爬虫的工作。这样的机器运算速度不需要特别高。
在老师的视频里面是这么划分页面的:
- 一个是list, 那种汇聚了许多新闻超链接的页面
- 还有一种是page, 也就是普通的页面
2. Multiple Page Website Crawler
爬虫首先要找到那个list 页面,从这个页面开始搜集page。这个就产生了最基本的爬多个页面网站的爬虫架构:

上图是一个很基础的爬虫结构。值得注意的是对于每个网站来说,list crawler 只有一个,但是news crawler有许多个,而且news crawler 可以复用。
scheduler 就算是一个master,在控制整个爬虫的工作。但是,这也有一个问题——复用。这些list crawler会有浪费。比如说新浪没有啥新闻,list crawler就会闲置在那里;而163有很多新闻,crawler却不够使,这是浪费资源。
所以,讲义上提供了第三版的结构。
3. Master-Slave Crawler
这种结构没有分是list 还是 page 的crawler。 由一个master 的负责读写,其他crawler 来爬。这样就很好解决了一个资源浪费的问题。

这样就很好解决了一个资源浪费的问题。在这幅图里面画了task table的架构。这里面有一些列还是值得思考的。
- Priority
比如说priority是用来划分爬虫的优先级的。可以把要用来爬list的优先级提高。把要来爬page的优先级降低。
还有state在这里包含 done, working, new 这几个状态。这个可以用于管理,这个也可以用来做verification。比如说一个爬虫的状态是done了。那就应该是爬过了。但是如果没有得到应有的数据,及link里面的内容。我就可以拿它来查是不是那个爬虫坏了。
- Timestamp
最后面还有两个时间。这样还能做到定时爬取的效果,原因可能在于要对一个网站做到爬虫友好。
Scheduler
然后就应该说说那个scheduler 这个可以是个不过分的考点。考多线程的锁。这是第一种加锁的方式:睡眠。
1) Sleep
当有任务的时候爬,没任务的时候睡。这个方式的缺点在于睡多久。课件里面给的是睡一秒。但是外一这个一秒有任务了。爬虫还是不能马上开始爬。但是睡眠还是多线程一个很常见的处理方式。这个图很清晰。 按照视频的说法是把他理解并背诵

2) Conditional Variable
第二种就比较复杂了。用条件变量。视频里面把这个用了一个生动的比喻来描述这个结构。就是顾客去餐馆吃饭。进去要问有没有空位。如果没有空位,就去等待区等候。然后一旦有空位,饭馆会来提醒有空位了。
1. 自己观察
2. 可以排队
那个Cond_wait 的意思是: 没有任务的话就等着, 内部释放锁。
那个Cond_signal 就是去唤醒一个等着的线程
这是具体那两个conditional variable 的具体实现。


视频里的老师说这个也要理解并背诵。
3) Semaphore
然后课件里面又提到了第三种经典的处理多线程的方式用信号量。




这个在视频里面也有一个很好的比喻。比如说我能处理有10 个新任务,我就有10个令牌。如果没有令牌就意味着没有新任务。这个爬虫就开始等着。当爬虫爬完页面, 就把令牌放回。
- Advantage
我觉得这个很巧妙的地方就是,简化了很多控制变量。就用一个Integer就控制了多个爬虫。信号量就是一个整形数正数代表有新任务负数代表没新任务。每次爬虫就来看一下这个数就好。任务拿走减去1 发现新任务+1。
生产者消费者模型
然后呢。视频里面对于这个生产者消费者模型,借着爬虫又详细的讲了一下。而且是对于这种处理大量数据的情况做了很经典的讲解。说到大数据。我们一台机器上肯定放不下所有的爬虫 肯定我们就要把他们部署在多个机器上。每个crawler负责爬页面获取任务 并把得到的页面发回给connector。由这个connector负责往table 里面读写。但是这样每个crawler就需要一个connector有点浪费。


所以, 为了减少connector 就按照crawler 的工作内容: 拿任务,送回页面 分成了两类 sender和receiver这样一组爬虫结构 就需要两个大的控制结构就好。


上述单机的版的爬虫,在数据量不大和数据更新频率要求不高的情况下,可以很好的工作,但是当需要爬取的页面数量过多,或者网站有反爬虫限制的时候,上述代码并不能很好的工作。
例如通用的搜索爬虫需要爬取很多网页的时候,就需要多个爬虫来一起工作,这个时候各个爬虫必然要共享上述两个数据结构。
其次,现在很多网站对于爬虫都有限制,如果要是爬取的过于频繁,会被封Ip,为了应对这种情况,对应的策略是休眠一段时间,这样的话,又浪费了CPU资源。
最后,当要求实现不同的爬取策略,或者统一管理爬虫作业生命周期的时候,必然要一个Master来协调各个Slave的工作。
3. 设计实现
3.1 Master:
我们框架的主节点称为WebCrawlerMaster,针对不同的爬虫任务,WebCrawlerMaster会生成不同的WebCrawlerManager,WebCrawlerManger的功能是管理UrlsToDo和UrlsDone两个数据结构。Master主要的功能是管理WebCrawlerManager的实例,并且将不同的请求路由到对应的WebCrawlerManager上去。
对于Master来说,最主要的组件是一个叫做MetaDataHolder的成员,它主要用来管理元数据信息。为了加强系统的健壮性,这部分信息是一定需要持久化的,至于持久化的选择,可以是Redis,或者关系型数据库,甚至写文件都可以。如果用Mysql来做持久化的工作,则需要做应用层的cache(通常用一个HashMap来实现)。
3.2 数据结构
对于一个CrawlManager,它主要管理两个数据结构UrlToDo,和UrlDone,前者可以抽象成一个链表,栈或者有优先级的队列,后者对外的表现是一个Set,做去重的工作。当定义出ADT(abstract data type)以后,则可以考虑出怎么样的去实现这个数据结构。这样的设计方法其实和实现一个数据结构是一样的,只不过当我们实现数据结构的时候,操作的对象是内存中的数组和列表,而在这个项目中,我们操作的对象是各种存储中提供给我们的功能,例如Redis中的List、Set,关系型数据库中的表等等。
4. 后记
这次的爬虫框架,从最开始的伪代码来看,是很简单的事情,但是一旦涉及到分布式的环境和系统的可扩展性,要真的实现起来,还是需要考虑到一些额外的东西,例如并发状态下共享数据结构的读写、系统的高可用等等,但是我觉得这个项目真正让我满意的地方,是通过合理的数据结构行为层面的抽象,让这个爬虫系统有着很强的扩展性。例如现在默认的UrlToDo是一个FIFO的队列,这样的话,爬虫实际上是按照BSF的策略去爬取的。但是当UrlToDo配置成一个LIFO的stack以后,爬虫实际上按照DSF的策略去爬取的,而这样的变化,只需要的更改一下请求新的WebCrawlerManager的参数,爬虫的业务代码并不需要任何的修改。
http://nlp.stanford.edu/IR-book/html/htmledition/web-crawling-and-indexes-1.html
fb面经题web crawler讨论
https://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=436948
给你10K个机器,然后1B的url,机器之间不能通信,问你怎么样每个机器才能平均的分任务
http://www.1point3acres.com/bbs/thread-268942-1-1.html
帖子的楼主在3楼说了一下面试时被面试官引导的方向
“思路就是每台机器都从起始点开始,然后对拿到的url做hash,事先规定好每台机器都只做那些hash value的job,如果hash的值跟当前机器的预定值不一样就skip,一样才继续crawl”
10k机器,都从起点开始,可是起点hash之后只会对应到一台机器,按照^说的方向,那其他所有机器都不用爬就一直空闲下去了
我理解其实就是一致性哈希啊。但是在分配任务之前,需要找到这1B个link,对它们做hash啊。这个事情并不能分布式的做
这是经典的distributed hash table 问题. 从root url开始,下载webpage,从这个page里提取embedded url links, distribute 每个link 到对应负责任的machine. In general, 毎个机器接收url links from peers, 看是否已经访问过,没有的话,放入work queue, 有个thread 专门从queue取url, download page, extract urls, distributes to other machines
如果只能遍历所有数据,一共10K台机器,一起遍历,没有数据库能承受这么大的load。有两种解决方法:
1 分拆数据库,按照hash range拆分,然后每一百个机器对应一个数据库instance
2 在crawler之前加一层,叫dispatcher,有比如100个,每个dispatcher负责一个range,分配任务给下面的crawler。
当然还要继续考虑dispatcher down了怎么办
比如有1 billion url需要定期的crawl。简单的做法,每个url一个hash,hash的取值范围就是1 到 1billion。把hash分成10K个组,每个组一个range。这个range就是一个partition,或者叫shard。每台机器就负责一个shard。
更好的做法可以参考consistency hash,或者直接用cassandra存取这些URLs。可以到几百上千的node,支持10K机器没啥问题