Related:
http://massivetechinterview.blogspot.com/2015/06/n00tc0d3r.html
https://puncsky.com/hacking-the-software-engineer-interview#designing-a-url-shortener
https://www.puncsky.com/notes/84-designing-a-url-shortener
https://www.interviewbit.com/problems/design-url-shortener/
Need use conditional insert(insert if not exist) - lightweight transaction
also if we want same url to always have same shorten url,
if we want different url, we add some random number
Q: How can we optimize read queries?
https://www.youtube.com/watch?v=fMZMm_0ZhK4
Questions:
1. if the user is trying to generate short url, the url already exists, what we should do?
return existing one or generate a new one?
do we support custom short url?
https://hufangyun.com/2017/short-url/
How to design a tiny URL or URL shortener? - GeeksforGeeks
How to design a system that takes big URLs like "http://www.geeksforgeeks.org/count-sum-of-digits-in-numbers-from-1-to-n/" and converts them into a short 6 character URL. It is given that URLs are stored in database and every URL has an associated integer id.
One important thing to note is, the long url should also be uniquely identifiable from short url. So we need a Bijective Function
http://n00tc0d3r.blogspot.com/2013/09/big-data-tinyurl.html
On Single Machine
Suppose we have a database which contains three columns: id (auto increment), actual url, and shorten url.
Intuitively, we can design a hash function that maps the actual url to shorten url. But string to string mapping is not easy to compute.
Notice that in the database, each record has a unique id associated with it. What if we convert the id to a shorten url?
Basically, we need a Bijective function f(x) = y such that
First insert the longurl to db, and get the newid, convert the newid to shorturl return new url
-- we don't need store the shorturl in db.
Then, the problem becomes Base Conversion problem which is bijection (if not overflowed :).
On Multiple Machine
Suppose the service gets more and more traffic and thus we need to distributed data onto multiple servers.
We can use Distributed Database. But maintenance for such a db would be much more complicated (replicate data across servers, sync among servers to get a unique id, etc.).
Alternatively, we can use Distributed Key-Value Datastore.
Some distributed datastore (e.g. Amazon's Dynamo) uses Consistent Hashing to hash servers and inputs into integers and locate the corresponding server using the hash value of the input. We can apply base conversion algorithm on the hash value of the input.
The basic process can be:
id-int <-> shorturl mapping
Insert
https://gist.github.com/gcrfelix/ac2fd9f394d8e71e75c2
http://www.allenlipeng47.com/blog/index.php/2015/12/01/compress-url-by-base62/
https://github.com/allenlipeng47/algorithm/blob/master/src/main/java/com/pli/project/algorithm/encode/Base62.java
public class ShortURL {
public static final String ALPHABET = "23456789bcdfghjkmnpqrstvwxyzBCDFGHJKLMNPQRSTVWXYZ-_";
public static final int BASE = ALPHABET.length();
public static String encode(int num) {
StringBuilder str = new StringBuilder();
while (num > 0) {
str.insert(0, ALPHABET.charAt(num % BASE)); // the following code is better. reverse at last step.
num = num / BASE;
}
return str.toString();
}
public static int decode(String str) {
int num = 0;
for (int i = 0; i < str.length(); i++) {
num = num * BASE + ALPHABET.indexOf(str.charAt(i));
}
return num;
}
}
http://yuanhsh.iteye.com/blog/2197100
https://zhuanlan.zhihu.com/p/21313382
https://www.hiredintech.com/classrooms/system-design/lesson/62
hashedUrl=convert_to_base62(md5(originalUrl+randomSort))
-- right?
https://stackoverflow.com/questions/8852668/what-is-the-clash-rate-for-md5
https://soulmachine.gitbooks.io/system-design/content/cn/tinyurl.html
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=145037&extra=page%3D7%26filter%3Dsortid%26sortid%3D311%26sortid%3D311
长到短,要查长的是否已经存在,存在直接返回已有值(这个就是我说的查重);如果不存在则生成一个唯一的短id存到数据库
短到长,查短id是否存在,不存在就报错,存在则返回。
其实都需要index, 然后根据需要load进cache,但是这些普通数据库都已经实现了,不需要我们操心。
当然你可以把index都load到memcache/redis加快点访问速度,不过这里都是没有必要的。
http://www.blogchong.com/?mod=pad&act=view&id=85
NOSQL:
http://coligo.io/create-url-shortener-with-node-express-mongo/
https://github.com/coligo-io/url-shortener-node-mongo-express
http://stackoverflow.com/questions/32798150/which-nosql-database-should-i-use-for-a-url-shortener
https://github.com/aerospike/url-shortener-nodejs/blob/master/url_shortener.js
http://www.aerospike.com/blog/aerospike-url-shortening-service/
http://stackoverflow.com/questions/15868988/url-shortening-for-nosql-databases
http://massivetechinterview.blogspot.com/2015/06/n00tc0d3r.html
https://puncsky.com/hacking-the-software-engineer-interview#designing-a-url-shortener
Design a system to take user-provided URLs and transform them to a shortened URLs that redirect back to the original. Describe how the system works. How would you allocate the shorthand URLs? How would you store the shorthand to original URL mapping? How would you implement the redirect servers? How would you store the click stats?
Assumptions: I generally don’t include these assumptions in the initial problem presentation. Good candidates will ask about scale when coming up with a design.
- Total number of unique domains registering redirect URLs is on the order of 10s of thousands
- New URL registrations are on the order of 10,000,000/day (100/sec)
- Redirect requests are on the order of 10B/day (100,000/sec)
- Remind candidates that those are average numbers - during peak traffic (either driven by time, such as ‘as people come home from work’ or by outside events, such as ‘during the Superbowl’) they may be much higher.
- Recent stats (within the current day) should be aggregated and available with a 5 minute lag time
- Long look-back stats can be computed daily
Assumptions
1B new URLs per day, 100B entries in total the shorter, the better show statics (real-time and daily/monthly/yearly)
Encode Url
Choice 1. md5(128 bit, 16 hex numbers, collision, birthday paradox, 2^(n/2) = 2^64) truncate? (64bit, 8 hex number, collision 2^32), Base64.
- Pros: hashing is simple and horizontally scalable.
- Cons: too long, how to purify expired URLs?
Choice 2. Distributed Seq Id Generator. (Base62: a~z, A~Z, 0~9, 62 chars, 62^7), sharding: each node maintains a section of ids.
- Pros: easy to outdate expired entries, shorter
- Cons: coordination (zookeeper)
KV store
MySQL(10k qps, slow, no relation), KV (100k qps, Redis, Memcached)
A great candidate will ask about the lifespan of the aliases and design a system that purges aliases past their expiration.
Followup
Q: How will shortened URLs be generated?
- A poor candidate will propose a solution that uses a single id generator (single point of failure) or a solution that requires coordination among id generator servers on every request. For example, a single database server using an auto-increment primary key.
- An acceptable candidate will propose a solution using an md5 of the URL, or some form of UUID generator that can be done independently on any node. While this allows distributed generation of non- colliding IDs, it yields large “shortened” URLs
- A good candidate will design a solution that utilizes a cluster of id generators that reserve chunks of the id space from a central coordinator (e.g. ZooKeeper) and independently allocate IDs from their chunk, refreshing as necessary.
Q: How to store the mappings?
- A poor candidate will suggest a monolithic database. There are no relational aspects to this store. It is a pure key-value store.
- A good candidate will propose using any light-weight, distributed store. MongoDB/HBase/Voldemort/etc.
- A great candidate will ask about the lifespan of the aliases and design a system that purges aliases past their expiration
Q: How to implement the redirect servers?
- A poor candidate will start designing something from scratch to solve an already solved problem
- A good candidate will propose using an off-the-shelf HTTP server with a plug-in that parses the shortened URL key, looks the alias up in the DB, updates click stats and returns a 303 back to the original URL. Apache/Jetty/Netty/tomcat/etc. are all fine.
Q: How are click stats stored?
- A poor candidate will suggest write-back to a data store on every click
- A good candidate will suggest some form of aggregation tier that accepts clickstream data, aggregates it, and writes back a persistent data store periodically
Q: How will the aggregation tier be partitioned?
- A great candidate will suggest a low-latency messaging system to buffer the click data and transfer it to the aggregation tier.
- A candidate may ask how often the stats need to be updated. If daily, storing in HDFS and running map/reduce jobs to compute stats is a reasonable approach If near real-time, the aggregation logic should compute stats
Q: How to prevent visiting restricted sites?
- A good candidate can answer with maintaining a blacklist of hostnames in a KV store.
- A great candidate may propose some advanced scaling techniques like bloom filter.
Design a system to take user-provided URLs and transform them to a shortened URLs that redirect back to the original. Describe how the system works. How would you allocate the shorthand URLs? How would you store the shorthand to original URL mapping? How would you implement the redirect servers? How would you store the click stats?
Assumptions: I generally don’t include these assumptions in the initial problem presentation. Good candidates will ask about scale when coming up with a design.
- Total number of unique domains registering redirect URLs is on the order of 10s of thousands
- New URL registrations are on the order of 10,000,000/day (100/sec)
- Redirect requests are on the order of 10B/day (100,000/sec)
- Remind candidates that those are average numbers - during peak traffic (either driven by time, such as ‘as people come home from work’ or by outside events, such as ‘during the Superbowl’) they may be much higher.
- Recent stats (within the current day) should be aggregated and available with a 5 minute lag time
- Long look-back stats can be computed daily
MySQL(10k qps, slow, no relation), KV (100k qps, Redis, Memcached)
A great candidate will ask about the lifespan of the aliases and design a system that purges aliases past their expiration.
Q: How will shortened URLs be generated?
- A poor candidate will propose a solution that uses a single id generator (single point of failure) or a solution that requires coordination among id generator servers on every request. For example, a single database server using an auto-increment primary key.
- An acceptable candidate will propose a solution using an md5 of the URL, or some form of UUID generator that can be done independently on any node. While this allows distributed generation of non- colliding IDs, it yields large “shortened” URLs
- A good candidate will design a solution that utilizes a cluster of id generators that reserve chunks of the id space from a central coordinator (e.g. ZooKeeper) and independently allocate IDs from their chunk, refreshing as necessary.
Q: How to store the mappings?
- A poor candidate will suggest a monolithic database. There are no relational aspects to this store. It is a pure key-value store.
- A good candidate will propose using any light-weight, distributed store. MongoDB/HBase/Voldemort/etc.
- A great candidate will ask about the lifespan of the aliases and design a system that purges aliases past their expiration
Q: How to implement the redirect servers?
- A poor candidate will start designing something from scratch to solve an already solved problem
- A good candidate will propose using an off-the-shelf HTTP server with a plug-in that parses the shortened URL key, looks the alias up in the DB, updates click stats and returns a 303 back to the original URL. Apache/Jetty/Netty/tomcat/etc. are all fine.
Q: How are click stats stored?
- A poor candidate will suggest write-back to a data store on every click
- A good candidate will suggest some form of aggregation tier that accepts clickstream data, aggregates it, and writes back a persistent data store periodically
Q: How will the aggregation tier be partitioned?
- A great candidate will suggest a low-latency messaging system to buffer the click data and transfer it to the aggregation tier.
- A candidate may ask how often the stats need to be updated. If daily, storing in HDFS and running map/reduce jobs to compute stats is a reasonable approach If near real-time, the aggregation logic should compute stats
Q: How to prevent visiting restricted sites?
- A good candidate can answer with maintaining a blacklist of hostnames in a KV store.
- A great candidate may propose some advanced scaling techniques like bloom filter.
Need use conditional insert(insert if not exist) - lightweight transaction
also if we want same url to always have same shorten url,
if we want different url, we add some random number
Hint: Earlier we saw, we would see 100 Million new URLs each month. Assuming same growth rate for next 5 years, total URLs we will need to shorten will be 100 Million * 12 * 5 = 6 Billion.
A: 6 Billion.
Hint: We will use (a-z, A-Z, 0-9) to encode our URLs. If we call x as minimum number of characters to represent 6 Billion total URLs, then will be the smallest integer such that x^62 > 6*10^9.
A: Log (6*109) to the base 62 = 6
A: 3 TeraBytes for URLs and 36 GigaBytes for shortened URLs
Note that for the shortened URL, we will only store the slug(6 chars) and compute the actual URL on the fly.
Note that for the shortened URL, we will only store the slug(6 chars) and compute the actual URL on the fly.
Q: Data read/written each second?
Hint: Data flow for each request would contain a shortened URL and the original URL. Shortened URL as we saw earlier, will take 6 bytes whereas the original URL can be assumed to take atmost 500 bytes.
A: Written : 40 * (500 + 6) bytes, Read : 360 * (500 + 6) bytes
Q: Should we choose Consistency or Availability for our service?
A: This is a tricky one. Both are extremenly important. However, CAP theorem dictates that we choose one. Do we want a system that always answers correctly but is not available sometimes? Or else, do we want a system which is always available but can sometime say that a URL does not exists even if it does?
This tradeoff is a product decision around what we are trying to optimize. Let's say, we go with consistency here.
This tradeoff is a product decision around what we are trying to optimize. Let's say, we go with consistency here.
Q: Try to list down other design goals?
A: URL shortener by definition needs to be as short as possible. Shorter the shortened URL, better it compares to competition.
Q: How should we compute the hash of a URL?
A: convert_to_base_62(md5(original_url + salt))[:6](first six characters)
Links: MD5-Wiki Base 62 Conversion-Stackoverflow
Gotchas:
Links: MD5-Wiki Base 62 Conversion-Stackoverflow
Gotchas:
- Directly encoding URL to base_62 will allow a user to check if a URL has been shortened already or not, reverse enginnering can lead the user to the exact hash function used, this should not be allowed. Therefore randomization has to be introduced. Also, if two users shortens the same URL, it should result in two separate shortened URL(for analytics)
- Database ID encoded to base_62 also won't be suitable for a production environment because it will leak information about the database. For example, patterns can be learnt to compute the growth rate(new URLs added per day) and in the worst case, copy the whole database.
In our case, since we will only query by hash which will never update, our key will be hash with the value being the URL.
Q: How can we optimize read queries?
Q: How would you shard the data if you were working with SQL DB?
A: We can use integer encoding of the shortened URL to distribute data among our DB shards.
Assuming we assign values from 0 to 61 to characters a to z, A to Z, and 0 to 9, we can compute the integer encoding of the shortened URL.
We can see that the maximum value of integer encoding will be less than 10^13, which we can divide among our DB shards.
We will use consistent hashing to ensure we don't have to rehash all the data again if we add new DB shards later.
Assuming we assign values from 0 to 61 to characters a to z, A to Z, and 0 to 9, we can compute the integer encoding of the shortened URL.
We can see that the maximum value of integer encoding will be less than 10^13, which we can divide among our DB shards.
We will use consistent hashing to ensure we don't have to rehash all the data again if we add new DB shards later.
Q: How would you handle machine dying in the case of SQL DB?
A: This is a bit tricky. Obviously, for every shard, we need to have more than one machine
We can have a scheme better known as master slave scheme, wherein there is one machine(master) which processes all writes and there is a slave machine which just subscribes to all of the writes and keeps updating itself. In an event that the master goes down, the slave can take over and start responding to the read queries
We can have a scheme better known as master slave scheme, wherein there is one machine(master) which processes all writes and there is a slave machine which just subscribes to all of the writes and keeps updating itself. In an event that the master goes down, the slave can take over and start responding to the read queries
- 是否需要保留原始链接最后部分?如http://abc.def.com/p/124/article/12306.html压缩成http://short.url/asdfasdf/12306.html,以增加可读性。
- 由于协议部分可以预见或者需要支持的数量很少(比如就支持http和https),是否可以考虑把协议部分略去,以枚举方式和短链接正文放在一起?
- 由于属于web服务,考虑判定URL合法性,考虑怎样控制请求流量和应对恶意访问。
- 如果使用统一的短链接序列分配机制,如何分布式设计这个分配逻辑?它不能够成为瓶颈。例如,一种常见的思路是让关系数据库的自增长索引给出唯一id,但是如果不使用关系数据库,在分布式系统中如何产生唯一序列号且避免冲突?参考:如何在高并发分布式系统中生成全局唯一Id。
- 思考读写模型,明显是读优先级高于写的服务,但是通常不需要修改。读写服务分离,在写服务崩溃时保证读服务健康运行。
- 链接缩短使用的加密和映射的方式中,算法如何选择?短链接可以接受那些字符?此处可以估算特定的规则下长度为n的短链接最多可能表示多少种实际链接。
Questions:
1. if the user is trying to generate short url, the url already exists, what we should do?
return existing one or generate a new one?
do we support custom short url?
https://hufangyun.com/2017/short-url/
301 是永久重定向,302 是临时重定向。短地址一经生成就不会变化,所以用 301 是符合
但是如果使用了
http 语义的。同时对服务器压力也会有一定减少。但是如果使用了
301,我们就无法统计到短地址被点击的次数了。而这个点击次数是一个非常有意思的大数据分析数据源。能够分析出的东西非常非常多。所以选择302虽然会增加服务器压力,但是我想是一个更好的选择。
自增序列算法 也叫永不重复算法
设置 id 自增,一个 10进制 id 对应一个 62进制的数值,1对1,也就不会出现重复的情况。这个利用的就是低进制转化为高进制时,字符数会减少的特性。
如下图:十进制 10000,对应不同进制的字符表示。
二
- 将长网址
md5生成 32 位签名串,分为 4 段, 每段 8 个字节 - 对这四段循环处理, 取 8 个字节, 将他看成 16 进制串与 0x3fffffff(30位1) 与操作, 即超过 30 位的忽略处理
- 这 30 位分成 6 段, 每 5 位的数字作为字母表的索引取得特定字符, 依次进行获得 6 位字符串
- 总的
md5串可以获得 4 个 6 位串,取里面的任意一个就可作为这个长 url 的短 url 地址
这种算法,虽然会生成4个,但是仍然存在重复几率
两种算法对比
第一种算法的好处就是简单好理解,永不重复。但是短码的长度不固定,随着 id 变大从一位长度开始递增。如果非要让短码长度固定也可以就是让 id 从指定的数字开始递增就可以了。百度短网址用的这种算法。上文说的开源短网址项目
YOURLS 也是采用了这种算法。源码学习
第二种算法,存在碰撞(重复)的可能性,虽然几率很小。短码位数是比较固定的。不会从一位长度递增到多位的。据说微博使用的这种算法。
我使用的算法一。有一个不太好的地方就是出现的短码是有序的,可能会不安全。我的处理方式是构造 62进制的字母不要按顺序排列。因为想实现自定义短码的功能,我又对算法一进行了优化,
但是自增序列算法是和 id 绑定的,如果允许自定义短码就会占用之后的短码,之后的 id 要生成短码的时候就发现短码已经被用了,那么 id 自增一对一不冲突的优势就体现不出来了。
How to design a system that takes big URLs like "http://www.geeksforgeeks.org/count-sum-of-digits-in-numbers-from-1-to-n/" and converts them into a short 6 character URL. It is given that URLs are stored in database and every URL has an associated integer id.
One important thing to note is, the long url should also be uniquely identifiable from short url. So we need a Bijective Function
http://n00tc0d3r.blogspot.com/2013/09/big-data-tinyurl.html
On Single Machine
Suppose we have a database which contains three columns: id (auto increment), actual url, and shorten url.
Intuitively, we can design a hash function that maps the actual url to shorten url. But string to string mapping is not easy to compute.
Notice that in the database, each record has a unique id associated with it. What if we convert the id to a shorten url?
Basically, we need a Bijective function f(x) = y such that
- Each x must be associated with one and only one y;
- Each y must be associated with one and only one x.
e.g. 0-0, ..., 9-9, 10-a, 11-b, ..., 35-z, 36-A, ..., 61-Z.
First insert the longurl to db, and get the newid, convert the newid to shorturl return new url
-- we don't need store the shorturl in db.
Then, the problem becomes Base Conversion problem which is bijection (if not overflowed :).
public String shorturl(int id, int base, HashMap map) {
StringBuilder res = new StringBuilder();
while (id > 0) {
int digit = id % base;
res.append(map.get(digit));
id /= base;
}
while (res.length() < 6) res.append('0');
return res.reverse().toString();
}
On Multiple Machine
Suppose the service gets more and more traffic and thus we need to distributed data onto multiple servers.
We can use Distributed Database. But maintenance for such a db would be much more complicated (replicate data across servers, sync among servers to get a unique id, etc.).
Alternatively, we can use Distributed Key-Value Datastore.
Some distributed datastore (e.g. Amazon's Dynamo) uses Consistent Hashing to hash servers and inputs into integers and locate the corresponding server using the hash value of the input. We can apply base conversion algorithm on the hash value of the input.
The basic process can be:
id-int <-> shorturl mapping
Insert
- Hash an input long url into a single integer;
- Locate a server on the ring and store the key--longUrl on the server;
- Compute the shorten url using base conversion (from 10-base to 62-base) and return it to the user.
- Convert the shorten url back to the key using base conversion (from 62-base to 10-base);
- Locate the server containing that key and return the longUrl.
A Better Solution is to use the integer id stored in database and convert the integer to character string that is at most 6 characters long. This problem can basically seen as a base conversion problem where we have a 10 digit input number and we want to convert it into a 6 character long string.
Below is one important observation about possible characters in URL.
A URL character can be one of the following
1) A lower case alphabet [‘a’ to ‘z’], total 26 characters
2) An upper case alphabet [‘A’ to ‘Z’], total 26 characters
3) A digit [‘0′ to ‘9’], total 10 characters'
Insertion:
1. Calculate the hash value of the id of the long URL
2. Locate the server by the hash value and store the id and longURL there.
3. Calculate the short URL based on base conversion and return.
1. Calculate the hash value of the id of the long URL
2. Locate the server by the hash value and store the id and longURL there.
3. Calculate the short URL based on base conversion and return.
Query (redirect):
1. Calculate the id of the short URL by base conversion algorithm.
2. Locate the server by the hashing the id.
3. find the long URL and redirect.
1. Calculate the id of the short URL by base conversion algorithm.
2. Locate the server by the hashing the id.
3. find the long URL and redirect.
public String convertToBase62(int input) { StringBuilder result = new StringBuilder(); HashMap<Integer, Character> map = new HashMap<Integer, Character(); for (int i = 0; i <= 62; i++) { //put matching here } while(input != 0) { int tmp = input % 62; result.append(map.get(tmp)); input /= 62; } result.reverse(); return new String(result); }http://www.allenlipeng47.com/blog/index.php/2015/12/01/compress-url-by-base62/
https://github.com/allenlipeng47/algorithm/blob/master/src/main/java/com/pli/project/algorithm/encode/Base62.java
public class ShortURL {
public static final String ALPHABET = "23456789bcdfghjkmnpqrstvwxyzBCDFGHJKLMNPQRSTVWXYZ-_";
public static final int BASE = ALPHABET.length();
public static String encode(int num) {
StringBuilder str = new StringBuilder();
while (num > 0) {
str.insert(0, ALPHABET.charAt(num % BASE)); // the following code is better. reverse at last step.
num = num / BASE;
}
return str.toString();
}
public static int decode(String str) {
int num = 0;
for (int i = 0; i < str.length(); i++) {
num = num * BASE + ALPHABET.indexOf(str.charAt(i));
}
return num;
}
}
http://yuanhsh.iteye.com/blog/2197100
- private static final String ALPHABET = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
- private static final int BASE = ALPHABET.length();
- public static String encode(int num) {
- StringBuilder sb = new StringBuilder();
- while ( num > 0 ) {
- sb.append( ALPHABET.charAt( num % BASE ) );
- num /= BASE;
- }
- return sb.reverse().toString();
- }
- public static int decode(String str) {
- int num = 0;
- for ( int i = 0, len = str.length(); i < len; i++ ) {
- num = num * BASE + ALPHABET.indexOf( str.charAt(i) );
- }
- return num;
- }
string idToShortURL(long int n){ // Map to store 62 possible characters char map[] = "abcdefghijklmnopqrstuvwxyzABCDEF" "GHIJKLMNOPQRSTUVWXYZ0123456789"; string shorturl; // Convert given integer id to a base 62 number while (n) { // use above map to store actual character // in short url shorturl.push_back(map[n%62]); n = n/62; } // Reverse shortURL to complete base conversion reverse(shorturl.begin(), shorturl.end()); return shorturl;}// Function to get integer ID back from a short urllong int shortURLtoID(string shortURL){ long int id = 0; // initialize result // A simple base conversion logic for (int i=0; i < shortURL.length(); i++) { if ('a' <= shortURL[i] && shortURL[i] <= 'z') id = id*62 + shortURL[i] - 'a'; if ('A' <= shortURL[i] && shortURL[i] <= 'Z') id = id*62 + shortURL[i] - 'A' + 26; if ('0' <= shortURL[i] && shortURL[i] <= '9') id = id*62 + shortURL[i] - '0' + 52; } return id;}https://zhuanlan.zhihu.com/p/21313382
Design URL Shortening Service
这一题是非常经典的System Design题目,可以考的很浅,也可以考的很深。由于特别适合初学者入门,建议每个想学习System Design的同学都要把这道题的可能的条件和解法过一遍。比如说:
- If your website is the top URL shortening service in the world(i.e. handling 70% of world URL shortening traffic) How do you handle it?
- How do you handle URL customization?
- What if you have very hot URLs? How do you handle it?
- How do you track the top N popular URLs?
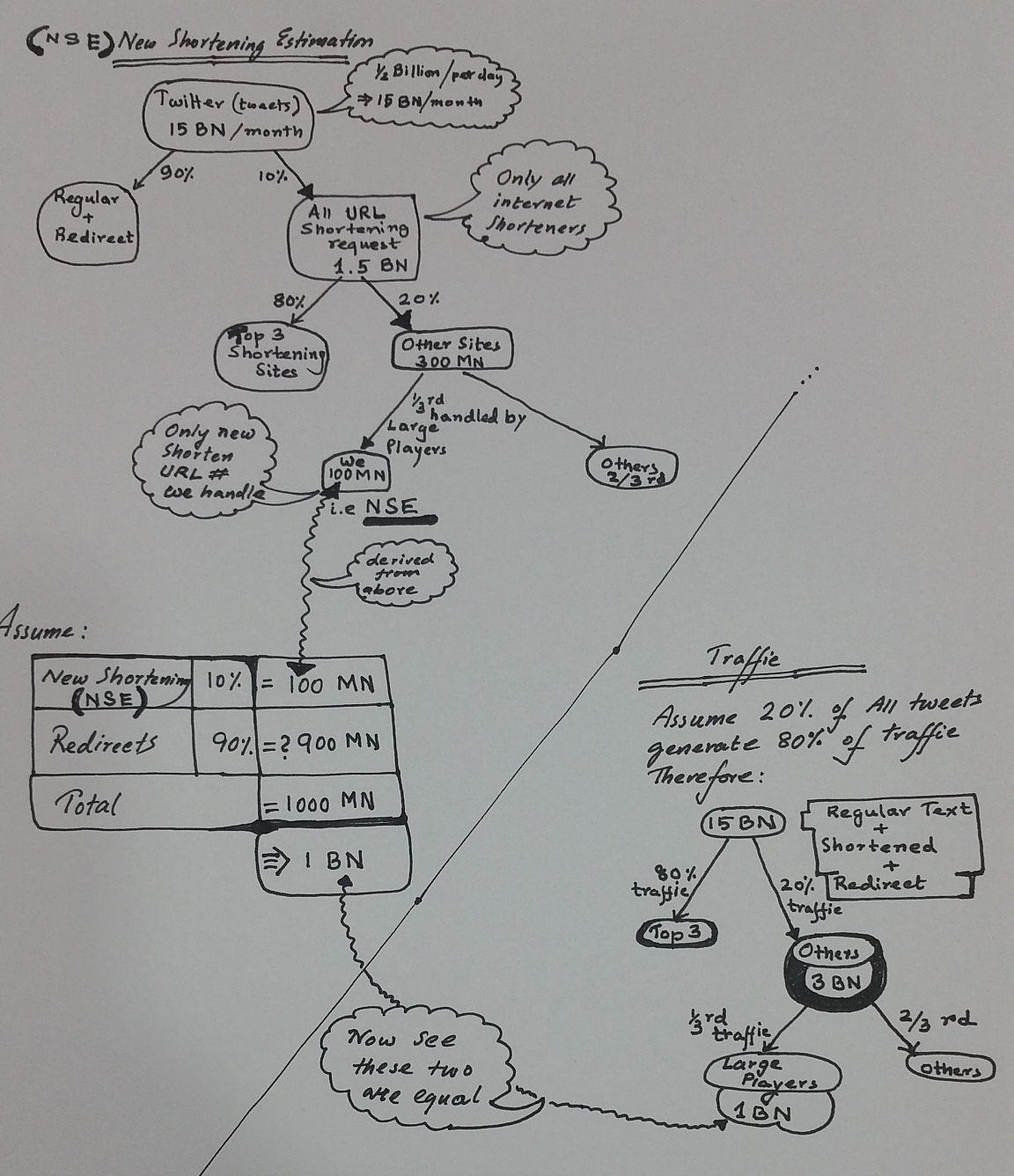
It has been pointed out to us that it is not very clear how the author gets to the 1 bln requests per month number around minute 6:00 of the video. Here is a short explanation. The author was considering the average time span of a URL (1-2 weeks, let's take the average ~ 10 days). Then he assumed 1 click per day, keeping in mind that the top 20% got much more traffic than the rest 80%. This makes 100 mln * 10 days * 1 click per day = 1 bln.
The important thing here is that these calculations are based largely on many assumptions and gut feeling. They may be incorrect. The point is that at the interview, if you need to come up with such numbers it's good to have some background knowledge but also to be able to do reasonable conclusions about the numbers and to explain them to the interviewer.
{kind=link}
hashedUrl=convert_to_base62(md5(originalUrl+randomSort))
-- right?
https://stackoverflow.com/questions/8852668/what-is-the-clash-rate-for-md5
You need to hash about 2^64 values to get a single collision among them, on average, if you don't try to deliberately create collisions. Hash collisions are very similar to the Birthday problem.
If you look at two arbitrary values, the collision probability is only 2-128.
The problem with md5 is that it's relatively easy to craft two different texts that hash to the same value. But this requires a deliberate attack, and doesn't happen accidentally. And even with a deliberate attack it's currently not feasible to get a plain text matching a given hash.
In short md5 is safe for non security purposes, but broken in many security applications.
短网址的长度该设计为多少呢? 当前互联网上的网页总数大概是 45亿(参考 http://www.worldwidewebsize.com),超过了 232=4294967296,那么用一个64位整数足够了。
一个64位整数如何转化为字符串呢?,假设我们只是用大小写字母加数字,那么可以看做是62进制数,,即字符串最长11就足够了。
实际生产中,还可以再短一点,比如新浪微博采用的长度就是7,因为 ,这个量级远远超过互联网上的URL总数了,绝对够用了。
现代的web服务器(例如Apache, Nginx)大部分都区分URL里的大小写了,所以用大小写字母来区分不同的URL是没问题的。
因此,正确答案:长度不超过7的字符串,由大小写字母加数字共62个字母组成
一对一还是一对多映射?
一个长网址,对应一个短网址,还是可以对应多个短网址? 这也是个重大选择问题
一般而言,一个长网址,在不同的地点,不同的用户等情况下,生成的短网址应该不一样,这样,在后端数据库中,可以更好的进行数据分析。如果一个长网址与一个短网址一一对应,那么在数据库中,仅有一行数据,无法区分不同的来源,就无法做数据分析了。
以这个7位长度的短网址作为唯一ID,这个ID下可以挂各种信息,比如生成该网址的用户名,所在网站,HTTP头部的 User Agent等信息,收集了这些信息,才有可能在后面做大数据分析,挖掘数据的价值。短网址服务商的一大盈利来源就是这些数据。
正确答案:一对多
如何计算短网址
现在我们设定了短网址是一个长度为7的字符串,如何计算得到这个短网址呢?
最容易想到的办法是哈希,先hash得到一个64位整数,将它转化为62进制整,截取低7位即可。但是哈希算法会有冲突,如何处理冲突呢,又是一个麻烦。这个方法只是转移了矛盾,没有解决矛盾,抛弃。
如何存储
如果存储短网址和长网址的对应关系?以短网址为 primary key, 长网址为value, 可以用传统的关系数据库存起来,例如MySQL, PostgreSQL,也可以用任意一个分布式KV数据库,例如Redis, LevelDB。
如果你手痒想要手工设计这个存储,那就是另一个话题了,你需要完整地造一个KV存储引擎轮子。当前流行的KV存储引擎有LevelDB何RockDB,去读它们的源码吧 :D
301还是302重定向
这也是一个有意思的问题。这个问题主要是考察你对301和302的理解,以及浏览器缓存机制的理解。
301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。但是如果用了301, Google,百度等搜索引擎,搜索的时候会直接展示真实地址,那我们就无法统计到短地址被点击的次数了,也无法收集用户的Cookie, User Agent 等信息,这些信息可以用来做很多有意思的大数据分析,也是短网址服务商的主要盈利来源。
所以,正确答案是302重定向。
预防攻击
如果一些别有用心的黑客,短时间内向TinyURL服务器发送大量的请求,会迅速耗光ID,怎么办呢?
首先,限制IP的单日请求总数,超过阈值则直接拒绝服务。
光限制IP的请求数还不够,因为黑客一般手里有上百万台肉鸡的,IP地址大大的有,所以光限制IP作用不大。
可以用一台Redis作为缓存服务器,存储的不是 ID->长网址,而是 长网址->ID,仅存储一天以内的数据,用LRU机制进行淘汰。这样,如果黑客大量发同一个长网址过来,直接从缓存服务器里返回短网址即可,他就无法耗光我们的ID了。
https://www.zhihu.com/question/29270034
最烂的回答
实现一个算法,将长地址转成短地址。实现长和短一一对应。然后再实现它的逆运算,将短地址还能换算回长地址。
这个回答看起来挺完美的,然后候选人也会说现在时间比较短,如果给我时间我去找这个算法就解决问题了。但是稍微有点计算机或者信息论常识的人就能发现,这个算法就跟永动机一样,是永远不可能找到的。即使我们定义短地址是100位。那么它的变化是62的100次方。62=10数字+26大写字母+26小写字母。无论这个数多么大,他也不可能大过世界上可能存在的长地址。所以实现一一对应,本身就是不可能的。
再换一个说法来反驳,如果真有这么一个算法和逆运算,那么基本上现在的压缩软件都可以歇菜了,而世界上所有的信息,都可以压缩到100个字符。这~可能吗。
另一个很烂的回答
和上面一样,也找一个算法,把长地址转成短地址,但是不存在逆运算。我们需要把短对长的关系存到DB中,在通过短查长时,需要查DB。
怎么说呢,没有改变本质,如果真有这么一个算法,那必然是会出现碰撞的,也就是多个长地址转成了同一个短地址。因为我们无法预知会输入什么样的长地址到这个系统中,所以不可能实现这样一个绝对不碰撞的hash函数。
比较烂的回答
那我们用一个hash算法,我承认它会碰撞,碰撞后我再在后面加1,2,3不就行了。
ok,这样的话,当通过这个hash算法算出来之后,可能我们会需要做btree式的大于小于或者like查找到能知道现在应该在后面加1,2,或3,这个也可能由于输入的长地址集的不确定性。导致生成短地址时间的不确定性。同样烂的回答还有随机生成一个短地址,去查找是否用过,用过就再随机,如此往复,直到随机到一个没用过的短地址。
正确的原理
上面是几种典型的错误回答,下面咱们直接说正确的原理。
正确的原理就是通过发号策略,给每一个过来的长地址,发一个号即可,小型系统直接用mysql的自增索引就搞定了。如果是大型应用,可以考虑各种分布式key-value系统做发号器。不停的自增就行了。第一个使用这个服务的人得到的短地址是http://xx.xx/0 第二个是 http://xx.xx/1 第11个是 http://xx.xx/a 第依次往后,相当于实现了一个62进制的自增字段即可。
几个子问题
1. 62进制如何用数据库或者KV存储来做?
其实我们并不需要在存储中用62进制,用10进制就好了。比如第10000个长地址,我们给它的短地址对应的编号是9999,我们通过存储自增拿到9999后,再做一个10进制到62进制的转换,转成62进制数即可。这个10~62进制转换,你完全都可以自己实现。
2. 如何保证同一个长地址,每次转出来都是一样的短地址
上面的发号原理中,是不判断长地址是否已经转过的。也就是说用拿着百度首页地址来转,我给一个http://xx.xx/abc 过一段时间你再来转,我还会给你一个 http://xx.xx/xyz。这看起来挺不好的,但是不好在哪里呢?不好在不是一一对应,而一长对多短。这与我们完美主义的基因不符合,那么除此以外还有什么不对的地方?
有人说它浪费空间,这是对的。同一个长地址,产生多条短地址记录,这明显是浪费空间的。那么我们如何避免空间浪费,有人非常迅速的回答我,建立一个长对短的KV存储即可。嗯,听起来有理,但是。。。这个KV存储本身就是浪费大量空间。所以我们是在用空间换空间,而且貌似是在用大空间换小空间。真的划算吗?这个问题要考虑一下。当然,也不是没有办法解决,我们做不到真正的一一对应,那么打个折扣是不是可以搞定?这个问题的答案太多种,各有各招,我这就不说了。(由于实在太多人纠结这个问题,请见我最下方的更新)
3. 如何保证发号器的大并发高可用
上面设计看起来有一个单点,那就是发号器。如果做成分布式的,那么多节点要保持同步加1,多点同时写入,这个嘛,以CAP理论看,是不可能真正做到的。其实这个问题的解决非常简单,我们可以退一步考虑,我们是否可以实现两个发号器,一个发单号,一个发双号,这样就变单点为多点了?依次类推,我们可以实现1000个逻辑发号器,分别发尾号为0到999的号。每发一个号,每个发号器加1000,而不是加1。这些发号器独立工作,互不干扰即可。而且在实现上,也可以先是逻辑的,真的压力变大了,再拆分成独立的物理机器单元。1000个节点,估计对人类来说应该够用了。如果你真的还想更多,理论上也是可以的。
4. 具体存储如何选择
这个问题就不展开说了,各有各道,主要考察一下对存储的理解。对缓存原理的理解,和对市面上DB、Cache系统可用性,并发能力,一致性等方面的理解。
5. 跳转用301还是302
这也是一个有意思的话题。首先当然考察一个候选人对301和302的理解。浏览器缓存机制的理解。然后是考察他的业务经验。301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。同时对服务器压力也会有一定减少。
但是如果使用了301,我们就无法统计到短地址被点击的次数了。而这个点击次数是一个非常有意思的大数据分析数据源。能够分析出的东西非常非常多。所以选择302虽然会增加服务器压力,但是我想是一个更好的选择。
实现一个算法,将长地址转成短地址。实现长和短一一对应。然后再实现它的逆运算,将短地址还能换算回长地址。
这个回答看起来挺完美的,然后候选人也会说现在时间比较短,如果给我时间我去找这个算法就解决问题了。但是稍微有点计算机或者信息论常识的人就能发现,这个算法就跟永动机一样,是永远不可能找到的。即使我们定义短地址是100位。那么它的变化是62的100次方。62=10数字+26大写字母+26小写字母。无论这个数多么大,他也不可能大过世界上可能存在的长地址。所以实现一一对应,本身就是不可能的。
再换一个说法来反驳,如果真有这么一个算法和逆运算,那么基本上现在的压缩软件都可以歇菜了,而世界上所有的信息,都可以压缩到100个字符。这~可能吗。
另一个很烂的回答
和上面一样,也找一个算法,把长地址转成短地址,但是不存在逆运算。我们需要把短对长的关系存到DB中,在通过短查长时,需要查DB。
怎么说呢,没有改变本质,如果真有这么一个算法,那必然是会出现碰撞的,也就是多个长地址转成了同一个短地址。因为我们无法预知会输入什么样的长地址到这个系统中,所以不可能实现这样一个绝对不碰撞的hash函数。
比较烂的回答
那我们用一个hash算法,我承认它会碰撞,碰撞后我再在后面加1,2,3不就行了。
ok,这样的话,当通过这个hash算法算出来之后,可能我们会需要做btree式的大于小于或者like查找到能知道现在应该在后面加1,2,或3,这个也可能由于输入的长地址集的不确定性。导致生成短地址时间的不确定性。同样烂的回答还有随机生成一个短地址,去查找是否用过,用过就再随机,如此往复,直到随机到一个没用过的短地址。
正确的原理
上面是几种典型的错误回答,下面咱们直接说正确的原理。
正确的原理就是通过发号策略,给每一个过来的长地址,发一个号即可,小型系统直接用mysql的自增索引就搞定了。如果是大型应用,可以考虑各种分布式key-value系统做发号器。不停的自增就行了。第一个使用这个服务的人得到的短地址是http://xx.xx/0 第二个是 http://xx.xx/1 第11个是 http://xx.xx/a 第依次往后,相当于实现了一个62进制的自增字段即可。
几个子问题
1. 62进制如何用数据库或者KV存储来做?
其实我们并不需要在存储中用62进制,用10进制就好了。比如第10000个长地址,我们给它的短地址对应的编号是9999,我们通过存储自增拿到9999后,再做一个10进制到62进制的转换,转成62进制数即可。这个10~62进制转换,你完全都可以自己实现。
2. 如何保证同一个长地址,每次转出来都是一样的短地址
上面的发号原理中,是不判断长地址是否已经转过的。也就是说用拿着百度首页地址来转,我给一个http://xx.xx/abc 过一段时间你再来转,我还会给你一个 http://xx.xx/xyz。这看起来挺不好的,但是不好在哪里呢?不好在不是一一对应,而一长对多短。这与我们完美主义的基因不符合,那么除此以外还有什么不对的地方?
有人说它浪费空间,这是对的。同一个长地址,产生多条短地址记录,这明显是浪费空间的。那么我们如何避免空间浪费,有人非常迅速的回答我,建立一个长对短的KV存储即可。嗯,听起来有理,但是。。。这个KV存储本身就是浪费大量空间。所以我们是在用空间换空间,而且貌似是在用大空间换小空间。真的划算吗?这个问题要考虑一下。当然,也不是没有办法解决,我们做不到真正的一一对应,那么打个折扣是不是可以搞定?这个问题的答案太多种,各有各招,我这就不说了。(由于实在太多人纠结这个问题,请见我最下方的更新)
3. 如何保证发号器的大并发高可用
上面设计看起来有一个单点,那就是发号器。如果做成分布式的,那么多节点要保持同步加1,多点同时写入,这个嘛,以CAP理论看,是不可能真正做到的。其实这个问题的解决非常简单,我们可以退一步考虑,我们是否可以实现两个发号器,一个发单号,一个发双号,这样就变单点为多点了?依次类推,我们可以实现1000个逻辑发号器,分别发尾号为0到999的号。每发一个号,每个发号器加1000,而不是加1。这些发号器独立工作,互不干扰即可。而且在实现上,也可以先是逻辑的,真的压力变大了,再拆分成独立的物理机器单元。1000个节点,估计对人类来说应该够用了。如果你真的还想更多,理论上也是可以的。
4. 具体存储如何选择
这个问题就不展开说了,各有各道,主要考察一下对存储的理解。对缓存原理的理解,和对市面上DB、Cache系统可用性,并发能力,一致性等方面的理解。
5. 跳转用301还是302
这也是一个有意思的话题。首先当然考察一个候选人对301和302的理解。浏览器缓存机制的理解。然后是考察他的业务经验。301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。同时对服务器压力也会有一定减少。
但是如果使用了301,我们就无法统计到短地址被点击的次数了。而这个点击次数是一个非常有意思的大数据分析数据源。能够分析出的东西非常非常多。所以选择302虽然会增加服务器压力,但是我想是一个更好的选择。
我的方案是:用key-value存储,保存“最近”生成的长对短的一个对应关系。注意是“最近”,也就是说,我并不保存全量的长对短的关系,而只保存最近的。比如采用一小时过期的机制来实现LRU淘汰。
这样的话,长转短的流程变成这样:
1 在这个“最近”表中查看一下,看长地址有没有对应的短地址
1.1 有就直接返回,并且将这个key-value对的过期时间再延长成一小时
1.2 如果没有,就通过发号器生成一个短地址,并且将这个“最近”表中,过期时间为1小时
所以当一个地址被频繁使用,那么它会一直在这个key-value表中,总能返回当初生成那个短地址,不会出现重复的问题。如果它使用并不频繁,那么长对短的key会过期,LRU机制自动就会淘汰掉它。
当然,这不能保证100%的同一个长地址一定能转出同一个短地址,比如你拿一个生僻的url,每间隔1小时来转一次,你会得到不同的短地址。但是这真的有关系吗?
这样的话,长转短的流程变成这样:
1 在这个“最近”表中查看一下,看长地址有没有对应的短地址
1.1 有就直接返回,并且将这个key-value对的过期时间再延长成一小时
1.2 如果没有,就通过发号器生成一个短地址,并且将这个“最近”表中,过期时间为1小时
所以当一个地址被频繁使用,那么它会一直在这个key-value表中,总能返回当初生成那个短地址,不会出现重复的问题。如果它使用并不频繁,那么长对短的key会过期,LRU机制自动就会淘汰掉它。
当然,这不能保证100%的同一个长地址一定能转出同一个短地址,比如你拿一个生僻的url,每间隔1小时来转一次,你会得到不同的短地址。但是这真的有关系吗?
http://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=145037&extra=page%3D7%26filter%3Dsortid%26sortid%3D311%26sortid%3D311
长到短,要查长的是否已经存在,存在直接返回已有值(这个就是我说的查重);如果不存在则生成一个唯一的短id存到数据库
短到长,查短id是否存在,不存在就报错,存在则返回。
其实都需要index, 然后根据需要load进cache,但是这些普通数据库都已经实现了,不需要我们操心。
当然你可以把index都load到memcache/redis加快点访问速度,不过这里都是没有必要的。
58就是62里面去掉部分元音这样不会产生foul words, 判重就是duplication check, index是如果经常要查询long url就要加index, 否则每次查询是O(n)
http://www.blogchong.com/?mod=pad&act=view&id=85
1、基于MD5码 : 这种算法计算的短网址长度一般是5位或者6位,计算过程中可能出现碰撞(概率很小),可表达的url数量为62 的5次方或6次方。感觉google(http://goo.gl),微博用的是类似这种的算法(猜的),可能看起来比较美观。
a.计算长地址的MD5码,将32位的MD码分成4段,每段8个字符
b.将a得到的8个字符串看成一个16进制的数,与N * 6个1表示的二进制数进行&操作
得到一个N * 6长的二进制数
c.将b得到的数分成N段,每段6位,然后将这N个6位数分别与61进行&操作,将得到的
数作为INDEX去字母表取相应的字母或数字,拼接就是一个长度为N的短网址。
static final char[] DIGITS = { '0', '1', '2', '3', '4', '5', '6', '7',
'8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j',
'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z' };
public String shorten(String longUrl, int urlLength) {
if (urlLength < 0 || urlLength > 6) {
throw new IllegalArgumentException(
"the length of url must be between 0 and 6");
}
String md5Hex = DigestUtils.md5Hex(longUrl);
// 6 digit binary can indicate 62 letter & number from 0-9a-zA-Z
int binaryLength = urlLength * 6;
long binaryLengthFixer = Long.valueOf(
StringUtils.repeat("1", binaryLength), BINARY);
for (int i = 0; i < 4; i++) {
String subString = StringUtils
.substring(md5Hex, i * 8, (i + 1) * 8);
subString = Long.toBinaryString(Long.valueOf(subString, 16)
& binaryLengthFixer);
subString = StringUtils.leftPad(subString, binaryLength, "0");
StringBuilder sbBuilder = new StringBuilder();
for (int j = 0; j < urlLength; j++) {
String subString2 = StringUtils.substring(subString, j * 6,
(j + 1) * 6);
int charIndex = Integer.valueOf(subString2, BINARY) & NUMBER_61;
sbBuilder.append(DIGITS[charIndex]);
}
String shortUrl = sbBuilder.toString();
if (lookupLong(shortUrl) != null) {
continue;
} else {
return shortUrl;
}
}
// if all 4 possibilities are already exists
return null;
}
NOSQL:
http://coligo.io/create-url-shortener-with-node-express-mongo/
https://github.com/coligo-io/url-shortener-node-mongo-express
Let's actually put MongoDB to work by creating a database and 2 collections: one to store our URLs that we're shortening and one to keep track of the global integer that acts as an ID for each entry in the URLs collection.
An example of our urls collection:
| _id | long_url | created_at |
|---|---|---|
| .... | .... | .... |
| 10002 | http://stackoverflow.com/questions/tagged/node.js | 2015-12-26 11:27 |
| 10003 | https://docs.mongodb.org/getting-started/node/ | 2015-12-27 12:14 |
| 10004 | http://expressjs.com/en/starter/basic-routing.html | 2015-12-28 16:12 |
Our simple counters collection that keeps track of the last _id we inserted into our urls collection:
| _id | seq |
|---|---|
| url_count | 10004 |
Every time a user creates a short URL:
- Our server will check the value of the url_count in our counters collection
- Increment it by 1 and insert that new globally unique ID as the _id of the new entry in the urls collection
If you're more familiar with relational databases like MySQL, Postgres, SQLServer, etc.. you might be wondering why we need a separate collection to keep track of that global auto incremented ID. Unlike MySQL, for instance, which allows you to define a column as an auto incremented integer, MongoDB doesn't support auto incremented fields. Instead, MongoDB has a unique field called _id that acts as a primary key, referred to as an ObjectID: a 12-byte BSON type.
We create a separate counters collection as opposed to just reading the last value of the urls collection to leverage the atomicity of the findAndModify method in MongoDB. This allows our application to handle concurrent URL shortening requests by atomically incrementing the seq field and returning the new value for use in our urls collection.
http://stackoverflow.com/questions/32798150/which-nosql-database-should-i-use-for-a-url-shortener
For a URL shortener, you'll not need a document store --- the data is too simple.
You'll not need a column store --- columns are for sorting and searching multiple attributes, like finding all Wongs in Hong Kong.
You'll not need a graph DB --- there's no graph.
You want a key/value DB. Some that you'll want to look at are the old standard MemCache, Redis, Aerospike, DynamoDB in EC2.
An example of a URL shortener, written in Node, for AerospikeDB, can be found in this github repo - it's just a single file - and the technique can be applied to other key-value systems.https://github.com/aerospike/url-shortener-nodejs
http://www.aerospike.com/blog/aerospike-url-shortening-service/
http://stackoverflow.com/questions/15868988/url-shortening-for-nosql-databases
Then, if I understand correctly, your question has to do with the fact that SQL DBs have auto-increment counters which are convenient primary keys while NoSQL DBs, like MongoDB, don't, which opens the question about what should you use as the basis for generating a new short URL.
If you want to generate auto-incrementing IDs in MongoDB there are two main approaches: optimistic loop & maintaining a separate counter collection/doc. Having tried both at scale exceeding 1,000 requests/second, I would recommend the approach based on
findAndModify.
A good URL shortener design would also include randomization, which in this case would mean leaving random gaps between different auto-incrementing IDs. You can use this by generating a random number on the client and incrementing by that number.
http://blog.gainlo.co/index.php/2016/03/08/system-design-interview-question-create-tinyurl-system/
For example, URL http://blog.gainlo.co/index.php/2015/10/22/8-things-you-need-to-know-before-system-design-interviews/ is long and hard to remember, TinyURL can create a alias for it – http://tinyurl.com/j7ve58y. If you click the alias, it’ll redirect you to the original URL.
Therefore, the question can be simplified like this – given a URL, how can we find hash function F that maps URL to a short alias:
and satisfies following condition:s
F(URL) = aliasand satisfies following condition:s
- Each URL can only be mapped to a unique alias
- Each alias can be mapped back to a unique URL easily
The second condition is the core as in the run time, the system should look up by alias and redirect to the corresponding URL quickly.
To make things easier, we can assume the alias is something like http://tinyurl.com/<alias_hash> and alias_hash is a fixed length string.
If the length is 7 containing [A-Z, a-z, 0-9], we can serve 62 ^ 7 ~= 3500 billion URLs. It’s said that there are ~644 million URLs at the time of this writing.
To begin with, let’s store all the mappings in a single database. A straightforward approach is using alias_hash as the ID of each mapping, which can be generated as a random string of length 7.
Therefore, we can first just store <ID, URL>. When a user inputs a long URL “http://www.gainlo.co”, the system creates a random 7-character string like “abcd123” as ID and inserts entry <“abcd123”, “http://www.gainlo.co”> into the database.
In the run time, when someone visits http://tinyurl.com/abcd123, we look up by ID “abcd123” and redirect to the corresponding URL “http://www.gainlo.co”.
There are quite a few follow-up questions for this problem. One thing I’d like to further discuss here is that by using GUID (Globally Unique Identifier) as the entry ID, what would be pros/cons versus incremental ID in this problem?
If you dig into the insert/query process, you will notice that using random string as IDs may sacrifice performance a little bit. More specifically, when you already have millions of records, insertion can be costly. Since IDs are not sequential, so every time a new record is inserted, the database needs to go look at the correct page for this ID. However, when using incremental IDs, insertion can be much easier – just go to the last page.
So one way to optimize this is to use incremental IDs. Every time a new URL is inserted, we increment the ID by 1 for the new entry. We also need a hash function that maps each integer ID to a 7-character string. If we think each string as a 62-base numeric, the mapping should be easy (Of course, there are other ways).
On the flip side, using incremental IDs will make the mapping less flexible. For instance, if the system allows users to set custom short URL, apparently GUID solution is easier because for whatever custom short URL, we can just calculate the corresponding hash as the entry ID.
Note: In this case, we may not use random generated key but a better hash function that maps any short URL into an ID, e.g. some traditional hash functions like CRC32, SHA-1 etc..
Cost
I can hardly not ask about how to evaluate the cost of the system. For insert/query, we’ve already discussed above. So I’ll focus more on storage cost.
Each entry is stored as <ID, URL> where ID is a 7-character string. Assuming max URL length is 2083 characters, then each entry takes 7 * 4 bytes + 2083 * 4 bytes = 8.4 KB. If we store a million URL mappings, we need around 8.4G storage.
If we consider the size of database index and we may also store other information like user ID, date each entry is inserted etc., it definitely requires much more storage.
Multiple machines
The more general problem is how to store hash mapping across multiple machines. If you know distributed key-value store, you should know that this can be a very complicated problem. I will discuss only high-level ideas here and if you are interested in all those details, I’d recommend you read papers like Dynamo: Amazon’s Highly Available Key-value Store.
In a nutshell, if you want to store a huge amount of key-value pairs across multiple instances, you need to design a lookup algorithm that allows you to find the corresponding machine for a given lookup key.
For example, if the incoming short alias is http://tinyurl.com/abcd123, based on key “abcd123” the system should know which machine stores the database that contains entry for this key. This is exactly the same idea of database sharding.
A common approach is to have machines that act as a proxy, which is responsible for dispatching requests to corresponding backend stores based on the lookup key. Backend stores are actually databases that store the mapping. They can be split by various ways like use hash(key) % 1024 to divide mappings to 1024 stores.
There are tons of details that can make the system complicated, I’ll just name a few here:
- Replication. Data stores can crash for various random reasons, therefore a common solution is having multiple replicas for each database. There can be many problems here: how to replicate instances? How to recover fast? How to keep read/write consistent?
- Resharding. When the system scales to another level, the original sharding algorithm might not work well. We may need to use a new hash algorithm to reshard the system. How to reshard the database while keeping the system running can be an extremely difficult problem.
- Concurrency. There can be multiple users inserting the same URL or editing the same alias at the same time. With a single machine, you can control this with a lock. However, things become much more complicated when you scale to multiple instances.
As we said in earlier post, specific techniques used is not that important. What really matters is the high-level idea of how to solve the problem. That’s why I don’t mention things like Redis, RebornDb etc..
https://www.packtpub.com/books/content/url-shorteners-%E2%80%93-designing-tinyurl-clone-ruby
===>
这是一道经典的系统设计面试题,是对SNAKE原则的深度应用,包含了系统设计的方方面面。最初的需求分析发现“长到短”和“短到长”两个基本接口,让我们又一次理解了“读与写是系统设计的基础”。根据日活跃一百万用户进行的QPS估算,让我们理解了什么是“用数字说话”。从最符合直觉的hash映射算法,到简单有效的整数累加算法让我们理解了什么是“不要过度设计”。从数字编码,到字母编码,甚至表情编码,让我们看到了短链接的种种变体的来源。最后对存储的估算,让我们看到了貌似复杂的功能,居然占不了什么空间。





https://github.com/zxqiu/leetcode-lintcode/blob/master/system%20design/Tiny_Url_I_II.java
Given a long url, make it shorter. To make it simpler, let's ignore the domain name.
You should implement two methods:
longToShort(url). Convert a long url to a short url.
shortToLong(url). Convert a short url to a long url starts with http://tiny.url/.
You can design any shorten algorithm, the judge only cares about two things:
The short key's length should equal to 6 (without domain and slash). And the acceptable characters are [a-zA-Z0-9]. For example: abcD9E
No two long urls mapping to the same short url and no two short urls mapping to the same long url.
Example
Given url = http://www.lintcode.com/faq/?id=10, run the following code (or something similar):
short_url = longToShort(url) // may return http://tiny.url/abcD9E
long_url = shortToLong(short_url) // return http://www.lintcode.com/faq/?id=10
The short_url you return should be unique short url and start with http://tiny.url/ and 6 acceptable characters. For example "http://tiny.url/abcD9E" or something else.
The long_url should be http://www.lintcode.com/faq/?id=10 in this case.
解:
Long url转short url分四步:
一,判断是否已经转换过。若已经转换过,直接取值返回。为此,保存两张表,从long到short和从short到long。
二,取出long url中除了网站地址的部分key。在此使用正则表达式。
三,用hash function把key进行转换。在此使用简单计数方式作hash。每转换一次,count加一。将count转成62进制数,然后若不够6位在前面补0。6位短网址有62^6~64^6~2^36个,count需要用long型才够用。
四,把转换好的短网址接上短网址前缀然后存入两个map中。
Short url转long url直接从map中取值即可。
*/
import java.util.regex.*;
public class TinyUrl {
/**
* @param url a long url
* @return a short url starts with http://tiny.url/
*/
private static long count = 0;
private static Map<String, String> s2l = new HashMap<>();
private static Map<String, String> l2s = new HashMap<>();
private static final String prefix = "http://tiny.url/";
public String longToShort(String url) {
if (l2s.containsKey(url)) {
return l2s.get(url);
}
Pattern reg = Pattern.compile("https?:\\/\\/.*\\.\\w+\\/(.*)", Pattern.CASE_INSENSITIVE);
Matcher matcher = reg.matcher(url);
if (!matcher.find()) {
return "";
}
String key = matcher.group(1);
String shortUrl = prefix + hashLong(key);
s2l.put(shortUrl, url);
l2s.put(url, shortUrl);
return shortUrl;
}
/**
* @param url a short url starts with http://tiny.url/
* @return a long url
*/
public String shortToLong(String url) {
if (s2l.containsKey(url)) {
return s2l.get(url);
}
return "";
}
private String hashLong(String url) {
String ret = "";
long div, res;
int digits = 0;
div = count++;
do {
res = div % 62;
div = div / 62;
char c = '0';
if (res >= 0 && res <= 9) {
c = (char)(res + '0');
} else if (res >= 10 && res <= 35) {
c = (char)(res - 10 + 'a');
} else {
c = (char)(res - 36 + 'A');
}
ret = String.valueOf(c) + ret;
digits++;
} while (div > 0 || digits < 6);
return ret;
}
}
/*
Tiny Url II
As a follow up for Tiny URL, we are going to support custom tiny url, so that user can create their own tiny url.
Notice
Custom url may have more than 6 characters in path.
Example
createCustom("http://www.lintcode.com/", "lccode")
>> http://tiny.url/lccode
createCustom("http://www.lintcode.com/", "lc")
>> error
longToShort("http://www.lintcode.com/problem/")
>> http://tiny.url/1Ab38c // this is just an example, you can have you own 6 characters.
shortToLong("http://tiny.url/lccode")
>> http://www.lintcode.com/
shortToLong("http://tiny.url/1Ab38c")
>> http://www.lintcode.com/problem/
shortToLong("http://tiny.url/1Ab38d")
>> null
解:
这道题的重点在理解题意。
首先,custom tiny URL不受到普通tiny URL的各种限制,比如长度,字符类型。所以直接对输入的custom tiny URL进行查重然后插入表中就可以了。
其次,对于普通的long URL到short URL的转换与上面完全一致,直接照抄过来。
由于作为global ID的count不能检查custom tiny URL,所以可能会出现custom tiny URL覆盖或者被普通URL覆盖的情况。
如果一定要防止这种情况发生,需要设定以下原则:
一,在生成普通tiny URL时,如果发现long URL被生成过,不管是否是custom tiny URL,都直接返回该值。
二,在生成普通tiny URL时,如果发现生成的short URL已经存在,需要重新生成,即count++后重生成。
三,如果一个long URL已经有了对应的custom tiny URL,再次生成不同的custom tiny URL时直接返回错误。但是如果只是有了一个普通的tiny URL,则覆盖这个普通tiny URL。
为此,增加一个isCustom map来标记一个long URL对应的short URL是否是customized。
*/
import java.util.regex.*;
public class TinyUrl2 {
private static long count = 0;
private static Map<String, String> s2l = new HashMap<>();
private static Map<String, String> l2s = new HashMap<>();
private static Map<String, Boolean> isCustom = new HashMap<>();
private static final String prefix = "http://tiny.url/";
/**
* @param long_url a long url
* @param a short key
* @return a short url starts with http://tiny.url/
*/
String createCustom(String long_url, String short_key) {
String shortUrl = prefix + short_key;
if (s2l.containsKey(shortUrl) &&
!s2l.get(shortUrl).equals(long_url)) {
return "error";
}
if (l2s.containsKey(long_url) &&
isCustom.get(long_url) &&
!l2s.get(long_url).equals(shortUrl)) {
return "error";
}
l2s.put(long_url, shortUrl);
s2l.put(shortUrl, long_url);
isCustom.put(long_url, true);
return prefix + short_key;
}
/**
* @param long_url a long url
* @return a short url starts with http://tiny.url/
*/
public String longToShort(String url) {
if (l2s.containsKey(url)) {
return l2s.get(url);
}
Pattern reg = Pattern.compile("https?:\\/\\/.*\\.\\w+\\/(.*)", Pattern.CASE_INSENSITIVE);
Matcher matcher = reg.matcher(url);
if (!matcher.find()) {
return "error";
}
String key = matcher.group(1);
String shortUrl = prefix + hashLong(key);
while (s2l.containsKey(shortUrl)) {
shortUrl = prefix + hashLong(key);
}
s2l.put(shortUrl, url);
l2s.put(url, shortUrl);
isCustom.put(url, false);
return shortUrl;
}
/**
* @param url a short url starts with http://tiny.url/
* @return a long url
*/
public String shortToLong(String url) {
if (s2l.containsKey(url)) {
return s2l.get(url);
}
return null;
}
private String hashLong(String url) {
String ret = "";
long div, res;
int digits = 0;
div = count++;
do {
res = div % 62;
div = div / 62;
char c = '0';
if (res >= 0 && res <= 9) {
c = (char)(res + '0');
} else if (res >= 10 && res <= 35) {
c = (char)(res - 10 + 'a');
} else {
c = (char)(res - 36 + 'A');
}
ret = String.valueOf(c) + ret;
digits++;
} while (div > 0 || digits < 6);
return ret;
}
http://www.jianshu.com/p/494e0dca106b
http://www.jianshu.com/p/6db232be35d7
https://www.jiuzhang.com/qa/87/
1) How would you do the long -> short mapping --按照老師上課講的說的。
2) What components would be needed for 1 Billion users at Peak time
我答了需要 Cached - memcache/redis
需要 的 database - MySQL, NoSQl
多台機器,需要sharding, horizontal and vertical way
數據庫的表裡 存的 column: ID, Url, shortUrl, status, MachineID, userID, timestamp
我也提到了rate limiter,load balancer, 但是沒展開說。
貌似沒答道面試官滿意程度,好像沒有完全解決這個問題
These are the main features of a URL shortener:
- Users can create a short URL that represents a long URL
- Users who visit the short URL will be redirected to the long URL
- Users can preview a short URL to enable them to see what the long URL is
- Users can provide a custom URL to represent the long URL
- Undesirable words are not allowed in the short URL
- Users are able to view various statistics involving the short URL, including the number of clicks and where the clicks come from (optional, not in TinyURL)
One of the ways we can associate the long URL with a unique key is to hash the long URL and use the resulting hash as the unique key. However, the resulting hash might be long and hashing functions could be slow.
The faster and easier way is to use a relational database's auto-incremented row ID as the unique key. The database will help ensure the uniqueness of the ID. However, the running row ID number is base 10. To represent a million URLs would already require 7 characters, to represent 1 billion would take up 9 characters. In order to keep the number of characters smaller, we will need a larger base numbering system.
In this clone we will use base 36, which is 26 characters of the alphabet (case insensitive) and 10 numbers. Using this system, we will only need 5 characters to represent 1 million URLs:
1,000,000 base 36 = lfls
And 1 billion URLs can be represented in just six characters:
Automatically redirecting from a short URL to a long URL1,000,000,000 base 36 = gjdgxs
HTTP has a built-in mechanism for redirection. In fact it has a whole class of HTTP status codes to do this. HTTP status codes that start with 3 (such as 301, 302) tell the browser to go look for that resource in another location. This is used in the case where a web page has moved to another location or is no longer at the original location. The two most commonly used redirection status codes are 301 Move Permanentlyand 302 Found.
301 tells the browser that the resource has moved away permanently and that it should look at that location as the permanent location of the resource. 302 on the other hand (despite its name) tells the browser that the resource it is looking for has moved away temporarily.
While the difference seems trivial, search engines (as user agents) treat the status codes differently. 301 tells the search engines that the short URL's location has moved permanently away to the long URL, so credit for the long URL goes to the long URL. However because 302 only tells the search engine that the location has moved temporarily, the credit goes to the short URL. This can cause issues with search engine marketing accounting.
Obviously in our design we will need to use the 301 Moved Permanently HTTP status code to do the redirection. When the short URL http://tinyclone.saush.com/singapore-flyer is requested, we need to send a HTTP response:
HTTP/1.1 301 Moved Permanently Location:http://maps.google.com/maps?f=q&source=s_q&hl=en&geocode=&q= singapore+flyer&vps=1&jsv=169c&sll=1.352083,103.819836&sspn=0.68645,1. 382904&g=singapore&ie=UTF8&latlng=8354962237652576151&ei=Shh3SsSRDpb4v APsxLS3BQ&cd=1&usq=Singapore+Flyer
Providing a customized short URL
Providing a customized short URL with the above design we had in mind before makes things less straightforward. Remember that our design uses the database row ID in base 36 as the unique key. To customize the short URL we cannot use this database row ID, so the customized short URL needs to be stored separately.
In Tinyclone we store the customized short URL in a separate secondary table called Links, which in turn points to the actual data in a table called Url. When a short URL is created and the user doesn't request a customized URL, we store the database record ID from the Url table as a base-36 string into the Links table. If the user requests a customized URL, we store the customized URL instead of the record ID.
A record in the Links table therefore maps a string to the actual record ID in the URL table. When a short URL is requested, we first look into the secondary table, which in turn points us to the actual record in the primary table.
Filtering undesirable words out
While we could use more complex filtering mechanisms, URL shorteners are simple web applications, so we stick to a simpler filtering mechanism. When we create the secondary table record, we compare the key with a list of banned words loaded in memory on startup.
If it is a customized short URL and the word is in the list, we prevent the user from using it. If the key was the actual record ID in the primary table, we create another record (and therefore using another record ID) to store the URL.
What happens if the new record ID is also coincidentally in the banned words list? We'll just have to create another one recursively until we find one that is not in the list. There is a probability that 2 or more consequent record IDs are in the banned words list, but the frequency of it happening is low enough that we don't need to worry about it.
Previewing the long URL
This feature is simple to implement. When the short URL preview function is called, we will show a page that displays the long URL instead of redirecting to that page. In Tinyclone we lump the preview long URL page together with the statistics information page.
Providing statistics
To provide statistics for the usage of the short URL, we need to store the number of times the short URL has been clicked and where the user is coming from. To do this, we create a Visits table to store the number of times the short URL has been visited. Each record in the Visits table stores the information about a particular visit, including its date and where the visitor comes from.
We use the environment variable from the server called REMOTE_ADDR to find out where the visitor comes. REMOTE_ADDR provides the remote IP address of the client that is accessing the short URL. We use this IP address with an IP geocoding provider to find the country that the visitor comes from then store the country code as well as the IP address.
Collecting the data is only the first step though. We will need to display it properly. There are plenty of visualization APIs and tools in the market; many of them are freely available. For the purpose of this article, we have chosen to use the Google Charts API to generate the following charts:
- A bar chart showing the daily number of visits
- A bar chart showing the total number of visits from individual countries
- A map of the world visualizing the number of visits from individual countries
You might notice that in our design the user does not need to log into this application to use it. Tinyclone is a clone that does not have any access control on its pages. Most URL shorteners have a public and main feature that redirects short URLs to their original, long URLs. In addition to that some URL shorteners have user-specific access controlled pages that provide information to the users such as the statistics and reporting feature shown above. However, in this clone we will not be implementing any access controlled pages.
===>
On the other hand, URL shorteners have it fair share of criticisms as well. Here is a summary of the bad side of URL shorteners:
- Provides opportunity to spammers because it hide original URLs
- Could be unreliable if dependent on it for redirection
- Possible undesirable or vulgar short URLs
URL shorteners have security issues. When a URL shortener creates a short URL, it effectively hides the original link and this provides opportunity for spammers or other abusers to redirect users to their sites. One relatively mild form of such attack is 'rickrolling'. Rickrolling uses a classic bait-and-switch trick to redirect users to a Rick Astley music video of Never Gonna Give You Up. For example, you might feel that the URL http://tinyurl.com/singapore-flyer goes to Google Map, but when you click on it, you might be rickrolled and redirected to that Rick Astley music video instead.
Also, because most short URLs are not customized, it is quite difficult to see if the link is genuine or not just from the URL. Many prominent websites and applications have such concerns, including MySpace, Flickr and even Microsoft Live Messenger, and have one time or another banned or restricted usage of TinyURL because of this problem. To combat spammers and fraud, URL shortening services have come up with the idea of link previews, which allows users to preview a short URL before it redirects the user to the long URL. For example TinyURL will show the user the long URL on a preview page and requires the user to explicitly go to the long URL.
Another problem is performance and reliability. When you access a website, your browser goes to a few DNS servers to resolve the address, but the URL shortener adds another layer of indirection. While DNS servers have redundancy and failsafe measures, there is no such assurance from URL shorteners. If the traffic to a particular link becomes too high, will the shortening service provider be able to add more servers to improve performance or even prevent a meltdown altogether? The problem of course lies in over-dependency on the shortening service.
Finally, a negative side effect of random or even customized short URLs is that undesirable, vulgar or embarrassing short URLs can be created. Earlier on TinyURL short URLs were predictable and it was exploited, such as embarrassing short URLs that were made to redirect to the White House websites of then U.S. Vice President Dick Cheney and Second Lady Lynne Cheney.
We have just covered significant ground on URL shorteners. If you are a programmer you might be wondering, "Why do I need to know such information? I am really interested in the programming bits, the others are just fluff to me."
https://www.bittiger.io/blog/post/JJcLtcFc8MWzSmbdW这是一道经典的系统设计面试题,是对SNAKE原则的深度应用,包含了系统设计的方方面面。最初的需求分析发现“长到短”和“短到长”两个基本接口,让我们又一次理解了“读与写是系统设计的基础”。根据日活跃一百万用户进行的QPS估算,让我们理解了什么是“用数字说话”。从最符合直觉的hash映射算法,到简单有效的整数累加算法让我们理解了什么是“不要过度设计”。从数字编码,到字母编码,甚至表情编码,让我们看到了短链接的种种变体的来源。最后对存储的估算,让我们看到了貌似复杂的功能,居然占不了什么空间。
首先考虑应用场景(Scenario),应用场景有两个:将长的URL变短并存储;查找短的URL还原。抽象一下就是两个接口。
然后考虑限制性条件(Necessary),假设我们有一百万日活用户,分别计算插入和查找的每日请求次数。假设使用插入功能的日活用户有1%,一个用户插十次,平均到秒,每秒才1.2次,好低的,随便就满足了。一年我们会新生成36,500,000个短URL。但是查找就不同啦,100%要使用,不然怎么知道这个短URL是什么页面呢,算一下每秒35次。
然后我们就可以考虑算法实现(Algorithm)。做法很简单,使用两个map,一个存储长URL到短URL的映射,一个存储短URL到长URL的映射。
大家可能比较困惑GenerateShortURL()这个函数怎么实现,有很多种方法,一种就是对长URL哈希;可是还有一种更简单的方法,就是累加,只要返回map的大小就可以。
我们已经计算出一年会生成36,500,000个短URL,如果我们用上面累加的方式来表示(只用数字编码),要8位数,加上前缀可能有点长,怎么变短呢?可以引入a到z和A到Z的字母(相当于62进制),这样长度就缩短到5位。
然后考虑数据存储(Kilobit),百万用户听起来很吓人,然而数据真的很多吗?来算一算:假设长URL的长度为100B,短URL使用我们上面的算法可以用int来表示,就是4B,假设我们还需要存储state(比如超时过期等)也用int型。这样每天有10.8M的数据,一年就是4GB。才4GB而已哎,两个map也才8GB,可以全放在内存里,并没有很吓人。
以上我们就用SNAKE原则设计了一个Tiny URL的服务,棒不棒。
http://likemyblogger.blogspot.com/2015/08/mj-9-design-tinyurl.htmlhttps://github.com/zxqiu/leetcode-lintcode/blob/master/system%20design/Tiny_Url_I_II.java
Given a long url, make it shorter. To make it simpler, let's ignore the domain name.
You should implement two methods:
longToShort(url). Convert a long url to a short url.
shortToLong(url). Convert a short url to a long url starts with http://tiny.url/.
You can design any shorten algorithm, the judge only cares about two things:
The short key's length should equal to 6 (without domain and slash). And the acceptable characters are [a-zA-Z0-9]. For example: abcD9E
No two long urls mapping to the same short url and no two short urls mapping to the same long url.
Example
Given url = http://www.lintcode.com/faq/?id=10, run the following code (or something similar):
short_url = longToShort(url) // may return http://tiny.url/abcD9E
long_url = shortToLong(short_url) // return http://www.lintcode.com/faq/?id=10
The short_url you return should be unique short url and start with http://tiny.url/ and 6 acceptable characters. For example "http://tiny.url/abcD9E" or something else.
The long_url should be http://www.lintcode.com/faq/?id=10 in this case.
解:
Long url转short url分四步:
一,判断是否已经转换过。若已经转换过,直接取值返回。为此,保存两张表,从long到short和从short到long。
二,取出long url中除了网站地址的部分key。在此使用正则表达式。
三,用hash function把key进行转换。在此使用简单计数方式作hash。每转换一次,count加一。将count转成62进制数,然后若不够6位在前面补0。6位短网址有62^6~64^6~2^36个,count需要用long型才够用。
四,把转换好的短网址接上短网址前缀然后存入两个map中。
Short url转long url直接从map中取值即可。
*/
import java.util.regex.*;
public class TinyUrl {
/**
* @param url a long url
* @return a short url starts with http://tiny.url/
*/
private static long count = 0;
private static Map<String, String> s2l = new HashMap<>();
private static Map<String, String> l2s = new HashMap<>();
private static final String prefix = "http://tiny.url/";
public String longToShort(String url) {
if (l2s.containsKey(url)) {
return l2s.get(url);
}
Pattern reg = Pattern.compile("https?:\\/\\/.*\\.\\w+\\/(.*)", Pattern.CASE_INSENSITIVE);
Matcher matcher = reg.matcher(url);
if (!matcher.find()) {
return "";
}
String key = matcher.group(1);
String shortUrl = prefix + hashLong(key);
s2l.put(shortUrl, url);
l2s.put(url, shortUrl);
return shortUrl;
}
/**
* @param url a short url starts with http://tiny.url/
* @return a long url
*/
public String shortToLong(String url) {
if (s2l.containsKey(url)) {
return s2l.get(url);
}
return "";
}
private String hashLong(String url) {
String ret = "";
long div, res;
int digits = 0;
div = count++;
do {
res = div % 62;
div = div / 62;
char c = '0';
if (res >= 0 && res <= 9) {
c = (char)(res + '0');
} else if (res >= 10 && res <= 35) {
c = (char)(res - 10 + 'a');
} else {
c = (char)(res - 36 + 'A');
}
ret = String.valueOf(c) + ret;
digits++;
} while (div > 0 || digits < 6);
return ret;
}
}
/*
Tiny Url II
As a follow up for Tiny URL, we are going to support custom tiny url, so that user can create their own tiny url.
Notice
Custom url may have more than 6 characters in path.
Example
createCustom("http://www.lintcode.com/", "lccode")
>> http://tiny.url/lccode
createCustom("http://www.lintcode.com/", "lc")
>> error
longToShort("http://www.lintcode.com/problem/")
>> http://tiny.url/1Ab38c // this is just an example, you can have you own 6 characters.
shortToLong("http://tiny.url/lccode")
>> http://www.lintcode.com/
shortToLong("http://tiny.url/1Ab38c")
>> http://www.lintcode.com/problem/
shortToLong("http://tiny.url/1Ab38d")
>> null
解:
这道题的重点在理解题意。
首先,custom tiny URL不受到普通tiny URL的各种限制,比如长度,字符类型。所以直接对输入的custom tiny URL进行查重然后插入表中就可以了。
其次,对于普通的long URL到short URL的转换与上面完全一致,直接照抄过来。
由于作为global ID的count不能检查custom tiny URL,所以可能会出现custom tiny URL覆盖或者被普通URL覆盖的情况。
如果一定要防止这种情况发生,需要设定以下原则:
一,在生成普通tiny URL时,如果发现long URL被生成过,不管是否是custom tiny URL,都直接返回该值。
二,在生成普通tiny URL时,如果发现生成的short URL已经存在,需要重新生成,即count++后重生成。
三,如果一个long URL已经有了对应的custom tiny URL,再次生成不同的custom tiny URL时直接返回错误。但是如果只是有了一个普通的tiny URL,则覆盖这个普通tiny URL。
为此,增加一个isCustom map来标记一个long URL对应的short URL是否是customized。
*/
import java.util.regex.*;
public class TinyUrl2 {
private static long count = 0;
private static Map<String, String> s2l = new HashMap<>();
private static Map<String, String> l2s = new HashMap<>();
private static Map<String, Boolean> isCustom = new HashMap<>();
private static final String prefix = "http://tiny.url/";
/**
* @param long_url a long url
* @param a short key
* @return a short url starts with http://tiny.url/
*/
String createCustom(String long_url, String short_key) {
String shortUrl = prefix + short_key;
if (s2l.containsKey(shortUrl) &&
!s2l.get(shortUrl).equals(long_url)) {
return "error";
}
if (l2s.containsKey(long_url) &&
isCustom.get(long_url) &&
!l2s.get(long_url).equals(shortUrl)) {
return "error";
}
l2s.put(long_url, shortUrl);
s2l.put(shortUrl, long_url);
isCustom.put(long_url, true);
return prefix + short_key;
}
/**
* @param long_url a long url
* @return a short url starts with http://tiny.url/
*/
public String longToShort(String url) {
if (l2s.containsKey(url)) {
return l2s.get(url);
}
Pattern reg = Pattern.compile("https?:\\/\\/.*\\.\\w+\\/(.*)", Pattern.CASE_INSENSITIVE);
Matcher matcher = reg.matcher(url);
if (!matcher.find()) {
return "error";
}
String key = matcher.group(1);
String shortUrl = prefix + hashLong(key);
while (s2l.containsKey(shortUrl)) {
shortUrl = prefix + hashLong(key);
}
s2l.put(shortUrl, url);
l2s.put(url, shortUrl);
isCustom.put(url, false);
return shortUrl;
}
/**
* @param url a short url starts with http://tiny.url/
* @return a long url
*/
public String shortToLong(String url) {
if (s2l.containsKey(url)) {
return s2l.get(url);
}
return null;
}
private String hashLong(String url) {
String ret = "";
long div, res;
int digits = 0;
div = count++;
do {
res = div % 62;
div = div / 62;
char c = '0';
if (res >= 0 && res <= 9) {
c = (char)(res + '0');
} else if (res >= 10 && res <= 35) {
c = (char)(res - 10 + 'a');
} else {
c = (char)(res - 36 + 'A');
}
ret = String.valueOf(c) + ret;
digits++;
} while (div > 0 || digits < 6);
return ret;
}
http://www.jianshu.com/p/494e0dca106b
const long long hashSize = 62 ^ 6;
map<long long, string> id2long;
map<string, long long> long2id;
const string tinyHeader = "http://tiny.url/";
map<string, string> custom2long;
map<string, string> long2custom;
public:
/**
* @param long_url a long url
* @param a short key
* @return a short url starts with http://tiny.url/
*/
string createCustom(string& long_url, string& short_key) {
string tinyURL = tinyHeader + short_key;
if (custom2long.count(short_key) > 0) {
if (custom2long[short_key] == long_url) {
return tinyURL;
} else {
return "error";
}
}
if (long2custom.count(long_url) > 0) {
if (long2custom[long_url] == short_key) {
return tinyURL;
} else {
return "error";
}
}
long long id = shortURL2id(short_key);
if (id2long.count(id) > 0) {
if (id2long[id] == long_url) {
return tinyURL;
} else {
return "error";
}
}
custom2long[short_key] = long_url;
long2custom[long_url] = short_key;
return tinyURL;
}
char number2char(int n) {
if (n <= 9) {
return '0' + n;
} else if (n <= 35) {
return 'a' + (n - 10);
} else {
return 'A' + (n - 36);
}
}
long long char2number(char c) {
if ('0' <= c && c <= '9') {
return c - '0';
} else if ('a' <= c && c <= 'z') {
return c - 'a' + 10;
} else if ('A' <= c && c <= 'Z') {
return c - 'A' + 36;
}
return 0;
}
long long shortURL2id(string url) {
long long id = 0;
for(int i = 0; i < url.size(); i++) {
id = id * 62 + char2number(url[i]);
}
return id;
}
string longToShort(string& url) {
if (long2custom.count(url) > 0) {
return tinyHeader + long2custom[url];
}
long long number = 0;
for(int i = 0; i < url.size(); i++) {
number = (number * 256 + (long long)url[i]) % hashSize;
}
while (id2long.count(number) > 0 && id2long[number] != url) {
number++;
}
id2long[number] = url;
string shortURL;
while (number > 0) {
int mod = number % 62;
number /= 62;
//shortURL = number2char(mod) + shortURL;
shortURL.push_back(number2char(mod));
}
while (shortURL.size() < 6) {
// shortURL = "0" + shortURL;
shortURL.push_back('0');
}
reverse(shortURL.begin(), shortURL.end());
shortURL = tinyHeader + shortURL;
return shortURL;
}
/**
* @param url a short url starts with http://tiny.url/
* @return a long url
*/
string shortToLong(string& url) {
string urlWithoutHeader = url.substr(tinyHeader.size(), url.size());
int id = shortURL2id(urlWithoutHeader);
if (id2long.count(id) > 0) {
return id2long[id];
}
if (custom2long.count(urlWithoutHeader) > 0) {
return custom2long[urlWithoutHeader];
}
return "";
}http://www.jianshu.com/p/6db232be35d7
https://www.jiuzhang.com/qa/87/
1) How would you do the long -> short mapping --按照老師上課講的說的。
2) What components would be needed for 1 Billion users at Peak time
我答了需要 Cached - memcache/redis
需要 的 database - MySQL, NoSQl
多台機器,需要sharding, horizontal and vertical way
數據庫的表裡 存的 column: ID, Url, shortUrl, status, MachineID, userID, timestamp
我也提到了rate limiter,load balancer, 但是沒展開說。
貌似沒答道面試官滿意程度,好像沒有完全解決這個問題
系统设计面试的核心并不是罗列关键点,而是针对具体问题具体分析,“证明出你的设计能够满足1b的请求”
例如,回答了redis,那么需要多少内存呢?需要几台服务器呢?如果有了redis,是否还需要NoSQL呢?它们还需要分布式吗?load balancer在做什么?和谁相连?怎么样限制。
因此,能否把你的答案再展开写呢?而不是罗列关键词。
https://stackoverflow.com/questions/8557490/redirect-to-a-different-url
It's called "redirecting". It's to be achieved by
HttpServletResponse#sendRedirect().response.sendRedirect(url);- The URL no longer contains any hints whatsoever as to the content of the URL. It's completely opaque. The only way to find out what's behind that hyperlink is to actually click on it. This is not a great user experience for the person doing the clicking.