Enter sharding... Sharding has gained a lot of popularity these days. This is largely thanks to the other three categories of NOSQL, where joins are an anti-pattern. Most queries involve reading or writing just a single piece of discrete data. Just as joining is an anti-pattern for key-value stores and document databases, sharding is an anti-pattern for graph databases. What I mean by that is... the very best performance will occur when all of your data is available in memory on a single instance, because hopping back and forth all over the network whenever you're reading and writing will slow things significantly down, unless you've been really really smart about how you distribute your data... and even then. Our approach has been twofold:
DetailsNeo4j still requires all data to fit on a single node. The node contents can be replicated within a cluster - but actual sharding is not part of the picture.
I can think of several ways of reduce the problem:
Batching cross machine queries so we only perform them at the close of each breadth first step.
Storing multiple levels of associations (So “users/ayende” would store its relations but also “users/ayende”’s relation and “users/arik”’s relations).
https://www.quora.com/How-well-does-the-Neo4j-scale-to-tens-or-hundreds-of-gigabytes-of-data-and-tens-or-hundreds-of-millions-of-nodes-edges for global graph queries such as shortest distance between two nodes in a graph, neo4j isn't that efficient. However, for local graph queries such as discovering neighborhood of a node in a graph, it is way more efficient than MySQL. multiple, directed, and qualified through properties. ER diagrams allow only single, undirected, named but otherwise unqualified relationships between entities for every relationship where we can have n-n combinations, we actually need to introduce something that links the two tables together. Calculating the Cartesian product of two sets (which is what relational databases need to do in order to perform the join) thin nodes and relationships, that is, nodes and relationships with few properties on them. Traversing through a node is often easier and faster than evaluating properties for each and every path. Cypher (NODE1)-[:RELATION]->(NODE2) MATCH (n) RETURN n; CREATE (romeo:Person{name: "Romeo"})-[:LOVES]->(juliet:Person{name:"Juliet"}) CREATE (juliet)-[:LOVES]->(romeo) RETURN romeo, juliet; CREATE (romeo:Teen:Person{firstName: "Romeo", lastName: "Montague", age: 13})-[:LOVES{since:"a long time ago",till:"forever",where: "Verona"}]->(juliet:Teen:Person{name:"Juliet",lastName: "Capulet",age: 13}) CREATE (romeo)<-[:LOVES]-(juliet) MATCH (n:Person) WHERE n.name="Juliet" or n.firstName="Juliet" RETURN n; MATCH (n:Person)-[:LOVES]-() WHERE toLower(n.name)="juliet" RETURN n ORDER BY n.age ASC SKIP 2 LIMIT 5 ; MATCH (n:Person{name:"Juliet"}) WHERE n.age = 13 SET n.age=14 RETURN n ; MATCH (n:Person) SET n.age=n.age+1 RETURN n ; MATCH (n:Teen:Person) WHERE n.age >18 REMOVE n:Teen RETURN n ; MATCH (n:Person) WHERE n.age>=12 AND n.age <18 SET n:Teen RETURN n ; MATCH (r:Person{lastName:"Montague"} DETACH DELETE r; nodeAliases are in lower camel case (start with lowercase) Labels are in upper camel case (start with uppercase) RELATIONS are in upper snake case (like IS_A) Property names are in lower camel case KEYWORDS are in uppercase CREATE CONSTRAINT ON (p:Person) ASSERT p.identifier IS UNIQUE DROP CONSTRAINT ON (p:Person) ASSERT p.identifier IS UNIQUE MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF]-(some:Dude) RETURN some MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF]-(someA:Dude)<-[:FRIEND_OF]-(someB:Dude) RETURN someB MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF*3]-(some:Dude) RETURN DISTINCT some openCypher Awesome Procedures on Cypher - APOC docker run --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data --volume=$HOME/neo4j/logs:/logs --volume=$HOME/neo4j/plugins:/plugins neo4j:3.4.0 Functions are designed to return a single value after a computation that only reads the database. procedures can make changes to the database and return several results. Procedures have to be CALL-ed. Functions can be referenced directly in a Cypher query (function is in bold). CREATE (p:Person{GUID:apoc.create.UUID()}) CALL apoc.help('meta') CALL db.schema() dbms.security.procedures.unrestricted=apoc.* conf/neo4j.conf to find all the People who are friends of themselves MATCH (p:Person)-[FRIEND_OF]-(p) RETURN p FOREACH (id IN range(0,1000) | CREATE (n:Node {id:id})) MATCH (n1:Node),(n2:Node) WITH n1,n2 LIMIT 1000000 WHERE rand() < 0.1 CREATE (n1)-[:TYPE_1]->(n2) MATCH (node:Node) WITH collect(node) AS nodes CALL apoc.algo.pageRank(nodes) YIELD node, score RETURN node, score
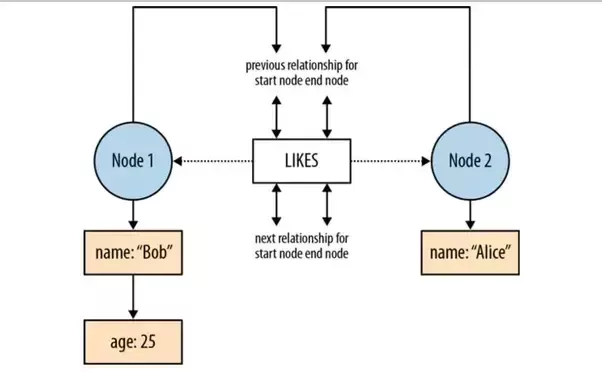
In Ne4j this is kind different. In short, every node stored in disk has a pointer only to the first relationship from a doubly linked list of relationships.
Each of the two node records contains a pointer to the first relationship in a relationship chain. [...] To find a relationship for a node, we follow that node’s relationship pointer to its first relationship (the LIKES relationship in this example). From here, we then follow the doubly linked list of relationships for that particular node (that is, either the start node doubly linked list, or the end node doubly linked list) until we find the relationship we’re interested in. [...]
Titan database, otherwise, stores more like a adjacent list format. This because it can benefits from the underlying wide-column data model, and the for every row key (vertex), it stores all edges (not only the pointer) in a contiguous area:
So, all this designs benefits from fast traversals queries, once they maintain the next ones locally, also receiving the label of "index-free adjacency" and "native processing". It means that query times are independent of the total size of the graph, and are instead simply proportional to the amount of the graph searched.
A database engine that utilizes index-free adjacency is one in which each node maintains direct references to its adjacent nodes. Each node, therefore, acts as a micro-index of other nearby nodes, which is much cheaper than using global indexes. It means that query times are independent of the total size of the graph, and are instead simply proportional to the amount of the graph searched.
A nonnative graph database engine, in contrast, uses (global) indexes to link nodes together, These indexes add a layer of indirection to each traversal, thereby incurring greater computational cost
Neo4j stores graph data in a number of different store files. Each store file contains the data for a specific part of the graph (e.g., there are separate stores for nodes, relationships, labels, and properties)
the node store is a fixed-size record store, where each record is nine bytes in length. Fixed-size records enable fast lookups for nodes in the store file
its first label (my guess is that labels are stored as a singly linked list)
its first property (properties are organized as a singly linked list)
its start/end relationships
Relationships are organized as doubly linked lists. A relationship points to:
its first property (same as nodes)
the predecessor and successor relationship of its start node
the predecessor and successor relationship of its end node
Because of this chaining structure, the notion of traversal (i.e. THE way of querying data) easily emerges. That's why a graph database like Neo4j excels at traversing graph-structured data.
My rough guess would be also, since Neo4j version 2.1 (and its newly introduced dense node management), nodes' relationships are segregated by type. By doing so, if a node N is for example a start node for 5 relationships of type A and for 5 million rels of type B, traversing rels of type A for N remains O(n=5).
https://code.fb.com/core-data/tao-the-power-of-the-graph/ https://www.quora.com/What-is-the-TAO-cache-used-for-at-Facebook TAO is the distributed data store that is widely used at facebook to store and serve the social graph. The entire architecture is highly read optimized, supports a graph data model and works across multiple geographical regions. TAO preserves some of the key advantages of the memcached/mysql architecture by cleanly separating the caching tiers from the persistent store allowing each of them to be scaled independently. To any user of the system it presents a single unified API that makes the entire system appear like 1 giant graph database.
Key advantages of the system include:
Provides a clean separation of application/product logic from data access by providing a simple yet powerful graph API and data model to store and fetch data. This enables facebook product engineers to move fast.
By implementing a write-through cache TAO allows facebook to provide a better user experience and preserve the all important read-what-you-write consistency semantics even when the architecture spans multiple geographical regions.
By implementing a read-through write-through cache TAO also protects the underlying persistent stores better by avoiding issues like thundering herds without compromising data consistency.
TAO is a very important part of the infrastructure at Facebook. This is my attempt at summarizing the TAO paper, and the blog post, and the talk by Nathan Bronson. I am purely referring to public domain materials for this post.
Memcache was being used as a cache for serving the FB graph, which is persisted on MySQL. Using Memcache along with MySQL as a look-aside/write-through cache makes it complicated for Product Engineers to write code modifying the graph while taking care of consistency, retries, etc. There has to be glue code to unify this, which can be buggy.
A new abstraction of Objects & Associations was created, which allowed expressing a lot of actions on FB as objects and their associations. Initially there seems to have been a PHP layer which deprecated direct access to MySQL for operations which fit this abstraction, while continuing to use Memcache and MySQL underneath the covers.
This PHP layer for the above model is not ideal, since:
Incremental Updates: For one-to-many associations, such as the association between a page and it’s fans on FB, any incremental update to the fan list, would invalidate the entire list in the cache.
Distributed Control Logic: Control logic resides in fat clients. Which is always problematic.
Expensive Read After Write Consistency: Unclear to me.
TAO
TAO is a write-through cache backed by MySQL.
TAO objects have a type ($otype$), along with a 64-bit globally unique id. Associations have a type ($atype$), and a creation timestamp. Two objects can have only one association of the same type. As an example, users can be Objects and their friendship can be represented as an association. TAO also provides the option to add inverse-assocs, when adding an assoc.
API
The TAO API is simple by design. Most are intuitive to understand.
assoc_add(id1, atype, id2, time, (k→v)*): Add an association of type atype from id1 to id2.
assoc_delete(id1, atype, id2): Delete the association of type atype from id1 to id2.
assoc_get(id1, atype, id2set, high?, low?): Returns assocs of atype between id1 and members of id2set, and creation time lies between $[high, low]$.
assoc_count(id1, atype): Number of assocs from id1 of type atype.
And a few others, refer to the paper.
As per the paper:
TAO enforces a per-atype upper bound (typically 6,000) on the actual limit used for an association query.
This is also probably why the maximum number of friends you can have on FB is 5000.
Architecture
There are two important factors in the TAO architecture design:
On FB the aggregate consumption of content (reads), is far more than the aggregate content creation (writes).
The TAO API is such that, to generate a newsfeed story (for example), the web-server will need to do the dependency resolution on its own, and hence will require multiple round-trips to the TAO backend. This further amplifies reads as compared to writes, bringing the read-write ratio to 500:1, as mentioned in Nathan’s talk.
The choice of being okay with multiple round-trips to build a page, while wanting to ensure a snappy product experience, imposes the requirement that:
Each of these read requests should have a low read latency (cannot cross data-center boundaries for every request).
The read availability is required to be pretty high.
Choice of Backing Store
The underlying DB is MySQL, and the TAO API is mapped to simple SQL queries. MySQL had been operated at FB for a long time, and internally backups, bulk imports, async replication etc. using MySQL was well understood. Also MySQL provides atomic write transactions, and few latency outliers.
Sharding / Data Distribution
Objects and Associations are in different tables. Data is divided into logical shards. Each shard is served by a database.
Quoting from the paper:
In practice, the number of shards far exceeds the number of servers; we tune the shard to server mapping to balance load across different hosts.
And it seems like the sharding trick we credited to Pinterest might have been used by FB first :-)
Each object id contains an embedded shard id that identifies its hosting shard.
The above setup means that your shard id is pre-decided. An assoc is stored in the shard belonging to its id1.
Consistency Semantics
TAO also requires “read-what-you-wrote” consistency semantics for writers, and eventual consistency otherwise.
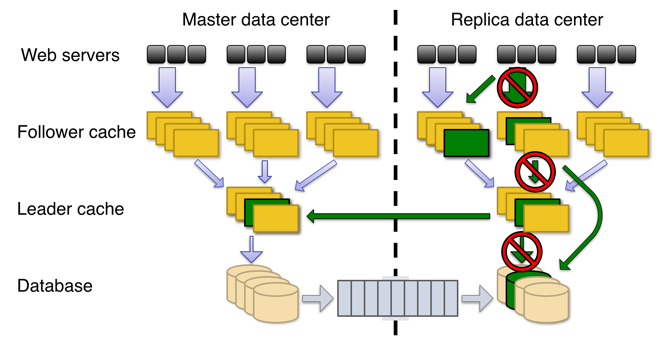
Leader-Follower Architecture
TAO is setup with multiple regions, and user requests hit the regions closest to them. The diagram below illustrates the caching architecture.
There is one ‘leader’ region and several ‘slave’ regions. Each region has a complete copy of the databases. There is an ongoing async replication between leader to slave(s). In each region, there are a group of machines which are ‘followers’, where each individual group of followers, caches and completely serves read requests for the entire domain of the data. Clients are sticky to a specific group of followers.
In each region, there is a group of leaders, where there is one leader for each shard. Read requests are served by the followers, cache misses are forwarded to the leaders, which in turn return the result from either their cache, or query the DB.
Write requests are forwarded to the leader of that region. If the current region is a slave region, the request is forwarded to the leader of that shard in the master region.
The leader sends cache-refill/invalidation messages to its followers, and to the slave leader, if the leader belongs to the master region. These messages are idempotent.
The way this is setup, the reads can never be stale in the master leader region. Followers in the master region, slave leader and by extension slave followers might be stale as well. The authors mention an average replication lag of 1s between master and slave DBs, though they don’t mention whether this is same-coast / cross-country / trans-atlantic replication.
When the leader fails, the reads go directly to the DB. The writes to the failed leader go through a random member in the leader tier.
Read Availability
There are multiple places to read, which increases read-availability. If the follower that the client is talking to, dies, the client can talk to some other follower in the same region. If all followers are down, you can talk directly to the leader in the region. Following whose failure, the client contacts the DB in the current region or other followers / leaders in other regions.
Performance
These are some client-side observed latency and hit-rate numbers in the paper.
The authors report a failure rate of $4.9 × 10^{−6}$, which is 5 9s! Though one caveat as mentioned in the paper is, because of the ‘chained’ nature of TAO requests, an initial failed request would imply the dependent requests would not be tried to begin with.
Comments
This again is a very readable paper relatively. I could understand most of it in 3 readings. It helped that there is a talk and a blog post about this. Makes the material easier to grasp.
I liked that the system is designed to have a simple API, and foucses on making them as fast as they can. Complex operations have not been built into the API. Eventual consistency is fine for a lot of use cases,
There is no transactional support, so if we have assocs and inverse assocs (for example likes_page and page_liked_by edges), and we would ideally want to remove both atomically. However, it is possible that assoc in one direction was removed, but there was a failure to remove the assoc in the other direction. These dangling pointers are removed by an async job as per the paper. So clients have to ensure that they are fine with this.
From the Q&A after the talk, Nathan Bronson mentions that there exists a flag in the calls, which could be set to force a cache miss / stronger consistency guarantees. This could be specifically useful in certain use-cases such ash blocking / privacy settings.
Pinterest’s Zen is inspired by TAO and implemented in Java. It powers messaging as well at Pinterest, interestingly (apart from the standard feed / graph based use-case), and is built on top of HBase, and a MySQL backend was in development in 2014. I have not gone through the talk, just cursorily seen the slides, but they seem to have been working on Compare-And-Swap style calls as well.
The Objects and Associations API that they created was based on the graph data model
As adoption of the new API grew, several limitations of the client-side implementation became apparent. First, small incremental updates to a list of edges required invalidation of the entire item that stored the list in cache, reducing hit rate. Second, requests operating on a list of edges had to always transfer the entire list from memcache servers over to the web servers, even if the final result contained only a few edges or was empty. This wasted network bandwidth and CPU cycles. Third, cache consistency was difficult to maintain. Finally, avoiding thundering herds in a purely client-side implementation required a form of distributed coordination that was not available for memcache-backed data at the time.
All those problems could be solved directly by writing a custom distributed service designed around objects and associations. In early 2009, a team of Facebook infrastructure engineers started to work on TAO (“The Associations and Objects”).
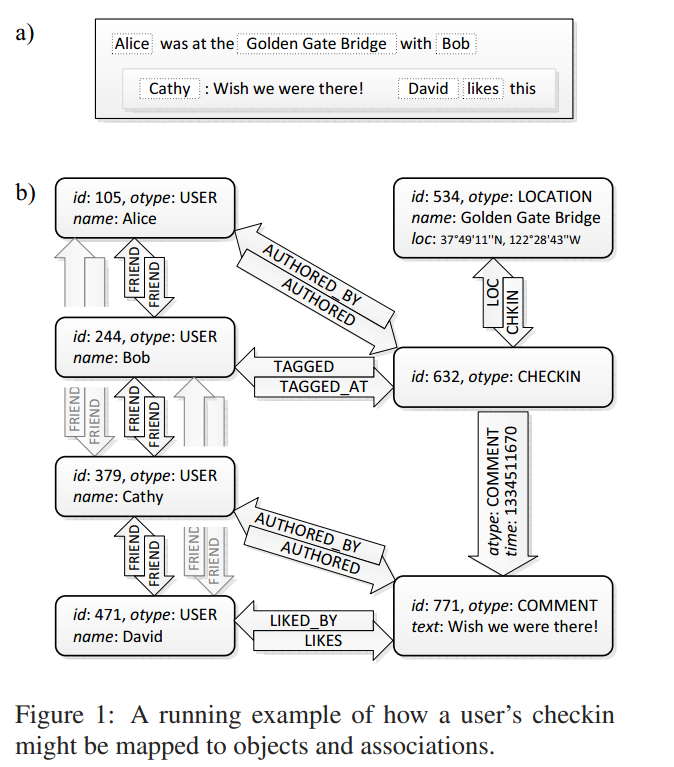
This simple example shows a subgraph of objects and associations that is created in TAO after Alice checks in at the Golden Gate Bridge and tags Bob there, while Cathy comments on the check-in and David likes it. Every data item, such as a user, check-in, or comment, is represented by a typed object containing a dictionary of named fields. Relationships between objects, such as “liked by" or “friend of," are represented by typed edges (associations) grouped in association lists by their origin. Multiple associations may connect the same pair of objects as long as the types of all those associations are distinct. Together objects and associations form a labeled directed multigraph.
For every association type a so-called inverse type can be specified. Whenever an edge of the direct type is created or deleted between objects with unique IDs id1 and id2, TAO will automatically create or delete an edge of the corresponding inverse type in the opposite direction (id2 to id1). The intent is to help the application programmer maintain referential integrity for relationships that are naturally mutual, like friendship, or where support for graph traversal in both directions is performance critical, as for example in “likes” and “liked by."
The set of operations on objects is of the fairly common create / set-fields / get / delete variety. All objects of a given type have the same set of fields. New fields can be registered for an object type at any time and existing fields can be marked deprecated by editing that type’s schema. In most cases product engineers can change the schemas of their types without any operational work.
There are three main classes of read operations on associations:
Point queries look up specific associations identified by their (id1, type, id2) triplets. Most often they are used to check if two objects are connected by an association or not, or to fetch data for an association.
Range queries find outgoing associations given an (id1, type) pair. Associations are ordered by time, so these queries are commonly used to answer questions like "What are the 50 most recent comments on this piece of content?" Cursor-based iteration is provided as well.
Count queries give the total number of outgoing associations for an (id1, type) pair. TAO optionally keeps track of counts as association lists grow and shrink, and can report them in constant time
Client requests are always sent to caching clusters running TAO servers. In addition to satisfying most read requests from a write-through cache, TAO servers orchestrate the execution of writes and maintain cache consistency among all TAO clusters. We continue to use MySQL to manage persistent storage for TAO objects and associations.
The data set managed by TAO is partitioned into hundreds of thousands of shards. All objects and associations in the same shard are stored persistently in the same MySQL database, and are cached on the same set of servers in each caching cluster. Individual objects and associations can optionally be assigned to specific shards at creation time. Controlling the degree of data collocation proved to be an important optimization technique for reducing communication overhead and avoiding hot spots.
There are two tiers of caching clusters in each geographical region. Clients talk to the first tier, called followers. If a cache miss occurs on the follower, the follower attempts to fill its cache from a second tier, called a leader. Leaders talk directly to a MySQL cluster in that region. All TAO writes go through followers to leaders. Caches are updated as the reply to a successful write propagates back down the chain of clusters. Leaders are responsible for maintaining cache consistency within a region. They also act as secondary caches, with an option to cache objects and associations in Flash. Last but not least, they provide an additional safety net to protect the persistent store during planned or unplanned outages.
TAO tries hard to guarantee with high probability that users always see their own updates. For the few use cases requiring strong consistency, TAO clients may override the default policy at the expense of higher processing cost and potential loss of availability.
We run TAO as single-master per shard and rely on MySQL replication to propagate updates from the region where the shard is mastered to all other regions (slave regions). A slave cannot update the shard in its regional persistent store. It forwards all writes to the shard’s master region. The write-through design of cache simplifies maintaining read-after-write consistency for writes that are made in a slave region for the affected shard. If necessary, the mastership can be switched to another region at any time. This is an automated procedure that is commonly used for restoring availability when a hardware failure brings down a MySQL instance.
A single Facebook page may aggregate and filter hundreds of items from the social graph. We present each user with content tailored to them, and we filter every item with privacy checks that take into account the current viewer. This extreme customization makes it infeasible to perform most aggregation and filtering when content is created; instead we resolve data dependencies and check privacy each time the content is viewed. As much as possible we pull the social graph, rather than pushing it. This implementation strategy places extreme read demands on the graph data store; it must be efficient, highly available, and scale to high query rates.
TAO is optimized heavily for reads, and favours efficiency and availability over consistency. It grew out of an existing system of memcaches in front of MySQL, queried in PHP. TAO continues to use MySQL for persistent storage, but mediates access to the database and uses its own graph aware cache.
TAO implements an objects and associations model. Objects are typed nodes in the graph, and associations are typed directed edges between objects. Objects and associations may contain data as key-value pairs, the schema of the corresponding object or association type determines the possible keys, value types, and default value. At most one association of a given type can exist between any two objects. Every association has a time field, which is critical for ordering query results by recency (e.g. most recent comments on a post). An association may also have an inverse type configured – bidirectional associations are modelled as two separate associations. There are no restrictions on the edge types that can connect to a particular node type, or the node types that can terminate an edge type.
The starting point for any TAO association query is an originating object and an association type. This is the natural result of searching for a specific type of information about a particular object… TAO’s association queries are organized around association lists. We define an association list to be the list of all associations with a particular id1 and atype, arranged in descending order by the time field. For example, the list (i, COMMENT) has edges to the example’s comments about i, most recent first.
Architecture & Implementation
All of the data for objects and associations is stored in MySQL. A non-SQL store could also have been used, but when looking at the bigger picture SQL still has many advantages:
…it is important to consider the data accesses that don’t use the API. These include back-ups, bulk import and deletion of data, bulk migrations from one data format to another, replica creation, asynchronous replication, consistency monitoring tools, and operational debugging. An alternate store would also have to provide atomic write transactions, efficient granular writes, and few latency outliers.
The space of objects and associations is divided into shards, each shard is assigned to a logical MySQL database with a table for objects and a table for associations. Objects of different types are therefore stored in the same table (with some separate custom tables for objects that benefit from separate data management). To avoid potentially expensive SELECT COUNT queries, association counts are stored in a separate table.
Each shard is contained in a logical database. Database servers are responsible for one or more shards. In practice, the number of shards far exceeds the number of servers; we tune the shard to server mapping to balance load across different hosts. By default all object types are stored in one table, and all association types in another. Each object id contains an embedded shard id that identifies its hosting shard. Objects are bound to a shard for their entire lifetime. An association is stored on the shard of its id1, so that every association query can be served from a single server. Two ids are unlikely to map to the same server unless they were explicitly colocated at creation time
TAO’s caching layer implements the full API for clients and handles all communication with the databases.
The social graph is tightly interconnected; it is not possible to group users so that cross-partition requests are rare. This means that each TAO follower must be local to a tier of databases holding a complete multi-petabyte copy of the social graph.
It’s too expensive to keep a full copy of the Facebook graph in every datacenter. Therefore several datacenters in a geographic region with low-latency interconnection (sub millisecond) between them are designated a region, and one copy of the graph is kept per-region. The master of a shard will have a slave in another region.
We prefer to locate all of the master databases in a single region. When an inverse association is mastered in a different region, TAO must traverse an extra inter-region link to forward the inverse write.
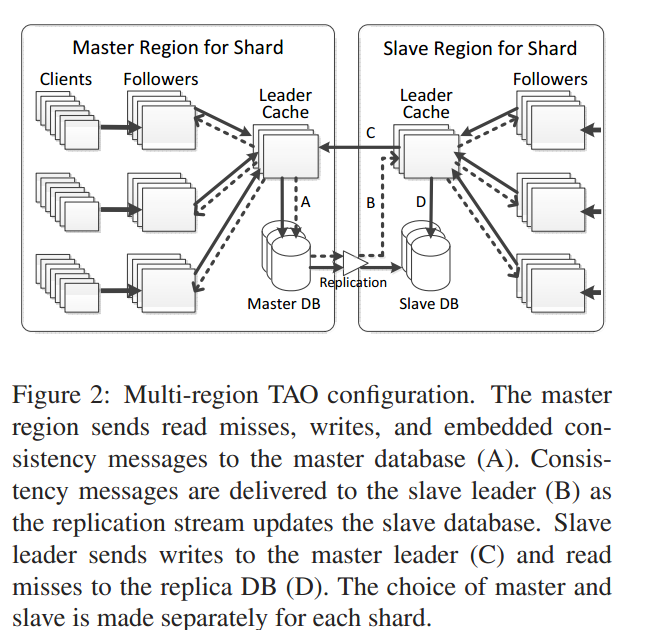
Within a region, there is a two-layer caching hierarchy to help handle the load.
A region has several follower tiers. Each tier contains a number of TAO servers, responsible for all of the shards between them. Follower tiers forward writes & read misses to a single TAO leader tier. This leader tier is responsible for interacting with the MySQL tier that holds the MySQL databases for all of the shards. All interactions with the data tier go through the leader tier. The leader tier asynchronously sends cache management messages to followers to keep them up to date.
Write operations on an association with an inverse may involve two shards, since the forward edge is stored on the shard for id1 and the inverse edge is on the shard for id2. The tier member that receives the query from the client issues an RPC call to the member hosting id2, which will contact the database to create the inverse asso- ciation. Once the inverse write is complete, the caching server issues a write to the database for id1. TAO does not provide atomicity between the two updates. If a failure occurs the forward may exist without an inverse; these hanging associations are scheduled for repair by an asynchronous job.
Replication lag in normally less than one second, and TAO provides read-after-write consistency within a single tier. Writes to MySQL are synchronous so the master database is a consistent source of truth.
This allows us to provide stronger consistency for the small subset of requests that need it. TAO reads may be marked critical, in which case they will be proxied to the master region. We could use critical reads during an authentication process, for example, so that replication lag doesn’t allow use of stale credentials.
TAO deliberately supports a restricted graph API. Facebook has large-scale offline graph processing systems similar in spirit to Google’s Pregel, but these operate on data copied from TAO’s databases and not within TAO itself.
TAO is deployed at scale inside Facebook. Its separation of cache and persistent store has allowed those layers to be independently designed, scaled, and operated, and maximizes the reuse of components across our organization. This separation also allows us to choose different tradeoffs for efficiency and consistency at the two layers, and to use an idempotent cache invalidation strategy. TAO’s restricted data and consistency model has proven to be usable for our application developers while allowing an efficient and highly available implementation.
While this is immensely useful, most information in Facebook is best represented using a social graph and the content that gets rendered on a page is highly customizable depending on users privacy settings and it is personalized for every user. This means that the data needs to be stored as-is and then filtered when it is being viewed/rendered.
In the memcache implementation at Facebook, memcache issue leases that tell clients to wait for some time and that prevents thundering herds(read and write on the same popular objects causing misses in cache and then going to database). This moves control logic to clients and since clients don’t communicate with each other, it adds more complexity there. In the model of Objects and Associations, everything is controlled by the TAO system which can implement these efficiently and hence clients are free to iterate quickly
Persistent Storage
At a high level, TAO uses mysql database as the persistent store for the objects and associations. This way they get all the features of database replication, backups, migrations etc.
The overall contents of the system are divided into shards. Each object_id contains a shard_id in it, reflecting the logical location of that object. This translates to locating the host for this object. Also Associations are stored on the same shard as its originating object(Remember that association is defined as Object1, AssociationType, Object2). This ensures better locality and helps with retrieving objects and associations from the same host. There are far more shards in the system than the number of hosts that host the mysql servers. So many shards are mapped onto a single host.
All the data belonging to objects is serialized and stored against the id. This makes the object table design pretty straightforward in the mysql database. Association are stored similarly with id as the key and data being serialized and stored in one column. Given the queries mentioned above, further indices are built on association tables for: originating id(Object1), time based sorting, type of association.
Caching Layer
If there is a read-miss then caches can contact the nearby caches or go to the database. On a write, caches go the database for a synchronous update. This helps with read-after-write consistency in most cases; more details on this in the following sections.
A single, large tier is prone to hot spots and square growth in terms of all-to-all connections.
Cache split into 2 levels - one leader tier and multiple follower tiers.
Clients communicate only with the followers.
In the case of read miss/write, followers forward the request to the leader which connects to the storage layer.
Eventual consistency maintained by serving cache maintenance messages from leaders to followers.
Object update in leaders leads results in invalidation message to followers.
Leader sends refill message to notify about association write.
Leaders also serialize concurrent writes and mediates thundering herds.
Scaling Geographically
Since workload is read intensive, read misses are serviced locally at the expense of data freshness.
In the multi-region configuration, there are master-slave regions for each shard and each region has its own followers, leader, and database.
Database in the local region is a replica of the database in the master region.
In the case of read miss, the leader always queries the region database (irrespective of it being the master database or slave database).
In the case of write, the leader in the local region would forward the request to database in the master region.
Caching Server
RAM is partitioned into arena to extend the lifetime of important data types.
For small, fixed-size items (eg association count), a direct 8-way associative cache is maintained to avoid the use of pointers.
Each atype is mapped to 16-bit value to reduce memory footprint.
Cache Sharding and Hot Spots
Load is balanced among followers through shard cloning(reads to a shard are served by multiple followers in a tier).
Response to query include the object's access rate and version number. If the access rate is too high, the object is cached by the client itself. Next time when the query comes, the data is omitted in the reply if it has not changed since the previous version.
High Degree Objects
In the case of assoc_count, the edge direction is chosen on the basis of which node (source or destination) has a lower degree (to optimize reading the association list).
For assoc_get query, only those associations are searched where time > object's creation time.
Failure Detection and Handling
Aggressive network timeouts to detect (potential) failed nodes.
Database Failure
In the case of master failure, one of the slaves take over automatically.
In case of slave failure, cache miss are redirected to TAO leader in the region hosting the database master.
Leader Failure
When a leader cache server fails, followers route read miss directly to the database and write to a replacement leader (chosen randomly from the leader tier).
Refill and Invalidation Failures
Refill and invalidation are sent asynchronously.
If the follower is not available, it is stored in leader's disk.
These messages will be lost in case of leader failure.
To maintain consistency, all the shards mapping to a failed leader are invalidated.
Follower Failure
Each TAO client is configured with a primary and backup follower tier.
In normal mode, the request is made to primary tier and in the case of its failure, requests go to backup tier.
Read after write consistency may be violated if failing over between different tiers (read reaches the failover target before writer's refill or invalidate).
Client communication stack:use a protocol with out-of-order responses
Leaders and followers:cache被分为两层,一个leader tier和多个follower tiers,leaders主要是读写存储层,followers处理读丢失和把写操作传递给一个leader。TAO处理最后的一致性是通过异步方式从leader到followers传递包括版本号的缓冲维护消息,follower收到leader发来的回应后处理读操作。
https://www.quora.com/What-was-the-reason-for-Facebook-team-to-avoid-using-Neo4J-for-the-Social-Graph Facebook has so much data to process that using anything but a custom-built solution would be infeasible FB does over a billion reads and a couple million writes per second to this graph. Neo4J is a graph database that supports ACID, but your standard ACID properties are not really needed in a social media context; very high speed, availability and high concurrency are more desirable than 100% transaction correctness.
Neo4J does not have a caching layer (which is extremely important as the disk-based backing store for TAO will not be able to support the amount of read QPS). Neo4J was also not designed as a distributed data store -- Facebook needs to have TAO presence in all its data centers to ensure that data fetching is fast (you will be surprised by how much data is fetched from TAO for every request).
Neo4j addresses different needs. For Facebook:
eventual consistency is sufficient, so there's no need for Neo4j's ACID compliance,
traffic is so huge that Neo4j's read-only horizontal scaling isn't sufficient; updates must need to scale as well,
amount of data is so huge that sharding is unavoidable, but Neo4j can't do it.
With Dragon, we specify an index and filter by the attribute of interest as we traverse the graph. When a query hits for the first time, Dragon falls back to TAO to set up the initial data in RocksDB on persistent storage. Dragon stores the most recent data or data that is likely to be queried the most often; pushing the code closer to storage allows queries to be answered much more efficiently. So, for example, when Alice visits Shakira’s page, it’s possible to compute a key involving <PostID, Language> and seek directly to the posts of interest. We can also do more complex sorting on persistent storage — for example, <Language, Score, CommentID> — to reduce the cost of the query.
While most people on Facebook don’t receive a high volume of comments on every post they make, many people tend to upload a lot of pictures. A typical photo upload on Facebook results in about 20 edges being written to MySQL and cached in RAM via TAO. These edges might include things like who uploaded the photo, where the photo was taken, whether anyone was tagged in the photo, and so on. The idea was to take advantage of the fact that most of this information is read-mostly, so we could do most of the work at write time. But this information required storage. Data size grew 20x over six years; about half the storage requirement was for data about edges — but only a small fraction of it described the primary relationship between two entities (for example, Alice → [uploaded] → PhotoID and PhotoID → [uploaded by] → Alice).
With Dragon, we write only this primary edge, and then create indices based on how we want to navigate. While indexing makes reads faster, it makes writes slower, so we create an index only when it makes sense. A post with 10 comments, for example, doesn't need an index because it's easy enough to scan through the comments individually with TAO. The combination of partial indexing techniques and a richer query language that supports a filter/orderby operator allows us to index a system that is roughly 150x larger while serving 90 percent of queries from the cache.
Inverted indexing is a popular technique in information retrieval. When Alice likes Shakira, we store two edges (Alice → [likes] → Shakira and Shakira → [liked-by] Alice) on the host responsible for Alice. What we get is a distributed inverted index, because the Shakira likers aren’t limited to only one host. Querying such an index requires communication with all hosts in the cluster, which significantly increases latency and the cost of the query.