https://zeroturnaround.com/rebellabs/a-glance-into-the-developers-world-of-data-graphs-rdbms-and-nosql/
https://zeroturnaround.com/rebellabs/examples-where-graph-databases-shine-neo4j-edition/
docker run --rm --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data --volume=$HOME/neo4j/logs:/logs neo4j:3.1.2
https://www.quora.com/How-does-Neo4j-scale-compared-to-a-traditional-RDBMS-like-MySQL-or-Postgres
https://dzone.com/articles/scaling-graph-databases
https://www.quora.com/How-well-does-the-Neo4j-scale-to-tens-or-hundreds-of-gigabytes-of-data-and-tens-or-hundreds-of-millions-of-nodes-edges
for global graph queries such as shortest distance between two nodes in a graph, neo4j isn't that efficient. However, for local graph queries such as discovering neighborhood of a node in a graph, it is way more efficient than MySQL.
multiple, directed, and qualified through properties.
ER diagrams allow only single, undirected, named but otherwise unqualified relationships between entities
for every relationship where we can have n-n combinations, we actually need to introduce something that links the two tables together.
Calculating the Cartesian product of two sets (which is what relational databases need to do in order to perform the join)
thin nodes and relationships, that is, nodes and relationships with few properties on them.
Traversing through a node is often easier and faster than evaluating properties for each and every path.
Cypher
(NODE1)-[:RELATION]->(NODE2)
MATCH (n)
RETURN n;
CREATE (romeo:Person{name: "Romeo"})-[:LOVES]->(juliet:Person{name:"Juliet"})
CREATE (juliet)-[:LOVES]->(romeo)
RETURN romeo, juliet;
CREATE (romeo:Teen:Person{firstName: "Romeo", lastName: "Montague", age: 13})-[:LOVES{since:"a long time ago",till:"forever",where: "Verona"}]->(juliet:Teen:Person{name:"Juliet",lastName: "Capulet",age: 13})
CREATE (romeo)<-[:LOVES]-(juliet)
MATCH (n:Person)
WHERE n.name="Juliet" or n.firstName="Juliet"
RETURN n;
MATCH (n:Person)-[:LOVES]-()
WHERE toLower(n.name)="juliet"
RETURN n ORDER BY n.age ASC
SKIP 2 LIMIT 5 ;
MATCH (n:Person{name:"Juliet"})
WHERE n.age = 13
SET n.age=14
RETURN n ;
MATCH (n:Person)
SET n.age=n.age+1
RETURN n ;
MATCH (n:Teen:Person)
WHERE n.age >18
REMOVE n:Teen
RETURN n ;
MATCH (n:Person)
WHERE n.age>=12 AND n.age <18
SET n:Teen
RETURN n ;
MATCH (r:Person{lastName:"Montague"}
DETACH DELETE r;
nodeAliases are in lower camel case (start with lowercase)
Labels are in upper camel case (start with uppercase)
RELATIONS are in upper snake case (like IS_A)
Property names are in lower camel case
KEYWORDS are in uppercase
CREATE CONSTRAINT ON (p:Person) ASSERT p.identifier IS UNIQUE
DROP CONSTRAINT ON (p:Person) ASSERT p.identifier IS UNIQUE
MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF]-(some:Dude)
RETURN some
MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF]-(someA:Dude)<-[:FRIEND_OF]-(someB:Dude)
RETURN someB
MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF*3]-(some:Dude)
RETURN DISTINCT some
openCypher
Awesome Procedures on Cypher - APOC
docker run --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data --volume=$HOME/neo4j/logs:/logs --volume=$HOME/neo4j/plugins:/plugins neo4j:3.4.0
Functions are designed to return a single value after a computation that only reads the database.
procedures can make changes to the database and return several results.
Procedures have to be CALL-ed. Functions can be referenced directly in a Cypher query (function is in bold).
CREATE (p:Person{GUID:apoc.create.UUID()})
CALL apoc.help('meta')
CALL db.schema()
dbms.security.procedures.unrestricted=apoc.*
conf/neo4j.conf
to find all the People who are friends of themselves
MATCH (p:Person)-[FRIEND_OF]-(p)
RETURN p
FOREACH (id IN range(0,1000) | CREATE (n:Node {id:id}))
MATCH (n1:Node),(n2:Node) WITH n1,n2 LIMIT 1000000 WHERE rand() < 0.1
CREATE (n1)-[:TYPE_1]->(n2)
MATCH (node:Node) WITH collect(node) AS nodes
CALL apoc.algo.pageRank(nodes) YIELD node, score
RETURN node, score
ORDER BY score DESC
https://www.quora.com/How-is-Neo4j-stored-on-a-disk-Is-it-some-kind-of-adjacent-matrix-stored-in-a-relational-database


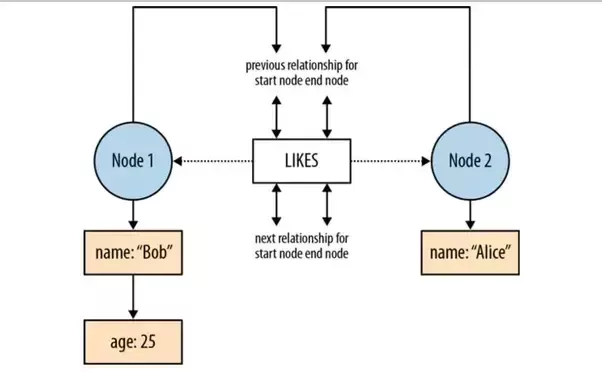
In Ne4j this is kind different. In short, every node stored in disk has a pointer only to the first relationship from a doubly linked list of relationships.
A database engine that utilizes index-free adjacency is one in which each node maintains direct references to its adjacent nodes. Each node, therefore, acts as a micro-index of other nearby nodes, which is much cheaper than using global indexes. It means that query times are independent of the total size of the graph, and are instead simply proportional to the amount of the graph searched.
A nonnative graph database engine, in contrast, uses (global) indexes to link nodes together, These indexes add a layer of indirection to each traversal, thereby incurring greater computational cost
Neo4j stores graph data in a number of different store files. Each store file contains the data for a specific part of the graph (e.g., there are separate stores for nodes, relationships, labels, and properties)
the node store is a fixed-size record store, where each record is nine bytes in length. Fixed-size records enable fast lookups for nodes in the store file
https://stackoverflow.com/questions/24366078/how-neo4j-stores-data-internally
https://zeroturnaround.com/rebellabs/examples-where-graph-databases-shine-neo4j-edition/
docker run --rm --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data --volume=$HOME/neo4j/logs:/logs neo4j:3.1.2
Ports used by Neo4j are 7474, 7473, and 7687, for the protocols http, https, and bolt, respectively .
Enter sharding... Sharding has gained a lot of popularity these days. This is largely thanks to the other three categories of NOSQL, where joins are an anti-pattern. Most queries involve reading or writing just a single piece of discrete data. Just as joining is an anti-pattern for key-value stores and document databases, sharding is an anti-pattern for graph databases. What I mean by that is... the very best performance will occur when all of your data is available in memory on a single instance, because hopping back and forth all over the network whenever you're reading and writing will slow things significantly down, unless you've been really really smart about how you distribute your data... and even then. Our approach has been twofold:
Details
Neo4j still requires all data to fit on a single node. The node contents can be replicated within a cluster - but actual sharding is not part of the picture.https://dzone.com/articles/scaling-graph-databases
I can think of several ways of reduce the problem:
- Batching cross machine queries so we only perform them at the close of each breadth first step.
- Storing multiple levels of associations (So “users/ayende” would store its relations but also “users/ayende”’s relation and “users/arik”’s relations).
https://www.quora.com/How-well-does-the-Neo4j-scale-to-tens-or-hundreds-of-gigabytes-of-data-and-tens-or-hundreds-of-millions-of-nodes-edges
for global graph queries such as shortest distance between two nodes in a graph, neo4j isn't that efficient. However, for local graph queries such as discovering neighborhood of a node in a graph, it is way more efficient than MySQL.
multiple, directed, and qualified through properties.
ER diagrams allow only single, undirected, named but otherwise unqualified relationships between entities
for every relationship where we can have n-n combinations, we actually need to introduce something that links the two tables together.
Calculating the Cartesian product of two sets (which is what relational databases need to do in order to perform the join)
thin nodes and relationships, that is, nodes and relationships with few properties on them.
Traversing through a node is often easier and faster than evaluating properties for each and every path.
Cypher
(NODE1)-[:RELATION]->(NODE2)
MATCH (n)
RETURN n;
CREATE (romeo:Person{name: "Romeo"})-[:LOVES]->(juliet:Person{name:"Juliet"})
CREATE (juliet)-[:LOVES]->(romeo)
RETURN romeo, juliet;
CREATE (romeo:Teen:Person{firstName: "Romeo", lastName: "Montague", age: 13})-[:LOVES{since:"a long time ago",till:"forever",where: "Verona"}]->(juliet:Teen:Person{name:"Juliet",lastName: "Capulet",age: 13})
CREATE (romeo)<-[:LOVES]-(juliet)
MATCH (n:Person)
WHERE n.name="Juliet" or n.firstName="Juliet"
RETURN n;
MATCH (n:Person)-[:LOVES]-()
WHERE toLower(n.name)="juliet"
RETURN n ORDER BY n.age ASC
SKIP 2 LIMIT 5 ;
MATCH (n:Person{name:"Juliet"})
WHERE n.age = 13
SET n.age=14
RETURN n ;
MATCH (n:Person)
SET n.age=n.age+1
RETURN n ;
MATCH (n:Teen:Person)
WHERE n.age >18
REMOVE n:Teen
RETURN n ;
MATCH (n:Person)
WHERE n.age>=12 AND n.age <18
SET n:Teen
RETURN n ;
MATCH (r:Person{lastName:"Montague"}
DETACH DELETE r;
nodeAliases are in lower camel case (start with lowercase)
Labels are in upper camel case (start with uppercase)
RELATIONS are in upper snake case (like IS_A)
Property names are in lower camel case
KEYWORDS are in uppercase
CREATE CONSTRAINT ON (p:Person) ASSERT p.identifier IS UNIQUE
DROP CONSTRAINT ON (p:Person) ASSERT p.identifier IS UNIQUE
MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF]-(some:Dude)
RETURN some
MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF]-(someA:Dude)<-[:FRIEND_OF]-(someB:Dude)
RETURN someB
MATCH (le:Dude {name:"Lebowski"})<-[:FRIEND_OF*3]-(some:Dude)
RETURN DISTINCT some
openCypher
Awesome Procedures on Cypher - APOC
docker run --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data --volume=$HOME/neo4j/logs:/logs --volume=$HOME/neo4j/plugins:/plugins neo4j:3.4.0
Functions are designed to return a single value after a computation that only reads the database.
procedures can make changes to the database and return several results.
Procedures have to be CALL-ed. Functions can be referenced directly in a Cypher query (function is in bold).
CREATE (p:Person{GUID:apoc.create.UUID()})
CALL apoc.help('meta')
CALL db.schema()
dbms.security.procedures.unrestricted=apoc.*
conf/neo4j.conf
to find all the People who are friends of themselves
MATCH (p:Person)-[FRIEND_OF]-(p)
RETURN p
FOREACH (id IN range(0,1000) | CREATE (n:Node {id:id}))
MATCH (n1:Node),(n2:Node) WITH n1,n2 LIMIT 1000000 WHERE rand() < 0.1
CREATE (n1)-[:TYPE_1]->(n2)
MATCH (node:Node) WITH collect(node) AS nodes
CALL apoc.algo.pageRank(nodes) YIELD node, score
RETURN node, score
ORDER BY score DESC
https://www.quora.com/How-is-Neo4j-stored-on-a-disk-Is-it-some-kind-of-adjacent-matrix-stored-in-a-relational-database
In Ne4j this is kind different. In short, every node stored in disk has a pointer only to the first relationship from a doubly linked list of relationships.
Each of the two node records contains a pointer to the first relationship in a relationship chain. [...] To find a relationship for a node, we follow that node’s relationship pointer to its first relationship (the LIKES relationship in this example). From here, we then follow the doubly linked list of relationships for that particular node (that is, either the start node doubly linked list, or the end node doubly linked list) until we find the relationship we’re interested in. [...]
Titan database, otherwise, stores more like a adjacent list format. This because it can benefits from the underlying wide-column data model, and the for every row key (vertex), it stores all edges (not only the pointer) in a contiguous area:

So, all this designs benefits from fast traversals queries, once they maintain the next ones locally, also receiving the label of "index-free adjacency" and "native processing". It means that query times are independent of the total size of the graph, and are instead simply proportional to the amount of the graph searched.
So, all this designs benefits from fast traversals queries, once they maintain the next ones locally, also receiving the label of "index-free adjacency" and "native processing". It means that query times are independent of the total size of the graph, and are instead simply proportional to the amount of the graph searched.
A database engine that utilizes index-free adjacency is one in which each node maintains direct references to its adjacent nodes. Each node, therefore, acts as a micro-index of other nearby nodes, which is much cheaper than using global indexes. It means that query times are independent of the total size of the graph, and are instead simply proportional to the amount of the graph searched.
A nonnative graph database engine, in contrast, uses (global) indexes to link nodes together, These indexes add a layer of indirection to each traversal, thereby incurring greater computational cost
Neo4j stores graph data in a number of different store files. Each store file contains the data for a specific part of the graph (e.g., there are separate stores for nodes, relationships, labels, and properties)
the node store is a fixed-size record store, where each record is nine bytes in length. Fixed-size records enable fast lookups for nodes in the store file
https://stackoverflow.com/questions/24366078/how-neo4j-stores-data-internally
http://www.slideshare.net/thobe/an-overview-of-neo4j-internals is a bit outdated but this gives you a good overview of Neo4j logical representation.
A node references:
- its first label (my guess is that labels are stored as a singly linked list)
- its first property (properties are organized as a singly linked list)
- its start/end relationships
Relationships are organized as doubly linked lists. A relationship points to:
- its first property (same as nodes)
- the predecessor and successor relationship of its start node
- the predecessor and successor relationship of its end node
Because of this chaining structure, the notion of traversal (i.e. THE way of querying data) easily emerges. That's why a graph database like Neo4j excels at traversing graph-structured data.
My rough guess would be also, since Neo4j version 2.1 (and its newly introduced dense node management), nodes' relationships are segregated by type. By doing so, if a node N is for example a start node for 5 relationships of type A and for 5 million rels of type B, traversing rels of type A for N remains O(n=5).