https://people.eecs.berkeley.edu/~brewer/papers/GiantScale-IEEE.pdf
http://muratbuffalo.blogspot.com/2011/01/lessons-from-giant-scale-services.html
https://loonytek.com/2017/03/15/notes-on-distributed-systems-part-1/
http://www.infoq.com/cn/articles/features-and-design-concept-of-distributed-system

cascading failure
《分布式服务框架原理与实践》
《亿级流量网站架构核心技术》
http://microservices.io/patterns/
https://www.nginx.com/blog/microservices-at-netflix-architectural-best-practices/
http://afghl.github.io/2017/07/26/distributed-system-00-index.html
服务治理的技术点,例如:限流、降级、熔断、隔离、路由 & 负载均衡、服务注册 & 发现
http://afghl.github.io/2017/07/30/distributed-system-02-load-balance.html
服务路由 & 负载均衡


 https://mp.weixin.qq.com/s/zIUny7SmxXIkyGufkWt9HQ
https://mp.weixin.qq.com/s/zIUny7SmxXIkyGufkWt9HQ
https://cloud.tencent.com/developer/article/1012458









http://muratbuffalo.blogspot.com/2011/01/lessons-from-giant-scale-services.html
In the web services model, clients make read queries to the servers and servers return data to reply those queries. The DQ principle is simple:
data_per_query * queries_per_second == constant
https://loonytek.com/2017/03/15/notes-on-distributed-systems-part-1/
Such consistency semantics are preferred to increase availability and lower the operation latency. Relaxed consistency semantics do not require the update operation to be visible/applied on each replicas of the data object. The system takes care of converging or syncing all the replicas in background (asynchronously) to a single consistent copy. Special algorithms have to be implemented to do this. The fact that this doesn’t happen on the critical path (client request) is the fundamental reason for improved availability and performance of the system since the request can complete even when some nodes are down (high availability) and the update operation can be potentially completed by executing on fewer replicas (low latency).
- N – Replication Factor
- W – Minimum number of replica nodes that should acknowledge a write request for the system to declare the operation as successful.
- R – Minimum number of replica nodes that should acknowledge a read request for the system to declare the operation as successful.
Generally speaking, if the system has configuration R + W > N, we get strong consistency since the replica sets participating in read and write operations will always overlap (QUORUM). Thus a “successful” read request is guaranteed to return the result of most recent write since the request will always touch at least one replica that has the most recent copy of object.
http://www.infoq.com/cn/articles/features-and-design-concept-of-distributed-system
1. 分布式系统对服务器硬件要求很低
2. 分布式系统强调横向可扩展性
3. 分布式系统不允许单点失效(No Single Point Failure)
4. 分布式系统尽可能减少节点间通讯开销
5. 分布式系统应用服务最好做成无状态的
https://fanchao01.github.io/blog/2018/01/15/fault-tolerant/容错
A fault-tolerant design enables a system to continue its intended operation, possibly at a reduced level, rather than failing completely, when some part of the system fails. If its operating quality decreases at all, the decrease is proportional to the severity of the failure, as compared to a naively designed system in which even a small failure can cause total breakdown.
- 容错指系统遭遇故障时不是完全崩溃;
- 容错系统的服务能力能够根据不同程度的故障保证不同程度的服务,优雅降级。
重试
重试是错误处理中最常使用的技术,通过重试能够大幅度提高SLA,提高系统的可用性。按照系统的状态,重试的难易程度不同。对于无状态服务,例如大多数HTTP请求,简单重新发起调用即可;但是对于有状态服务,不仅需要被请求方具有幂等性,而是要求整个系统具有幂等性。因为极有可能上次失败的调用,使整个下游的状态都发生了改变。因此,对于不同错误应采用不同的重试策略,一些错误不能重试。
另外,重试有副作用,可能引起大量的重复操作和吞吐。例如,一个页面展示显示不出来,用户会大量频繁点击,反而造成系统瞬时压力过大,给本来处于不正常的系统带来更加重的问题。按照具体策略不同,重试可能需要限制次数,或者根据成功率决定是否重试等。
重试的另外一个副作用是增大了延时,重试时间一般采用退化算法,失败次数越多,下次重试的等待时间越长,那么最大延时取决于最后一次重试成功时的总重试时间,这个时间一定要(远)小于整个系统的延时要求。
另外,重试有副作用,可能引起大量的重复操作和吞吐。例如,一个页面展示显示不出来,用户会大量频繁点击,反而造成系统瞬时压力过大,给本来处于不正常的系统带来更加重的问题。按照具体策略不同,重试可能需要限制次数,或者根据成功率决定是否重试等。
重试的另外一个副作用是增大了延时,重试时间一般采用退化算法,失败次数越多,下次重试的等待时间越长,那么最大延时取决于最后一次重试成功时的总重试时间,这个时间一定要(远)小于整个系统的延时要求。
超时
对各种请求,特别是跨模块/服务的请求一定要添加超时,无论是同步还是异步请求。超时除了能够保证延时,更大的作用在于能够快速发现问题,从而积极采取应对策略。假设一个系统出现内部问题,请求被开在某个状态无法返回,那么这个问题就很难处理,一方面监控发现需要一定时间,另一方面即使发现也很难处理,因为卡的状态可能是复杂且未知的。
限流
限流是拒绝一部分请求而保障另一部分请求,简单来说就是削峰填谷。根据具体应用一般有两种方式,一种是缓存请求排队,需要考虑最后排队的请求也要在一定延时内返回。另外一种方式直接限制QPS,在请求过高时直接拒接掉,具体算法也有两种,令牌桶和漏桶算法。在实际使用时可以两种方式结合使用,在保证延时的情况下将请求排队,将不能保证延时的那部分请求直接拒绝。
这里的HA特指一些集群的方案和算法,保证单个服务或者单台机器出现问题而整个系统正常提供服务。简单来说就是避免单点问题。这个比较有名的总结即为下图。
通过改图可以总结出,就是简单的方案性能高,但是可用性较低;而复杂的方案,影响吞吐和延时。
从系统内部和外部可以将集群HA方案分为两个维度:
- 集群本身支持HA,通过各种一致性算法保证强一致或者最终一致
- 集群外部,例如通过使用prox、LB等各种代理,但这要求服务最好无状态
服务分离
将重要服务/客户分离是减小问题的影响范围的最简易手段。现在比较流行微服务架构,不同的服务通过松耦合的方式连接,不同服务往往部署在不同的docker、虚拟机或者物理机上。根据服务的重要性不同,可以分离的程度不同。一些及其重要的服务,甚至单独部署在隔离的物理机上。
服务冗余
这里的服务冗余与HA不同,更加偏向于上图中的Backups。平时不提供服务,专门存在一个备份系统在主系统出现问题时进行快速切换。这里有两个问题,一个是数据的一致性问题,可以时时同步或者冷备份,但是一般都有一定时间内的数据丢失问题。而且在实际使用过程中,备份的系统往往有时候并不处在可用状态。主系统可能定时升级,而备份系统没有;同步到备份系统的数据可能某次有丢失不全等等。亚马逊也出现过类似问题,出现故障时恢复耗时过长,而主要原因就是备份系统起不来数据也不全。备份冗余的另外一个问题是快速切换,如果切换太慢那么可能还不如修复主系统。鉴于实际的种种问题,一般出现故障不太会倾向于切换到备系统,坑比较深。
服务降级
当出现故障后,能够按照故障的严重程度不同,提供不同质量的服务。服务降级是容灾的核心,但是往往很难做到,这不仅需要好的架构设计,也需要好的编程实现。比较容易理解的例子是页面渲染,例如在页面不能加载一些宣传语广告时直接跳过,保证主要功能可用。另外通过将系统做到跨机器、跨机柜、跨TOR、跨机房、跨地域的容灾设计,可以保证不同程度的服务可用性。
cascading failure
《分布式服务框架原理与实践》
《亿级流量网站架构核心技术》
http://microservices.io/patterns/
https://www.nginx.com/blog/microservices-at-netflix-architectural-best-practices/
服务治理的技术点,例如:限流、降级、熔断、隔离、路由 & 负载均衡、服务注册 & 发现
服务化的过程上文已经说了,通常是一个大项目,分拆成若干个小项目。在初级阶段,这些小项目的相互调用可以通过URL来进行HTTP + JSON的RPC调用。
但当服务越来越多时,服务间的依赖错综复杂,这种调用方式会非常混乱。特别是,一个服务模块可以由多个实例提供服务,如果用nginx做为反向代理,会出现单点问题。
这时,需要引入服务调用框架,来封装这些复杂的RPC调用,包括服务治理的功能。以下的技术点,都是对这个服务框架的需求。
我们可以把分布式中的一次跨服务的调用,还原成一个使用TCP/IP协议的网络请求。而TCP/IP协议需要指定正确的IP + port。也就是说,要发起调用,调用方本身必须知道服务提供方的IP + 端口地址。
这种需求在大规模的分布式系统里会变得非常复杂:
一是由于服务间依赖错综复杂,这些信息该如何有效率的存储;
二是无论是服务提供方还是服务调用方都是以集群的形式、甚至是多个 集群 的性质出现,而IP + 端口是 节点 层面的路由信息;
三是在运行时,所有集群都有可能动态伸缩,当要在一个集群里踢掉一台机,或者新增一台机(也就是节点)时,该怎样使流量流进 / 流出这个节点?
服务路由 & 负载均衡,讨论的就是如何解决这些问题的。
服务注册 & 发现
服务路由和负载均衡的前置条件是:有服务可路由。系统中必然需要有地方保存这些IP和端口。还有各种问题:
- 一个分布式系统里是怎样获得各个集群里的节点的信息的?
- 这些节点的健康状况怎么维护和更新。
- 怎么零配置的上线一个服务而被其他服务发现?
零配置或低配置得让一个上线的节点被集群发现,就是服务发现。
限流的核心思路是,当整个系统的并发数超过阈值,宁愿放弃掉一部分请求,也要保住集群。使正常范围内(阈值以下)的流量得到正确处理。这个思路会在下面多次用到。
降级 & 熔断
在应用系统中,我们通常会去调用远程的服务或者资源(这些服务或资源通常是来自第三方),对这些远程服务或者资源的调用通常会导致失败,
或者挂起没有响应,直到超时的产生。在一些极端情况下,大量的请求会阻塞在对这些异常的远程服务的调用上,会导致一些关键性的系统资源耗尽,
从而导致级联的失败,从而拖垮整个系统。熔断器模式在内部采用状态机的形式,使得对这些可能会导致请求失败的远程服务进行了包装,
当远程服务发生异常时,可以立即对进来的请求返回错误响应,并告知系统管理员,将错误控制在局部范围内,从而提高系统的稳定性和可靠性。
服务路由 & 负载均衡
在传统的(小规模的)架构里,因为依赖简单,机器较少,可以将这种IP + port写在配置文件里,或者通过配dns的方式写在代码里。
常见方案
集中式load balance
第一种是集中式LB方案,如下图。首先,服务的消费方和提供方不直接耦合,而是在服务消费者和服务提供者之间有一个独立的LB(LB通常是专门的硬件设备如F5,或者基于软件如LVS,HAproxy等实现)。
LB上有所有服务的地址映射表,通常由运维配置注册,当服务消费方调用某个目标服务时,它向LB发起请求,由LB以某种策略(比如Round-Robin)做负载均衡后将请求转发到目标服务。
LB一般具备健康检查能力,能自动摘除不健康的服务实例。
服务消费方如何发现LB呢?通常的做法是通过DNS,运维人员为服务配置一个DNS域名,这个域名指向LB。
这种方案基本可以否决,因为它有致命的缺点:所有服务调用流量都经过load balance服务器,所以load balance服务器成了系统的单点,一旦LB发生故障对整个系统的影响是灾难性的。为了解决这个问题,必然需要对这个load balance部件做分布式处理(部署多个实例,冗余,然后解决一致性问题等全家桶解决方案),但这样做会徒增非常多的复杂度。
进程内load balance
第二种方案:进程内load balance。将load balance的功能和算法以sdk的方式实现在客户端进程内。先看架构图:
可看到引入了第三方:服务注册中心。它做两件事:
- 维护服务提供方的节点列表,并检测这些节点的健康度。检测的方式是:每个节点部署成功,都通知服务注册中心;然后一直和注册中心保持心跳。
- 允许服务调用方注册感兴趣的事件,把服务提供方的变化情况推送到服务调用方。
这种方案下,整个load balance的过程是这样的:
- 服务注册中心维护所有节点的情况。
- 任何一个节点想要订阅其他服务提供方的节点列表,向服务注册中心注册。
- 服务注册中心将服务提供方的列表(以长连接的方式)推送到消费方。
- 消费方接收到消息后,在本地维护一份这个列表,并自己做load balance。
可见,服务注册中心充当什么角色?它是唯一一个知道整个集群内部所有的节点情况的中心。所以对它的可用性要求会非常高,这个组件可以用Zookeeper实现。
这种方案的缺点是:每个语言都要研究一套sdk,如果公司内的服务使用的语言五花八门的话,这方案的成本会很高。第二点是:后续如果要对客户库进行升级,势必要求服务调用方修改代码并重新发布,所以该方案的升级推广有不小的阻力。
独立进程load balance
该方案是针对第二种方案的不足而提出的一种折中方案,原理和第二种方案基本类似,不同之处是,他将LB和服务发现功能从进程内移出来,变成主机上的一个独立进程,主机上的一个或者多个服务要访问目标服务时,他们都通过同一主机上的独立LB进程做服务发现和负载均衡。如图:
这个方案解决了上一种方案的问题,不需要为不同语言开发客户库,LB的升级不需要服务调用方改代码。
但新引入的问题是:这个组件本身的可用性谁来维护?还要再写一个watchdog去监控这个组件?另外,多了一个环节,就多了一个出错的可能,线上出问题了,也多了一个需要排查的环节。
路由算法有多种多样,但实际场景中不一定需要那么高深的算法。用简单的轮询就很好。在这里就不展开了。
一致性哈希算法在之前的文章中也讨论过,但在服务之间的调用一般不会用到一致性哈希作为路由算法。
为什么?因为服务本身是无状态的(状态都在mysql, redis),既然如此,流量打到哪一台机上也就无所谓了。
服务路由一般是这么做的:有一个服务注册中心,它知道网络内所有节点的情况,暴露restful接口(甚至是长连接)给各个消费方消费。
路由的前置条件是服务注册中心知道所有节点的情况。那么服务注册中心怎么维护所有节点情况的?这篇文章就来讨论一下这个问题。
常见方案
内网DNS
DNS可以理解成是一个域名和IP的hash,客户端写上服务提供方的host name,这个host name指向哪一个IP,在DNS服务器里配置。听上去很简单粗暴。
实际上,DNS的确是小规模系统的杀器。小系统里服务少,服务间的依赖关系不复杂而且节点变化较少,DNS能很好的满足要求。
但是当系统规模变大时,DNS有两个缺点:
- DNS需要人肉配置。就算做个脚本完成自动化配置,也需要不低的开发成本。
- 配置到生效之间,延迟较大。
在服务的动态性很强的微服务环境,DNS就不适合了。
自注册
这个方案也很简单:服务注册中心开放接口给服务提交自己的信息(IP、port等)。在每个实例启动时,调用这个接口上传自己的信息,然后服务注册中心保存。
那实例怎么知道在何时,向谁,调用哪个API接口呢?答:SDK。没错,需要SDK,又会引入开发成本和升级成本的问题了。
第三方注册
避免服务自注册的一个方法是:加入一个新服务注册进程,由它检测服务的启动和健康状况,并上报服务中心。
心跳的保持
心跳的实现本来很简单:约定个端口和返回内容即可,但有这么一个问题:
- 有三个角色:服务调用方,服务提供方,服务注册中心,心跳应该由哪两者保持?
健康的语义
还是心跳的问题。一般的心跳只是一个简单的echo。这样的话,检测的实际上是网络连接状况。但有一些情况下,明明心跳是正常的,但是请求却不能正确处理。
为什么?比如说:一个服务重度依赖redis,某一个和redis连接挂了,但是这时,因为它和其他调用方的连接没挂,任何调用方和它的心跳都返回正常。
为了应对这种特殊的情况,就需要让业务团队定义健康的语义:框架开放心跳接口,让业务团队重写,让业务团队定义每个服务的健康。
graceful shutdown
服务的优雅退出问题。服务在下线的时候分两步:
- 调用注册中心的unregistry接口,通知服务注册中心。
- 注册中心将这个服务踢掉,并把这个变更推给相关的调用方。
考虑一个问题,这两步之间存在一定的延迟,即使是几十毫秒,也可能有上百个请求。如何保证这些请求不丢?
一个暴力而最简单的做法是,在调用unregistry接口之后,等两秒,再退出JVM。
另一个方法是引入生命周期,并把管理一个服务的生命周期的责任交给注册中心。
熔断模式(circuit breaker)可以参考电路熔断,如果一条线路电压过高,保险丝会熔断,防止火灾。放到我们的系统中,如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
熔断pattern详细可见参考列表的连接,这里我只说我想到的一些要考虑的情况。
熔断发生在哪
熔断的核心思路是,当服务集群表现不正常的时候,快速失败,保护正常流量,和集群的系统资源。所以这时,应该阻止请求方直接调用那些很可能会调用失败的远程服务或共享资源。这点逻辑发生在调用方。
也就是说,触发熔断后,直接在调用方进程内快速失败。
熔断是怎样触发的
怎样触发熔断?我们在实现的时候,希望做到这样的效果:server不知道自己是否触发熔断,应不应该触发熔断,它尽最大努力处理流量。这个判断由消费方完成。
所以,熔断的的计数,阈值,熔断时间,重试间隔都配置在消费方,让消费方做逻辑判断。
一个简单的判断方法是:没有得到正确处理的请求占比。比如阈值设为60,那么,调用方会对每个请求计数,如果超过60%的请求,调用方都抛出非业务异常,就触发熔断。
熔断的粒度
(消费方的)进程粒度,接口粒度。粒度越小越好,熔断在进程粒度是为了实现简单(可利用juc中的并发工具类,无需用分布式redis)。
另一个考虑是:相同的熔断器有可能被大量并发请求同时访问。熔断器的实现不应该阻塞并发的请求或者增加每次请求调用的负担。降低熔断粒度,也是降低熔断器粒度。
降级
降级好像没什么好说的,也是在zk里配置,从配置中心推到服务提供方生效。注意提供fallback。
初为架构师,使用“三个分离”架构设计原则,可以在对原有系统改造尽可能小的情况下,快速提升系统性能,是架构师在接手一个新系统时,最喜欢用的三板斧。
一、动静分离
功效:极大提升站点访问速度
二、读写分离
功效:快速线性提升系统的读性能
画外音:读写分离架构能够快速实施,微服务缓存架构对系统改造相对较大,创业初期非常适合使用读写分离。
三、前后台分离
功效:快速解除用户侧与后台侧系统耦合
一、静态页面
静态页面,是指互联网架构中,几乎不变的页面(或者变化频率很低),例如:
首页等html页面
js/css等样式文件
jpg/apk等资源文件
静态页面,有与之匹配的技术架构来加速,例如:
CDN
nginx
三、互联网动静分离架构
动静分离是指,静态页面与动态页面分开不同系统访问的架构设计方法。
一般来说:
静态页面访问路径短,访问速度快,几毫秒
动态页面访问路径长,访问速度相对较慢(数据库的访问,网络传输,业务逻辑计算),几十毫秒甚至几百毫秒,对架构扩展性的要求更高
静态页面与动态页面以不同域名区分
四、页面静态化
既然静态页面访问快,动态页面生成慢,有没有可能,将原本需要动态生成的站点提前生成好,使用静态页面加速技术来访问呢?
这就是互联网架构中的“页面静态化”优化技术。
举例,如下图,58同城的帖子详情页,原本是需要动态生成的:
浏览器发起http请求,访问/detail/12348888x.shtml详情页
web-server层从RESTful接口中,解析出帖子id是12348888
service层通过DAO层拼装SQL语句,访问数据库
最终获取数据,拼装html返回浏览器
而“页面静态化”是指,将帖子ID为12348888的帖子12348888x.shtml提前生成好,由静态页面相关加速技术来加速:
这样的话,将极大提升访问速度,减少访问时间,提高用户体验。
五、页面静态化的适用场景
页面静态化优化后速度会加快,那能不能所有的场景都使用这个优化呢?哪些业务场景适合使用这个架构优化方案呢?
一切脱离业务的架构设计都是耍流氓,页面静态化,适用于:总数据量不大,生成静态页面数量不多的业务。例如:
58速运的城市页只有几百个,就可以用这个优化,只需提前生成几百个城市的“静态化页面”即可
一些二手车业务,只有几万量二手车库存,也可以提前生成这几万量二手车的静态页面
像58同城这样的信息模式业务,有几十亿的帖子量,就不太适合于静态化(碎片文件多,反而访问慢)
“页面静态化”是一种将原本需要动态生成的站点提前生成静态站点的优化技术。
总数据量不大,生成静态页面数量不多的业务,非常适合于“页面静态化”优化。
RD:单库数据量太大,数据库扛不住了,我要申请一个数据库从库,读写分离。
DBA:数据量多少?
RD:5000w左右。
DBA:读写吞吐量呢?
RD:读QPS约200,写QPS约30左右。
上周在公司听到两个技术同学讨论,感觉对读写分离解决什么问题没有弄清楚,有些奔溃。
一、读写分离
什么是数据库读写分离?
答:一主多从,读写分离,主动同步,是一种常见的数据库架构,一般来说:
- 主库,提供数据库写服务
- 从库,提供数据库读服务
- 主从之间,通过某种机制同步数据,例如mysql的binlog
一个组从同步集群通常称为一个“分组”。
分组架构究竟解决什么问题?
答:大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈,如果希望:
- 线性提升数据库读性能
- 通过消除读写锁冲突提升数据库写性能
此时可以使用分组架构。
一句话,分组主要解决“数据库读性能瓶颈”问题,在数据库扛不住读的时候,通常读写分离,通过增加从库线性提升系统读性能。
三、为什么不喜欢读写分离
对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,如果数据库读写分离:
- 数据库连接池需要区分:读连接池,写连接池
- 如果要保证读高可用,读连接池要实现故障自动转移
- 有潜在的主库从库一致性问题
- 如果面临的是“读性能瓶颈”问题,增加缓存可能来得更直接,更容易一点
- 关于成本,从库的成本比缓存高不少
- 对于云上的架构,以阿里云为例,主库提供高可用服务,从库不提供高可用服务
所以,上述业务场景下,楼主建议使用缓存架构来加强系统读性能,替代数据库主从分离架构。
当然,使用缓存架构的潜在问题:如果缓存挂了,流量全部压到数据库上,数据库会雪崩。不过幸好,云上的缓存一般都提供高可用的服务。
四、总结
- 读写分离,解决“数据库读性能瓶颈”问题
- 水平切分,解决“数据库数据量大”问题
- 对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,微服务缓存架构,可能比数据库读写分离架构更合适
前后分离:前台与后台的数据与访问分离
虚拟一个类似于“安居客”租房买房的业务场景,这个业务的数据有两大来源:
- 用户发布的数据
- 爬虫从竞对抓取来的数据
这个业务对应的系统有两类使用者:
- 普通用户,浏览与发布数据,俗称“前台用户”
- 后台用户,运营与管理数据,俗称“后台用户”
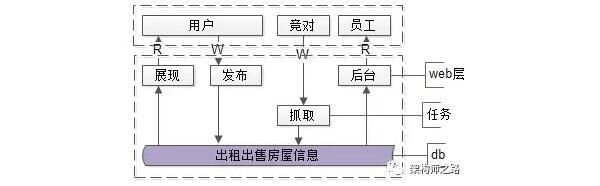
在一个创业公司,为了快速迭代,系统架构如上:
- web层:前台web,后台web
- 任务层:抓取数据
- 数据层:存储数据
二、数据耦合的问题
系统两类数据源,一类是用户发布的数据,一类是爬虫抓取的数据,两类数据的特点不一样:
- 自有数据相对结构化,变化少
- 抓取数据源很多,数据结构变化快
如果将自有数据和抓取数据耦合在一个库里,经常出现的情况是:
- -> 抓取数据结构变化
- -> 需要修改数据结构
- -> 影响前台用户展现
- -> 经常被动修改前台用户展现逻辑,配合抓取升级
如果经历过这个过程,其中的痛不欲生,是谁都不愿意再次回忆起的。
优化思路:前台展现数据,后台抓取数据分离,解耦。
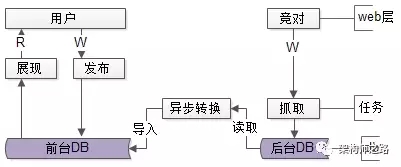
如上图所示:
- 前台展现的稳定数据,库独立
- 后台抓取的多变数据,库独立
- 任务层新增一个异步转换的任务
如此这般:
- 频繁变化的抓取程序,以及抓取的异构数据存储,解耦
- 前台数据与web都不需要被动配合升级
- 即使出现问题,前台用户的发布与展现都不影响
三、系统耦合的问题
上面解决了不同数据源写入的耦合问题,再来看看前台与后台用户访问的耦合问题。
用户侧,前台访问的特点是:
- 访问模式有限
- 访问量较大,DAU不达到百万都不好意思说是互联网C端产品
- 对访问时延敏感,用户如果访问慢,立马就流失了
- 对服务可用性要求高,系统经常用不了,用户还会再来么
- 对数据一致性的要求高,关乎用户体验的事情就是大事
运营侧,后台访问的特点是:
- 访问模式多种多样,运营销售各种奇形怪状的,大批量分页的,查询需求
- 用户量小,访问量小
- 访问延时不这么敏感,大批量分页,几十秒能出结果,也能接受
- 对可用性能容忍,系统挂了,10分钟之内重启能回复,也能接受
- 对一致性的要求始终,晚个30秒的数据,也能接受
前台和后台的模式与访问需求都不一样,但是,如果前台与后台混用同一套服务和结构化数据,会导致:
- 后台的低性能访问,对前台用户产生巨大的影响,本质还是耦合
- 随着数据量变大,为了保证前台用户的时延,质量,做一些类似与分库分表的升级,数据库一旦变化,可能很多后台的需求难以满足
优化思路:冗余数据,前台与后台服务与数据分离,解耦。
如上图所示:
- 前台和后台独立服务与数据,解耦
- 如果出现问题,相互不影响
- 通过不同的技术方案,在不同容忍度,业务对系统要求不同的情况下,可以使用不同的技术栈来满足各自的需求,如上图,后台使用ES或者hive在进行数据存储,用以满足“售各种奇形怪状的,大批量分页的,查询需求”
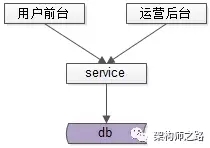
通用业务服务化之后,系统的典型后端结构如下:
- web-server通过RPC接口,从通用业务服务获取数据
- biz-service通过RPC接口,从多个基础数据service获取数据
- 基础数据service通过DAO,从独立db/cache获取数据
- db/cache存储数据

此时,为了缓解这些问题,一般会成立单独的前端FE部门,来负责交互与展现的研发,其职责与后端Java工程师分离开,但痛点依然没有完全解决:
- 一点点展现的改动,需要Java工程师们重新编译,打包,上线,重启tomcat,效率极低
- 原先Java工程师负责所有MVC的研发工作,现在分为Java和FE两块,需要等前端和后端都完成研发,才能一起调试整体效果,不仅增加了沟通成本,任何一块出问题,都可能导致项目延期
前后端分离的分层抽象势在必行。
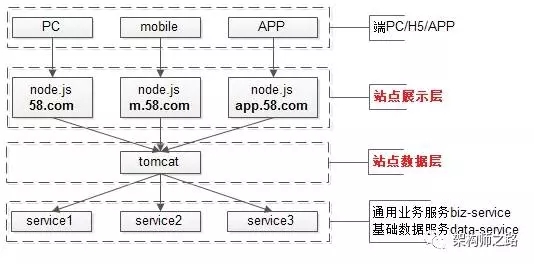
通过前后端分离分层抽象:
- 站点展示层,node.js,负责数据的展现与交互,由FE维护
- 站点数据层,web-server,负责业务逻辑与json数据接口的提供,由Java工程师维护
这样的好处是:
- 复杂的业务逻辑与数据生成,只有在站点数据层处写了一次,没有代码拷贝
- 底层service接口发生变化,只有站点数据层一处需要升级修改
- 底层service如果有bug,只有站点数据层一处需要升级修改
- 站点展现层可以根据产品的不同形态,传入不同的参数,调用不同的站点数据层接口
当业务越来越复杂,端上的产品越来越多,展现层的变化越来越快越来越多,站点层存在大量代码拷贝,数据获取复杂性成为通用痛点的时候,就应该进行前后端分离分层抽象,简化数据获取过程,提高数据获取效率,向上游屏蔽底层的复杂性。
传统 FE 与后端 Java/PHP 工程师的合作方式, FE 工程师不需要有很深的后端功底,一旦引入前后端分离, node.js 层的前端同学需要了解更多的后端知识体系,不排除有 FE 同学对后端技能的排斥,引发人员的不稳定。
结论:前后端分离不只是一个分层架构的技术决策,和SEO、产品特性、公司发展阶段、人员知识体系相关,千万不可一概而论。