Video service over Http Live Streaming for mobile devices, which…
has limited memory/storage
suffers from the unstable network connection and variable bandwidth, and needs midstream quality adjustments.
Solution
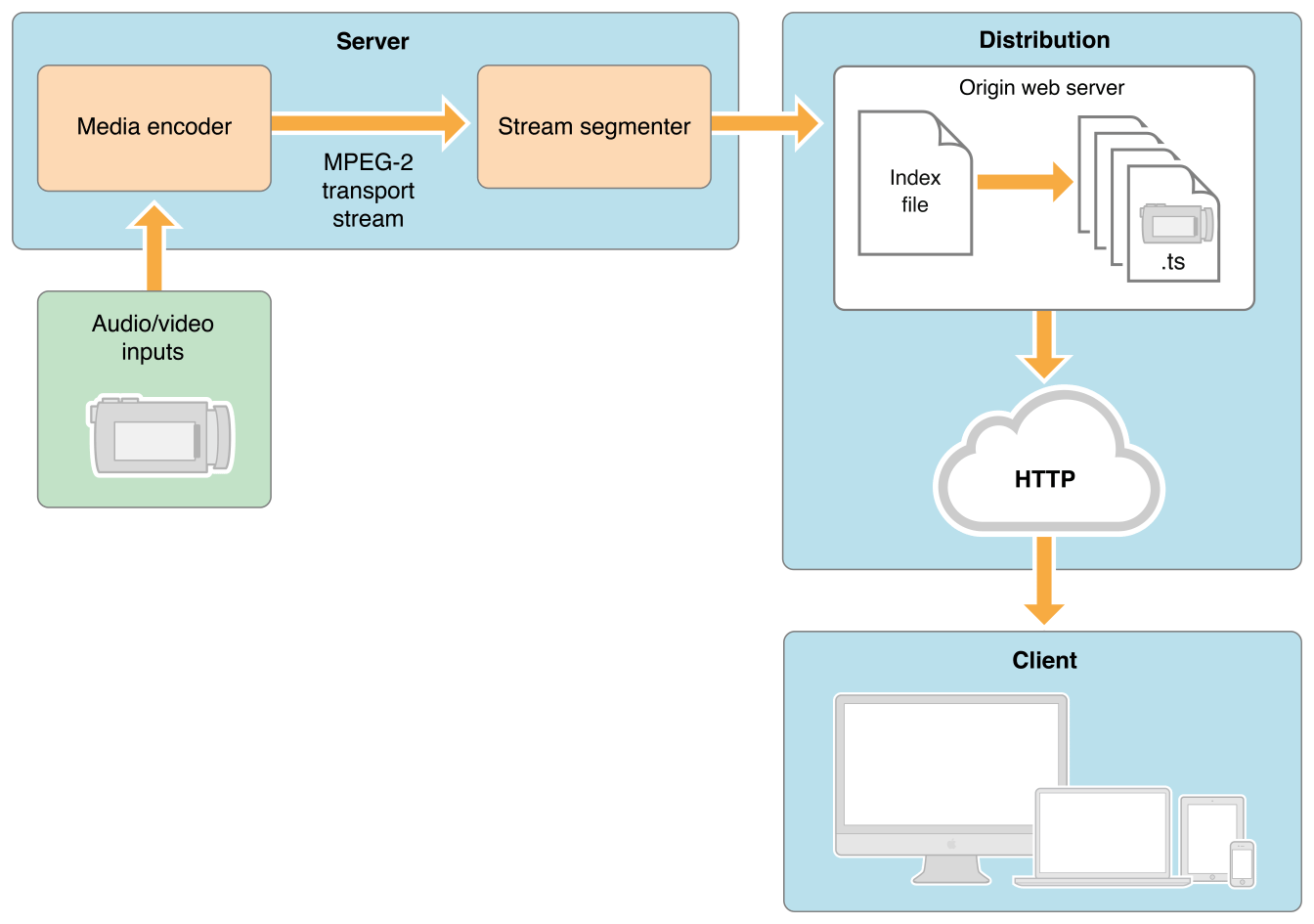
Server-side: In a typical configuration, a hardware encoder takes audio-video input, encodes it as H.264 video and AAC audio, and outputs it in an MPEG-2 Transport Stream
the stream is then broken into a series of short media files (.ts possibly 10s) by a software stream segmenter.
The segmenter also creates and maintains an index(.m3u8) file containing a list of the media files.
Both the media fils and the index files are published on the web server.
Client-side: client reads the index, then requests the listed media files in order and displays them without any pauses or gaps between segments.
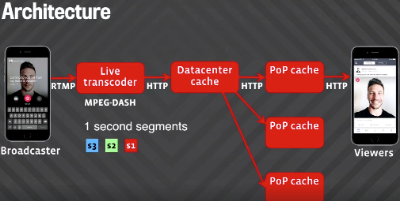
Architecture
https://code.fb.com/ios/under-the-hood-broadcasting-live-video-to-millions/ Public figures on Facebook can have millions of followers all trying to watch a video at once; creating new tricks for load balancing became our goal. To begin rolling out live video for more people, we’re taking the latency in live broadcasts down to few seconds by enabling RTMP playback. We’re hoping that these low-latency broadcasts will make the experience more engaging for broadcasters and viewers alike. No high-scale system likes traffic spikes, especially this many requests coming in at once. When it happens, we call it a “thundering herd” problem — too many requests can stampede the system, causing lag, dropout, and disconnection from the stream.
The best way to stop the stampede is to never let it through the gates, so to speak. Instead of having clients connecting directly to the live stream server, there’s a network of edge caches distributed around the globe. A live video is split into three-second HLS segments in our implementation. These segments are sequentially requested by the video player displaying the broadcast. The segment request is handled by one of the HTTP proxies in an edge data center that checks to see whether the segment is already in an edge cache. If the segment is in cache, it’s returned directly from there. If not, the proxy issues an HTTP request to the origin cache, which is another cache layer with the same architecture. If the segment is not in origin cache, then it needs to request it to the server handling that particular stream. Then the server returns the HTTP response with the segment, which is cached in each layer, so following clients receive it faster. With this scheme, more than 98 percent of segments are already in an edge cache close to the user, and the origin server receives only a fraction of requests.
The solution works well, except that at our scale there was some leakage — about 1.8 percent of requests were getting past the edge cache. When you’re dealing with a million viewers, that’s still a large number. To make sure there was no failure at the origin level, we applied a technique called request coalescing. People typically watch regular, non-live videos at different times. You can see the traffic spike coming if something is viral, so the minute-to-minute need to balance the load isn’t there. With live video, a large number of people watch the same video at the same time with potentially no notice, which creates a load problem and a cache problem. People request the same video segment at the same time, and it may not be in cache yet. Without a thundering herd prevention plan, the edge cache would return a cache miss for all the client requests, and all of them would go to origin cache, and all the way to the live stream server. This would mean that a single server would receive a huge number of requests. To prevent that, the edge cache returns a cache miss for the first request, and it holds the following requests in a queue. Once the HTTP response comes from the server, the segment is stored in the edge cache, and the requests in the queue are responded from the edge as cache hits. This effectively handles the thundering herd, reducing the load to origin. The origin cache in turn runs the same mechanism to handle requests from multiple edge caches — the same object can be requested from an edge cache in Chicago and an edge cache in Miami.
Bringing latency down
Where building Live for Facebook Mentions was an exercise in making sure the system didn’t get overloaded, building Live for people was an exercise in reducing latency. People who aren’t public figures are more likely to be broadcasting to a small, interactive group. It was important to us that people be able to have near real-time conversations without an awkward data transmission delay. To bring latency down to a two- to three-second transmission, we decided to use RTMP.
RTMP is a streaming protocol that maintains a persistent TCP connection between the player and the server during the whole broadcast. Unlike HLS, RTMP uses a push model. Instead of the player requesting each segment, the server continuously sends video and audio data. The client can still issue pause and resume commands when the person requests it or when the player is not visible. In RTMP, the broadcast is split into two streams: a video stream and an audio stream. The streams are split into chunks of 4 KB, which can be multiplexed in the TCP connection, i.e., video and audio chunks are interleaved. At a video bit rate of 500 Kbps, each chunk is only 64 ms long, which, compared with HLS segments of 3 seconds each, produces smoother streaming across all components. The broadcaster can send data as soon as it has encoded 64 ms of video data; the transcoding server can process that chunk and produce multiple output bit rates. The chunk is then forwarded through proxies until it reaches the player. The push model plus small chunks reduce the lag between broadcaster and viewer by 5x, producing a smooth and interactive experience. Most of the live stream products use HLS because it’s HTTP-based and easy to integrate with all existing CDNs. But because we wanted to implement the best live streaming product, we decided to implement RTMP by modifying nginx-rtmp module, and developed an RTMP proxy. The lessons learned from the HLS path also allowed us to implement an RTMP architecture that effectively scales to millions of broadcasters.
They started with HLS, HTTP Live Streaming. It’s supported by the iPhone and allowed them to use their existing CDN architecture.
Simultaneously began investigating RTMP (Real-Time Messaging Protocol), a TCP based protocol. There’s a stream of video and a stream of audio that is sent from the phone to the Live Stream servers.
Advantage: RTMP has lower end-end latency between the broadcaster and viewers. This really makes a difference an interactive broadcast where people are interacting with each other. Then lowering latency and having a few seconds less delay makes all the difference in the experience.
Disadvantage: requires a whole now architecture because it’s not HTTP based. A new RTMP proxy need to be developed to make it scale.
Also investigating MPEG-DASH (Dynamic Adaptive Streaming over HTTP).
Advantage: compared to HLS it is 15% more space efficient.
Advantage: it allows adaptive bit rates. The encoding quality can be varied based on the network throughput.
Spiky traffic cause problems in the caching system and the load balancing system.
Caching Problems
A lot of people may want to watch a live video at the same time. This is your classic Thundering Herd problem.
The spiky traffic pattern puts pressure on the caching system.
Video is segmented into one second files. Servers that cache these segments may overload when traffic spikes.
Global Load Balancing Problem
Facebook has points of presence (PoPs) distributed around the world. Facebook traffic is globally distributed.
The challenge is preventing a spike from overloading a PoP.
How Does It Scale?
There is one point of multiplication between the datacenter cache and the many PoP caches. Users access PoP caches, not the datacenter, and there are many PoP caches distributed around the world.
Another multiplication factor is within each PoP.
Within the PoP there are two layers: a layer of HTTP proxies and a layer of cache.
Viewers request the segment from a HTTP proxy. The proxy checks if the segment is in cache. If it’s in cache the segment is returned. If it’s not in cache a request for the segment is sent to the datacenter.
Different segments are stored in different caches so that helps with load balancing across different caching hosts.
Protecting The Datacenter From The Thundering Herd
What happens when all the viewers are requesting the same segment at the same time?
If the segment is not in cache one request will be sent to the datacenter for each viewer.
Request Coalescing. The number of requests is reduced by adding request coalescing to the PoP cache. Only the first request is sent to the datacenter. The other requests are held until the first response arrives and the data is sent to all the viewers.
New caching layer is added to the proxy to avoid the Hot Server problem.
All the viewers are sent to one cache host to wait for the segment, which could overload the host.
The proxy adds a caching layer. Only the first request to the proxy actually makes a request to the cache. All the following requests are served directly from the proxy.
PoPs Are Still At Risk - Global Load Balancing To The Rescue
So the datacenter is protected from the Thundering Herd problem, but the PoPs are still at risk. The problem with Live is the spikes are so huge that a PoP could be overloaded before the load measure for a PoP reaches the load balancer.
Each PoP has a limited number of servers and connectivity. How can a spike be prevented from overloading a PoP?
A system called Cartographer maps Internet subnetworks to PoPs. It measure the delay between each subnet and each PoP. This is the latency measurement.
The load for each PoP is measured and each user is sent to the closest PoP that has enough capacity. There are counters in the proxies that measure how much load they are receiving. Those counters are aggregated so we know the load for each PoP.
Now there’s an optimization problem that respects capacity constraints and minimizes latency.
With control systems there’s a delay to measure and a delay to react.
They changed the load measurement window from 1.5 minutes to 3 seconds, but there’s still that 3 second window.
The solution is to predict the load before it actually happens.
A capacity estimator was implemented that extrapolates the previous load and the current load of each PoP to the future load.
How can a predictor predict the load will decrease if the load is currently increasing?
Cubic splines are used for the interpolation function.
The first and second derivative are taken. If the speed is positive the load is increasing. If the acceleration is negative that means the speed is decreasing and it will eventually be zero and start decreasing.
Cubic splines predict more complex traffic patterns than linear interpolation.
Avoiding oscillations. This interpolation function also solves the oscillation problem.
The delay to measure and react means decisions are made on stale data. The interpolation reduces error, predicting more accurately, and reduces oscillations. So the load can be closer to the capacity target
Currently prediction is based on the last three intervals where each interval is 30 seconds. Almost instantaneous load.
Testing
You need to be able to overload a PoP.
A load testing service was built that is globally distributed across the PoPs that simulates live traffic.
Able to simulate 10x production load.
Can simulate a viewer that is requesting one segment at a time.
This system helped reveal and fix problems in the capacity estimator, to tune parameters, and to verify the caching layer solves the Thundering Herd problem.
Upload Reliability
Uploading a video in real-time is challenging.
Take, for an example, an upload that has between 100 and 300 Kbps of available bandwidth.
Audio requires 64 Kbps of throughput.
Standard definition video require 500 Kbps of throughput.
Adaptive encoding on the phone is used to adjust for the throughput deficit of video + audio. The encoding bit-rate of the video is adjusted based on the available network bandwidth.
The decision for the upload bitrate is done in the phone by measuring uploaded bytes on the RTMP connection and it does a weighted average of the last intervals.
Future Direction
Investigating a push mechanism rather than the request-pull mechanism, leveraging HTTP/2 to push to the PoPs before segments have been requested.
An interesting post by Facebook engineering shares information on these challenges and the design approaches they took: Facebook’s system uses Content Delivery Network (CDN) architecture with a two-layer caching of the content, with the edge cache closest to the users and serving 98 percent of the content. This design aims to reduce the load from the backend server processing the incoming live feed from the broadcaster. Another useful optimization for further reducing the load on the backend is request coalescing, whereby when many followers (in the case of celebs it could reach millions!) are asking for some content that’s missing in the cache (cache miss), only one instance request will proceed to the backend to fetch the content on behalf of all to avoid a flood.