http://www.brianstorti.com/an_introduction_to_unix_processes/
Every process is created using the fork system call. We won’t cover system calls in this post, but you can imagine them as a way for a program to send a message to the kernel (in this case, asking for the creation of a new process).
What fork does is create a copy of the calling process. The newly created process is called the child, and the caller is the parent. This child process inherits everything that the parent has in memory, it’s an almost exact copy (pid and ppid are different, for instance).
One thing to be aware of is that if a process is using 200MB of memory, when it forks a child, the newly created process will use more 200MB. This can easily become an accidental “fork bomb”, that will consume all the available resources of the machine.
The second step is the exec. What exec does is replace the current process with a new one. The caller process is gone forever, and the new process takes its place. If you try to run this command in a terminal session:
exec vim
vim will be opened normally, as it was a direct call to it, but as soon as you close it, you will see that the terminal is gone as well. So here’s what happened:
You had a shell process running (bash, zsh or similar). In the moment that you called exec, passing vim and a parameter, it replaced the bash process with a vim process, so when you close vim, there is no shell there anymore.
A process is an instance of a running program;
Processes have some properties related to it (pid, ppid, tty, etc.);
Processes are created in a two step process: exec and fork;
Processes always exit with an exit code;
A process is a zombie if it is already dead but its parent still didn’t read its exit code with wait;
A process is an orphan if it is still alive but its parent isn’t. The initprocess becomes the new parent;
A daemon is a process that runs in the background, and is not attached to a controlling terminal;
Signals are messages sent from one process to another
https://unix.stackexchange.com/questions/136637/why-do-we-need-to-fork-to-create-new-processes
http://www.geeksforgeeks.org/linux-virtualization-using-chroot-jail/
Every process is created using the fork system call. We won’t cover system calls in this post, but you can imagine them as a way for a program to send a message to the kernel (in this case, asking for the creation of a new process).
What fork does is create a copy of the calling process. The newly created process is called the child, and the caller is the parent. This child process inherits everything that the parent has in memory, it’s an almost exact copy (pid and ppid are different, for instance).
One thing to be aware of is that if a process is using 200MB of memory, when it forks a child, the newly created process will use more 200MB. This can easily become an accidental “fork bomb”, that will consume all the available resources of the machine.
The second step is the exec. What exec does is replace the current process with a new one. The caller process is gone forever, and the new process takes its place. If you try to run this command in a terminal session:
exec vim
vim will be opened normally, as it was a direct call to it, but as soon as you close it, you will see that the terminal is gone as well. So here’s what happened:
You had a shell process running (bash, zsh or similar). In the moment that you called exec, passing vim and a parameter, it replaced the bash process with a vim process, so when you close vim, there is no shell there anymore.
If you are running a bash process, when you call, say,
ls, to list your files, what actually is done is exactly this. The bash process calls fork to create an exact copy of itself, then call exec, to replace this copy with the ls process. When the lsprocess exits, you are back to the parent process, that is bashA process is an instance of a running program;
Processes have some properties related to it (pid, ppid, tty, etc.);
Processes are created in a two step process: exec and fork;
Processes always exit with an exit code;
A process is a zombie if it is already dead but its parent still didn’t read its exit code with wait;
A process is an orphan if it is still alive but its parent isn’t. The initprocess becomes the new parent;
A daemon is a process that runs in the background, and is not attached to a controlling terminal;
Signals are messages sent from one process to another
https://unix.stackexchange.com/questions/136637/why-do-we-need-to-fork-to-create-new-processes
The short answer is,
fork is in Unix because it was easy to fit into the existing system at the time, and because a predecessor system at Berkeley had used the concept of forks.
From The Evolution of the Unix Time-sharing System (relevant text has been highlighted):
Process control in its modern form was designed and implemented within a couple of days. It is astonishing how easily it fitted into the existing system; at the same time it is easy to see how some of the slightly unusual features of the design are present precisely because they represented small, easily-coded changes to what existed. A good example is the separation of the fork and exec functions. The most common model for the creation of new processes involves specifying a program for the process to execute; in Unix, a forked process continues to run the same program as its parent until it performs an explicit exec. The separation of the functions is certainly not unique to Unix, and in fact it was present in the Berkeley time-sharing system, which was well-known to Thompson. Still, it seems reasonable to suppose that it exists in Unix mainly because of the ease with which fork could be implemented without changing much else. The system already handled multiple (i.e. two) processes; there was a process table, and the processes were swapped between main memory and the disk. The initial implementation of fork required only1) Expansion of the process table2) Addition of a fork call that copied the current process to the disk swap area, using the already existing swap IO primitives, and made some adjustments to the process table.In fact, the PDP-7's fork call required precisely 27 lines of assembly code. Of course, other changes in the operating system and user programs were required, and some of them were rather interesting and unexpected. But a combined fork-exec would have been considerably more complicated, if only because exec as such did not exist; its function was already performed, using explicit IO, by the shell.
Since that paper, Unix has evolved.
fork followed by exec is no longer the only way to run a program.- vfork was created to be a more efficient fork for the case where the new process intends to do an exec right after the fork. After doing a vfork, the parent and child processes share the same data space, and the parent process is suspended until the child process either execs a program or exits.
- posix_spawn creates a new process and executes a file in a single system call. It takes a bunch of parameters that let you selectively share the caller's open files and copy its signal disposition and other attributes to the new process.
A chroot on Unix operating systems is an operation that changes the apparent root directory for the current running process and its children. The programs that run in this modified environment cannot access the files outside the designated directory tree. This essentially limits their access to a directory tree and thus they get the name “chroot jail”.
The idea is that you create a directory tree where you copy or link in all the system files needed for a process to run. You then use the chroot system call to change the root directory to be at the base of this new tree and start the process running in that chrooted environment. Since it can’t actually reference paths outside the modified root, it can’t maliciously read or write to those locations.
Why is it required and how is it different from the virtual machines?
This is a Operating-system-level virtualization and is often used instead of virtual machines to create multiple isolated instances of the host OS. This is a kernel level virtualization and has practically no overhead as compared to Virtual Machines, which are a application layer virtualization, as a result it provides a very good method for creating multiple isolated instances on the same hardware. A virtual machine (VM) is a software implementation of a machine and they often exploit what is know as the Hardware Virtualization to render a virtual images of a working operating system.
This is a Operating-system-level virtualization and is often used instead of virtual machines to create multiple isolated instances of the host OS. This is a kernel level virtualization and has practically no overhead as compared to Virtual Machines, which are a application layer virtualization, as a result it provides a very good method for creating multiple isolated instances on the same hardware. A virtual machine (VM) is a software implementation of a machine and they often exploit what is know as the Hardware Virtualization to render a virtual images of a working operating system.
What is difference between hard link and soft link in UNIX?
http://java67.blogspot.com/2015/07/what-is-difference-between-hard-link.html
hard link is direct pointer to the inode of the original file. If you compare the original file with the hard link there won't be any differences between them. On other hand, a soft link is a file that have the information to point to another file or inode. That inode points to the data in the disk.
Hard links are much more restrictive than soft links and that's why they are used rarely.
Difference between Soft link and Hard link in UNIX
1) The target of the the hard link must exist, which is not mandatory in case of soft link. A soft link is said broken if target link doesn't exists.
2) Unlike soft link which are mostly created to reference directories e.g. current link pointing to latest release, Hard links are generally not allowed on directories.
3) One more critical difference between soft link and Hard link is that hard links are not allowed to cross partitions or volumes. Therefore, they cannot exist across file systems.
4) A hard link looks, and behaves, like a regular file, so they can be hard to find. On the other hand soft links are quite different than regular files.
5) A hard link is, for all intents and purposes, the same entity as the original file. They have the same file permissions, time stamps, and so on. All attributes are identical.
Difference Between User Level Threads and Kernel Level Threads
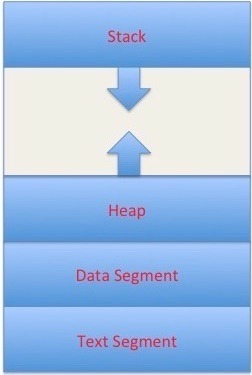
A process is an executing instance of a computer program. We say instance because we may have multiple copies of the same program running simultaneously. How does a process layout look like when loaded into memory for execution ? It is divided into four sections as follows:
- Text section contains compiled code of the program logic.
- Data section stores global and static variables.
- Heap section contains dynamically allocated memory (ex. when you use malloc or new in C or C++).
- Stack section stores local variables and function return values.
Stack and heap sections grow in opposite directions as shown in the figure below.
Thread Management
A thread is a sequence of instructions.
CPU can handle one instruction at a time.
To switch between instructions on parallel threads, execution state need to be saved.
Execution state in its simplest form is a program counter and CPU registers.
Program counter tells us what instruction to execute next.
CPU registers hold execution arguments for example addition operands.
This alternation between threads requires management.
Management includes saving state, restoring state, deciding what thread to pick next and why?
Thread management decides thread type. User level threads are managed by a user level library and kernel level threads are managed by the operating system kernel code.
User Level Threads
user level threads are managed by a user level library however, they still require a kernel system call to operate. It does not mean that the kernel knows anything about thread management. Not at all, It only takes care of the execution part. The lack of cooperation between user level threads and the kernel is a known disadvantage. In this case, the kernel may not favor a process that has many threads. User level threads are typically fast. Creating threads, switching between threads and synchronizing threads only needs a procedure call. They are a good choice for non blocking tasks otherwise the entire process will block if any of the threads blocks.
Kernel Level Threads
Kernel level threads are managed by the OS, therefore, thread operations (ex. Scheduling) are implemented in the kernel code. This means kernel level threads may favor thread heavy processes. Moreover, they can also utilize multiprocessor systems by splitting threads on different processors or cores. They are a good choice for processes that block frequently. If one thread blocks it does not cause the entire process to block. Kernel level threads have disadvantages as well. They are slower than user level threads due to the management overhead. Kernel level context switch involves more steps than just saving some registers. Finally, they are not portable because the implementation is operating system dependent.
UNIX command to find symbolic link or soft link in Linux
http://java67.blogspot.com/2012/10/unix-command-to-find-symbolic-link-or.html
First way is by using ls command in UNIX which display files, directories and links in any directory.
other way is by using UNIX find command which has ability to search any kind of files e.g. file, directory or link.
ls -lrt
lrwxrwxrwx ==> l means link
ls -lrt | grep ^l
find . -type l
find . -maxdepth 1 -type l
Linux下具有基本功能的shell的具体代码实现
1. 支持ls,touch,wc 等外部命令
2. 支持输入输出重定向符
2. 支持输入输出重定向符
3. 支持管道命令
4 .支持后台作业
5. 支持cd,jobs,kill,exit等内部命令(自己还写了一个about 命令 ^ _ ^)
6. 支持对ctrl+c 和ctrl +z 信号的处理