https://labs.consol.de/java-caches/index.html
Peer-to-Peer for Distributed Caches



http://blog.csdn.net/chenleixing/article/details/44629005
Peer-to-Peer for Distributed Caches
From a maintenance point of view, peer-to-peer is the most
simple architecture for distributed caches. Peer-to-peer clusters
are self-organizing, which means that nodes may join and leave the
cluster any time, while the peer-to-peer algorithms take care of
integrating and removing them from the network.
simple architecture for distributed caches. Peer-to-peer clusters
are self-organizing, which means that nodes may join and leave the
cluster any time, while the peer-to-peer algorithms take care of
integrating and removing them from the network.
The different Cache implementations offer two fundamentally different
peer-to-peer architectures:
peer-to-peer architectures:
- full replication
- distributed hash tables
The following sections introduce these architectures.
Full Peer-to-Peer Replication
As the name indicates, full peer-to-peer replication means that each
peer maintains a full copy of the cache. All updates are broadcast
to all other peers.
peer maintains a full copy of the cache. All updates are broadcast
to all other peers.
This is very useful for WORM applications (write-once-read-many),
as it makes resources available for reading without any network
overhead.
as it makes resources available for reading without any network
overhead.
However, fully replicated peer-to-peer clusters do not scale well
with write operations: As each write triggers an update on each other peer,
the scalability is limited by the number of peers and the frequency
of write operations.
with write operations: As each write triggers an update on each other peer,
the scalability is limited by the number of peers and the frequency
of write operations.
Distributed Hash Tables
Distributed hash tables provide an infrastructure where each peer is
responsible for a certain range of keys.
responsible for a certain range of keys.
That means, whenever a key/value pair is read or written, there is one (or
a defined set of) peers holding the values for that key.
a defined set of) peers holding the values for that key.
In order to provide resilience to node failure, there are usually
back-up copies stored on other peers, but there is no full replication
of all data among all peers.
back-up copies stored on other peers, but there is no full replication
of all data among all peers.
Distributed Hash tables provide good scalability for write operations, as
only a limited number of peers need to be updated. Moreover, Distributed
Hash Tables also provide an infrastructure enabling the implementation of
atomicity and consistency guarantees.
only a limited number of peers need to be updated. Moreover, Distributed
Hash Tables also provide an infrastructure enabling the implementation of
atomicity and consistency guarantees.
However, read operations in Distributed Hash Tables result in network overhead,
as the responsible peer needs to be involved with each request. This makes read
operations slower than in fully replicated systems, where read operations
can be served from the local RAM.
Part 3.2: Peer-to-peer with Ehcacheas the responsible peer needs to be involved with each request. This makes read
operations slower than in fully replicated systems, where read operations
can be served from the local RAM.
Ehcache uses its listener architecture to provide a
fully replicated peer-to-peer cluster: Whenever a key/value pair is
written, updated, or deleted, a listener broadcasts the event to
all other instances in the network.
fully replicated peer-to-peer cluster: Whenever a key/value pair is
written, updated, or deleted, a listener broadcasts the event to
all other instances in the network.
As the implementation below shows, Ehcache does not support atomic
operations in peer-to-peer mode. Therefore, the set-up below is only
useful in one of the following scenarios:
operations in peer-to-peer mode. Therefore, the set-up below is only
useful in one of the following scenarios:
- Scenario 1: Each key is only written once, like in a WORM (write-once-read-many) application.
- Scenario 2: Each key is only updated by a single Tomcat instance, like
an HTTP session key when a session-aware load balancer is used.
In scenarios where keys are modified by multiple nodes, Ehcache’s peer-to-peer
cluster will either throw an Exception or become inconsistent. In these cases,
Ehcache should be used in client-server mode,
cluster will either throw an Exception or become inconsistent. In these cases,
Ehcache should be used in client-server mode,
All of ConcurrentMap’s atomic compare-and-swap operations are
not supported in Ehcache’s peer-to-peer configuration!
not supported in Ehcache’s peer-to-peer configuration!
- Cache.replace
- Cache.putIfAbsent
- Cache.remove
Therefore, Ehcace’s peer-to-peer mode cannot be used when multiple peers
modify the same key. However, it can be used if either keys are only written
once, or if each key is only modified by a single instance (for example,
if the key is a HTTP session, and a session aware load balancer is used).
In that case, regular
https://labs.consol.de/java-caches/part-4-2-client-server-with-ehcache/index.htmlmodify the same key. However, it can be used if either keys are only written
once, or if each key is only modified by a single instance (for example,
if the key is a HTTP session, and a session aware load balancer is used).
In that case, regular
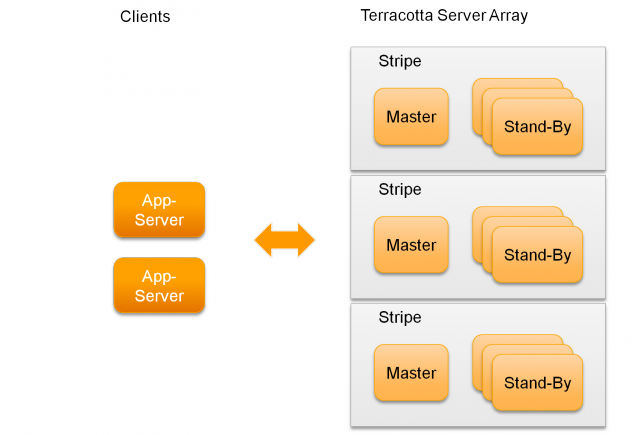
Ehcache’s server side is called the
Terracotta Server Array (TSA).
As Terracotta and Ehcache were originally independent projects, Ehcache’s
client-server implementation differs significantly from the peer-to-peer
implementation shown in part 02.
Terracotta Server Array (TSA).
As Terracotta and Ehcache were originally independent projects, Ehcache’s
client-server implementation differs significantly from the peer-to-peer
implementation shown in part 02.
Similar to a distributed hash table,
the TSA splits the data into stripes, and has one server being responsible
for each stripe. That way, the TSA can be configured to support atomic
operations in a distributed environment.
the TSA splits the data into stripes, and has one server being responsible
for each stripe. That way, the TSA can be configured to support atomic
operations in a distributed environment.
However, unlike Hazelcast’s and Infinispan’s distributed hash tables,
Terracotta’s server infrastructure is static: It is not possible to remove
a stripe at run-time without loosing the data stored on that stripe. Moreover,
it is not possible to dynamically increase the number of stripes
at run-time.
Terracotta’s server infrastructure is static: It is not possible to remove
a stripe at run-time without loosing the data stored on that stripe. Moreover,
it is not possible to dynamically increase the number of stripes
at run-time.
In order to prevent data loss, Terracotta supports dedicated stand-by instances
for each stripe, serving as a hot stand-by when the master fails. If there
is more than one stand-by for a master, an election algorithm is run to
determine which of the stand-by will take over.
for each stripe, serving as a hot stand-by when the master fails. If there
is more than one stand-by for a master, an election algorithm is run to
determine which of the stand-by will take over.
While Terracotta’s static infrastructure seems as a drawback at the first
sight, it gives the user full control of how the hardware infrastructure
is used:
For example, when there are some dedicated hardware units to host the
Cache server, Terracotta allows to configure one stripe on each unit.
In these cases, it might not be desired to have a self-organizing
peer-to-peer cluster shifting data around.
sight, it gives the user full control of how the hardware infrastructure
is used:
For example, when there are some dedicated hardware units to host the
Cache server, Terracotta allows to configure one stripe on each unit.
In these cases, it might not be desired to have a self-organizing
peer-to-peer cluster shifting data around.
Terracotta provides two consistency models:
- eventual consistency
- strong consistency
When eventual consistency is used, but two concurrent clients modify
the same key at the same time, data loss might occur.
the same key at the same time, data loss might occur.
In its free version, Terracotta supports only one stripe, i.e. one
master/standby serving the entire cache. In order to distribute the data among
multiple stripes, Terracotta’s full version needs to be acquired.
master/standby serving the entire cache. In order to distribute the data among
multiple stripes, Terracotta’s full version needs to be acquired.
For the demo application below, the free production version of Terracotta
Big Memory Max is used, which requires a free license from Terracotta
to be run.
http://slamke.blogspot.com/2015/07/j2cache.htmlBig Memory Max is used, which requires a free license from Terracotta
to be run.
为什么只使用独立的Java缓存框架Ehcache不行?
Ehcache这类缓存框架,是一个进程内的缓存框架,如果是集群的话会导致缓存数据不同步。
缓存数据不同步有两个解决办法:
1. 集中式缓存,直接将 Ehcache 换成 Redis 这类产品。如果访问量不大是没问题,访问量大,大量的缓存数据访问使得应用服务器和缓存服务器之间的网络I/O成为瓶颈。
2. Ehcache 的分布式,节点间大量的数据复制带来额外的开销,在节点多的情况下此问题越发严重。
1. 集中式缓存,直接将 Ehcache 换成 Redis 这类产品。如果访问量不大是没问题,访问量大,大量的缓存数据访问使得应用服务器和缓存服务器之间的网络I/O成为瓶颈。
2. Ehcache 的分布式,节点间大量的数据复制带来额外的开销,在节点多的情况下此问题越发严重。
因此,出现了两级缓存框架J2Cache,引入集中式缓存Redis,通过进程内的Ehcache 缓存来缓解网络 I/O 瓶颈。同时也降低集中式缓存服务器的压力。
拓扑结构:

数据流:

缓存同步:

源码阅读:
J2Cache使用JGroups进行组播。https://github.com/belaban/JGroups
使用FST进行对象序列化。https://github.com/RuedigerMoeller/fast-serialization
J2Cache使用JGroups进行组播。https://github.com/belaban/JGroups
使用FST进行对象序列化。https://github.com/RuedigerMoeller/fast-serialization
http://blog.csdn.net/chenleixing/article/details/44629005
这 是 开源中国社区OSChina 目前正在使用的两级缓存框架,托管在OSG@Git上,大部分由设计人红薯来维护。它的第一级缓存使用 Ehcache,第二级缓存使用 Redis 。由于大量的缓存读取会导致 L2 的网络成为整个系统的瓶颈,因此 L1 的目标是降低对 L2 的读取次数。该缓存框架主要用于集群环境中。单机也可使用,用于避免应用重启导致的 Ehcache 缓存数据丢失。
在我看来,不管是ehcache或者redis都是缓存的一个扩展,但是这些东西都被结结实实的依赖在框架的main主干中,Hibernate只是应用缓冲的一种应用场景,但是也赫然在工程结构当中,如果把J2Cache的缓冲实现扩展N种,再把J2Cache的应用推广M种,我们就欣然看到在J2Cache当中信赖了n+m种的依赖包们,我们的使用者应该怎么办呢?要么忍受利用J2Cache时带来的N多用不着的包,要么就要辛苦的去强制不依赖这些包,而这都要拜J2Cache所赐。
这个没有什么问题,不管谁来做,大致也是这个样子的,所以到这里来说,还是非常不错的。
但是实际上也有改进的余地,比如把Cache换成Cache<KeyType>,这样
public Object get(Object key) throws CacheException;public <T> T get(KeyType key) throws CacheException;public Class XxxCache implements Cache<String){
public <T> T get(String key)throws CacheException{
......
}
}
可以看到,上面的工程里面依赖了许许多多的包,这个时候就可能会引入大量的依赖冲突问题。另外,我只想用你这个东东,为什么还把hibernate引入了?
为什么必须用ehcache,虽然ehcache非常不错,但是如果把它变成可选件是可以接受的,变成必选件就要了命了。
同样的,这里面引入的许多内容从道理上都讲不通,比如:
redis.clients:jedis:jar:2.8.0:compile
工程一:Cache接口设计
这个工程啥实现也没有,就是一个Cache的接口,用来规范Cache访问规范,具体怎么写,不同人有不同的写法。
工程二:
各种不同种类的Cache实现,比如:ehcache,jedis,memcache,JCS,等等,如果精力过剩,各种版本的都来一个也可以。当然,实际上这里每一个具体实现都是一个独立的工程了。
工程三:
J2Cache,它也是Cache接口的一个实现类,在它里面注入两个Cache实例,然后在处理逻辑上做两级缓冲的处理。
当然,如果你想要弄个CacheManager也是可以的,这个不是关键因素,随便都可以。
最后就贴一下Tiny自己的二级缓冲实现类:
public class MultiCache implements Cache{
/**
* 1级缓存
*/
Cache cacheFirst;
/**
* 2级缓存
*/
Cache cacheSecond;
public MultiCache() {
}
public MultiCache(Cache cacheFirst, Cache cacheSecond) {
this.cacheFirst = cacheFirst;
this.cacheSecond = cacheSecond;
}
public Object get(String key) {
Object obj = cacheFirst.get(key);
if (obj == null) {
obj = cacheSecond.get(key);
cacheFirst.put(key, obj);
}
return obj;
}
public Object get(String group, String key) {
Object obj = cacheFirst.get(group ,key);
if (obj == null) {
obj = cacheSecond.get(group ,key);
cacheFirst.put(group,key, obj);
}
return obj;
}
public Object[] get(String[] keys) {
List<Object> objs = new ArrayList<Object>();
if (keys != null && keys.length > 0) {
for (int i = 0; i < keys.length; i++) {
objs.add(get(keys[i]));
}
}
return objs.toArray();
}
public Object[] get(String group, String[] keys) {
List<Object> objs = new ArrayList<Object>();
if (keys != null && keys.length > 0) {
for (int i = 0; i < keys.length; i++) {
objs.add(get(group ,keys[i]));
}
}
return objs.toArray();
}
public void put(String key, Object object) {
cacheFirst.put(key ,object);
cacheSecond.put(key ,object);
}
public void putSafe(String key, Object object) {
cacheFirst.putSafe(key ,object);
cacheSecond.putSafe(key ,object);
}
public void put(String groupName, String key, Object object) {
cacheFirst.put(groupName ,key ,object);
cacheSecond.put(groupName ,key ,object);
}
public void remove(String key) {
cacheFirst.remove(key);
cacheSecond.remove(key);
}
public void remove(String group, String key) {
cacheFirst.remove(group ,key);
cacheSecond.remove(group ,key);
}
public void remove(String[] keys) {
cacheFirst.remove(keys);
cacheSecond.remove(keys);
}
public void remove(String group, String[] keys) {
cacheFirst.remove(group ,keys);
cacheSecond.remove(group ,keys);
}
}
同时,由于每种不同的缓冲,基于不同的缓冲框架或版本,也可以有多个实例存在,用户在使用的时候,也可以直接引用具体的缓冲实现就好,当然也可以自己根据接口实现一个就OK了,这样避免了大量不需要的Jar包的引入,对于工程化处理是非常有好处的。
cache-aside
This pattern is the most common approach. In simple words you consult the cache entity first and if it contains the requested data, it is retrieved (from now on we will refer to this behavior as a cache lookup). Otherwise, the application code queries the datasource directly.
cache-as-sor
This pattern is all about using cache as your primary datasource.
write-through
the difference being that the data writing to the system-of-record happens in the same thread.
write-behind
OUT-PROCESS CACHING
IN-PROCESS CACHING
This pattern is the most common approach. In simple words you consult the cache entity first and if it contains the requested data, it is retrieved (from now on we will refer to this behavior as a cache lookup). Otherwise, the application code queries the datasource directly.
cache-as-sor
This pattern is all about using cache as your primary datasource.
write-through
the difference being that the data writing to the system-of-record happens in the same thread.
write-behind
OUT-PROCESS CACHING
IN-PROCESS CACHING