http://www.sitepoint.com/hierarchical-data-database/
http://qinxuye.me/article/storing-hierachical-data-in-database/





http://www.jiuzhang.com/qa/80/?source=weibo
http://qinxuye.me/article/storing-hierachical-data-in-database/
层级结构,也叫树形结构。在实际应用中,你经常需要保存层级结构到数据库中。比如说:你的网站上的目录。不过,除非使用类XML的数据库,通用的关系数据库很难做到这点。
对于树形数据的存储有很多种方案。主要的方法有两种:邻接表模型,以及修改过的前序遍历算法。本文将会讨论这两种方法的实现。这里的例子沿用参考文章中的例子,原文使用的PHP,这里将会用Java替代。(本例使用Mysql数据库,Java如何连接Mysql,见备注一。)文中使用虚拟的在线食品商店作例子。这个食品商店通过类别、颜色以及种类来来组织它的食品。如图所示:
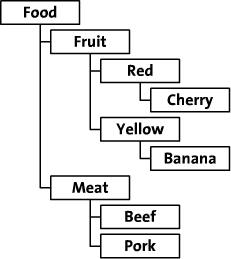
1)首先是邻接表模型。
邻接表相当简单。只需要写一个递归函数来遍历这个树。我们的食品商店的例子用邻接表模型存储时看起来就像是这样:
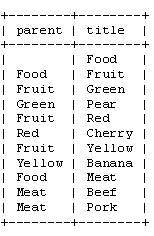
通过邻接表模型存储法中,我们可以看到Pear,它的父节点是Green,而Green的父节点又是Fruit,以此类推。而根节点是没有父节点的。这里为了方便观看,parent字段使用的字符串,实际应用中只要使用每个节点的ID即可。
现在已经在数据库中插入完毕数据,接下来开始先显示这棵树。
打印这棵树:
这里我们只需要写一个简单的递归函数就可以实现。打印某节点时,如果该节点有子节点就打印其子节点。源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
| public static void displayTree(int parentId, int level) throws SQLException { setUp(); ResultSet result = dbc.query( "SELECT ID, title FROM `adjacency_list` WHERE parentid=" + parentId); while(result.next()){ System.out.println(repeatStr(" ", level) + result.getString("title")); displayTree(result.getInt("ID"), level+1); }} |
要打印整棵树,我们只要运行代码:
1
| displayTree(0, 0); |
求节点的路径
有时候我们需要知道某个节点所在的路径。举例来说,“Cherry”所在的路径为Food > Fruit > Red > Cherry。在这里,我们可以从Cherry开始查起,然后递归查询查询节点前的节点,直到某节点的父节点ID为0。源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public static List<String> getPath(int id) throws SQLException{ List<String> paths = new ArrayList<String>(); setUp(); ResultSet result = dbc.query( "SELECT parentid, title FROM `adjacency_list` WHERE ID=" + id); result.next(); int parentid = result.getInt("parentid"); if(parentid != 0){ paths.addAll(getPath(parentid)); } paths.add(result.getString("title")); return paths;} |
我们用以下代码来打印结果:
1
2
3
4
5
6
| List<String> paths = getPath(6);int i = 0;for(String path: paths){ System.out.println("[" + String.valueOf(i) + "] ==> " + path); i++;} |
缺点
我们可以看到,用邻接表模型确实是个不错的方法。它简单易懂,而且实现的代码写起来也很容易。那么,缺点是什么呢?那就是,邻接表模型执行起来效率低下。我们对于每个结果,期望只需要一次查询;可是当使用邻接表模型时嵌套的递归使用了多次查询,当树很大的时候,这种慢就会表现得尤为明显。另外,对于一门程序语言来说,除了Lisp这种,大多数不是为了递归而设计。当一个节点深度为4时,它得同时生成4个函数实例,它们都需要花费时间、占用一定的内存空间。所以,邻接表模型效率的低下可想而知。
就像在程序世界经常遇到的一样。上帝是公平的,当在执行时效率低下,意味着可以增加预处理的程度。那么就让我们来看另外一种存储树形结构的方法。如之前所讲,我们希望能够减少查询的数量,最好是只做到查询一次数据库。
先来讲解一下原理。现在我们把树“横”着放。如下图所示,我们首先从根节点(“Food”)开始,先在它左侧标记“1”,然后我们到“Fruit”,左侧标记“2”,接着按照前序遍历的顺序遍历完树,依次在每个节点的左右侧标记数字。
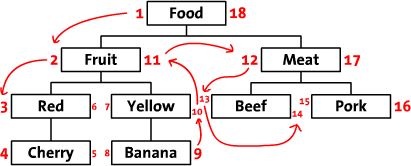
相信你也在图中发现一些规律,没错。比如,“Red”节点左边的数为3、右边的数为6,它是Food(1-18)的后代。同样的,我们可以注意到,左数大于2、右数小于11的节点都是“Fruit”的子孙。现在,所有的节点将以左数-右数的方式存储,这种通过遍历一个树、然后给每一个节点标注左数、右数的方式称为修改过的前序遍历算法。
2)修改过的前序遍历算法
在看完了介绍之后,我们要来讨论具体的实现。在这之前,先来看一下,数据库中表存储这些数的情况。
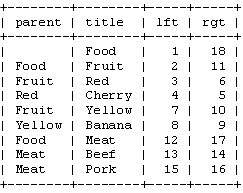
??? How to add new data?
在这种存储方式中,我们实际上是不需要parent这个字段的。
在这种存储方式中,我们实际上是不需要parent这个字段的。
打印树:
如之前的介绍。如果要想打印树,你只需要知道你要检索的节点。比如,想要打印“Fruit”的子树,可以查询左数大于2而小于11的节点。SQL语句就像这样:
1
| SELECT * FROM tree WHERE lft BETWEEN 2 AND 11; |
返回结果如下:
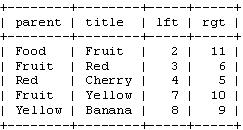
有时候,如果进行过增、删的操作,表中的数据可能就不是正确的顺序。没问题,只要使用“ORDER BY”语句就可以了,就像这样:
1
| SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC; |
现在唯一的问题是缩进问题。
http://www.jiuzhang.com/qa/80/?source=weibo