https://stackoverflow.com/questions/25840713/illegal-option-error-when-using-find-on-macos
https://mp.weixin.qq.com/s/9oPSSlIuHhcKWw-QckGUcg
http://adamish.com/blog/archives/68
wget
https://linux.die.net/man/1/wget
-o logfile
--output-file=logfile
Log all messages to logfile. The messages are normally reported to standard error.
https://stackoverflow.com/questions/15345936/regular-expression-usage-with-ls
https://unix.stackexchange.com/questions/157823/list-ports-a-process-pid-is-listening-on-preferably-using-iproute2-tools
http://www.unixcl.com/2010/01/sed-save-changes-to-same-file.html
Append or redirection to the same filename will be wrong !!
Newer sed versions (e.g sed version 4.1.4), there is a useful command line option:
https://serverfault.com/questions/153875/how-to-let-cp-command-dont-fire-an-error-when-source-file-does-not-exist
http://www.linuxquestions.org/questions/linux-newbie-8/searching-contents-of-class-file-within-jar-for-strings-705087/
if you only want to know first, in which files the string appears, you can use the following sample (works only with GNU find!):
https://stackoverflow.com/questions/39903571/gnu-find-on-mac-os-x
https://apple.stackexchange.com/questions/69223/how-to-replace-mac-os-x-utilities-with-gnu-core-utilities
https://unix.stackexchange.com/questions/37356/how-do-i-transfer-multiple-files-with-a-common-suffix-and-prefix-using-an-offset
lls
mput *.xls
iconv -f UTF-16 -t UTF-8 file
https://www.certdepot.net/rhel7-install-nux-repository/
https://centos.pkgs.org/6/nux-dextop-x86_64/mmv-1.01b-16.el6.nux.x86_64.rpm.html
https://ss64.com/bash/mmv.html
unzip *.zip
The command result into an error which read as follows:
caution: filename not matched
https://www.tecmint.com/find-top-large-directories-and-files-sizes-in-linux/
https://linux.die.net/man/1/pv
pv - monitor the progress of data through a pipe
Open another terminal and type:
In this example you can see progress of both pipes:
https://stackoverflow.com/questions/19598797/is-there-any-way-to-show-progress-on-a-gunzip-database-sql-gz-mysql-pr
https://developer.apple.com/legacy/library/documentation/Darwin/Reference/ManPages/man1/top.1.html
what this
When you need to watch multiple files at the same time,
http://stackoverflow.com/questions/8245903/tail-sampling-logs
http://stackoverflow.com/questions/3968103/how-can-i-format-my-grep-output-to-show-line-numbers-at-the-end-of-the-line-and
http://www.geeksforgeeks.org/daily-life-linux-commands/
Duplicate pipe content: ‘tee’ is a very useful utility that duplicates pipe content. Now, what makes tee really useful is that it can append data to existing files, making it ideal for writing periodic log information to multiple files at once.

export
sudo lsof -i
sudo netstat -lptu
sudo netstat -tulpn
-p, --program
Show the PID and name of the program to which each socket belongs.
-l, --listening
Show only listening sockets. (These are omitted by default.)
-a, --all
Show both listening and non-listening (for TCP this means established connections) sockets. With the --interfaces option, show interfaces that are not marked
https://en.wikipedia.org/wiki/Netcat
du --max-depth=1 -B M |sort -rn
http://stackoverflow.com/questions/10103604/linux-command-line-du-how-to-make-it-show-only-total-for-each-directories
http://www.ducea.com/2006/05/14/tip-how-to-sort-folders-by-size-with-one-command-line-in-linux/
du -h -d 1
https://www.cyberciti.biz/faq/how-do-i-sort-du-h-output-by-size-under-linux/
http://askubuntu.com/questions/10521/how-to-scroll-in-the-terminal-app-top
Press (Shift+P) to sort processes as per CPU utilization. See screenshot below.
https://www.linux.com/learn/uncover-meaning-tops-statistics
What's "total memory" in your opinion? The size of your RAM? Not really. The real meaning is the total size of RAM that is mappable by your running kernel.
http://serverfault.com/questions/138427/top-what-does-virtual-memory-size-mean-linux-ubuntu/138625


Zombie process or defunct process is a process that has completed execution but still has an entry in the process table. This entry is still needed to allow the parent process to read its child’s exit status.

Steal time is the time that a virtual CPU waits for a real CPU while the hypervisor is servicing another virtual processor.
http://unix.stackexchange.com/questions/554/how-to-monitor-cpu-memory-usage-of-a-single-process
https://coolestguidesontheplanet.com/how-to-compress-and-uncompress-files-and-folders-in-os-x-lion-10-7-using-terminal/
http://superuser.com/questions/161706/command-to-gzip-a-folder
http://superuser.com/questions/309034/how-to-check-which-timezone-in-linux
date +%Z
http://www.cyberciti.biz/faq/centos-linux-6-7-changing-timezone-command-line/find-timezone/
http://stackoverflow.com/questions/407612/how-to-get-a-thread-and-heap-dump-of-a-java-process-on-windows-thats-not-runnin
http://unix.stackexchange.com/questions/164653/actual-memory-usage-of-a-process
free -t -m
http://www.thegeekstuff.com/2013/06/cut-command-examples/
1. Select Column of Characters
To extract only a desired column from a file use -c option.
cut -c3- test.txt
$ cut -c-8 test.txt
The entire line would get printed when you don’t specify a number before or after the ‘-‘ as shown below.
$ cut -c- test.txt
4. Select a Specific Field from a File
$ cut -d':' -f1 /etc/passwd
5. Select Multiple Fields from a File
$ grep "/bin/bash" /etc/passwd | cut -d':' -f1,6
$ grep "/bin/bash" /etc/passwd | cut -d':' -f1-4,6,7
6. Select Fields Only When a Line Contains the Delimiter
it is possible to filter and display only the lines that contains the specified delimiter using -s option.
The following example doesn’t display any output, as the cut command didn’t find any lines that has | (pipe) as delimiter in the /etc/passwd file.
$ grep "/bin/bash" /etc/passwd | cut -d'|' -s -f1
7. Select All Fields Except the Specified Fields
$ grep "/bin/bash" /etc/passwd | cut -d':' --complement -s -f7
8. Change Output Delimiter for Display
$ grep "/bin/bash" /etc/passwd | cut -d':' -s -f1,6,7 --output-delimiter='#'
9. Change Output Delimiter to Newline
$ grep bala /etc/passwd | cut -d':' -f1,6,7 --output-delimiter=$'\n'
10. Combine Cut with Other Unix Command Output
$ ps axu | grep python | sed 's/\s\+/ /g' | cut -d' ' -f2,11-
http://www.admin-magazine.com/HPC/Articles/GNU-Parallel-Multicore-at-the-Command-Line-with-GNU-Parallel
time find . -type f -print | parallel echo {}
http://superuser.com/questions/609615/efficient-way-to-search-string-within-file-find-and-grep
http://unix.stackexchange.com/questions/140367/finding-all-large-files-in-the-root-filesystem
创建一个文件,在文件里面输入几个单词,rev命令会将你写的东西反转输出到控制台
# rev <file name>
http://www.admin-magazine.com/Articles/Automating-with-Expect-Scripts
Useful for interview
List All Users In The System
cat /etc/passwd
awk -F':' '{ print $1}' /etc/passwd
User group info: groups user_name
uniq
http://unix.stackexchange.com/questions/114140/uniq-wont-remove-duplicate
The uniq command reads the input file and compares adjacent lines. Any line that is the same as the one before it will be discarded. In other words, duplicates are discarded, leaving only the unique lines in the file.
cat <(seq 5) <(seq 5) | sort | uniq
cat <(seq 5) <(seq 5) | sort -u
http://lowfatlinux.com/linux-uniq.html
sort | uniq existed before sort -u, and is compatible with a wider range of systems, although almost all modern systems do support -u -- it's POSIX. t is also faster internally as a result of being able to do both operations at the same time (and due to the fact that it doesn't require IPC between uniq and sort). Especially if the file is big, sort -u will likely use fewer intermediate files to sort the data.
cat
https://ruixublog.wordpress.com/2015/05/14/leetcode192-word-frequency/
2.从键盘创建一个文件。$ cat > filename
只能创建新文件,不能编辑已有文件.
3.将几个文件合并为一个文件: $cat file1 file2 > file
http://www.eriky.com/2014/10/copy-one-file-to-multiple-locations-with-bash-globbing-wildcards
echo /home/*/etc/php5/php.ini | xargs -n 1 cp php.ini
http://www.eriwen.com/bash/pushd-and-popd/
put paths on a stack (push) and then take them off in reverse order (pop). This is useful when you have more than one directory that you need to switch between frequently.
# change to home directory quickly in bash cd # change to last directory in bash cd -
# print directories on the stack dirs
http://evc-cit.info/cit050/pushd.html
If you never use the
X. Switch between two directories
if you type just
http://stackoverflow.com/questions/18983719/is-there-any-way-to-get-curl-to-decompress-a-response-without-sending-the-accept
Is there any way to get curl to decompress a response without sending the Accept headers in the request?
Shortcuts to Move Faster in Bash Command Line
mv `ls --sort-time -r | tail -n` /home/yasemin/hebelek/
http://segmentfault.com/a/1190000002803307
加在一个命令的最后,可以把这个命令放到后台执行,如
watch -n 10 sh test.sh & #每10s在后台执行一次test.sh脚本
二、ctrl + z
全选复制放进笔记
可以将一个正在前台执行的命令放到后台,并且处于暂停状态。
jobs -l选项可显示所有任务的PID,jobs的状态可以是running, stopped, Terminated。但是如果任务被终止了(kill),shell 从当前的shell环境已知的列表中删除任务的进程标识。
fg: 将后台中的命令调至前台继续运行。如果后台中有多个命令,可以用fg %jobnumber(是命令编号,不是进程号)将选中的命令调出。
bg: 将一个在后台暂停的命令,变成在后台继续执行。如果后台中有多个命令,可以用bg %jobnumber将选中的命令调出。
nohup
如果让程序始终在后台执行,即使关闭当前的终端也执行(之前的&做不到),这时候需要nohup。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。关闭中断后,在另一个终端jobs已经无法看到后台跑得程序了,此时利用ps(进程查看命令)
ps -aux | grep "test.sh" #a:显示所有程序 u:以用户为主的格式来显示 x:显示所有程序,不以终端机来区分
Linux运行与控制后台进程的方法:nohup, setsid, &, disown, screen
1.nohup
顾名思义,nohup的用途就是让提交的命令忽略所有的hangup信号。
使用方法:nohup COMMAND [ARG]...
2.setsid
在一个新的会话中运行命令,从而可以避开当前终端发出的HUP信号。
使用方法:setsid COMMAND [ARG]...
3.&
可以结合()产生一个新的子shell并在这个子shell中将任务放置到后台运行,从而不受当前shell终端的HUP信号影响。
使用方法:(COMMAND [ARG]... &)
而我通常的使用方式为:
nohup ./filename.sh > filename.log 2>&1 &
三点理由:
1)nohup保障进程不会被hangup信号异常中断;
2)将任务放置到后台运行,不占用当前的终端;
3)将错误输出也打印到log中,默认>只有标准输出,错误输出没有。
5.disown
亡羊补牢,为没有使用nohup与setsid的进程加上忽略HUP信号的功能。
使用方法:
将当前正在前台运行的进程放到后台运行(ctrl+z和bg);
然后执行disown -h %{jobid} //这里的{jobid}是通过jobs命令中看到的进程前[]中的数字。
6.通过screen来实现稳定的后台运行
screen是建立一个新的全屏虚拟会话终端,这个会话只有在手动输入exit的时候才会退出,在这个会话里执行的命令不用担心HUP信号会对我们的进程 造成影响,因此也不用给每个命令前都加上“nohup”或“setsid”了,非常适合我们有规划的执行大量的后台任务,可以非常方便的让我们对这些后台任 务进行管理。
使用方法:
screen //立即创建并进入一个会话。
screen -dmS {name} //建立一个处于断开模式下的会话,并根据我们的需要指定其会话名称。
screen -list //列出所有会话。
screen -r {name} //进入指定会话。
ctrl +ad //输入快捷键ctrl +a和d,可暂时退出当前会话。
exit //进入指定会话后执行exit即可关闭该会话。
The first argument to
find is the path where it should start looking. The path . means the current directory.find . -type f -name '*R'
You must provide at least one path, but you can actually provide as many as you want:
find ~/Documents ~/Library -type f -name '*R'http://adamish.com/blog/archives/68
requiretty is an option in /etc/sudoers which prevents sudo operations from non-TTY sesssions.
- # This will be disallowed
- ssh example.com echo "hello world"
- sudo: sorry, you must have a tty to run sudo
- # This will work
- ssh -t example.com echo "hello world"
- hello world
If however you’re using SSH via a wrapper you cannot control, like phpseclib, or ssh2 native support in PHP then you cannot simply pass a -t option.
In this case you need the lesser known command open_init_pty which “runs a program under a psuedo terminal”. This is in debian package policycoreutils if you need to install it.
https://www.shell-tips.com/2014/09/08/sudo-sorry-you-must-have-a-tty-to-run-sudo/sudo: sorry, you must have a tty to run sudo
No panic, there is an easy fix!
It is most-likely that you are running on a Linux distribution with sudo configured to require a tty. This is generally enforced by having
Defaults requiretty in the /etc/sudoers.
To disable requiretty globally or to a single command, you have two options:
- Replace Defaults requiretty by Defaults !requiretty in your /etc/sudoers. This will impact your global sudo configuration.
Alternatively, you can change this configuration at a per user, per group or per command basis
Defaults!/path/to/my/bin !requiretty
Defaults:myuser !requiretty
- Connect by ssh using
-toptions
From man ssh:
text -t Force pseudo-tty allocation. This can be used to execute arbitrary screen-based programs on a remote machine, which can be very useful, e.g. when implementing menu services. Multiple -t options force tty allocation, even if ssh has no local tty.
The
useradd command will try to add a new user. Since your user already exists this is not what you want.
Instead: To modify an existing user, like adding that user to a new group, use the
usermodcommand.
Try this:
sudo usermod -a -G groupName userName
The user will need to logout and log back in to see their new group added.
- The
-a(append) switch is important, otherwise the user will be removed from any groups not in the list. - The
-Gswitch takes a (comma-separated) list of supplementary groups to assign the user to.
https://linux.die.net/man/1/wget
For downloading files from a directory listing, use
-r (recursive), -np (don't follow links to parent directories), and -k to make links in downloaded HTML or CSS point to local files (credit @xaccrocheur).wget -r -np -k http://www.ime.usp.br/~coelho/mac0122-2013/ep2/esqueleto/
Other useful options:
-nd(no directories): download all files to the current directory-e robots.off: ignore robots.txt files, don't download robots.txt files-A png,jpg: accept only files with the extensionspngorjpg-m(mirror):-r --timestamping --level inf --no-remove-listing-nc,--no-clobber: Skip download if files exist
--execute="robots = off": This will ignore robots.txt file while crawling through pages. It is helpful if you're not getting all of the files.--mirror: This option will basically mirror the directory structure for the given URL. It's a shortcut for-N -r -l inf --no-remove-listingwhich means:-N: don't re-retrieve files unless newer than local-r: specify recursive download-l inf: maximum recursion depth (inf or 0 for infinite)--no-remove-listing: don't remove '.listing' files
--convert-links: make links in downloaded HTML or CSS point to local files--no-parent: don't ascend to the parent directory--wait=5: wait 5 seconds between retrievals. So that we don't thrash the server.
- --no-parent: don't follow links outside the directory tutorials/html/.
- --no-clobber: don't overwrite any existing files (used in case the download is interrupted and
resumed).
https://stackoverflow.com/questions/15345936/regular-expression-usage-with-ls
You are confusing regular expression with shell globbing. If you want to use regular expression to match file names you could do:
$ ls | egrep '.+\..+'lsof -Pan -p PID -ihttp://www.unixcl.com/2010/01/sed-save-changes-to-same-file.html
Append or redirection to the same filename will be wrong !!
$ sed 's/VERSION/8.04/' file.txt > file.txt
Newer sed versions (e.g sed version 4.1.4), there is a useful command line option:
-i[SUFFIX], --in-place[=SUFFIX]
Description: edit files in place (makes backup if extension supplied)
$ sed -i 's/VERSION/8.04/' file.txt
$ sed -i.bak 's/VERSION/8.04/' file.txt
https://stackoverflow.com/questions/3224878/what-is-the-purpose-of-the-colon-gnu-bash-builtin
Nowadays (that is: in a modern context) you can usually use either
: or true. Both are specified by POSIX, and some find true easier to read. However there is one interesting difference: : is a so-called POSIX special built-in, whereas true is a regular built-in.- Special built-ins are required to be built into the shell; Regular built-ins are only "typically" built in, but it isn't strictly guaranteed. There usually shouldn't be a regular program named
:with the function oftruein PATH of most systems. - Probably the most crucial difference is that with special built-ins, any variable set by the built-in - even in the environment during simple command evaluation - persists after the command completes, as demonstrated here using ksh93:
$ unset x; ( x=hi :; echo "$x" ) hi $ ( x=hi true; echo "$x" ) $Note that Zsh ignores this requirement, as does GNU Bash except when operating in POSIX compatibility mode, but all other major "POSIX sh derived" shells observe this including dash, ksh93, and mksh. - Another difference is that regular built-ins must be compatible with
exec- demonstrated here using Bash:$ ( exec : ) -bash: exec: :: not found $ ( exec true ) $ - POSIX also explicitly notes that
:may be faster thantrue, though this is of course an implementation-specific detail.
If you're talking about the error message, you can suppress that by sending it to the bit bucket:
cp ./src/*/*.h ./aaa 2>/dev/null
If you want to suppress the exit code and the error message:
cp ./src/*/*.h ./aaa 2>/dev/null || :
The
https://stackoverflow.com/questions/4923834/how-to-ls-only-one-level-deepq switch sets diff brief mode. If we didn’t set brief mode, diff would not only tell you which files are different between the two folders, but also show the actual line-by-line differences for any text files that exist in both locations but are not identical.find . -type d -maxdepth 1 -name "H2*"ls -d H2*/
The
-d option is supposed to list "directories only", but by itself just lists.
which I personally find kind of strange. The wildcard is needed to get an actual list of directories.
UPDATE: As @Philipp points out, you can do this even more concisely and without leaving bash by saying
echo H2*/
huntercao$find . -name *.h
Get error:
find: xxxx.h: unknown primary or operator
Error reason:
* is expanded by the shell before the command-line is passed to find(1). If there's only 1 item in the directory, then it works. If there's more than one item in the directory, then it fails as the command-line options are no longer correct.
You have to escape the * so that find does the expansion internally.
http://www.javaworld.com/article/2074884/core-java/searching-jars-for-string--linux-.htmlhttp://www.linuxquestions.org/questions/linux-newbie-8/searching-contents-of-class-file-within-jar-for-strings-705087/
if you only want to know first, in which files the string appears, you can use the following sample (works only with GNU find!):
find . -iname '*.jar' -printf "unzip -c %p | grep -q 'Tag read' && echo %p\n" | sh
brew install findutils --with-default-names
When I run which on find I get what I expect:
$ which find
/usr/local/bin/find
However, when I use find, the system falls back to OS X default /usr/bin/find, i.e.:
$ find -exec file {} \;
find: illegal option -- e
usage: find [-H | -L | -P] [-EXdsx] [-f path] path ... [expression]
find [-H | -L | -P] [-EXdsx] -f path [path ...] [expression]
$ /usr/local/bin/find -exec file {} \;
.: directory
A simple system restart.
This adds symlinks for GNU utilities with g prefix to
/usr/local/bin/:brew install coreutils findutils gnu-tar gnu-sed gawk gnutls gnu-indent gnu-getopt
See
brew search gnu for other packages. If you want to use the commands without a g prefix, install the formulas with --default-names (or --with-default-names if your brew version is newer), or add for example /usr/local/opt/coreutils/libexec/gnubin before other directories on your PATH.$ brew info coreutils
You can install GNU
grep by tapping homebrew/dupes:brew tap homebrew/dupes; brew install grephttps://unix.stackexchange.com/questions/37356/how-do-i-transfer-multiple-files-with-a-common-suffix-and-prefix-using-an-offset
Your examples and description are inconsistent. Going by the list
sequence_2_0001.hmf, sequence_2_0101.hmf, sequence_2_0201.hmf, …, you can use the ? wildcard to match any one character.get sequence_2_??01.hmf
You can use character sets to match one file every 20 (for example).
[02468] matches any one of the digits 0, 2, 4, 6 or 8.get sequence_2_[02468]?01.hmflls
mput *.xls
Creating new directories on local and remote locations.
Remove directory or file in remote system.
sftp> mget *
You may also be able to use use
scp. The general format isscp -rp sourceDirName username@server:destDirName
scp means "secure copy". The flags are-rrecurse into subdirectories-ppreserve modification times
iconv -f UTF-16 -t UTF-8 file
gpg --decrypt-files *https://www.certdepot.net/rhel7-install-nux-repository/
The Nux repository brings a set of additional packages available at least for RHEL 7 and CentOS 7.
This is the best place to find desktop and multimedia oriented RPMs.
This is the best place to find desktop and multimedia oriented RPMs.
To install the Nux repository, you need to install the EPEL7 repository then type:
# yum install -y http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-1.el7.nux.noarch.rpm
The Nux repository consists of 2 different channels:
- nux-dextop: this is the main channel; it is enabled by default,
- nux-dextop-testing: it is a channel used for testing; it is disabled by default.
- Download the latest nux-dextop-release rpm from
http://li.nux.ro/download/nux/dextop/el6/x86_64/
- Install nux-dextop-release rpm:
# rpm -Uvh nux-dextop-release*rpm
- Install mmv rpm package:
# yum install mmv
Rename the file extension of all .csv files in the current directory to .xls
mmv "*.csv" "#1.xls"
Copy report6part4.txt to ./french/rapport6partie4.txt along with all similarly named files:
mmv -c "report*part*.txt" "./french/rapport#1partie#2.txt"
Append the contents of all .txt files into one file:
mmv -a "*.txt" "all.txt"
or you can simply install the
mmv command and do:mmv *.t1 '#1.t2'unzip *.zip
The command result into an error which read as follows:
caution: filename not matched
To unzip all files, enter:
Sample outputs:
$ unzip *.zipSample outputs:
Archive: data.zip caution: filename not matched: invoices.zip caution: filename not matched: pictures.zip caution: filename not matched: visit.zip
Above error indicate that you used the unzip command wrongly. It means extract invoices.zip, pictures.zip, and visit.zip files from inside the data.zip archive. Your shell expands the command ‘unzip *.zip’ it as follows:
unzip data.zip invoices.zip pictures.zip visit.zip#2: Unzip Multiple Files from Linux Command Line Using Shell For Loop (Long Version)
You can also use for loop as follows:
ducommand: Estimate file space usage.
If you want to display the biggest file sizes only, then run the following command:
du -cks * | sort -rn | head
https://linux.die.net/man/1/pv
pv - monitor the progress of data through a pipe
pv allows a user to see the progress of data through a pipeline, by giving information such as time elapsed, percentage completed (with progress bar), current throughput rate, total data transferred, and ETA.
pv will copy each supplied FILE in turn to standard output (- means standard input), or if no FILEs are specified just standard input is copied. This is the same behaviour as cat(1).
A simple example to watch how quickly a file is transferred using nc(1):
pv file | nc -w 1 somewhere.com 3000
A similar example, transferring a file from another process and passing the expected size to pv:
cat file | pv -s 12345 | nc -w 1 somewhere.com 3000
In this example copy a file called origin-cdn.cyberciti.org_access.log to /tmp/origin-cdn-access.log and show progress:
OR just send it to /dev/null:
Use nc to create a network port # 2000. Type the following command:# pv origin-cdn.cyberciti.org_access.log > /tmp/origin-cdn-access.logOR just send it to /dev/null:
# pv origin-cdn.cyberciti.org_access.log > /dev/null$ nc -l -v -w 30 -p 2000 > /tmp/data.binOpen another terminal and type:
$ pv firmware33921.bin | nc -w 1 127.0.0.1 2000In this example you can see progress of both pipes:
- -c : Use cursor positioning escape sequences instead of just using carriage returns. This is useful in conjunction with -N (name) if you are using multiple pv invocations in a single, long, pipeline.
- N rawlogfile : Prefix the output information with NAME. Useful in conjunction with -c if you have a complicated pipeline and you want to be able to tell different parts of it apart.
In this example, extract tar ball and show progress using the dialog command:
http://www.catonmat.net/blog/unix-utilities-pipe-viewer/
By using pv you can precisely time how long it will take. Take a look at doing the same through pv:
$ pv access.log | gzip > access.log.gz 611MB 0:00:11 [58.3MB/s] [=> ] 15% ETA 0:00:59
Pipe viewer acts as "cat" here, except it also adds a progress bar.
$ pv -cN source access.log | gzip | pv -cN gzip > access.log.gz source: 760MB 0:00:15 [37.4MB/s] [=> ] 19% ETA 0:01:02 gzip: 34.5MB 0:00:15 [1.74MB/s] [ <=> ]
Here we specified the "-N" parameter to pv to create a named stream. The "-c" parameter makes sure the output is not garbaged by one pv process writing over the other.
This example shows that "access.log" file is being read at a speed of 37.4MB/s but gzip is writing data at only 1.74MB/s. We can immediately calculate the compression rate. It's 37.4/1.74 = 21x!
Notice how the gzip does not include how much data is left or how fast it will finish. It's because the pv process after gzip has no idea how much data gzip will produce (it's just outputting compressed data from input stream). The first pv process, however, knows how much data is left, because it's reading it.
Another similar example would be to pack the whole directory of files into a compressed tarball:
$ tar -czf - . | pv > out.tgz 117MB 0:00:55 [2.7MB/s] [> ]
$ pv -cN source access.log | gzip | pv -cN gzip > access.log.gz source: 760MB 0:00:15 [37.4MB/s] [=> ] 19% ETA 0:01:02 gzip: 34.5MB 0:00:15 [1.74MB/s] [ <=> ]
Here we specified the "-N" parameter to pv to create a named stream. The "-c" parameter makes sure the output is not garbaged by one pv process writing over the other.
This example shows that "access.log" file is being read at a speed of 37.4MB/s but gzip is writing data at only 1.74MB/s. We can immediately calculate the compression rate. It's 37.4/1.74 = 21x!
Notice how the gzip does not include how much data is left or how fast it will finish. It's because the pv process after gzip has no idea how much data gzip will produce (it's just outputting compressed data from input stream). The first pv process, however, knows how much data is left, because it's reading it.
Another similar example would be to pack the whole directory of files into a compressed tarball:
$ tar -czf - . | pv > out.tgz 117MB 0:00:55 [2.7MB/s] [> ]
Suppose you have two computers A and B. You want to transfer a directory from A to B very quickly. The fastest way is to use tar and nc, and time the operation with pv.
# on computer A, with IP address 192.168.1.100 $ tar -cf - /path/to/dir | pv | nc -l -p 6666 -q 5
# on computer B $ nc 192.168.1.100 6666 | pv | tar -xf -
That's it. All the files in /path/to/dir on computer A will get transferred to computer B, and you'll be able to see how fast the operation is going.
If you want the progress bar, you have to do the "pv -s $(...)" trick from the previous example (only on computer A).
Another funny example is by my blog reader alexandru. He shows how to time how fast the computer reads from /dev/zero:
$ pv /dev/zero > /dev/null 157GB 0:00:38 [4,17GB/s]
You may use -v : Verbose mode (show progress) in your command, or there's another method using Pipe Viewer (
pv) which shows the progress of the gzip, gunzip command as follows:$ pv database1.sql.gz | gunzip | mysql -u root -p database1
This will output progress similar to scp:
$ pv database1.sql.gz | gunzip | mysql -uroot -p database1
593MiB 1:00:33 [ 225kiB/s] [====================> ] 58% ETA 0:42:25
You can also use Pipe Viewer to monitor mysqldump:
mysqldump -uroot -p database1 | pv | gzip -9 > database1.sql.gz
If you don't already have
pv, you can install it with:yum install pv
or with macports
sudo port install pv-O <skey> Use <skey> as a secondary key when ordering the process display. See -o for key names (pid is the default). -o <key> Order the process display by sorting on <key> in descending order. A + or - can be prefixed to the key name to specify ascending or descending order, respectively. The supported keys are: pid Process ID (default). command Command name. cpu CPU usage. csw Number of context switches. time Execution time. threads alias: th Number of threads (total/running). ports alias: prt Number of Mach ports. mregion alias: mreg, reg Number of memory regions. mem Internal memory size. rprvt Resident private address space size. purg Purgeable memory size. vsize Total memory size. vprvt Private address space size. kprvt Private kernel memory size. kshrd Shared kernel memory size. pgrp Process group id. ppid Parent process id. state alias: pstate Process state. uid User ID. wq alias: #wq, workqueue The workqueue total/running. faults alias: fault The number of page faults. cow alias: cow_faults The copy-on-write faults. user alias: username Username. msgsent Total number of mach messages sent. msgrecv Total number of mach messages received. sysbsd Total BSD syscalls. sysmach Total Mach syscalls. pageins Total pageins.http://www.brianstorti.com/stop-using-tail/
what this
+F is all about: > Scroll forward, and keep trying to read when the end of file is reached. Normally this command would be used when already at the end of the file. It is a way to monitor the tail of a file which is > growing while it is being viewed. (The behavior is similar to the “tail -f” command.)less +F production.logCtrl-c to go to “normal” less mode (as if you had opened the file without the +F flag), and then you have all the normal less features you’d expect, including the search with /foo. You can go to the next or previous occurrence with n or N, up and down with j and k, create marks with m and do all sort of things that less(1) says you can do.When you need to watch multiple files at the same time,
tail -f can actually give you a better output.http://stackoverflow.com/questions/8245903/tail-sampling-logs
-f, --follow[={name|descriptor}]output appended data as the file grows;-f,--follow, and--follow=descriptorare equivalent
--retrykeep trying to open a file even if it is inaccessible when tail starts or if it becomes inaccessible later - useful only with-f
-Fsame as--follow=name --retry
http://stackoverflow.com/questions/3968103/how-can-i-format-my-grep-output-to-show-line-numbers-at-the-end-of-the-line-and
-n returns line number.
Use
-n or --line-number.grep -c is useful for finding how many times a string occurs in a file, but it only counts each occurence once per line. http://www.geeksforgeeks.org/daily-life-linux-commands/
Duplicate pipe content: ‘tee’ is a very useful utility that duplicates pipe content. Now, what makes tee really useful is that it can append data to existing files, making it ideal for writing periodic log information to multiple files at once.
export
- -p : List of all names that are exported in the current shell
- -n: Remove names from export list
- -f : Names are exported as functions
ls --color
man ls
man lsapropos: If you don’t know what something is or how to use it, the first place to look is its manual and information pages. If you don’t know the name of what you want to do, the apropos command can help. Let’s say you want to rename files but you don’t know what command does that. Try apropos with some word that is related to what you want, like this:
$ apropos rename ... mv (1) - move (rename) files prename (1) - renames multiple files rename (2) - change the name or location of a filethttps://unix.stackexchange.com/questions/64148/how-do-i-make-ls-show-file-sizes-in-megabytes/64149
ls -l --block-size=M will give you a long format listing (needed to actually see the file size) and round file sizes up to the nearest MiB.
If you want MB (10^6 bytes) rather than MiB (2^20 bytes) units, use
--block-size=MB instead.
If you don't want the
http://unix.stackexchange.com/questions/205867/viewing-all-iptables-rulesM suffix attached to the file size, you can use something like --block-size=1M.
Thus, to get a complete presentation of the netfilter rules, you need
iptables -vL -t filter
iptables -vL -t nat
iptables -vL -t mangle
iptables -vL -t raw
iptables -vL -t security
Alternatively, you can call the
https://www.cyberciti.biz/tips/linux-display-open-ports-owner.htmliptables-save program, which displays all the rules in all tables in a format that can be parsed by iptables-restore. This format is also reasonably readable by humans (it's pretty much like a series of calls to the iptables command to build the table).sudo lsof -i
sudo netstat -lptu
sudo netstat -tulpn
-p, --program
Show the PID and name of the program to which each socket belongs.
-l, --listening
Show only listening sockets. (These are omitted by default.)
-a, --all
Show both listening and non-listening (for TCP this means established connections) sockets. With the --interfaces option, show interfaces that are not marked
-udp|-u
--tcp|-t
--listening
--program|-p
http://stackoverflow.com/questions/11392526/how-to-sort-the-output-of-grep-l-chronologically-by-newest-modification-datehttps://en.wikipedia.org/wiki/Netcat
- there are two versions of netcat around. There is GNU netcat which is a re-implementation of the original nc. Interesting, and confusing at the same time.
The netcat utility can be run in the server mode on a specified port listening for incoming connections.
$ nc -l 2389
Also, it can be used in client mode trying to connect on the port(2389) just opened
$ nc localhost 23892. Use Netcat to Transfer Files
$ nc -l 2389 > test
and run the client as :
cat testfile | nc localhost 2389
$ nc -w 10 localhost 2389
The connection above would be terminated after 10 seconds.
6. Force Netcat Server to Stay Up$ nc -k -l 2389
It may be useful to know which ports are open and running services on a target machine. The -z flag can be used to tell nc to report open ports, rather than initiate a connection. Usually it's useful to turn on verbose output to stderr by use this option in conjunction with -v option.
nc -zv host.example.com 20-30
nc -zv host.example.com 80 20 22
echo "QUIT" | nc host.example.com 20-30
nc -p 31337 -w 5 host.example.com 42
Opens a TCP connection to port 42 of host.example.com, using port 31337 as the source port, with a timeout of 5 seconds.
nc -u host.example.com 53
Opens a UDP connection to port 53 of host.example.com.
http://www.commandlinefu.com/commands/view/8277/simple-du-command-to-give-size-of-next-level-of-subfolder-in-mbdu --max-depth=1 -B M |sort -rn
http://stackoverflow.com/questions/10103604/linux-command-line-du-how-to-make-it-show-only-total-for-each-directories
du -cksh *du -h -d 1
https://www.cyberciti.biz/faq/how-do-i-sort-du-h-output-by-size-under-linux/
To see top 10 files pass the output to the head command, enter:
http://superuser.com/questions/198529/how-to-scroll-one-page-at-a-time-in-linux-at-the-command-line
The same
ls | more although most people use the ls | less command as it has more features, such as scrolling back as well as forwards, and searching for text.
If you have GNU coreutils (common in most Linux distributions), you can use
du -sh * | sort -h. The -h option tells sort that the input is the human-readable format (number with unit).
Mac OS X doesn't have the
http://askubuntu.com/questions/205063/command-to-get-the-hostname-of-remote-server-using-ip-address-h option for sorthost <ip>http://askubuntu.com/questions/10521/how-to-scroll-in-the-terminal-app-top
The point of the "TOP" program is to tell you which processes are using the most resources or are at the TOP of the list.
As Daniel Arndt said, you can also use htop instead of top. It's available on all distro nowadays, and it provides better numbers (especially for memory usage)
It is also far easier to use and nicer to see, even if it's limited to terminal's colors. You can scroll to the right in order to see the full command, for instance, or you can kill a process with a simple F9. You can also see full tree with 't' key.
The command field is by default truncated automatically for better reading.
You need to run
top -c
to show full command then depending on your console window's capabilities you would be able to scroll to right and see full command.
Press ‘c‘ option in running top command, it will display absolute path of running process.Press (Shift+P) to sort processes as per CPU utilization. See screenshot below.
https://www.linux.com/learn/uncover-meaning-tops-statistics
What's "total memory" in your opinion? The size of your RAM? Not really. The real meaning is the total size of RAM that is mappable by your running kernel.
http://serverfault.com/questions/138427/top-what-does-virtual-memory-size-mean-linux-ubuntu/138625
Virtual memory isn't even necessarily memory. For example, if a process memory-maps a large file, the file is actually stored on disk, but it still takes up "address space" in the process.
Address space (ie. virtual memory in the process list) doesn't cost anything; it's not real. What's real is the RSS (RES) column, which is resident memory. That's how much of your actual memory a process is occupying.
But even that isn't the whole answer. If a process calls fork(), it splits into two parts, and both of them initially share all their RSS. So even if RSS was initially 1 GB, the result after forking would be two processes, each with an RSS of 1 GB, but you'd still only be using 1 GB of memory.
Confused yet? Here's what you really need to know: use the
free command and check the results before and after starting your program (on the +/- buffers/cache line). That difference is how much new memory your newly-started program used.
VIRT stands for the virtual size of a process, which is the sum of memory it is actually using, memory it has mapped into itself (for instance the video card’s RAM for the X server), files on disk that have been mapped into it (most notably shared libraries), and memory shared with other processes. VIRT represents how much memory the program is able to access at the present moment.
RES stands for the resident size, which is an accurate representation of how much actual physical memory a process is consuming. (This also corresponds directly to the %MEM column.) This will virtually always be less than the VIRT size, since most programs depend on the C library.
SHR indicates how much of the VIRT size is actually sharable (memory or libraries). In the case of libraries, it does not necessarily mean that the entire library is resident. For example, if a program only uses a few functions in a library, the whole library is mapped and will be counted in VIRT and SHR, but only the parts of the library file containing the functions being used will actually be loaded in and be counted under RES.
http://tecadmin.net/understanding-linux-top-command-results-uses/#Result Row #1:
Row 1 results shows about server up time from last reboot, currently logged in users and cpu load on server. The same output you can find using linux uptime command.
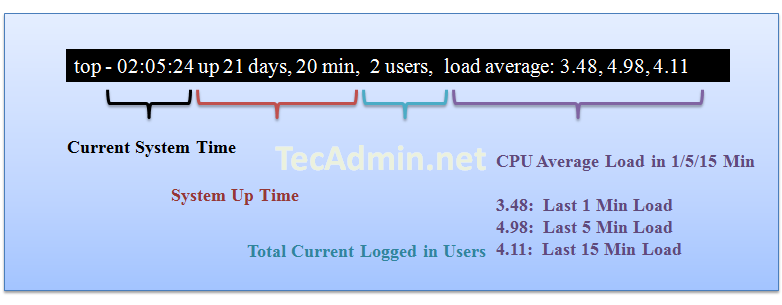
Result Row #2:
Row 2 shows the number of process running on server and there state.

Result Row #3:
Row three shows the cpu utilization status on server, you can find here how much cpu is free and how much is utilizing by system.

Row 4 shows the memory utilization on server, you can find here how much memory is used, the same results you can find using free command.

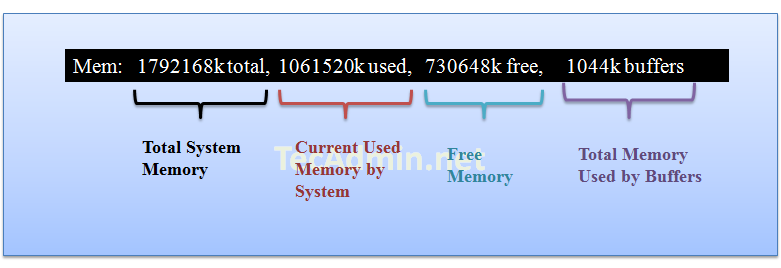
Row 4 shows the swap memory utilization on server, you can find here how much swap is being used, the same results you can find using free command.

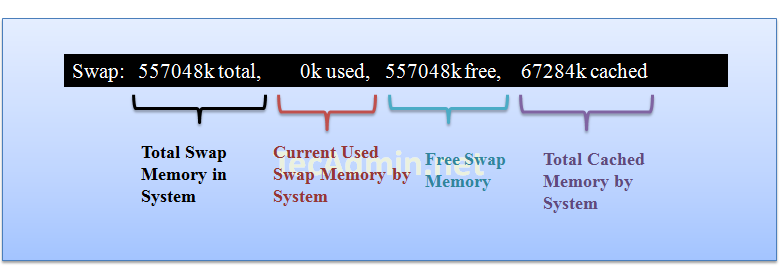
In this steps you will see all running process on servers and there additional details about them like below.


http://unix.stackexchange.com/questions/554/how-to-monitor-cpu-memory-usage-of-a-single-process
On Linux,
top actually supports focusing on a single process, although it naturally doesn't have a history graph:top -p PID
This is also available on Mac OS X with a different syntax:
top -pid PIDhttps://coolestguidesontheplanet.com/how-to-compress-and-uncompress-files-and-folders-in-os-x-lion-10-7-using-terminal/
http://superuser.com/questions/161706/command-to-gzip-a-folder
tar -czf folder_name.tar.gz folder_name/
If you don't want to make a tar archive (may be you want to compress just a single file), then you can use gzip command directly.
gzip file.txt
It will create a compressed file named file.txt.gz
gzip file.txt replaces the original filegzip -k file.txt to "keep" (don't delete) the input filegzip -d filename.ext.gz
gunzip filename.ext.gz
tar -xvf filename.tar
date +%Z
http://www.cyberciti.biz/faq/centos-linux-6-7-changing-timezone-command-line/find-timezone/
Outputs (note CST in output):
Tue Jan 13 00:09:06 CST 2015
Or better use the following command:
Outputs (note UTC in output):
lrwxrwxrwx. 1 root root 25 Nov 9 03:52 /etc/localtime -> ../usr/share/zoneinfo/UTC
Finally, use the following command:
Outputs:
ZONE="America/Chicago"show only total for each directories
du -h -d 1
-h is for human readable sizes.
http://stackoverflow.com/questions/15595374/whats-the-difference-between-nohup-and-ampersandnohup catches the hangup signal (see man 7 signal) while the ampersand doesn't (except the shell is confgured that way or doesn't send SIGHUP at all).
Normally, when running a command using
& and exiting the shell afterwards, the shell will terminate the sub-command with the hangup signal (kill -SIGHUP <pid>). This can be prevented using nohup, as it catches the signal and ignores it so that it never reaches the actual application.
In case you're using bash, you can use the command
shopt | grep hupon to find out whether your shell sends SIGHUP to its child processes or not. If it is off, processes won't be terminated, as it seems to be the case for you. More information on how bash terminates applications can be found here.nohup runs the specificed program with the SIGHUP signal ignored. When a terminal is closed, the kernel sends SIGHUP to the controlling process in that terminal (i.e. the shell). The shell in turn sends SIGHUP to all the jobs running in the background. Running a job with nohup prevents it from being killed in this way if the terminal dies (which happens e.g. if you were logged in remotely and the connection drops, or if you close your terminal emulator).nohup also redirects the program's output to the file nohup.out. This avoids the program dying because it isn't able to write to its output or error output. Note that nohup doesn't redirect the input. To fully disconnect a program from the terminal where you launched it, usenohup myprogram </dev/null >myprogram.log 2>&1 &
You can use
jmap to get a dump of any process running, assuming you know the pid.
Use Task Manager or Resource Monitor to get the pid. Then
jmap -dump:format=b,file=cheap.bin <pid>http://unix.stackexchange.com/questions/164653/actual-memory-usage-of-a-process
[root@server ~]# pmap 10436 | grep total
total 379564K
In recent versions of linux, use the smaps subsystem. For example, for a process with a PID of 1234:
cat /proc/1234/smaps
It will tell you exactly how much memory it is using at that time. More importantly, it will divide the memory into private and shared, so you can tell how much memory your instance of the program is using, without including memory shared between multiple instances of the program.
http://sharadchhetri.com/2013/03/11/4-different-commands-to-check-the-load-average-in-linux/
Command 1: Run the command, “cat /proc/loadavg” .
root@localhost:~]# cat /proc/loadavg
0.18 0.28 0.30 2/527 4237
root@localhost:~]#
Command 2 : Run the command, “w” .
[root@localhost:~]# w
09:07:09 up 8:18, 2 users, load average: 1.00, 1.00, 1.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 – 00:52 10:52 0.13s 0.13s -bash
root pts/0 192.168.122.1 01:01 0.00s 0.34s 0.00s w
[root@localhost:~]#
Command 3 : Run the command, “uptime” .
[root@localhost ~]# uptime
09:08:57 up 8:20, 2 users, load average: 1.00, 1.00, 1.00
[root@localhost ~]#
Command 4: Run the command, “top” . See the first line of top command’s output
[root@localhost ~]# top
top – 09:10:32 up 8:21, 2 users, load average: 1.00, 1.00, 1.00
free -t -m
cat /proc/cpuinfo | grep processor | wc -llscpu
http://www.thegeekstuff.com/2013/06/cut-command-examples/
1. Select Column of Characters
To extract only a desired column from a file use -c option.
$ cut -c2 test.txt
2. Select Column of Characters using Range
cut -c1-3 test.txt
3. Select Column of Characters using either Start or End Positioncut -c3- test.txt
$ cut -c-8 test.txt
The entire line would get printed when you don’t specify a number before or after the ‘-‘ as shown below.
$ cut -c- test.txt
4. Select a Specific Field from a File
$ cut -d':' -f1 /etc/passwd
5. Select Multiple Fields from a File
$ grep "/bin/bash" /etc/passwd | cut -d':' -f1,6
$ grep "/bin/bash" /etc/passwd | cut -d':' -f1-4,6,7
6. Select Fields Only When a Line Contains the Delimiter
it is possible to filter and display only the lines that contains the specified delimiter using -s option.
The following example doesn’t display any output, as the cut command didn’t find any lines that has | (pipe) as delimiter in the /etc/passwd file.
$ grep "/bin/bash" /etc/passwd | cut -d'|' -s -f1
7. Select All Fields Except the Specified Fields
$ grep "/bin/bash" /etc/passwd | cut -d':' --complement -s -f7
8. Change Output Delimiter for Display
$ grep "/bin/bash" /etc/passwd | cut -d':' -s -f1,6,7 --output-delimiter='#'
9. Change Output Delimiter to Newline
$ grep bala /etc/passwd | cut -d':' -f1,6,7 --output-delimiter=$'\n'
10. Combine Cut with Other Unix Command Output
$ ps axu | grep python | sed 's/\s\+/ /g' | cut -d' ' -f2,11-
time find . -type f -print | parallel echo {}
http://superuser.com/questions/609615/efficient-way-to-search-string-within-file-find-and-grep
$ time find . -type f -exec grep -Fli "mystring" {} 2>/dev/null \;
real 0m13.982s
user 0m4.328s
sys 0m1.592s
$ time find . -type f -print0 | xargs -0 grep -Fil "mystring" >/dev/null
real 0m3.565s
user 0m3.508s
sys 0m0.052s
To ignore case distinctions:
To display print only the filenames with GNU grep, enter:
You can also specify directory name:
http://stackoverflow.com/questions/1019116/using-ls-to-list-directories-and-their-total-sizesgrep -ri "word" .To display print only the filenames with GNU grep, enter:
grep -r -l "foo" .You can also specify directory name:
grep -r -l "foo" /path/to/dir/*.cdu -sh *
Explanation:
du: Disk Usage-s: Display an entry for each specified file. (Equivalent to -d 0)-h: "Human-readable" output. Use unit suffixes: Byte, Kilobyte, Megabyte, Gigabyte, Terabyte andPetabyte.find / -xdev -type f -size +100M -exec ls -la {} \; | sort -nk 5find . -type d \( -path dir1 -o -path dir2 -o -path dir3 \) -prune -o -print
Here we exclude dir1, dir2 and dir3, since in
http://stackoverflow.com/questions/10265162/the-meaning-of-real-user-and-sys-in-output-of-linux-time-commandfind expressions it is an action, that acts on the criteria -path dir1 -o -path dir2 -o -path dir3 (if dir1 or dir2 or dir3), ANDed with type -d. Further action is -o print, just print.
Basically though, the
user time is how long your program was running on the CPU, and the systime was how long your program was waiting for the operating system to perform tasks for it. If you're interested in benchmarking, user + sys is a good time to use. real can be affected by other running processes, and is more inconsistent.# rev <file name>
http://www.admin-magazine.com/Articles/Automating-with-Expect-Scripts
#!/usr/bin/expect -f spawn ssh aspen expect "password: " send "PASSWORD\r" expect "$ " send "ps -ef |grep apache\r" expect "$ " send "exit\r"
#!/usr/bin/expect -f
spawn ssh HOSTNAME
expect "login:"
send "username\r"
expect "Password:"
send "password\r"
interact
#!/usr/bin/expect
set timeout 20
set ip [lindex $argv 0]
set user [lindex $argv 1]
set password [lindex $argv 2]
spawn ssh "$user\@$ip"
expect "*?assword:*"
send "$password\r";
interact
#!/usr/bin/expect
set timeout 20
set ip [lindex $argv 0]
spawn ssh "your-user-name\@$ip"
expect "Password:"
send "your-pass\r";
interact
Useful for interview
List All Users In The System
cat /etc/passwd
awk -F':' '{ print $1}' /etc/passwd
User group info: groups user_name
uniq
http://unix.stackexchange.com/questions/114140/uniq-wont-remove-duplicate
The uniq command reads the input file and compares adjacent lines. Any line that is the same as the one before it will be discarded. In other words, duplicates are discarded, leaving only the unique lines in the file.
You have to sort the output in order for the
uniq command to be able to work. See the man page:So you can pipe the output intoFilter adjacent matching lines from INPUT (or standard input), writing to OUTPUT (or standard output).
sort first and then uniq it. Or you can make use of sort's ability to perform the sort and unique all together like so: sort -ucat <(seq 5) <(seq 5) | sort | uniq
cat <(seq 5) <(seq 5) | sort -u
http://lowfatlinux.com/linux-uniq.html
-u Print only lines that appear once in the input file.
-d Print only the lines that appear more than once in the input file.
-c Precede each output line with a count of the number of times it was found.
- n 前n个字段与每个字段前的空白一起被忽略。一个字段是一个非空格、非制表符的字符串,彼此由制表符和空格隔开(字段从0开始编号)。-c Precede each output line with a count of the number of times it was found.
https://ruixublog.wordpress.com/2015/05/14/leetcode192-word-frequency/
uniq命令常用语报告或者消除文件中的重复内容,一般与sort命令结合使用。
-f 栏位:忽略指定的栏;
-s N:指定可以跳过前N个字符;
-w 字符位数:指定用于比较的最大字符数;
http://unix.stackexchange.com/questions/76049/what-is-the-difference-between-sort-u-and-sort-uniquniq命令常用语报告或者消除文件中的重复内容,一般与sort命令结合使用。
-f 栏位:忽略指定的栏;
-s N:指定可以跳过前N个字符;
-w 字符位数:指定用于比较的最大字符数;
sort | uniq existed before sort -u, and is compatible with a wider range of systems, although almost all modern systems do support -u -- it's POSIX. t is also faster internally as a result of being able to do both operations at the same time (and due to the fact that it doesn't require IPC between uniq and sort). Especially if the file is big, sort -u will likely use fewer intermediate files to sort the data.
cat
https://ruixublog.wordpress.com/2015/05/14/leetcode192-word-frequency/
2.从键盘创建一个文件。$ cat > filename
只能创建新文件,不能编辑已有文件.
3.将几个文件合并为一个文件: $cat file1 file2 > file
- 参数:
-n 或 –number 由 1 开始对所有输出的行数编号
-b 或 –number-nonblank 和 -n 相似,只不过对于空白行不编号
-s 或 –squeeze-blank 当遇到有连续两行以上的空白行,就代换为一行的空白行
-v 或 –show-nonprinting
例:
把 textfile1 的档案内容加上行号后输入 textfile2 这个档案里
cat -n textfile1 > textfile2 - 把 textfile1 和 textfile2 的档案内容加上行号(空白行不加)之后将内容附加到 textfile3 里。
cat -b textfile1 textfile2 >> textfile3 - 把text.txt文件扔进垃圾箱,赋空值test.txt
- cat /dev/null > /etc/test.txt
http://www.eriky.com/2014/10/copy-one-file-to-multiple-locations-with-bash-globbing-wildcards
echo /home/*/etc/php5/php.ini | xargs -n 1 cp php.ini
http://www.eriwen.com/bash/pushd-and-popd/
put paths on a stack (push) and then take them off in reverse order (pop). This is useful when you have more than one directory that you need to switch between frequently.
# change to home directory quickly in bash cd # change to last directory in bash cd -
# print directories on the stack dirs
http://evc-cit.info/cit050/pushd.html
If you never use the
pushd and popd commands, the shell’s directory stack will only contain one entry: your current directory. dirs -l -v
(The -l option gives the full name for your home directory rather than a ~, and the -v option prints the stack one entry per line, numbered.)
The popd command has taken the top entry (/opt) off the stack and has moved you back into the directory that is now on top of the stack (/var). X. Switch between two directories
if you type just
pushd without any arguments, it will swap the top two entries on the stack, so that you can switch back and forth between the two directories at will.http://stackoverflow.com/questions/18983719/is-there-any-way-to-get-curl-to-decompress-a-response-without-sending-the-accept
Is there any way to get curl to decompress a response without sending the Accept headers in the request?
curl -sH 'Accept-encoding: gzip' http://example.com/ | gunzip -
Or there's also
--compressed, which curl will decompress (I believe) since it knows the response is compressed.
tac: reverse of 'cat', print a file line by line in reverse order.
cal: Displays a very nice calendar with current date highlighted.
http://yyeclipse.blogspot.com/2013/01/some-powerful-shell-commands.html
!$
!$是一个特殊的环境变量,它代表了上一个命令的最后一个字符串。如:你可能会这样:
$mkdir mydir
$mv mydir yourdir
$cd yourdir
可以改成:
$mkdir mydir
$mv !$ yourdir
$cd !$
sudo !!
以root的身份执行上一条命令 。
http://www.tecmint.com/mysterious-uses-of-symbol-or-operator-in-linux-commands/
http://www.linuxstory.org/mysterious-ten-operator-in-linux/
“!$” 符号可以将上一条命令的参数传递给下一条命令参数:
ls -l !$
你可以运行 !-1、!-2 或者 !-7 等命令来执行你记录序列中的倒数第一条命令、倒数第二条命令已经倒数第七条等等
非常实用的 !! 操作符
su -c !! root
^old^new
替换前一条命令里的部分字符串。
> file.txt
创建一个空文件,比touch短。
mtr coolshell.cn
mtr命令比traceroute要好。
echo “ls -l” | at midnight
在某个时间运行某个命令。
curl -u user:pass -d status=”Tweeting from the shell” http://twitter.com/statuses/update.xml
ps aux | sort -nk +4 | tail
列出头十个最耗内存的进
netstat –tlnp
列出本机进程监听的端口号。(netstat -anop 可以显示侦听在这个端口号的进程)
tail -f /path/to/file.log | sed '/^Finished: SUCCESS$/ q'
当file.log里出现Finished: SUCCESS时候就退出tail,这个命令用于实时监控并过滤log是否出现了某条记录。
ssh user@server bash < /path/to/local/script.sh
在远程机器上运行一段脚本。这条命令最大的好处就是不用把脚本拷到远程机器上。
ssh user@host cat /path/to/remotefile | diff /path/to/localfile -
比较一个远程文件和一个本地文件
net rpc shutdown -I ipAddressOfWindowsPC -U username%password
远程关闭一台Windows的机器
screen -d -m -S some_name ping my_router
后台运行一段不终止的程序,并可以随时查看它的状态。-d -m参数启动“分离”模式,-S指定了一个session的标识。可以通过-R命令来重新“挂载”一个标识的session。更多细节请参考screen用法 man screen。
wget --random-wait -r -p -e robots=off -U mozilla http://www.example.com
下载整个www.example.com网站。(注:别太过分,大部分网站都有防爬功能了:))
lsof
http://www.thegeekstuff.com/2012/08/lsof-command-examples/
lsof –i
实时查看本机网络服务的活动状态。
List processes which opened a specific file
lsof +D /var/log/
List opened files based on process names starting with
-c followed by the process name will list the files opened by the process starting with that processes name.
lsof -c ssh -c init -c java
List files opened by a specific user
lsof -u user
lsof -u ^user
List all open files by a specific process
lsof -p 1753
you can use ‘-t’ option to list output only the process id of the process
kill -9 `lsof -t -u lakshmanan`
lsof -t /var/log/syslog
https://danielmiessler.com/study/lsof/
-a : AND the results (instead of OR)
vim scp://username@host//path/to/somefile
vim一个远程文件
python -m SimpleHTTPServer
一句话实现一个HTTP服务,把当前目录设为HTTP服务目录,可以通过http://localhost:8000访问 这也许是这个星球上最简单的HTTP服务器的实现了。
Scripting
Single quotes won’t interpolate anything, but double quotes will (e.g., variables, backticks, \ escapes)
!$
!$是一个特殊的环境变量,它代表了上一个命令的最后一个字符串。如:你可能会这样:
$mkdir mydir
$mv mydir yourdir
$cd yourdir
可以改成:
$mkdir mydir
$mv !$ yourdir
$cd !$
sudo !!
以root的身份执行上一条命令 。
http://www.tecmint.com/mysterious-uses-of-symbol-or-operator-in-linux-commands/
http://www.linuxstory.org/mysterious-ten-operator-in-linux/
“!$” 符号可以将上一条命令的参数传递给下一条命令参数:
ls -l !$
你可以运行 !-1、!-2 或者 !-7 等命令来执行你记录序列中的倒数第一条命令、倒数第二条命令已经倒数第七条等等
非常实用的 !! 操作符
su -c !! root
7.使用 !(文件名) 的方式来避免命令对某个文件的影响
这里的 “!” 符号相当于逻辑否定来使用,用来避免对加了 “!” 前缀的文件产生影响。
A.从目录中删除除 2.txt 外的所有文件: rm !(2.txt)
B.从目录中删除 pdf 为后缀以外的文件: rm !(*.pdf)
8.检查某个目录是否存在,如果存在就将其打印
这里使用 ‘! -d’ 命令来判断目录是否为空,同时使用 “&&” 和 “||” 命令来打印判断目录是否存在:
9.检测目录是否是否为空,如果为空则退出: [ ! -d dir ] && exit
10.检测目录是否为空,如果为空则在 home 目录中重新创建目录: [ ! -d dir ] && mkdir -d dir
^old^new
替换前一条命令里的部分字符串。
> file.txt
创建一个空文件,比touch短。
mtr coolshell.cn
mtr命令比traceroute要好。
echo “ls -l” | at midnight
在某个时间运行某个命令。
curl -u user:pass -d status=”Tweeting from the shell” http://twitter.com/statuses/update.xml
ps aux | sort -nk +4 | tail
列出头十个最耗内存的进
netstat –tlnp
列出本机进程监听的端口号。(netstat -anop 可以显示侦听在这个端口号的进程)
tail -f /path/to/file.log | sed '/^Finished: SUCCESS$/ q'
当file.log里出现Finished: SUCCESS时候就退出tail,这个命令用于实时监控并过滤log是否出现了某条记录。
ssh user@server bash < /path/to/local/script.sh
在远程机器上运行一段脚本。这条命令最大的好处就是不用把脚本拷到远程机器上。
ssh user@host cat /path/to/remotefile | diff /path/to/localfile -
比较一个远程文件和一个本地文件
net rpc shutdown -I ipAddressOfWindowsPC -U username%password
远程关闭一台Windows的机器
screen -d -m -S some_name ping my_router
后台运行一段不终止的程序,并可以随时查看它的状态。-d -m参数启动“分离”模式,-S指定了一个session的标识。可以通过-R命令来重新“挂载”一个标识的session。更多细节请参考screen用法 man screen。
wget --random-wait -r -p -e robots=off -U mozilla http://www.example.com
下载整个www.example.com网站。(注:别太过分,大部分网站都有防爬功能了:))
lsof
http://www.thegeekstuff.com/2012/08/lsof-command-examples/
Which process opens 9160
lsof -i :9160
实时查看本机网络服务的活动状态。
List processes which opened a specific file
lsof /var/log/system.log
List opened files under a directorylsof +D /var/log/
List opened files based on process names starting with
-c followed by the process name will list the files opened by the process starting with that processes name.
lsof -c ssh -c init -c java
List files opened by a specific user
lsof -u user
lsof -u ^user
List all open files by a specific process
lsof -p 1753
you can use ‘-t’ option to list output only the process id of the process
kill -9 `lsof -t -u lakshmanan`
lsof -t /var/log/syslog
https://danielmiessler.com/study/lsof/
-a : AND the results (instead of OR)
lsof -i
Get only IPv6 traffic with -i 6
# lsof -i 6
lsof -iTCP
Show networking related to a given port using -i :port
lsof -i :22
lsof -i :8000 -sTCP:LISTEN
Show connections to a specific host using @host
This is quite useful when you’re looking into whether you have open connections with a given host on the network or on the internet.
# lsof -i@172.16.12.5
lsof -i@172.16.12.5:22
Find listening ports
lsof -i -sTCP:LISTEN
lsof -i | grep -i LISTEN
lsof -i -sTCP:ESTABLISHED
See what a given process ID has open using -p
# lsof -p 10075
See what files and network connections a named command is using with -c
# lsof -c syslog-ng
vim scp://username@host//path/to/somefile
vim一个远程文件
python -m SimpleHTTPServer
一句话实现一个HTTP服务,把当前目录设为HTTP服务目录,可以通过http://localhost:8000访问 这也许是这个星球上最简单的HTTP服务器的实现了。
Scripting
Single quotes won’t interpolate anything, but double quotes will (e.g., variables, backticks, \ escapes)
Shortcuts to Move Faster in Bash Command Line
- Move to the start of line.
Ctrl+a - Move to the end of line.
Ctrl+e - Move forward a word.
Meta+f(a word contains alphabets and digits, no symbols) - Move backward a word.
Meta+b - Clear the screen.
Ctrl+l
- Search as you type.
Ctrl+rand type the search term; RepeatCtrl+rto loop through results. - Search the last remembered search term.
Ctrl+rtwice. - End the search at current history entry.
Ctrl+j - Cancel the search and restore original line.
Ctrl+g
mv `ls --sort-time -r | tail -n` /home/yasemin/hebelek/
http://segmentfault.com/a/1190000002803307
加在一个命令的最后,可以把这个命令放到后台执行,如
watch -n 10 sh test.sh & #每10s在后台执行一次test.sh脚本
二、ctrl + z
全选复制放进笔记
可以将一个正在前台执行的命令放到后台,并且处于暂停状态。
jobs -l选项可显示所有任务的PID,jobs的状态可以是running, stopped, Terminated。但是如果任务被终止了(kill),shell 从当前的shell环境已知的列表中删除任务的进程标识。
fg: 将后台中的命令调至前台继续运行。如果后台中有多个命令,可以用fg %jobnumber(是命令编号,不是进程号)将选中的命令调出。
bg: 将一个在后台暂停的命令,变成在后台继续执行。如果后台中有多个命令,可以用bg %jobnumber将选中的命令调出。
nohup
如果让程序始终在后台执行,即使关闭当前的终端也执行(之前的&做不到),这时候需要nohup。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。关闭中断后,在另一个终端jobs已经无法看到后台跑得程序了,此时利用ps(进程查看命令)
ps -aux | grep "test.sh" #a:显示所有程序 u:以用户为主的格式来显示 x:显示所有程序,不以终端机来区分
Linux运行与控制后台进程的方法:nohup, setsid, &, disown, screen
1.nohup
顾名思义,nohup的用途就是让提交的命令忽略所有的hangup信号。
使用方法:nohup COMMAND [ARG]...
2.setsid
在一个新的会话中运行命令,从而可以避开当前终端发出的HUP信号。
使用方法:setsid COMMAND [ARG]...
3.&
可以结合()产生一个新的子shell并在这个子shell中将任务放置到后台运行,从而不受当前shell终端的HUP信号影响。
使用方法:(COMMAND [ARG]... &)
而我通常的使用方式为:
nohup ./filename.sh > filename.log 2>&1 &
三点理由:
1)nohup保障进程不会被hangup信号异常中断;
2)将任务放置到后台运行,不占用当前的终端;
3)将错误输出也打印到log中,默认>只有标准输出,错误输出没有。
5.disown
亡羊补牢,为没有使用nohup与setsid的进程加上忽略HUP信号的功能。
使用方法:
将当前正在前台运行的进程放到后台运行(ctrl+z和bg);
然后执行disown -h %{jobid} //这里的{jobid}是通过jobs命令中看到的进程前[]中的数字。
6.通过screen来实现稳定的后台运行
screen是建立一个新的全屏虚拟会话终端,这个会话只有在手动输入exit的时候才会退出,在这个会话里执行的命令不用担心HUP信号会对我们的进程 造成影响,因此也不用给每个命令前都加上“nohup”或“setsid”了,非常适合我们有规划的执行大量的后台任务,可以非常方便的让我们对这些后台任 务进行管理。
使用方法:
screen //立即创建并进入一个会话。
screen -dmS {name} //建立一个处于断开模式下的会话,并根据我们的需要指定其会话名称。
screen -list //列出所有会话。
screen -r {name} //进入指定会话。
ctrl +ad //输入快捷键ctrl +a和d,可暂时退出当前会话。
exit //进入指定会话后执行exit即可关闭该会话。
http://segmentfault.com/a/1190000002905983
vim
%s/\\x22/"/g
%s/\\x5C//g
g 代表全局。
s 代表替换
for x in $in_list;do
if [ "$new" == "$x" ]
then
echo "same "$x
continue
else
continue
#sh run.sh $new $x > $root$new"_"$x.log
fi
done;
http://segmentfault.com/a/1190000002547332
答: /proc文件系统是一个基于内存的文件系统,其维护着关于当前正在运行的内核状态信息,其中包括CPU、内存、分区划分、I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的并不是各种实际存储信息的文件,它们指向的是内存里的信息。/proc文件系统是由系统自动维护的。
答: cpio就是复制入和复制出的意思。cpio可以向一个归档文件(或单个文件)复制文件、列表,还可以从中提取文件。
问:11 如何在/usr目录下找出大小超过10MB的文件?
全选复制放进笔记
# find /usr -size +10M
问:7 如何从命令行查看域SPF记录?
答: 我们可以用dig命令来查看域SPF记录。举例如下:
linuxtechi@localhost:~$ dig -t TXT google.com
问:8 如何识别Linux系统中指定文件(/etc/fstab)的关联包?
# rpm -qf /etc/fstab
以上命令能列出提供/etc/fstab这个文件的包。
问:9 哪条命令用来查看bond0的状态?
cat /proc/net/bonding/bond0
问:10 Linux系统中的/proc文件系统有什么用?
答: /proc文件系统是一个基于内存的文件系统,其维护着关于当前正在运行的内核状态信息,其中包括CPU、内存、分区划分、I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的并不是各种实际存储信息的文件,它们指向的是内存里的信息。/proc文件系统是由系统自动维护的。
问:11 如何在/usr目录下找出大小超过10MB的文件?
# find /usr -size +10M
问:12 如何在/home目录下找出120天之前被修改过的文件?
# find /home -mtime +120
问:13 如何在/var目录下找出90天之内未被访问过的文件?
# find /var \! -atime -90
问:14 在整个目录树下查找文件core,如发现则无需提示直接删除它们。
# find / -name core -exec rm {} \;
问:15 strings命令有什么作用?
答: strings命令用来提取和显示非文本文件中的文本字符串。(LCTT 译注:当用来分析你系统上莫名其妙出现的二进制程序时,可以从中找到可疑的文件访问,对于追查入侵有用处)
问:16 tee 过滤器有什么作用 ?
答: tee 过滤器用来向多个目标发送输出内容。如果用于管道的话,它可以将输出复制一份到一个文件,并复制另外一份到屏幕上(或一些其它程序)。
linuxtechi@localhost:~$ ll /etc | nl | tee /tmp/ll.out
在以上例子中,从ll输出可以捕获到 /tmp/ll.out 文件中,并且同样在屏幕上显示了出来。
问:17 export PS1 = `$LOGNAME@hostname:\$PWD: 这条命令是在做什么?
答: 这条export命令会更改登录提示符来显示用户名、本机名和当前工作目录。
http://www.hollischuang.com/archives/800
1.查找文件
find / -name filename.txt 根据名称查找/目录下的filename.txt文件。
find . -name "*.xml" 递归查找所有的xml文件
find . -name "*.xml" |xargs grep "hello world" 递归查找所有文件内容中包含hello world的xml文件
grep -H 'spring' *.xml 查找所以有的包含spring的xml文件
find ./ -size 0 | xargs rm -f & 删除文件大小为零的文件
ls -l | grep 'jar' 查找当前目录中的所有jar文件
grep 'test' d* 显示所有以d开头的文件中包含test的行。
grep 'test' aa bb cc 显示在aa,bb,cc文件中匹配test的行。
grep '[a-z]\{5\}' aa 显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
20.查看端口占用情况
netstat -tln | grep 8080 查看端口8080的使用情况
21.查看端口属于哪个程序
lsof -i :8080
23.以树状图列出目录的内容
tree a
用十条命令在一分钟内检查Linux服务器性能
Finding all large files in the root filesystem
http://unix.stackexchange.com/questions/140367/finding-all-large-files-in-the-root-filesystem
http://www.infoq.com/cn/news/2015/12/linux-performance
http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
https://github.com/jlevy/the-art-of-command-line
http://blog.jobbole.com/90364/
Use
type
learn vi
http://unix.stackexchange.com/questions/108174/how-to-persist-ulimit-settings-in-osx-mavericks
http://www.hongkiat.com/blog/linux-commands-to-avoid/
1. Linux Fork Bomb Command
http://www.techug.com/linux-bash-alias
1. 取出两个文件的并集(重复的行只保留一份)
cat file1 file2 | sort | uniq
2. 取出两个文件的交集(只留下同时存在于两个文件中的文件)
cat file1 file2 | sort | uniq -d
3. 删除交集,留下其他的行
cat file1 file2 | sort | uniq -u
如果需要计数也有一个很好的参数uniq -c 可以将相同行数的计数放在行首
sort排序是根据从输入行抽取的一个或多个关键字进行比较来完成的。排序关键字定义了用来排序的最小的字符序列。缺省情况下以整行为关键字按ASCII字符顺序进行排序。
改变缺省设置的选项主要有:
- m 若给定文件已排好序,合并文件。
- c 检查给定文件是否已排好序,如果它们没有都排好序,则打印一个出错信息,并以状态值1退出。
- u 对排序后认为相同的行只留其中一行。
- o 输出文件 将排序输出写到输出文件中而不是标准输出,如果输出文件是输入文件之一,sort先将该文件的内容写入一个临时文件,然后再排序和写输出结果。
改变缺省排序规则的选项主要有:
- d 按字典顺序排序,比较时仅字母、数字、空格和制表符有意义。
- f 将小写字母与大写字母同等对待。
- I 忽略非打印字符。
- M 作为月份比较:“JAN”<“FEB”
- r 按逆序输出排序结果。
-k, -key=POS1[,POS2] posl - pos2 指定一个或几个字段作为排序关键字,字段位置从posl开始,到pos2为止(包括posl,不包括pos2)。如不指定pos2,则关键字为从posl到行尾。字段和字符的位置从0开始。
- b 在每行中寻找排序关键字时忽略前导的空白(空格和制表符)。
- t separator 指定字符separator作为字段分隔符。vim
%s/\\x22/"/g
%s/\\x5C//g
g 代表全局。
s 代表替换
for x in $in_list;do
if [ "$new" == "$x" ]
then
echo "same "$x
continue
else
continue
#sh run.sh $new $x > $root$new"_"$x.log
fi
done;
http://segmentfault.com/a/1190000002547332
答: /proc文件系统是一个基于内存的文件系统,其维护着关于当前正在运行的内核状态信息,其中包括CPU、内存、分区划分、I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的并不是各种实际存储信息的文件,它们指向的是内存里的信息。/proc文件系统是由系统自动维护的。
答: cpio就是复制入和复制出的意思。cpio可以向一个归档文件(或单个文件)复制文件、列表,还可以从中提取文件。
问:11 如何在/usr目录下找出大小超过10MB的文件?
全选复制放进笔记
# find /usr -size +10M
问:7 如何从命令行查看域SPF记录?
答: 我们可以用dig命令来查看域SPF记录。举例如下:
linuxtechi@localhost:~$ dig -t TXT google.com
问:8 如何识别Linux系统中指定文件(/etc/fstab)的关联包?
# rpm -qf /etc/fstab
以上命令能列出提供/etc/fstab这个文件的包。
问:9 哪条命令用来查看bond0的状态?
cat /proc/net/bonding/bond0
问:10 Linux系统中的/proc文件系统有什么用?
答: /proc文件系统是一个基于内存的文件系统,其维护着关于当前正在运行的内核状态信息,其中包括CPU、内存、分区划分、I/O地址、直接内存访问通道和正在运行的进程。这个文件系统所代表的并不是各种实际存储信息的文件,它们指向的是内存里的信息。/proc文件系统是由系统自动维护的。
问:11 如何在/usr目录下找出大小超过10MB的文件?
# find /usr -size +10M
问:12 如何在/home目录下找出120天之前被修改过的文件?
# find /home -mtime +120
问:13 如何在/var目录下找出90天之内未被访问过的文件?
# find /var \! -atime -90
问:14 在整个目录树下查找文件core,如发现则无需提示直接删除它们。
# find / -name core -exec rm {} \;
问:15 strings命令有什么作用?
答: strings命令用来提取和显示非文本文件中的文本字符串。(LCTT 译注:当用来分析你系统上莫名其妙出现的二进制程序时,可以从中找到可疑的文件访问,对于追查入侵有用处)
问:16 tee 过滤器有什么作用 ?
答: tee 过滤器用来向多个目标发送输出内容。如果用于管道的话,它可以将输出复制一份到一个文件,并复制另外一份到屏幕上(或一些其它程序)。
linuxtechi@localhost:~$ ll /etc | nl | tee /tmp/ll.out
在以上例子中,从ll输出可以捕获到 /tmp/ll.out 文件中,并且同样在屏幕上显示了出来。
问:17 export PS1 = `$LOGNAME@hostname:\$PWD: 这条命令是在做什么?
答: 这条export命令会更改登录提示符来显示用户名、本机名和当前工作目录。
http://www.hollischuang.com/archives/800
1.查找文件
find / -name filename.txt 根据名称查找/目录下的filename.txt文件。
find . -name "*.xml" 递归查找所有的xml文件
find . -name "*.xml" |xargs grep "hello world" 递归查找所有文件内容中包含hello world的xml文件
grep -H 'spring' *.xml 查找所以有的包含spring的xml文件
find ./ -size 0 | xargs rm -f & 删除文件大小为零的文件
ls -l | grep 'jar' 查找当前目录中的所有jar文件
grep 'test' d* 显示所有以d开头的文件中包含test的行。
grep 'test' aa bb cc 显示在aa,bb,cc文件中匹配test的行。
grep '[a-z]\{5\}' aa 显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
20.查看端口占用情况
netstat -tln | grep 8080 查看端口8080的使用情况
21.查看端口属于哪个程序
lsof -i :8080
23.以树状图列出目录的内容
tree a
用十条命令在一分钟内检查Linux服务器性能
Finding all large files in the root filesystem
http://unix.stackexchange.com/questions/140367/finding-all-large-files-in-the-root-filesystem
find / -xdev -type f -size +100M -exec ls -la {} \; | sort -nk 5
-x Prevent find from descending into directories that have a device number different than that of the file from which the descent began.
This option is equivalent to the deprecated -xdev primary.
ls-command: how to display the file size in megabytes?
ls -lah
-h
When used with the -l option, use unit suffixes: Byte, Kilobyte, Megabyte, Gigabyte, Terabyte and Petabyte in order to reduce the number of digits to three or less using base 2 for sizes.
ls --block-size=M(not in mac) prints the sizes in Megabytes but shows 1MB also for anything below 1 MB. I'm unsure if this option is acceptable in your UNIX version of ls, though.
http://www.infoq.com/cn/news/2015/12/linux-performance
http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
$ uptime 23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02
这个命令可以快速查看机器的负载情况。在Linux系统中,这些数据表示等待CPU资源的进程和阻塞在不可中断IO进程(进程状态为D)的数量。这些数据可以让我们对系统资源使用有一个宏观的了解。
命令的输出分别表示1分钟、5分钟、15分钟的平均负载情况。通过这三个数据,可以了解服务器负载是在趋于紧张还是区域缓解。如果1分钟平均负载很高,而15分钟平均负载很低,说明服务器正在命令高负载情况,需要进一步排查CPU资源都消耗在了哪里。反之,如果15分钟平均负载很高,1分钟平均负载较低,则有可能是CPU资源紧张时刻已经过去。
dmesg | tail
该命令会输出系统日志的最后10行。示例中的输出,可以看见一次内核的oom kill和一次TCP丢包。这些日志可以帮助排查性能问题。千万不要忘了这一步。
https://github.com/jlevy/the-art-of-command-line
http://blog.jobbole.com/90364/
Use
apt-get/yum/dnf/pacman/pip/brew (as appropriate) to install new programs.type
man bash and at least skim the whole thing;learn vi
- Know how to read documentation with
man(for the inquisitive,man manlists the section numbers, e.g. 1 is "regular" commands, 5 is files/conventions, and 8 are for administration). Find man pages withapropos. Know that some commands are not executables, but Bash builtins, and that you can get help on them withhelpandhelp -d.
- Learn about redirection of output and input using
>and<and pipes using|. Know>overwrites the output file and>>appends. Learn about stdout and stderr. - Learn about file glob expansion with
*(and perhaps?and[...]) and quoting and the difference between double"and single'quotes. (See more on variable expansion below.) - Be familiar with Bash job management:
&, ctrl-z, ctrl-c,jobs,fg,bg,kill, etc. - Know
ssh, and the basics of passwordless authentication, viassh-agent,ssh-add, etc. - Basic file management:
lsandls -l(in particular, learn what every column inls -lmeans),less,head,tailandtail -f(or even better,less +F),lnandln -s(learn the differences and advantages of hard versus soft links),chown,chmod,du(for a quick summary of disk usage:du -hs *). For filesystem management,df,mount,fdisk,mkfs,lsblk. Learn what an inode is (ls -iordf -i). - Basic network management:
iporifconfig,dig. - Know regular expressions well, and the various flags to
grep/egrep. The-i,-o,-v,-A,-B, and-Coptions are worth knowing.
Everyday use
- In Bash, use Tab to complete arguments or list all available commands and ctrl-r to search through command history (after pressing, type to search, press ctrl-r repeatedly to cycle through more matches, press Enter to execute the found command, or hit the right arrow to put the result in the current line to allow editing).
- In Bash, use ctrl-w to delete the last word, and ctrl-u to delete all the way back to the start of the line. Use alt-b andalt-f to move by word, ctrl-a to move cursor to beginning of line, ctrl-e to move cursor to end of line, ctrl-k to kill to the end of the line, ctrl-l to clear the screen. See
man readlinefor all the default keybindings in Bash. There are a lot. For example alt-. cycles through previous arguments, and alt-* expands a glob. - Alternatively, if you love vi-style key-bindings, use
set -o vi(andset -o emacsto put it back). - For editing long commands, after setting your editor (for example
export EDITOR=vim), ctrl-x ctrl-e will open the current command in an editor for multi-line editing. Or in vi style, escape-v. - To see recent commands,
history. There are also many abbreviations such as!$(last argument) and!!last command, though these are often easily replaced with ctrl-r and alt-.. - To go back to the previous working directory:
cd - - If you are halfway through typing a command but change your mind, hit alt-# to add a
#at the beginning and enter it as a comment (or use ctrl-a, #, enter). You can then return to it later via command history. - Use
xargs(orparallel). It's very powerful. Note you can control how many items execute per line (-L) as well as parallelism (-P). If you're not sure if it'll do the right thing, usexargs echofirst. Also,-I{}is handy. Examples:
find . -name '*.py' | xargs grep some_function
cat hosts | xargs -I{} ssh root@{} hostname
pstree -pis a helpful display of the process tree.- Use
pgrepandpkillto find or signal processes by name (-fis helpful). - Know the various signals you can send processes. For example, to suspend a process, use
kill -STOP [pid]. For the full list, seeman 7 signal - Use
nohupordisownif you want a background process to keep running forever. - Check what processes are listening via
netstat -lntporss -plat(for TCP; add-ufor UDP). - See also
lsoffor open sockets and files. - See
uptimeorwto know the how long the system has been running. - Use
aliasto create shortcuts for commonly used commands. For example,alias ll='ls -latr'creates a new aliasll. - In Bash scripts, use
set -x(or the variantset -v, which logs raw input, including unexpanded variables and comments) for debugging output. Use strict modes unless you have a good reason not to: Useset -eto abort on errors (nonzero exit code). Useset -uto detect unset variable usages. Considerset -o pipefailtoo, to on errors within pipes, too (though read up on it more if you do, as this topic is a bit subtle). For more involved scripts, also usetrapon EXIT or ERR. A useful habit is to start a script like this, which will make it detect and abort on common errors and print a message:
set -euo pipefail
trap "echo 'error: Script failed: see failed command above'" ERR
- In Bash scripts, subshells (written with parentheses) are convenient ways to group commands. A common example is to temporarily move to a different working directory, e.g.
# do something in current dir
(cd /some/other/dir && other-command)
# continue in original dir
- In Bash, note there are lots of kinds of variable expansion. Checking a variable exists:
${name:?error message}. For example, if a Bash script requires a single argument, just writeinput_file=${1:?usage: $0 input_file}. Arithmetic expansion:i=$(( (i + 1) % 5 )). Sequences:{1..10}. Trimming of strings:${var%suffix}and${var#prefix}. For example ifvar=foo.pdf, thenecho ${var%.pdf}.txtprintsfoo.txt. - Brace expansion using
{...}can reduce having to re-type similar text and automate combinations of items. This is helpful in examples likemv foo.{txt,pdf} some-dir(which moves both files),cp somefile{,.bak}(which expands tocp somefile somefile.bak) ormkdir -p test-{a,b,c}/subtest-{1,2,3}(which expands all possible combinations and creates a directory tree). - The output of a command can be treated like a file via
<(some command). For example, compare local/etc/hostswith a remote one:
diff /etc/hosts <(ssh somehost cat /etc/hosts)
- Know about "here documents" in Bash, as in
cat <<EOF .... - In Bash, redirect both standard output and standard error via:
some-command >logfile 2>&1orsome-command &>logfile. Often, to ensure a command does not leave an open file handle to standard input, tying it to the terminal you are in, it is also good practice to add</dev/null. - Use
man asciifor a good ASCII table, with hex and decimal values. For general encoding info,man unicode,man utf-8, andman latin1are helpful. - Use
screenortmuxto multiplex the screen, especially useful on remote ssh sessions and to detach and re-attach to a session.byobucan enhance screen or tmux providing more information and easier management. A more minimal alternative for session persistence only isdtach. - In ssh, knowing how to port tunnel with
-Lor-D(and occasionally-R) is useful, e.g. to access web sites from a remote server. - It can be useful to make a few optimizations to your ssh configuration; for example, this
~/.ssh/configcontains settings to avoid dropped connections in certain network environments, uses compression (which is helpful with scp over low-bandwidth connections), and multiplex channels to the same server with a local control file:
TCPKeepAlive=yes
ServerAliveInterval=15
ServerAliveCountMax=6
Compression=yes
ControlMaster auto
ControlPath /tmp/%r@%h:%p
ControlPersist yes
- A few other options relevant to ssh are security sensitive and should be enabled with care, e.g. per subnet or host or in trusted networks:
StrictHostKeyChecking=no,ForwardAgent=yes - Consider
moshan alternative to ssh that uses UDP, avoiding dropped connections and adding convenience on the road (requires server-side setup). - To get the permissions on a file in octal form, which is useful for system configuration but not available in
lsand easy to bungle, use something like
stat -c '%A %a %n' /etc/timezone
- For a simple web server for all files in the current directory (and subdirs), available to anyone on your network, use:
python -m SimpleHTTPServer 7777(for port 7777 and Python 2) andpython -m http.server 7777(for port 7777 and Python 3). - For running a command with privileges, use
sudo(for root) orsudo -u(for another user). Usesuorsudo bashto actually run a shell as that user. Usesu -to simulate a fresh login as root or another user.
Processing files and data
- To locate a file by name in the current directory,
find . -iname '*something*'(or similar). To find a file anywhere by name, uselocate something(but bear in mindupdatedbmay not have indexed recently created files). - For general searching through source or data files (more advanced than
grep -r), useag. - To convert HTML to text:
lynx -dump -stdin - For Markdown, HTML, and all kinds of document conversion, try
pandoc. - If you must handle XML,
xmlstarletis old but good. - For JSON, use
jq. - For YAML, use
shyaml. - Know about
sortanduniq, including uniq's-uand-doptions -- see one-liners below. See alsocomm. - Know about
cut,paste, andjointo manipulate text files. Many people usecutbut forget aboutjoin. - Know about
wcto count newlines (-l), characters (-m), words (-w) and bytes (-c). - Know about
teeto copy from stdin to a file and also to stdout, as inls -al | tee file.txt. - Know that locale affects a lot of command line tools in subtle ways, including sorting order (collation) and performance. Most Linux installations will set
LANGor other locale variables to a local setting like US English. But be aware sorting will change if you change locale. And know i18n routines can make sort or other commands run many times slower. In some situations (such as the set operations or uniqueness operations below) you can safely ignore slow i18n routines entirely and use traditional byte-based sort order, usingexport LC_ALL=C. - Know basic
awkandsedfor simple data munging. For example, summing all numbers in the third column of a text file:awk '{ x += $3 } END { print x }'. This is probably 3X faster and 3X shorter than equivalent Python. - To replace all occurrences of a string in place, in one or more files:
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
- To rename multiple files and/or search and replace within files, try
repren. (In some cases therenamecommand also allows multiple renames, but be careful as its functionality is not the same on all Linux distributions.)
# Full rename of filenames, directories, and contents foo -> bar:
repren --full --preserve-case --from foo --to bar .
# Recover backup files whatever.bak -> whatever:
repren --renames --from '(.*)\.bak' --to '\1' *.bak
# Same as above, using rename, if available:
rename 's/\.bak$//' *.bak
- As the man page says,
rsyncreally is a fast and extraordinarily versatile file copying tool. It's known for synchronizing between machines but is equally useful locally. It also is among the fastest ways to delete large numbers of files:
mkdir empty && rsync -r --delete empty/ some-dir && rmdir some-dir
- Use
shufto shuffle or select random lines from a file. - Know
sort's options. For numbers, use-n, or-hfor handling human-readable numbers (e.g. fromdu -h). Know how keys work (-tand-k). In particular, watch out that you need to write-k1,1to sort by only the first field;-k1means sort according to the whole line. Stable sort (sort -s) can be useful. For example, to sort first by field 2, then secondarily by field 1, you can usesort -k1,1 | sort -s -k2,2. - If you ever need to write a tab literal in a command line in Bash (e.g. for the -t argument to sort), press ctrl-v [Tab] or write
$'\t'(the latter is better as you can copy/paste it). - The standard tools for patching source code are
diffandpatch. See alsodiffstatfor summary statistics of a diff andsdifffor a side-by-side diff. Notediff -rworks for entire directories. Usediff -r tree1 tree2 | diffstatfor a summary of changes. Usevimdiffto compare and edit files. - For binary files, use
hd,hexdumporxxdfor simple hex dumps andbviorbiewfor binary editing. - Also for binary files,
strings(plusgrep, etc.) lets you find bits of text. - For binary diffs (delta compression), use
xdelta3. - To convert text encodings, try
iconv. Oruconvfor more advanced use; it supports some advanced Unicode things. For example, this command lowercases and removes all accents (by expanding and dropping them):
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
- To split files into pieces, see
split(to split by size) andcsplit(to split by a pattern). - Use
zless,zmore,zcat, andzgrepto operate on compressed files.
System debugging
- For web debugging,
curlandcurl -Iare handy, or theirwgetequivalents, or the more modernhttpie. - To know current cpu/disk status, the classic tools are
top(or the betterhtop),iostat, andiotop. Useiostat -mxz 15for basic CPU and detailed per-partition disk stats and performance insight. - For network connection details, use
netstatandss. - For a quick overview of what's happening on a system,
dstatis especially useful. For broadest overview with details, useglances. - To know memory status, run and understand the output of
freeandvmstat. In particular, be aware the "cached" value is memory held by the Linux kernel as file cache, so effectively counts toward the "free" value. - Java system debugging is a different kettle of fish, but a simple trick on Oracle's and some other JVMs is that you can run
kill -3 <pid>and a full stack trace and heap summary (including generational garbage collection details, which can be highly informative) will be dumped to stderr/logs. The JDK'sjps,jstat,jstack,jmapare useful. SJK toolsare more advanced. - Use
mtras a better traceroute, to identify network issues. - For looking at why a disk is full,
ncdusaves time over the usual commands likedu -sh *. - To find which socket or process is using bandwidth, try
iftopornethogs. - The
abtool (comes with Apache) is helpful for quick-and-dirty checking of web server performance. For more complex load testing, trysiege. - For more serious network debugging,
wireshark,tshark, orngrep. - Know about
straceandltrace. These can be helpful if a program is failing, hanging, or crashing, and you don't know why, or if you want to get a general idea of performance. Note the profiling option (-c), and the ability to attach to a running process (-p). - Know about
lddto check shared libraries etc. - Know how to connect to a running process with
gdband get its stack traces. - Use
/proc. It's amazingly helpful sometimes when debugging live problems. Examples:/proc/cpuinfo,/proc/meminfo,/proc/cmdline,/proc/xxx/cwd,/proc/xxx/exe,/proc/xxx/fd/,/proc/xxx/smaps(wherexxxis the process id or pid). - When debugging why something went wrong in the past,
sarcan be very helpful. It shows historic statistics on CPU, memory, network, etc. - Check what OS you're on with
unameoruname -a(general Unix/kernel info) orlsb_release -a(Linux distro info). - Use
dmesgwhenever something's acting really funny (it could be hardware or driver issues).
One-liners
A few examples of piecing together commands:
- It is remarkably helpful sometimes that you can do set intersection, union, and difference of text files via
sort/uniq. Supposeaandbare text files that are already uniqued. This is fast, and works on files of arbitrary size, up to many gigabytes. (Sort is not limited by memory, though you may need to use the-Toption if/tmpis on a small root partition.) See also the note aboutLC_ALLabove andsort's-uoption (left out for clarity below).
cat a b | sort | uniq > c # c is a union b
cat a b | sort | uniq -d > c # c is a intersect b
cat a b b | sort | uniq -u > c # c is set difference a - b
- Use
grep . *to quickly examine the contents of all files in a directory (so each line is paired with the filename), orhead -100 *(so each file has a heading). This can be useful for directories filled with config settings like those in/sys,/proc,/etc. - Summing all numbers in the third column of a text file (this is probably 3X faster and 3X less code than equivalent Python):
awk '{ x += $3 } END { print x }' myfile
- If want to see sizes/dates on a tree of files, this is like a recursive
ls -lbut is easier to read thanls -lR:
find . -type f -ls
- Say you have a text file, like a web server log, and a certain value that appears on some lines, such as an
acct_idparameter that is present in the URL. If you want a tally of how many requests for eachacct_id:
cat access.log | egrep -o 'acct_id=[0-9]+' | cut -d= -f2 | sort | uniq -c | sort -rn
- To continuously monitor changes, use
watch, e.g. check changes to files in a directory withwatch -d -n 2 'ls -rtlh | tail'or to network settings while troubleshooting your wifi settings withwatch -d -n 2 ifconfig. - Run this function to get a random tip from this document (parses Markdown and extracts an item):
function taocl() {
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README.md |
pandoc -f markdown -t html |
xmlstarlet fo --html --dropdtd |
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
xmlstarlet unesc | fmt -80
}
Obscure but useful
expr: perform arithmetic or boolean operations or evaluate regular expressionsm4: simple macro processoryes: print a string a lotcal: nice calendarenv: run a command (useful in scripts)printenv: print out environment variables (useful in debugging and scripts)look: find English words (or lines in a file) beginning with a stringcut,pasteandjoin: data manipulationfmt: format text paragraphspr: format text into pages/columnsfold: wrap lines of textcolumn: format text fields into aligned, fixed-width columns or tablesexpandandunexpand: convert between tabs and spacesnl: add line numbersseq: print numbersbc: calculatorfactor: factor integersgpg: encrypt and sign filestoe: table of terminfo entriesnc: network debugging and data transfersocat: socket relay and tcp port forwarder (similar tonetcat)slurm: network traffic visualizationdd: moving data between files or devicesfile: identify type of a filetree: display directories and subdirectories as a nesting tree; likelsbut recursivestat: file infotime: execute and time a commandtimeout: execute a command for specified amount of time and stop the process when the specified amount of time completes.lockfile: create semaphore file that can only be removed byrm -flogrotate: rotate, compress and mail logs.watch: run a command repeatedly, showing results and/or highlighting changestac: print files in reverseshuf: random selection of lines from a filecomm: compare sorted files line by linepv: monitor the progress of data through a pipehd,hexdump,xxd,biewandbvi: dump or edit binary filesstrings: extract text from binary filestr: character translation or manipulationiconvoruconv: conversion for text encodingssplitandcsplit: splitting filessponge: read all input before writing it, useful for reading from then writing to the same file, e.g.,grep -v something some-file | sponge some-fileunits: unit conversions and calculations; converts furlongs per fortnight to twips per blink (see also/usr/share/units/definitions.units)apg: generates random passwords7z: high-ratio file compressionldd: dynamic library infonm: symbols from object filesab: benchmarking web serversstrace: system call debuggingmtr: better traceroute for network debuggingcssh: visual concurrent shellrsync: sync files and folders over SSH or in local file systemwiresharkandtshark: packet capture and network debuggingngrep: grep for the network layerhostanddig: DNS lookupslsof: process file descriptor and socket infodstat: useful system statsglances: high level, multi-subsystem overviewiostat: Disk usage statsmpstat: CPU usage statsvmstat: Memory usage statshtop: improved version of toplast: login historyw: who's logged onid: user/group identity infosar: historic system statsiftopornethogs: network utilization by socket or processss: socket statisticsdmesg: boot and system error messagessysctl: view and configure Linux kernel parameters at run timehdparm: SATA/ATA disk manipulation/performancelsb_release: Linux distribution infolsblk: list block devices: a tree view of your disks and disk paritionslshw,lscpu,lspci,lsusb,dmidecode: hardware information, including CPU, BIOS, RAID, graphics, devices, etc.lsmodandmodinfo: List and show details of kernel modules.fortune,ddate, andsl: um, well, it depends on whether you consider steam locomotives and Zippy quotations "useful"
MacOS X only
These are items relevant only on MacOS.
- Package management with
brew(Homebrew) and/orport(MacPorts). These can be used to install on MacOS many of the above commands. - Copy output of any command to a desktop app with
pbcopyand paste input from one withpbpaste. - To enable the Option key in Mac OS Terminal as an alt key (such as used in the commands above like alt-b, alt-f, etc.), open Preferences -> Profiles -> Keyboard and select "Use Option as Meta key".
- To open a file with a desktop app, use
openoropen -a /Applications/Whatever.app. - Spotlight: Search files with
mdfindand list metadata (such as photo EXIF info) withmdls. - Be aware MacOS is based on BSD Unix, and many commands (for example
ps,ls,tail,awk,sed) have many subtle variations from Linux, which is largely influenced by System V-style Unix and GNU tools. You can often tell the difference by noting a man page has the heading "BSD General Commands Manual." In some cases GNU versions can be installed, too (such asgawkandgsedfor GNU awk and sed). If writing cross-platform Bash scripts, avoid such commands (for example, consider Python orperl) or test carefully. - To get MacOS release information, use
sw_vers.
http://unix.stackexchange.com/questions/108174/how-to-persist-ulimit-settings-in-osx-mavericks
The limits set via
ulimit only affects processes created by the current shell session. The "soft limit" is the actual limit that is used. It could be set, as far as it is not greater than the "hard limit". The "hard limit" could also be set, but only to a value less than the current one, and only to a value not less than the "soft limit". The "hard limit", as well as system-wide limits, could be raised by root (the administrator) by executing system configuration commands or modifying system configuration files.
After you terminate the shell session (by
Ctrl-D, exit, or closing the Terminal.app window, etc.), the settings are gone. If you want the same setting in the next shell session, add the setting to the shell startup script. If you are using bash, then it should be ~/.bash_proile or ~/.bash_login. If you are using other shells, it should probably be ~/.profile.1. Linux Fork Bomb Command
:(){ :|: & };: also known as Fork Bomb is a denial-of-service attack against a Linux System. :(){ :|: & };: is a bash function. Once executed, it repeats itself multiple times until the system freezes.
You can only get rid of it by restarting your system. So be careful when executing this command on your Linux shell.
Decompression Bomb
Tar Bomb
It is an archive file which explodes into thousands or millions of files with names similar to the existing files into the current directory rather than into a new directory when untarred.
在你开始你的别名体验之旅前,这里有一个便于使用的小技巧:如果你的别名和原本的命令名字相同,你可以用如下技巧来访问原本的命令(LCTT 译注:你也可以直接原本命令的完整路径来访问它。)
\command
例如,如果有一个替换了ls命令的别名 ls。如果你想使用原本的ls命令而不是别名,通过调用它:
\ls
alias grep='grep --color=auto'
类似,只是在grep里输出带上颜色。
mcd() { mkdir -p "$1"; cd "$1";}
我的最爱之一。创建一个目录并进入该目录里: mcd [目录名]。
cls() { cd "$1"; ls;}
类似上一个函数,进入一个目录并列出它的的内容:cls[目录名]。
backup() { cp "$1"{,.bak};}
alias ..='cd ..'
回到上层目录还需要输入 cd 吗?
alias ...='cd ../..'
自然,去到上两层目录。