https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying

One of the most useful things I learned in all this was that many of the things we were building had a very simple concept at their heart: the log. Sometimes called write-ahead logs or commit logs or transaction logs, logs have been around almost as long as computers and are at the heart of many distributed data systems and real-time application architectures.
Part One: What Is a Log?
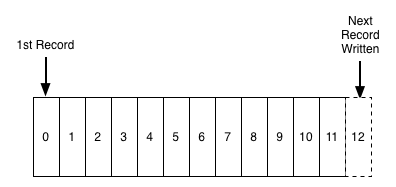
A log is perhaps the simplest possible storage abstraction. It is an append-only, totally-ordered sequence of records ordered by time. It looks like this:
Records are appended to the end of the log, and reads proceed left-to-right. Each entry is assigned a unique sequential log entry number.
The ordering of records defines a notion of "time" since entries to the left are defined to be older then entries to the right. The log entry number can be thought of as the "timestamp" of the entry. Describing this ordering as a notion of time seems a bit odd at first, but it has the convenient property that it is decoupled from any particular physical clock. This property will turn out to be essential as we get to distributed systems.
So, a log is not all that different from a file or a table. A file is an array of bytes, a table is an array of records, and a log is really just a kind of table or file where the records are sorted by time.
logs have a specific purpose: they record what happened and when. For distributed data systems this is, in many ways, the very heart of the problem.
The application log is a degenerative form of the log concept I am describing. The biggest difference is that text logs are meant to be primarily for humans to read and the "journal" or "data logs" I'm describing are built for programmatic access.
(Actually, if you think about it, the idea of humans reading through logs on individual machines is something of an anachronism. This approach quickly becomes an unmanageable strategy when many services and servers are involved and the purpose of logs quickly becomes as an input to queries and graphs to understand behavior across many machines—something for which english text in files is not nearly as appropriate as the kind structured log described here.)
Logs in databases
It is present as early as IBM's System R. The usage in databases has to do with keeping in sync the variety of data structures and indexes in the presence of crashes. To make this atomic and durable, a database uses a log to write out information about the records they will be modifying, before applying the changes to all the various data structures it maintains. The log is the record of what happened, and each table or index is a projection of this history into some useful data structure or index. Since the log is immediately persisted it is used as the authoritative source in restoring all other persistent structures in the event of a crash.
Over-time the usage of the log grew from an implementation detail of ACID to a method for replicating data between databases. It turns out that the sequence of changes that happened on the database is exactly what is needed to keep a remote replica database in sync. Oracle, MySQL, and PostgreSQL include log shipping protocols to transmit portions of log to replica databases which act as slaves. Oracle has productized the log as a general data subscription mechanism for non-oracle data subscribers with their XStreamsand GoldenGate and similar facilities in MySQL and PostgreSQL are key components of many data architectures.
Logs in distributed systems
The two problems a log solves—ordering changes and distributing data—are even more important in distributed data systems. Agreeing upon an ordering for updates (or agreeing to disagree and coping with the side-effects) are among the core design problems for these systems.
The log-centric approach to distributed systems arises from a simple observation that I will call the State Machine Replication Principle:
If two identical, deterministic processes begin in the same state and get the same inputs in the same order, they will produce the same output and end in the same state.
Deterministic means that the processing isn't timing dependent and doesn't let any other "out of band" input influence its results. For example a program whose output is influenced by the particular order of execution of threads or by a call to
gettimeofday or some other non-repeatable thing is generally best considered as non-deterministic.
The state of the process is whatever data remains on the machine, either in memory or on disk, at the end of the processing.
The bit about getting the same input in the same order should ring a bell—that is where the log comes in. This is a very intuitive notion: if you feed two deterministic pieces of code the same input log, they will produce the same output.
The application to distributed computing is pretty obvious. You can reduce the problem of making multiple machines all do the same thing to the problem of implementing a distributed consistent log to feed these processes input. The purpose of the log here is to squeeze all the non-determinism out of the input stream to ensure that each replica processing this input stays in sync.
One of the beautiful things about this approach is that the time stamps that index the log now act as the clock for the state of the replicas—you can describe each replica by a single number, the timestamp for the maximum log entry it has processed. This timestamp combined with the log uniquely captures the entire state of the replica.
There are a multitude of ways of applying this principle in systems depending on what is put in the log. For example, we can log the incoming requests to a service, or the state changes the service undergoes in response to request, or the transformation commands it executes. Theoretically, we could even log a series of machine instructions for each replica to execute or the method name and arguments to invoke on each replica. As long as two processes process these inputs in the same way, the processes will remaining consistent across replicas.
Different groups of people seem to describe the uses of logs differently. Database people generally differentiate between physical and logical logging. Physical logging means logging the contents of each row that is changed. Logical logging means logging not the changed rows but the SQL commands that lead to the row changes (the insert, update, and delete statements).
The distributed systems literature commonly distinguishes two broad approaches to processing and replication. The "state machine model" usually refers to an active-active model where we keep a log of the incoming requests and each replica processes each request. A slight modification of this, called the "primary-backup model", is to elect one replica as the leader and allow this leader to process requests in the order they arrive and log out the changes to its state from processing the requests. The other replicas apply in order the state changes the leader makes so that they will be in sync and ready to take over as leader should the leader fail.
To understand the difference between these two approaches, let's look at a toy problem. Consider a replicated "arithmetic service" which maintains a single number as its state (initialized to zero) and applies additions and multiplications to this value. The active-active approach might log out the transformations to apply, say "+1", "*2", etc. Each replica would apply these transformations and hence go through the same set of values. The "active-passive" approach would have a single master execute the transformations and log out theresult, say "1", "3", "6", etc. This example also makes it clear why ordering is key for ensuring consistency between replicas: reordering an addition and multiplication will yield a different result
The distributed log can be seen as the data structure which models the problem of consensus. A log, after all, represents a series of decisions on the "next" value to append. You have to squint a little to see a log in the Paxos family of algorithms, though log-building is their most common practical application. With Paxos, this is usually done using an extension of the protocol called "multi-paxos", which models the log as a series of consensus problems, one for each slot in the log. The log is much more prominent in other protocols such as ZAB, RAFT, and Viewstamped Replication, which directly model the problem of maintaining a distributed, consistent log.