https://puncsky.com/hacking-the-software-engineer-interview#designing-uber-or-a-realtime-marketplace
http://www.mitbbs.com/article_t/JobHunting/33027343.html
Level 1 乘客跟司机应该更重视哪边?(乘客)
Level 2 如何缩短乘客等待时间?(司机十秒抢单机制v.s. queue)
Level 3 乘客叫车流程:
request with location,
ack & profile dispatch,
ETA,
picked up confirmation (driver side),
routing (A*),
arrival confirmation,
credit card processing,
feedback loop,
receipt email trigger,
coupon and promotion,
refund and dispute,
rider request cancellation,
driver rating,
peak hour fare surge (machine learning)
Level 4
4.1 Nearest Drivers algorithm: Zoning and confinement? Distance
calculation? Geohash approximation? KD-tree sorting?
4.2 Driver ETA, location update intervals, estimate and delays.
4.3 Parallelism: Multi riders v.s. multi drivers
.....
Level 5
5.1 Latency requirement between any two components
5.2 User data and cache retention policy
5.3 Data warehouse failover policy
5.4 Localized data warehouses communication (e.g. Europe vs North America)
....
好歹把high level architecture/都有哪些模块,各自负责什么功能说一下再细化吧
另外最后这个EU/NA数据通信打算做什么用?
在职刷题 + System Design + 面试准备的路上
System Design:
How to design Uber:
今天白板了一遍Design Uber, 其workflow为Driver ->report their location every 4s -> Dispatch service -> update location information with 4,5,6 length of Geohash in Location Table(Redis) -> check if there is assigned trip id in Driver Table -> Retrieve Trip information from Trip Table in Dispatch Server -> Driver Accept/Deny/Cancel trip -> Update status in Trip Table in Dispatch Server and Driver Table in Geo Server -> Returned matched user to driver and matched driver to user.
这里User Table 和 Trip Table (trip_id, driver_id, user_id, latitude, longitude, status, created_at) 在Dispatch Server 里为SQL, Location Table (key: geohash, value: set of driver_id) 和 Driver Table(driver_id, lati, longi, status, trip_id, updated_at)为NoSQL使用Redis或者Cassandra. 使用NoSql是因为写操作要求更多,需要不断更新location.
Uber使用的定位存储是Google S2,但为了方便理解,使用Geohash来替代。Geohash以base32通过把经纬度横竖划分不断精确,就比如把世界分为32份,每份再分32份,这样不断分割,精度越来越高,同一个地区的两点其prefix相同的也更多.这就方便去查找user附近的driver,通过把地点的prefix存为4,5,6位来划分20km,2.5km,0.5km范围内来找出附近的driver。 每次司机通过heartbeat的方式每4秒上报一次自己的位置,顺便拿一下是否有附近user的request.
今天白板了一遍Design Uber, 其workflow为Driver ->report their location every 4s -> Dispatch service -> update location information with 4,5,6 length of Geohash in Location Table(Redis) -> check if there is assigned trip id in Driver Table -> Retrieve Trip information from Trip Table in Dispatch Server -> Driver Accept/Deny/Cancel trip -> Update status in Trip Table in Dispatch Server and Driver Table in Geo Server -> Returned matched user to driver and matched driver to user. 这里User Table 和 Trip Table (trip_id, driver_id, user_id, latitude, longitude, status, created_at) 在Dispatch Server 里为SQL, Location Table (key: geohash, value: set of driver_id) 和 Driver Table(driver_id, lati, longi, status, trip_id, updated_at)为NoSQL使用Redis或者Cassandra. 使用NoSql是因为写操作要求更多,需要不断更新location
Requirements
- ride hailing service targeting the transportation markets around the world
- realtime dispatch in massive scale
- backend design
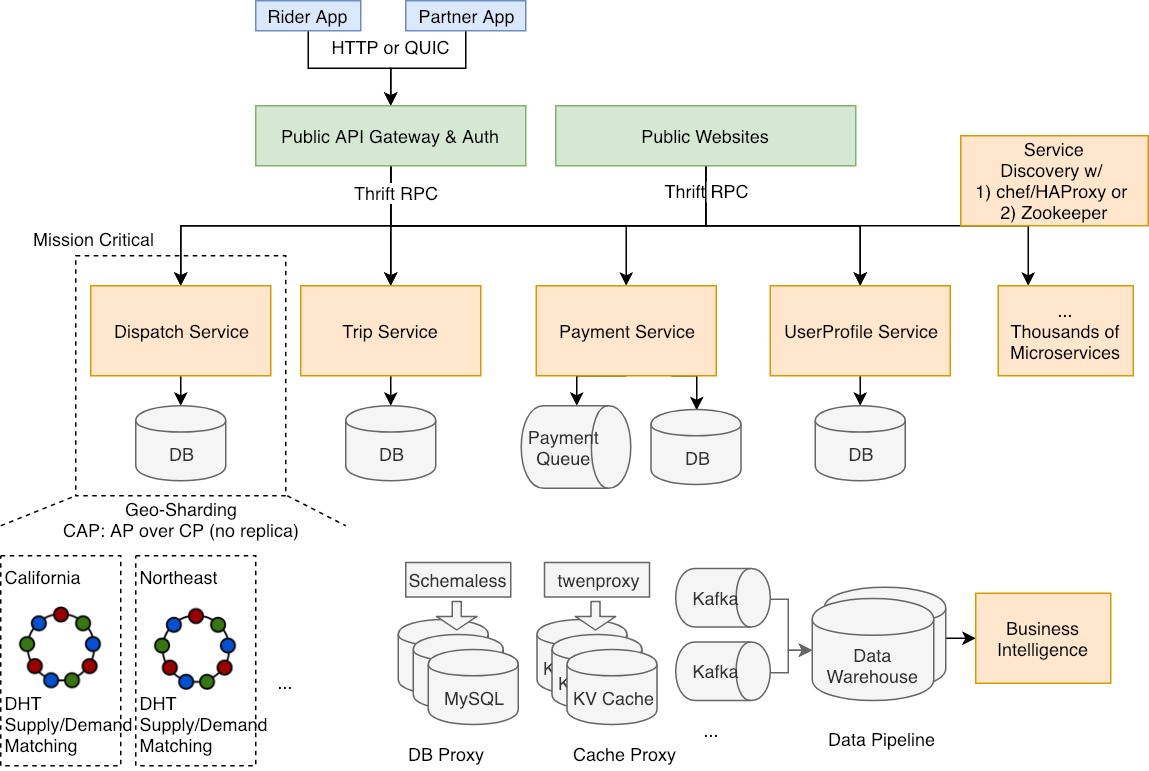
Architecture
Why micro services?
Conway’s law says structures of software systems are copies of the organization structures.
| Monolithic Service | Micro Services | |
|---|---|---|
| Productivity, when teams and codebases are small | ✅ High | ❌ Low |
| Productivity, when teams and codebases are large | ❌ Low | ✅ High (Conway’s law) |
| Requirements on Engineering Quality | ❌ High (under-qualified devs break down the system easily) | ✅ Low (runtimes are segregated) |
| Dependency Bump | ✅ Fast (centrally managed) | ❌ Slow |
| Multi-tenancy support / Production-staging Segregation | ✅ Easy | ❌ Hard (each individual service has to either 1) build staging env connected to others in staging 2) Multi-tenancy support across the request contexts and data storage) |
| Debuggability, assuming same modules, metrics, logs | ❌ Low | ✅ High (w/ distributed tracing) |
| Latency | ✅ Low (local) | ❌ High (remote) |
| DevOps Costs | ✅ Low (High on building tools) | ❌ High (capacity planning is hard) |
Combining monolithic codebase and micro services can bring benefits from both sides.
Dispatch Service
- consistent hashing sharded by geohash
- data is transient, in memory, and thus there is no need to replicate. (CAP: AP over CP)
- single-threaded or locked matching in a shard to prevent double dispatching
Payment Service
The key is to have an async design, because payment systems usually have a very long latency for ACID transactions across multiple systems.
- leverage event queues
- payment gateway w/ Braintree, PayPal, Card.io, Alipay, etc.
- logging intensively to track everything
- APIs with idempotency, exponential backoff, and random jitter
UserProfile Service and Trip Service
- low latency with caching
- UserProfile Service has the challenge to serve users in increasing types (driver, rider, restaurant owner, eater, etc) and user schemas in different regions and countries.
Push Notification Service
- Apple Push Notifications Service (not quite reliable)
- Google Cloud Messaging Service GCM (it can detect the deliverability) or
- SMS service is usually more reliable
http://www.mitbbs.com/article_t/JobHunting/33027343.html
Level 1 乘客跟司机应该更重视哪边?(乘客)
Level 2 如何缩短乘客等待时间?(司机十秒抢单机制v.s. queue)
Level 3 乘客叫车流程:
request with location,
ack & profile dispatch,
ETA,
picked up confirmation (driver side),
routing (A*),
arrival confirmation,
credit card processing,
feedback loop,
receipt email trigger,
coupon and promotion,
refund and dispute,
rider request cancellation,
driver rating,
peak hour fare surge (machine learning)
Level 4
4.1 Nearest Drivers algorithm: Zoning and confinement? Distance
calculation? Geohash approximation? KD-tree sorting?
4.2 Driver ETA, location update intervals, estimate and delays.
4.3 Parallelism: Multi riders v.s. multi drivers
.....
Level 5
5.1 Latency requirement between any two components
5.2 User data and cache retention policy
5.3 Data warehouse failover policy
5.4 Localized data warehouses communication (e.g. Europe vs North America)
....
好歹把high level architecture/都有哪些模块,各自负责什么功能说一下再细化吧
另外最后这个EU/NA数据通信打算做什么用?
在职刷题 + System Design + 面试准备的路上
System Design:
How to design Uber:
今天白板了一遍Design Uber, 其workflow为Driver ->report their location every 4s -> Dispatch service -> update location information with 4,5,6 length of Geohash in Location Table(Redis) -> check if there is assigned trip id in Driver Table -> Retrieve Trip information from Trip Table in Dispatch Server -> Driver Accept/Deny/Cancel trip -> Update status in Trip Table in Dispatch Server and Driver Table in Geo Server -> Returned matched user to driver and matched driver to user.
这里User Table 和 Trip Table (trip_id, driver_id, user_id, latitude, longitude, status, created_at) 在Dispatch Server 里为SQL, Location Table (key: geohash, value: set of driver_id) 和 Driver Table(driver_id, lati, longi, status, trip_id, updated_at)为NoSQL使用Redis或者Cassandra. 使用NoSql是因为写操作要求更多,需要不断更新location.
Uber使用的定位存储是Google S2,但为了方便理解,使用Geohash来替代。Geohash以base32通过把经纬度横竖划分不断精确,就比如把世界分为32份,每份再分32份,这样不断分割,精度越来越高,同一个地区的两点其prefix相同的也更多.这就方便去查找user附近的driver,通过把地点的prefix存为4,5,6位来划分20km,2.5km,0.5km范围内来找出附近的driver。 每次司机通过heartbeat的方式每4秒上报一次自己的位置,顺便拿一下是否有附近user的request.
今天白板了一遍Design Uber, 其workflow为Driver ->report their location every 4s -> Dispatch service -> update location information with 4,5,6 length of Geohash in Location Table(Redis) -> check if there is assigned trip id in Driver Table -> Retrieve Trip information from Trip Table in Dispatch Server -> Driver Accept/Deny/Cancel trip -> Update status in Trip Table in Dispatch Server and Driver Table in Geo Server -> Returned matched user to driver and matched driver to user. 这里User Table 和 Trip Table (trip_id, driver_id, user_id, latitude, longitude, status, created_at) 在Dispatch Server 里为SQL, Location Table (key: geohash, value: set of driver_id) 和 Driver Table(driver_id, lati, longi, status, trip_id, updated_at)为NoSQL使用Redis或者Cassandra. 使用NoSql是因为写操作要求更多,需要不断更新location