https://github.com/JerryLead/SparkInternals/tree/master/EnglishVersion
https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
Spark Datasets, an extension of the DataFrame API that provides a type-safe, object-oriented programming interface
Spark Datasets, an extension of the DataFrame API that provides a type-safe, object-oriented programming interface. Spark 1.6 includes an API preview of Datasets, and they will be a development focus for the next several versions of Spark. Like DataFrames, Datasets take advantage of Spark’s Catalyst optimizer by exposing expressions and data fields to a query planner. Datasets also leverage Tungsten’s fast in-memory encoding. Datasets extend these benefits with compile-time type safety – meaning production applications can be checked for errors before they are r
A Dataset is a strongly-typed, immutable collection of objects that are mapped to a relational schema. At the core of the Dataset API is a new concept called an encoder, which is responsible for converting between JVM objects and tabular representation. The tabular representation is stored using Spark’s internal Tungsten binary format, allowing for operations on serialized data and improved memory utilization
Dataset encoders provide more information to Spark about the data being stored, the cached representation can be optimized to use 4.5x less space.
df.filter("age > 21");
The Dataset API aims to provide the best of both worlds; the familiar object-oriented programming style and compile-time type-safety of the RDD API but with the performance benefits of the Catalyst query optimizer. Datasets also use the same efficient off-heap storage mechanism as the DataFrame API.
When it comes to serializing data, the Dataset API has the concept of encoders which translate between JVM representations (objects) and Spark’s internal binary format. Spark has built-in encoders which are very advanced in that they generate byte code to interact with off-heap data and provide on-demand access to individual attributes without having to de-serialize an entire object.
https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
In 2.0, DataFrame APIs will merge with Datasets APIs, unifying data processing capabilities across libraries. Because of this unification, developers now have fewer concepts to learn or remember, and work with a single high-level and type-safe API called Dataset.
http://datastrophic.io/core-concepts-architecture-and-internals-of-apache-spark/
Spark is a generalized framework for distributed data processing providing functional API for manipulating data at scale, in-memory data caching and reuse across computations. It applies set of coarse-grained transformations over partitioned data and relies on dataset's lineage to recompute tasks in case of failures. Worth mentioning is that Spark supports majority of data formats, has integrations with various storage systems and can be executed on Mesos or YARN.
 Spark Application (often referred to as Driver Program or Application Master) at high level consists of SparkContext and user code which interacts with it creating RDDs and performing series of transformations to achieve final result. These transformations of RDDs are then translated into DAG and submitted to Scheduler to be executed on set of worker nodes.
Spark Application (often referred to as Driver Program or Application Master) at high level consists of SparkContext and user code which interacts with it creating RDDs and performing series of transformations to achieve final result. These transformations of RDDs are then translated into DAG and submitted to Scheduler to be executed on set of worker nodes.
The dependencies are usually classified as "narrow" and "wide":


Programming Spark: RDD 本质论
https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
Java objects have a large inherent memory overhead. Consider a simple string “abcd” that would take 4 bytes to store using UTF-8 encoding.
It encodes each character using 2 bytes with UTF-16 encoding, and each String object also contains a 12 byte header and 8 byte hash code
Spark understands how data flows through various stages of computation and the scope of jobs and tasks. As a result, Spark knows much more information than the JVM garbage collector about the life cycle of memory blocks, and thus should be able to manage memory more efficiently than the JVM.
2. Cache-aware Computation
3. Code Generation
https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
Spark Datasets, an extension of the DataFrame API that provides a type-safe, object-oriented programming interface
Spark Datasets, an extension of the DataFrame API that provides a type-safe, object-oriented programming interface. Spark 1.6 includes an API preview of Datasets, and they will be a development focus for the next several versions of Spark. Like DataFrames, Datasets take advantage of Spark’s Catalyst optimizer by exposing expressions and data fields to a query planner. Datasets also leverage Tungsten’s fast in-memory encoding. Datasets extend these benefits with compile-time type safety – meaning production applications can be checked for errors before they are r
A Dataset is a strongly-typed, immutable collection of objects that are mapped to a relational schema. At the core of the Dataset API is a new concept called an encoder, which is responsible for converting between JVM objects and tabular representation. The tabular representation is stored using Spark’s internal Tungsten binary format, allowing for operations on serialized data and improved memory utilization
RDDs
|
Datasets
|
|
Datasets
|
- case class University(name: String, numStudents: Long, yearFounded: Long)
- val schools = sqlContext.read.json("/schools.json").as[University]
- schools.map(s => s"${s.name} is ${2015 – s.yearFounded} years old")
Encoders eagerly check that your data matches the expected schema, providing helpful error messages before you attempt to incorrectly process TBs of data.
- Dataset<University> schools = context.read().json("/schools.json").as(Encoders.bean(University.class));
- Dataset<String> strings = schools.map(new BuildString(), Encoders.STRING());
- http://www.agildata.com/apache-spark-rdd-vs-dataframe-vs-dataset/
rdd.filter(_.age > 21) // transformation
.map(_.last) // transformation
.saveAsObjectFile("under21.bin") // action
1
|
rdd.filter(_.age > 21)
|
df.filter("age > 21");
The Dataset API aims to provide the best of both worlds; the familiar object-oriented programming style and compile-time type-safety of the RDD API but with the performance benefits of the Catalyst query optimizer. Datasets also use the same efficient off-heap storage mechanism as the DataFrame API.
When it comes to serializing data, the Dataset API has the concept of encoders which translate between JVM representations (objects) and Spark’s internal binary format. Spark has built-in encoders which are very advanced in that they generate byte code to interact with off-heap data and provide on-demand access to individual attributes without having to de-serialize an entire object.
https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
When to use RDDs?
Consider these scenarios or common use cases for using RDDs when:
- you want low-level transformation and actions and control on your dataset;
- your data is unstructured, such as media streams or streams of text;
- you want to manipulate your data with functional programming constructs than domain specific expressions;
- you don’t care about imposing a schema, such as columnar format, while processing or accessing data attributes by name or column; and
- you can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
DataFrames and Datasets are built on top of RDDs.
DataFrame allows developers to impose a structure onto a distributed collection of data, allowing higher-level abstraction; it provides a domain specific language API to manipulate your distributed dataIn 2.0, DataFrame APIs will merge with Datasets APIs, unifying data processing capabilities across libraries. Because of this unification, developers now have fewer concepts to learn or remember, and work with a single high-level and type-safe API called Dataset.
Starting in Spark 2.0, Dataset takes on two distinct APIs characteristics: a strongly-typed API and an untyped API, as shown in the table below. Conceptually, consider DataFrame as an alias for a collection of generic objects Dataset[Row], where a Row is a generic untyped JVM object. Dataset, by contrast, is a collection of strongly-typed JVM objects, dictated by a case class you define in Scala or a class in Java.
Benefits of Dataset APIs
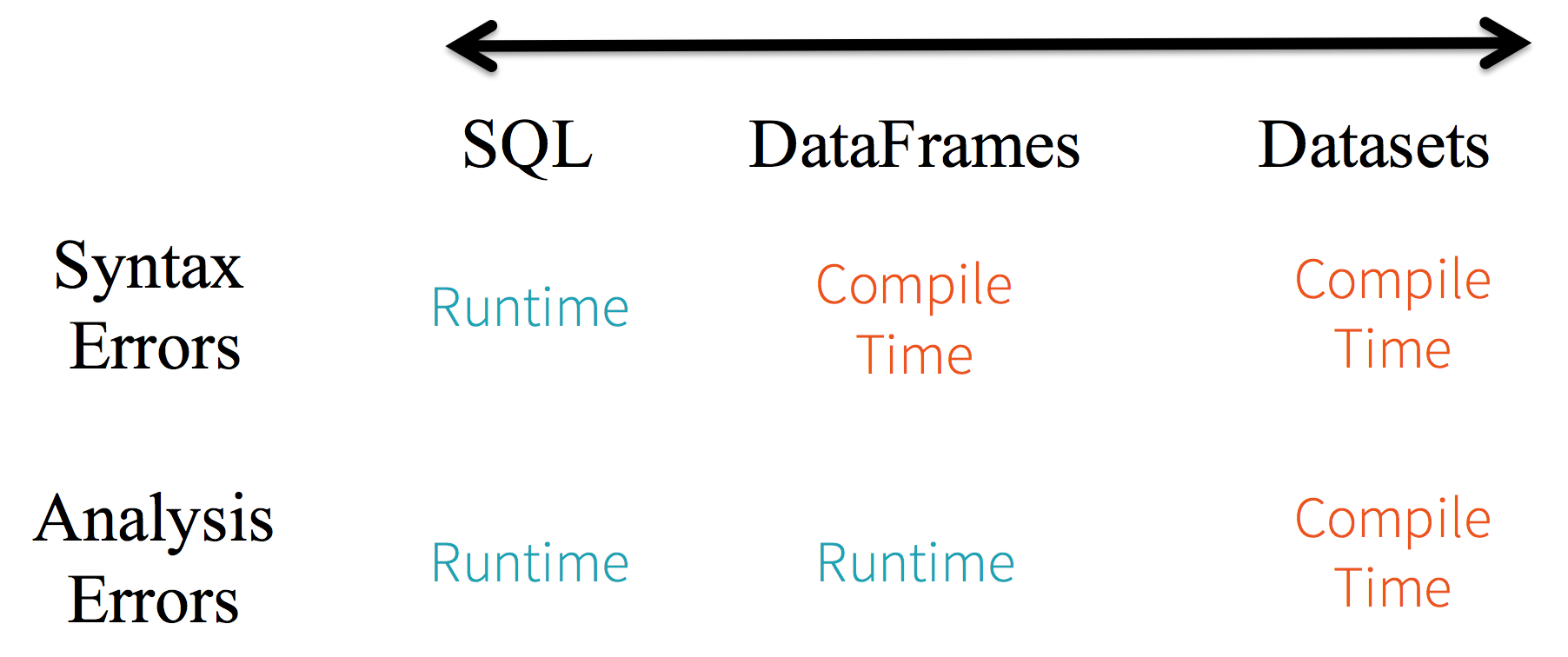
1. Static-typing and runtime type-safety
Consider static-typing and runtime safety as a spectrum, with SQL least restrictive to Dataset most restrictive. For instance, in your Spark SQL string queries, you won’t know a syntax error until runtime (which could be costly), whereas in DataFrames and Datasets you can catch errors at compile time (which saves developer-time and costs). That is, if you invoke a function in DataFrame that is not part of the API, the compiler will catch it. However, it won’t detect a non-existing column name until runtime.
At the far end of the spectrum is Dataset, most restrictive. Since Dataset APIs are all expressed as lambda functions and JVM typed objects, any mismatch of typed-parameters will be detected at compile time. Also, your analysis error can be detected at compile time too, when using Datasets, hence saving developer-time and costs.
2. High-level abstraction and custom view into structured and semi-structured data
- val ds = spark.read.json("/databricks-public-datasets/data/iot/iot_devices.json").as[DeviceIoTData]
- Spark reads the JSON, infers the schema, and creates a collection of DataFrames.
- At this point, Spark converts your data into DataFrame = Dataset[Row], a collection of generic Row object, since it does not know the exact type.
- Now, Spark converts the Dataset[Row] -> Dataset[DeviceIoTData] type-specific Scala JVM object, as dictated by the class DeviceIoTData.
3. Ease-of-use of APIs with structure
- val dsAvgTmp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.humidity, d.cca3)).groupBy($"_3").avg()
4. Performance and Optimization
because DataFrame and Dataset APIs are built on top of the Spark SQL engine, it uses Catalyst to generate an optimized logical and physical query plan. Across R, Java, Scala, or Python DataFrame/Dataset APIs, all relation type queries undergo the same code optimizer, providing the space and speed efficiency. Whereas the Dataset[T] typed API is optimized for data engineering tasks, the untyped Dataset[Row] (an alias of DataFrame) is even faster and suitable for interactive analysis.
Second, since Spark as a compiler understands your Dataset type JVM object, it maps your type-specific JVM object to Tungsten’s internal memory representation using Encoders. As a result, Tungsten Encoders can efficiently serialize/deserialize JVM objects as well as generate compact bytecode that can execute at superior speeds.
Note that you can always seamlessly interoperate or convert from DataFrame and/or Dataset to an RDD, by simple method call
.rdd.- val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level").where($"c02_level" > 1300)
- // convert to RDDs and take the first 10 rows
- val eventsRDD = deviceEventsDS.rdd.take(10)
While RDD offers you low-level functionality and control, the latter allows custom view and structure, offers high-level and domain specific operations, saves space, and executes at superior speeds.
As we examined the lessons we learned from early releases of Spark—how to simplify Spark for developers, how to optimize and make it performant—we decided to elevate the low-level RDD APIs to a high-level abstraction as DataFrame and Dataset and to build this unified data abstraction across libraries atop Catalyst optimizer and Tungsten.
Spark is a generalized framework for distributed data processing providing functional API for manipulating data at scale, in-memory data caching and reuse across computations. It applies set of coarse-grained transformations over partitioned data and relies on dataset's lineage to recompute tasks in case of failures. Worth mentioning is that Spark supports majority of data formats, has integrations with various storage systems and can be executed on Mesos or YARN.
Spark is built around the concepts of Resilient Distributed Datasets and Direct Acyclic Graph representing transformations and dependencies between them.
Spark Application (often referred to as Driver Program or Application Master) at high level consists of SparkContext and user code which interacts with it creating RDDs and performing series of transformations to achieve final result. These transformations of RDDs are then translated into DAG and submitted to Scheduler to be executed on set of worker nodes.
RDD could be thought as an immutable parallel data structure with failure recovery possibilities. It provides API for various transformations and materializations of data as well as for control over caching and partitioning of elements to optimize data placement. RDD can be created either from external storage or from another RDD and stores information about its parents to optimize execution (via pipelining of operations) and recompute partition in case of failure.
From a developer's point of view RDD represents distributed immutable data (partitioned data + iterator) and lazily evaluated operations (transformations).
//a list of partitions (e.g. splits in Hadoop)
def getPartitions: Array[Partition]
//a list of dependencies on other RDDs
def getDependencies: Seq[Dependency[_]]
//a function for computing each split
def compute(split: Partition, context: TaskContext): Iterator[T]
//(optional) a list of preferred locations to compute each split on
def getPreferredLocations(split: Partition): Seq[String] = Nil
//(optional) a partitioner for key-value RDDs
val partitioner: Option[Partitioner] = None - HadoopRDD:
- getPartitions = HDFS blocks
- getDependencies = None
- compute = load block in memory
- getPrefferedLocations = HDFS block locations
- partitioner = None
- MapPartitionsRDD
- getPartitions = same as parent
- getDependencies = parent RDD
- compute = compute parent and apply map()
- getPrefferedLocations = same as parent
- partitioner = None
- Transformations
- apply user function to every element in a partition (or to the whole partition)
- apply aggregation function to the whole dataset (groupBy, sortBy)
- introduce dependencies between RDDs to form DAG
- provide functionality for repartitioning (repartition, partitionBy)
- Actions
- trigger job execution
- used to materialize computation results
- Extra: persistence
- explicitly store RDDs in memory, on disk or off-heap (cache, persist)
- checkpointing for truncating RDD lineage
val events =
sc.cassandraTable("demo", "event")
.map(_.toEvent)
.filter { e =>
e.campaignId == campaignId && e.time.isAfter(watermark)
}
.keyBy(_.eventType)
.reduceByKey(_ + _)
.cache()
//aggregate campaigns by type
val campaigns =
sc.cassandraTable("demo", "campaign")
.map(_.toCampaign)
.filter { c =>
c.id == campaignId && c.time.isBefore(watermark)
}
.keyBy(_.eventType)
.reduceByKey(_ + _)
.cache()
//joined rollups and raw events
val joinedTotals = campaigns.join(events)
.map { case (key, (campaign, event)) =>
CampaignTotals(campaign, event)
}
.collect()
user code containing RDD transformations forms Direct Acyclic Graph which is then split into stages of tasks by DAGScheduler. Stages combine tasks which don’t require shuffling/repartitioning if the data. Tasks run on workers and results then return to client.The dependencies are usually classified as "narrow" and "wide":
- Narrow (pipelineable)
- each partition of the parent RDD is used by at most one partition of the child RDD
- allow for pipelined execution on one cluster node
- failure recovery is more efficient as only lost parent partitions need to be recomputed
- Wide (shuffle)
- multiple child partitions may depend on one parent partition
- require data from all parent partitions to be available and to be shuffled across the nodes
- if some partition is lost from all the ancestors a complete recomputation is needed
Splitting DAG into Stages
Spark stages are created by breaking the RDD graph at shuffle boundaries
- RDD operations with "narrow" dependencies, like map() and filter(), are pipelined together into one set of tasks in each stage operations with shuffle dependencies require multiple stages (one to write a set of map output files, and another to read those files after a barrier).
- In the end, every stage will have only shuffle dependencies on other stages, and may compute multiple operations inside it. The actual pipelining of these operations happens in the
RDD.compute()functions of various RDDs
There are two types of tasks in Spark:
ShuffleMapTask which partitions its input for shuffle and ResultTask which sends its output to the driver. The same applies to types of stages: ShuffleMapStage and ResultStage correspondingly.
During the shuffle
ShuffleMapTask writes blocks to local drive, and then the task in the next stages fetches these blocks over the network.- Shuffle Write
- redistributes data among partitions and writes files to disk
- each hash shuffle task creates one file per “reduce” task (total = MxR)
- sort shuffle task creates one file with regions assigned to reducer
- sort shuffle uses in-memory sorting with spillover to disk to get final result
- Shuffle Read
- fetches the files and applies reduce() logic
- if data ordering is needed then it is sorted on “reducer” side for any type of shuffle
In Spark Sort Shuffle is the default one since 1.2, but Hash Shuffle is available too.
Sort Shuffle

- Incoming records accumulated and sorted in memory according their target partition ids
- Sorted records are written to file or multiple files if spilled and then merged
- index file stores offsets of the data blocks in the data file
- Sorting without deserialization is possible under certain conditions (SPARK-7081)
- Spark Driver
- separate process to execute user applications
- creates SparkContext to schedule jobs execution and negotiate with cluster manager
- Executors
- run tasks scheduled by driver
- store computation results in memory, on disk or off-heap
- interact with storage systems
- Cluster Manager
- Mesos
- YARN
- Spark Standalone
Spark Driver contains more components responsible for translation of user code into actual jobs executed on cluster:
- SparkContext
- represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster
- DAGScheduler
- computes a DAG of stages for each job and submits them to TaskScheduler
- determines preferred locations for tasks (based on cache status or shuffle files locations) and finds minimum schedule to run the jobs
- TaskScheduler
- responsible for sending tasks to the cluster, running them, retrying if there are failures, and mitigating stragglers
- SchedulerBackend
- backend interface for scheduling systems that allows plugging in different implementations(Mesos, YARN, Standalone, local)
- BlockManager
- provides interfaces for putting and retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap)
Executors run as Java processes, so the available memory is equal to the heap size. Internally available memory is split into several regions with specific functions.

- Execution Memory
- storage for data needed during tasks execution
- shuffle-related data
- Storage Memory
- storage of cached RDDs and broadcast variables
- possible to borrow from execution memory (spill otherwise)
- safeguard value is 50% of Spark Memory when cached blocks are immune to eviction
- User Memory
- user data structures and internal metadata in Spark
- safeguarding against OOM
- Reserved memory
- memory needed for running executor itself and not strictly related to Spark
Programming Spark: RDD 本质论
RDD(Resilient Distributed Dataset),是Spark最令人青睐的抽象,是Spark设计的核心。其本质是一个只读的分区记录,并能够被并行操作的集合,它具有如下几方面的特点:- 分区:可分区的数据(
partitions); - 函数式:只读的,不可变的,惰性求值,并行处理
- 容错:分区数据的自动恢复;
- 序列化
特征
RDD具有5个最基本的特征或属性:- 分区集合(splits)
- 依赖的
RDD集合 - 分区的计算方法
- Preferred Locations(可选)
- Partitioner(可选)
可参阅
RDD的源代码:abstract class RDD[T: ClassTag](
private var sc: SparkContext,
private var deps: Seq[Dependency[_]]
) {
def getPartitions: Array[Partition]
def compute(split: Partition, context: TaskContext): Iterator[T]
def getDependencies: Seq[Dependency[_]] = deps
def getPreferredLocations(split: Partition): Seq[String] = Nil
val partitioner: Option[Partitioner] = None
}一个简单的例子
val file = sc.textFile("hdfs://...")
首先生成
HadoopRDD,在进行了一次Transformation变换为MapPartitionsRDD;val errors = file.filter(_.contains("ERROR"))filter操作再进行了一次Transformation变换为另外一个MapPartitionsRDD。HadoopRDD
- partitions = one per HDFS block
- dependencies = None
- compute(partition) = read corresponding block
- preferredLocations(part) = HDFS block location
- partitioner = None
MapPartitionsRDD
- partitions = same as parent RDD
- dependencies = "one-to-one" on parent
- compute(partition) = compute parent and filter it
- preferredLocations(part) = None(ask parent)
- partitioner = None
RDD的计算
RDD中的dependencies, 及其compute(partition)是RDD最重要的两个特征函数,其描述了RDD的最基本的行为特征。
首先解读
RDD的计算过程,依赖关系后文重点讲述。函数原型
RDD是针对于一个Partition(分区)的,而且由一个Task负责执行的;也就是说,RDD的分区与Task具有一一对应的关系);其计算结果表示一个类型为T的集合。
为此
compute的函数原型正如上文所示:def compute(split: Partition, context: TaskContext): Iterator[T]惰性求值
RDD的compute并没有执行真正的计算,它只描绘了计算过程的蓝图,而且计算之间是通过组合来完成的,是一种典型的函数式设计的思维。依赖关系
RDD的依赖关系可分为两类:Narrow Dependency: 一个父RDD之多被一个子RDD引用;Shuffle/Wide Dependency: 一个父RDD被多个子RDD引用;
也就是说,
Narrow Dependency的出度为1;Shuffle/Wide Dependency的出度大于1。
区分的意义
Narrow Dependency可以支持在同一个Cluster Node上以Pipeline的形式执行并发运算多条命令;Narrow Dependency的数据容错性会更有效,它只需重新计算丢失了的父分区即可,并且可以并行地在不同节点上重计算。
Stage划分
DAGScheduler根据RDD之间的依赖关系,识别出Stage列表,并依次将Stage(TaskSet)提交至TaskScheduler进行调度执行。
也就是说,
DAGScheduler最终的职责就是完成Stage的划分算法。划分准则
Wide Dependency是划分Stage的边界;Narrow Dependency的RDD被放在同一个Stage之中;
一个简单的例子
以下图为例,讲解
DAG的划分算法。G为FinalRDD,从后往前按照RDD的依赖关系,进行深度遍历算法,依次识别出各个Stage的起始边界。
Stage 3的划分:
G与B之间是Narrow Dependency,规约为同一Stage(3);B与A之间是Wide Dependency,A为新的FinalRDD,递归调用此过程;G与F之间是Wide Dependency,F为新的FinalRDD,递归调用此过程;
Stage 1的划分
A没有父亲RDD,Stage(1)划分结束。特殊地Stage(1)仅包含RDD A;
Stage 2的划分:
- 因
RDD之间的关系都为Narrow Dependency,规约为同一个Stage(2); - 直至
RDD C,因没有父亲RDD,Stage(2)划分结束;
最终,形成了
Stage的依赖关系,按照广度优先遍历算法,依次提交Stage(TaskSet)至TaskScheduler进行调度执行。算法解读
思考
Stage划分的3个基本的问题:- 如何确定
Stage的起始边界?- 开始:读外部数据源,或读
Shuffle; - 结束:发生
Shuffle写,或者Job结束;
- 开始:读外部数据源,或读
- 如何确定
FinalStage?- 触发
Action的RDD所在的Stage
- 触发
- 如何表示一个
Stage?
private[spark] abstract class Stage(
val id: Int,
val rdd: RDD[_],
val numTasks: Int)
其中
rdd为Stage中最后一个RDD,可反向推演出完整的Stage;numTasks表示Stage并发执行的的任务数,等于RDD的分区数。生命周期
总结一下,一个应用程序的整个生命周期如下图所示:

- 根据
RDD的依赖关系,由DAGScheduler识别出Stage列表; DAGScheduler依次将Stage(TaskSet)提交至TaskScheduler执行;TaskScheduler选择合适的Worker,将Task提交至Executor上计算;Executor从线程池中分配一个空闲的线程执行此Task。
Spark的性能归诸于以下原因:- 基于内存的迭代式计算
- 基于
DAG的执行引擎 - 基于
RDD的统一抽象模型 - 出色的自动容错机制
One Stack to rule them all构建统一的技术栈Spark SQLSpark StreamingSpark MLlibSpark GraphX
近乎完美解决了大数据中三大应用场景。
Batch ProcessingStreaming ProcessingAd-hoc Query
易集成,易部署
支持多种部署方式:
StandaloneYarnMesosEC2
支持多种外部数据源:
HDFSHBaseHiveCassandraS3
https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
Java objects have a large inherent memory overhead. Consider a simple string “abcd” that would take 4 bytes to store using UTF-8 encoding.
It encodes each character using 2 bytes with UTF-16 encoding, and each String object also contains a 12 byte header and 8 byte hash code
A simple 4 byte string becomes over 48 bytes in total in the JVM object model!
The other problem with the JVM object model is the overhead of garbage collection. At a high level, generational garbage collection divides objects into two categories: ones that have a high rate of allocation/deallocation (the young generation) ones that are kept around (the old generation). Garbage collectors exploit the transient nature of young generation objects to manage them efficiently. This works well when GC can reliably estimate the life cycle of objects, but falls short if the estimation is off (i.e. some transient objects spill into the old generation).
Spark understands how data flows through various stages of computation and the scope of jobs and tasks. As a result, Spark knows much more information than the JVM garbage collector about the life cycle of memory blocks, and thus should be able to manage memory more efficiently than the JVM.
To tackle both object overhead and GC’s inefficiency, we are introducing an explicit memory manager to convert most Spark operations to operate directly against binary data rather than Java objects. This builds on
sun.misc.Unsafe, an advanced functionality provided by the JVM that exposes C-style memory access (e.g. explicit allocation, deallocation, pointer arithmetics). Furthermore, Unsafe methods are intrinsic, meaning each method call is compiled by JIT into a single machine instruction.
Spark can also process data orders magnitude larger than the available memory, transparently spill to disk and perform external operations such as sorting and hashing.
3. Code Generation
About a year ago Spark introduced code generation for expression evaluation in SQL and DataFrames. Expression evaluation is the process of computing the value of an expression (say “
age > 35 && age < 40”) on a particular record. At runtime, Spark dynamically generates bytecode for evaluating these expressions, rather than stepping through a slower interpreter for each row. Compared with interpretation, code generation reduces the boxing of primitive data types and, more importantly, avoids expensive polymorphic function dispatches.