https://www.facebook.com/Engineering/videos/typeahead-search-tech-talk-6152010/432864835468/
http://usefulstuff.io/2013/03/how-it-works-facebook-part-2/
Original Facebook search engine simply searches into cached users informations: friends list, like lists and so on. Typeahead search (the search box on the top of Facebook frontend) came on 2009.
https://github.com/FreemanZhang/system-design/blob/master/typeahead.md
https://www.interviewbit.com/problems/design-search-typeahead/#
Q: How many search queries are done per day?
Q: What would the API look like for the client?
http://usefulstuff.io/tag/typeahead/
Typeahead - facebook search box to find your friends
https://www.facebook.com/notes/facebook-engineering/the-life-of-a-typeahead-query/389105248919/
Despite these performance constraints, the UI cannot be too minimalist; each result needs enough contextual clues to convey its meaning and relevance. Because the new typeahead auto-selects the first result when you hit Enter in the search box, we need near-perfect relevance so that the first result is always the one you're looking for.
As soon as the user focuses in the text box, we send off a request to retrieve all of the user's friends, pages, groups, applications, and upcoming events. We load these results into the browser's cache, so that the user can find these results immediately without sending another request. The old typeahead did this, but stopped here.
If there are not enough results in the current browser cache, the browser sends an AJAX request containing the current query string and a list of results that are already being displayed due to browser cache. Our load balancer routes the request to an appropriate web machine.
The php AJAX endpoint is a thin wrapper around a Thrift service for handling typeahead queries. This service, called the "aggregator", is at the root of a tree of separate search services. Aggregators themselves are stateless and have no index of their own. They are instead responsible for delegating queries to multiple lower-level services in parallel and integrating their results.
In parallel, several different backend search services scour their indices for results that prefix-match the contents of the search box. Each leaf service is designed to retrieve and rank results on only a few specific features. The architecture of the system allows us to add new services, too, as we discover important sources of results and features.
The global service maintains an index of all the pages and applications on the site. Unlike most of what we do at Facebook, these results are global because they contain no personalization. The signals that this service records are identical for all user on the site; for example, we might rank applications by the number of users who have interacted with them in the last month, and pages by the structure of the graph surrounding them. Since this service's results are independent of the querying user, we can save latency by storing recent results in a memcached-based query cache.
The graph service returns results by searching the user's neighborhood of the graph. For some types of queries, a user and her friend's graph connections are a powerful signal of expressed preferences, and thus relevance. Graphs are notoriously difficult mathematical objects for computers to come to terms with: they are large, and are a minefield of computationally hard problems that appear simple. Our graph contains 400 million active users, and many billions of connections, both among users and from users to objects of other types: pages, applications, events, open graph nodes, etc.
The aggregator merges the results and features returned from each leaf service and ranks the results according to our model. The top results are returned to the web tier.
The results returned by the aggregator are simply a list of ids. The web tier needs to fetch all the data from memcache/MySQL to render the results and display information like the name, profile picture, link, shared networks, mutual friends, etc. The web tier also needs to do privacy checking here to make sure that the searcher is allowed to see each result.
The results with all the relevant data are sent back to the browser to be displayed in the typeahead. These results are also added to the browser cache along with the bootstrapped connections so that similar subsequent queries don't need to hit the backend again.
Once the basic architecture was in place, we spent a lot of time getting everything to a production-ready state. We dark-tested by changing the old typeahead to send a query on every keystroke. We knew that usage patterns could dramatically shift once the new typeahead was fully launched, but this was a good first step to uncovering any scalability issues we might have. As a result of this testing, we discovered network limitations that caused us to adjust the topology of the architecture.
We also experimented with a large number of user interface variants using A/B testing and more qualitiative usability studies to help us make some thorny decisions.
Other experiments included different picture sizes, ways of distinguishing between different result types like applications vs. people, highlighting the query string in results, and various ways of displaying mutual friends.
As with all interesting engineering projects, the trade-offs are where we had the most challenges, surprises, and fun. Many technical decisions in search boil down to a trilemma among performance, recall, and relevance. Our typeahead is perhaps unusual in our high prority on performance; spending more than 100 msec to retrieve a result will cause the typeahead to "stutter," leading to a bad user experience that is almost impossible to compensate for with quality. "Real-time search" is often used to mean chronologically ordered, up-to-date content search, but our typeahead search engine is "real-time" in the older sense of the term: late answers are wrong answers.
http://ying.ninja/?p=903



Implement typeahead. Given a string and a dictionary, return all words that contains the string as a substring. The dictionary will give at the initialize method and wont be changed.
The method to find all words with given substring would be called multiple times.
Example
Given dictionary = {"Jason Zhang", "James Yu", "Bob Zhang", "Larry Shi"}
search "Zhang", return ["Jason Zhang", "Bob Zhang"].
search "James", return ["James Yu"].
解:
这道题有两种做法,一是Inverted Index,二是Trie Tree。
两种做法的区别在于如何存储关键字。
这里使用查找效率更高的Trie Tree。
Trie Tree如何实现请参考Implement Trie和Trie Service。
在存储的时候,每个Trie Node都要保存这个节点和以下所有孩子节点的热门词,以便快速返回而无需遍历。
需要注意的是在插入新关键词的时候,应该把每个词从到到尾的每个字符作为开始的词都插入一次。这样才可以保证用户从一个词的中间某个字符开始输入时也能快速查找到热门词列表。
https://medium.com/@Pinterest_Engineering/rebuilding-the-user-typeahead-9c5bf9723173
http://shirleyisnotageek.blogspot.com/2016/11/facebook-typeahead-search.html
Unlike Google's search result, FB's search is personalized, i.e., for each user, the ranking of the results should be different based on their friends, likes, etc, so static ranking performs badly.
Boils down to the actual question, we would expect the user's first degree relations becomes the top results, then the second degree relations, and then the global results (like Google). Based on this, we actually can split searching to three parts and aggregate together later.
http://usefulstuff.io/2013/03/how-it-works-facebook-part-2/
Original Facebook search engine simply searches into cached users informations: friends list, like lists and so on. Typeahead search (the search box on the top of Facebook frontend) came on 2009.
https://github.com/FreemanZhang/system-design/blob/master/typeahead.md
Data collections service
- How frequently do you aggregate data
- Real-time not impractical. Read QPS 200K + Write QPS 200K. Will slow down query service.
- Once per week. Each week data collection service will fetch all the data within the most recent one week and aggregate them.
- How does data collection service update query service? Offline update and works online.
- All in-memory trie must have already been serialized. Read QPS already really high. Do not write to in-memory trie directly.
- Use another machine. Data collection service updates query service.
How to reduce response time
- Cache result
- Front-end browser cache the results
- Pre-fetch
- Fetch the latest 1000 results
What if the trie too large for one machine
- Use consistent hashing to decide which machine a particular string belongs to.
- A record can exist only in one machine. Sharding according to char will not distribute the resource evenly. Instead, calculate consistent hashing code
- a, am, ama, amax stored in different machines.
How to reduce the size of log file
- Probablistic logging.
- Too slow to calculate and too large amount of data to store.
- Log with 1/10,000 probability
- Say over the past two weeks "amazon" was searched 1 billion times, with 1/1000 probability we will only log 1 million times.
- For a term that's searched 1000 times, we might end up logging only once or even zero times
https://www.interviewbit.com/problems/design-search-typeahead/#
Features:
This is the first part of any system design interview, coming up with the features which the system should support. As an interviewee, you should try to list down all the features you can think of which our system should support. Try to spend around 2 minutes for this section in the interview. You can use the notes section alongside to remember what you wrote.
- Q: How many typeahead suggestions are to be provided?
A: Let's assume 5 for this case. - Q: Do we need to account for spelling mistakes ?
A: Example : Should typing mik give michael as a suggestion because michael is really popular as a query? - Q: What is the criteria for choosing the 5 suggestions ?
A: As the question suggests, all suggestions should have the typed phrase/query as the strict prefix. Now amongst those, the most relevant would be the most popular 5. Here, popularity of a query can be determined by the frequency of the query being searched in the past. - Q: Does the system need to be realtime ( For example, recent popular events like “Germany wins the FIFA worldcup” starts showing up in results within minutes ).
A: Let's assume that it needs to be realtime. - Q: Do we need to support personalization with the suggestions? ( My interests / queries affect the search suggestions shown to me).
A: Let's assume that we don’t need to support personalization
Estimation:
This is usually the second part of a design interview, coming up with the estimated numbers of how scalable our system should be. Important parameters to remember for this section is the number of queries per second and the data which the system will be required to handle.
Try to spend around 5 minutes for this section in the interview.
There are essentialy 2 parts to this system :
- Clients can query my system for top 5 suggestions given a query prefix.
- Every search query done should feed into the system for an update.
Q: How many queries per second should the system handle?
A: We can use the estimation from the last question here.
Total Number of queries : 4 Billion
Average length of query : 5 words = 25 letters ( Since avg length of english word is 5 letters ).
Assuming, every single keystroke results in a typeahead query, we are looking at an upper bound of 4 x 25 = 100 Billion queries per day.
Total Number of queries : 4 Billion
Average length of query : 5 words = 25 letters ( Since avg length of english word is 5 letters ).
Assuming, every single keystroke results in a typeahead query, we are looking at an upper bound of 4 x 25 = 100 Billion queries per day.
Q: How much data would we need to store?
A: Lets first look at the amount of new data we generate every day. 15% of the search queries are new for Google ( ~500 Million new queries ). Assuming 25 letters on average per query, we will 12.5G new data per day.
Assuming, we have accumulated queries over the last 10 years, the size would be 12.5 * 365 * 10 G which is approximately 50TB.
Assuming, we have accumulated queries over the last 10 years, the size would be 12.5 * 365 * 10 G which is approximately 50TB.
Design Goals:
There could be more goals depending on the problem. It's possible that all parameters might be important, and some of them might conflict. In that case, you’d need to prioritize one over the other.
- Latency - Is this problem very latency sensitive (Or in other words, Are requests with high latency and a failing request, equally bad?). For example, search typeahead suggestions are useless if they take more than a second.
- Consistency - Does this problem require tight consistency? Or is it okay if things are eventually consistent?
- Availability - Does this problem require 100% availability?
Q: Is Latency a very important metric for us?
A: A big Yes. Search typeahead almost competes with typing speed and hence needs to have a really low latency.
Q: How important is Consistency for us?
A: Not really important. If 2 people see different top 5 suggestions which are on the same scale of popularity, its not the end of the world. I, as a product owner, am happy as long as the results become eventually consistent.
Q: How important is Availability for us?
Skeleton of the design:
The next step in most cases is to come up with the barebone design of your system, both in terms of API and the overall workflow of a read and write request. Workflow of read/write request here refers to specifying the important components and how they interact. Try to spend around 5 minutes for this section in the interview.
Important : Try to gather feedback from the interviewer here to indicate if you are headed in the right direction.
As discussed before, there are essentially 2 parts to this system :
- Given a query, give me 5 most frequent search terms with the query as strict prefix
- Given a search term, update the frequencies.
Q: What would the API look like for the client?
A:
Read: List(string) getTopSuggestions(string currentQuery)
Write: void updateSuggestions(string searchTerm)
Write: void updateSuggestions(string searchTerm)
Q: What is a good data structure to store my search queries so that I can quickly retrieve the top 5 most popular queries?
A: For this question, we need to figure out top queries with another string as strict prefix. If you have dealt with enough string questions, you would realize a prefix tree (or trie) would be a perfect fit here
Q: How can we modify the trie so that reads become super efficient?
Hint : Store more data on every node of the trie.
A: Storage is cheap. Lets say we were allowed to store more stuff on each node. How would we use the extra storage to reduce the latency of answering the query.
A good choice would be storing the top 5 queries for the prefix ending on node n1 at n1 itself. So, every node has the top 5 search terms from the subtree below it. The read operation becomes fairly simple now. Given a search prefix, we traverse down to the corresponding node and return the top 5 queries stored in that node
A good choice would be storing the top 5 queries for the prefix ending on node n1 at n1 itself. So, every node has the top 5 search terms from the subtree below it. The read operation becomes fairly simple now. Given a search prefix, we traverse down to the corresponding node and return the top 5 queries stored in that node
Q: How would a typical write work in this trie?
A: So, now whenever we get an actual search term, we will traverse down to the node corresponding to it and increase its frequency. But wait, we are not done yet. We store the top 5 queries in each node. Its possible that this particular search query jumped into the top 5 queries of a few other nodes. We need to update the top 5 queries of those nodes then. How do we do it then? Truthfully, we need to know the frequencies of the top 5 queries ( of every node in the path from root to the node ) to decide if this query becomes a part of the top 5.
There are 2 ways we could achieve this.
There are 2 ways we could achieve this.
- Along with the top 5 on every node, we also store their frequency. Anytime, a node’s frequency gets updated, we traverse back from the node to its parent till we reach the root. For every parent, we check if the current query is part of the top 5. If so, we replace the corresponding frequency with the updated frequency. If not, we check if the current query’s frequency is high enough to be a part of the top 5. If so, we update the top 5 with frequency.
- On every node, we store the top pointer to the end node of the 5 most frequent queries ( pointers instead of the text ). The update process would involve comparing the current query’s frequency with the 5th lowest node’s frequency and update the node pointer with the current query pointer if the new frequency is greater
Q: What optimizations can we do to improve read efficiency?
A: Yes. If we assume Google’s scale, most frequent queries would appear 100s of times in an hour. As such instead of using every query to update, we can sample 1 in 100 or 1 in 1000 query and update the trie using that.
A: Again if we assume that most queries appearing in the search typeahead would appear 100s of times in an hour, we can have an offline hashmap which keeps maintaining a map from query to frequency. Its only when the frequency becomes a multiple of a threshold that we go and update the query in the trie with the new frequency. The hashmap being a separate datastore would not collide with the actual trie for reads.
A: As mentioned earlier, writes compete with read. Sampling writes and Offline updates can be used to improve read efficieny.
Q: What if I use a separate trie for updates and copy it over to the active one periodically?
A: Not really, there are 2 major problems with this approach.
- You are not realtime anymore. Lets say you copy over the trie every hour. Its possible a search term became very popular and it wasn’t reflected for an hour because it was present in the offline trie and did not appear till it was copied to the original trie
- The trie is humungous. Copying over the trie can’t be an atomic operation. As such, how would you make sure that reads are still consistent while still processing incoming writes?
Q: Would all data fit on a single machine?
Q: Alright, how do we shard the data then?
A: The number of shards could very well be more than the number of branches on first level(26). We will need to be more intelligent than just sharding on first level.
A: Load imbalance. Storage imbalance. Some letters are more frequent than the others. For example, letters starting with 'a' are more likely than letters starting with 'x'. As such, we can run into cases of certain shards running hot on load. Also, certain shards will have to store more data because there are more queries starting with a certain letter. Another fact in favor of sharding a little more intelligently.
A: Lets say we were sharding till the second or third level and we optimize for load here. Lets also say that we have the data around the expected load for every prefix.
We keep traversing the 2 letter prefixes in order ('a', 'aa', 'ab', 'ac',...) and break when the total load exceeds an threshold load and assign that range to a shard.
We will need to have a master which has this mapping with it, so that it can route a prefix query to the correct shard
We keep traversing the 2 letter prefixes in order ('a', 'aa', 'ab', 'ac',...) and break when the total load exceeds an threshold load and assign that range to a shard.
We will need to have a master which has this mapping with it, so that it can route a prefix query to the correct shard
Q: How would we handle a DB machine going down?
A: As we discussed earlier, availability is more important to us than consistency. If thats the case, we can maintain multiple replica of each shard and an update goes to all replicas. The read can go to multiple replicas (not necessarily all) and uses the first response it gets. If a replica goes down, reads and writes continue to work fine as there are other replicas to serve the queries.
The issue occurs when this replica comes back up. There are 2 options here :
The issue occurs when this replica comes back up. There are 2 options here :
- If the frequency of the replica going down is lower or we have much higher number of replicas, the replica which comes back up can read the whole data from one of the older working replica while keeping the new incoming writes in a queue.
- There is a queue with every server which contains the changelog or the exact write query being sent to them. The replica can request any of the other replicas in its shard for all changelog since a particular timestamp and use that to update its trie
http://usefulstuff.io/tag/typeahead/
Typeahead - facebook search box to find your friends
https://www.facebook.com/notes/facebook-engineering/the-life-of-a-typeahead-query/389105248919/
Despite these performance constraints, the UI cannot be too minimalist; each result needs enough contextual clues to convey its meaning and relevance. Because the new typeahead auto-selects the first result when you hit Enter in the search box, we need near-perfect relevance so that the first result is always the one you're looking for.
To satisfy all these constraints, we designed an architecture composed of several different backend services that were optimized for specific types of results. Let's follow a session as the request leaves a user's browser and becomes a set of navigable results.

1. Bootstrapping Connections
As soon as the user focuses in the text box, we send off a request to retrieve all of the user's friends, pages, groups, applications, and upcoming events. We load these results into the browser's cache, so that the user can find these results immediately without sending another request. The old typeahead did this, but stopped here.
2. AJAX Request
If there are not enough results in the current browser cache, the browser sends an AJAX request containing the current query string and a list of results that are already being displayed due to browser cache. Our load balancer routes the request to an appropriate web machine.
3. Aggregator Service
The php AJAX endpoint is a thin wrapper around a Thrift service for handling typeahead queries. This service, called the "aggregator", is at the root of a tree of separate search services. Aggregators themselves are stateless and have no index of their own. They are instead responsible for delegating queries to multiple lower-level services in parallel and integrating their results.
4. Leaf Services
In parallel, several different backend search services scour their indices for results that prefix-match the contents of the search box. Each leaf service is designed to retrieve and rank results on only a few specific features. The architecture of the system allows us to add new services, too, as we discover important sources of results and features.
The global service maintains an index of all the pages and applications on the site. Unlike most of what we do at Facebook, these results are global because they contain no personalization. The signals that this service records are identical for all user on the site; for example, we might rank applications by the number of users who have interacted with them in the last month, and pages by the structure of the graph surrounding them. Since this service's results are independent of the querying user, we can save latency by storing recent results in a memcached-based query cache.
The graph service returns results by searching the user's neighborhood of the graph. For some types of queries, a user and her friend's graph connections are a powerful signal of expressed preferences, and thus relevance. Graphs are notoriously difficult mathematical objects for computers to come to terms with: they are large, and are a minefield of computationally hard problems that appear simple. Our graph contains 400 million active users, and many billions of connections, both among users and from users to objects of other types: pages, applications, events, open graph nodes, etc.
5. Merging Results
The aggregator merges the results and features returned from each leaf service and ranks the results according to our model. The top results are returned to the web tier.
6. Fetching Data and Validating Results
The results returned by the aggregator are simply a list of ids. The web tier needs to fetch all the data from memcache/MySQL to render the results and display information like the name, profile picture, link, shared networks, mutual friends, etc. The web tier also needs to do privacy checking here to make sure that the searcher is allowed to see each result.
7. Displaying the Results
The results with all the relevant data are sent back to the browser to be displayed in the typeahead. These results are also added to the browser cache along with the bootstrapped connections so that similar subsequent queries don't need to hit the backend again.
Putting it all Together
Once the basic architecture was in place, we spent a lot of time getting everything to a production-ready state. We dark-tested by changing the old typeahead to send a query on every keystroke. We knew that usage patterns could dramatically shift once the new typeahead was fully launched, but this was a good first step to uncovering any scalability issues we might have. As a result of this testing, we discovered network limitations that caused us to adjust the topology of the architecture.
We also experimented with a large number of user interface variants using A/B testing and more qualitiative usability studies to help us make some thorny decisions.
- Number of results: We wanted to show enough entries so that you would serendipitously stumble upon fun results while typing, yet showing fewer results would be faster and be less distracting. Our ultimate design varies the number of results shown based on your browser window height.
- Searching: Even though we made the Enter key auto-select the first result, we wanted to ensure users who wanted to search still could. We experimented heavily with the placement, wording, and appearance of the “See More Results” link that takes you to our traditional search page.
- Mouse vs. keyboard: While Facebook employees are heavy keyboard users, we discovered most users prefer to use the mouse to select from the typeahead. This led us to focus on mouse use-cases more than we naturally would have.
Other experiments included different picture sizes, ways of distinguishing between different result types like applications vs. people, highlighting the query string in results, and various ways of displaying mutual friends.
As with all interesting engineering projects, the trade-offs are where we had the most challenges, surprises, and fun. Many technical decisions in search boil down to a trilemma among performance, recall, and relevance. Our typeahead is perhaps unusual in our high prority on performance; spending more than 100 msec to retrieve a result will cause the typeahead to "stutter," leading to a bad user experience that is almost impossible to compensate for with quality. "Real-time search" is often used to mean chronologically ordered, up-to-date content search, but our typeahead search engine is "real-time" in the older sense of the term: late answers are wrong answers.
http://ying.ninja/?p=903
Facebook Typeahead
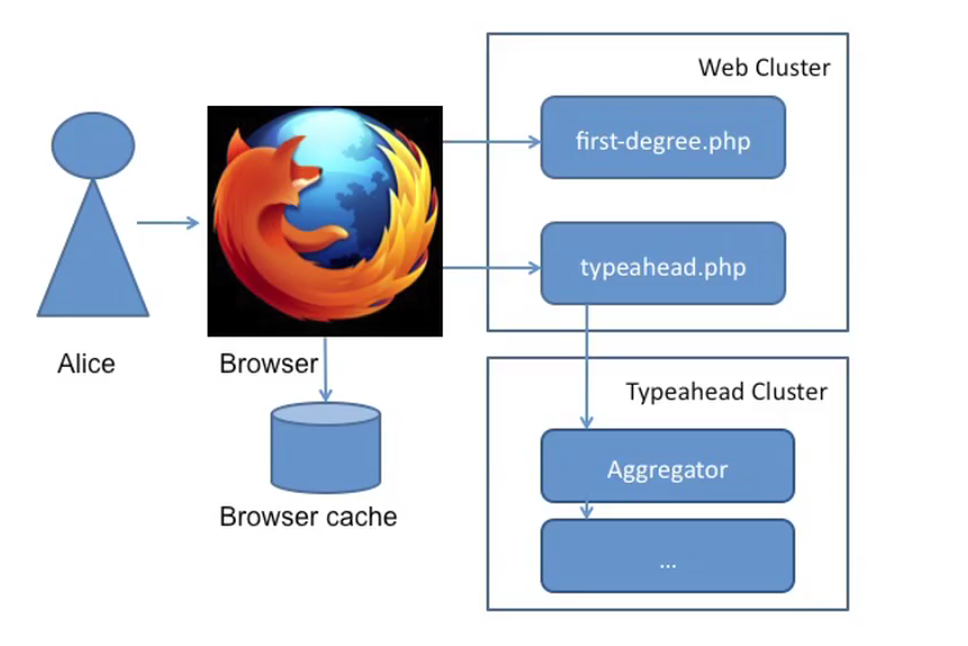
1. Preload 1st Degree Data into Browser Cache
Bootstrapping Connections
Once Alice clicks the search box, it sends off a request(basically calling first-degree.php in this case) to retrieve all of the user’s direct friends, pages, groups, applications, and upcoming events. Then save it in the browser cache. So that it can immediately show the results without sending another request.
2. AJAX request and Load Balancer
Now Alice types ‘B’, it should first show Bob since it is in the browser cache. Then it fires an ajax request (typeahead.php in this case), the load balancer is responsible for routing the request to different servers. Typically each server only handles one specific category of results(friend-of-friend, object-of-friend, events, etc).
Those blue rectangles are services which could be applied on multiple machines. The global service is for something which are independent to querying user. Like the most popular game or event, since ther we can save latency by storing recent results in a memcached-based query cache.
3. Aggregator
Aggregator delegates queries to multiple lower-level services in parallel and integrating their results.
4. Fetching Data and Validating Results
The results returned by the aggregator are simply a list of ids. The web tier needs to fetch all the data from memcache/MySQL to render the results and display information like the name, profile picture, link, shared networks, mutual friends, etc. The web tier also needs to do privacy checking here to make sure that the searcher is allowed to see each result.
5. Displaying the Results
The results with all the relevant data are sent back to the browser to be displayed in the typeahead. These results are also added to the browser cache along with the bootstrapped connections so that similar subsequent queries don’t need to hit the backend again.
Typeahead Algorithm
https://github.com/zxqiu/leetcode-lintcode/blob/master/system%20design/Typeahead.javaImplement typeahead. Given a string and a dictionary, return all words that contains the string as a substring. The dictionary will give at the initialize method and wont be changed.
The method to find all words with given substring would be called multiple times.
Example
Given dictionary = {"Jason Zhang", "James Yu", "Bob Zhang", "Larry Shi"}
search "Zhang", return ["Jason Zhang", "Bob Zhang"].
search "James", return ["James Yu"].
解:
这道题有两种做法,一是Inverted Index,二是Trie Tree。
两种做法的区别在于如何存储关键字。
这里使用查找效率更高的Trie Tree。
Trie Tree如何实现请参考Implement Trie和Trie Service。
在存储的时候,每个Trie Node都要保存这个节点和以下所有孩子节点的热门词,以便快速返回而无需遍历。
需要注意的是在插入新关键词的时候,应该把每个词从到到尾的每个字符作为开始的词都插入一次。这样才可以保证用户从一个词的中间某个字符开始输入时也能快速查找到热门词列表。
private class TreeNode {
Set<String> tops;
Map<Character, TreeNode> neighbors;
public TreeNode() {
tops = new HashSet<String>();
neighbors = new HashMap<Character, TreeNode>();
}
}
TreeNode root;
// @param dict A dictionary of words dict
public Typeahead(Set<String> dict) {
root = buildTree(dict);
}
// @param str: a string
// @return a list of words
public List<String> search(String str) {
TreeNode next = root;
for (char c : str.toCharArray()) {
if (!next.neighbors.containsKey(c)) {
return new ArrayList<String>();
}
next = next.neighbors.get(c);
}
return new ArrayList<String>(next.tops);
}
private TreeNode buildTree(Set<String> dict) {
TreeNode _root = new TreeNode();
for (String word : dict) {
for (int i = 0; i < word.length(); i++) {
TreeNode next = _root;
String subWord = word.substring(i);
for (char c : subWord.toCharArray()) {
if (!next.neighbors.containsKey(c)) {
next.neighbors.put(c, new TreeNode());
}
next = next.neighbors.get(c);
next.tops.add(word);
}
}
}
return _root;
}
http://shirleyisnotageek.blogspot.com/2016/11/facebook-typeahead-search.html
Unlike Google's search result, FB's search is personalized, i.e., for each user, the ranking of the results should be different based on their friends, likes, etc, so static ranking performs badly.
Boils down to the actual question, we would expect the user's first degree relations becomes the top results, then the second degree relations, and then the global results (like Google). Based on this, we actually can split searching to three parts and aggregate together later.
First degree relations include user's friends, his/her likes, activities and etc. For each user, these information may not be changed very quickly, so a batch job can always run to get all the first degree results, and cache it somewhere. When user types the first character, all first degree results can be immediately rendered.
For the global results, it can always be ranked and cached in advance as those are indifferent to different users (like Google search).
Now the real problem comes from the second degree relations, i.e., friends of friends, objects (likes, activities, etc) of friends.
For the global results, it can always be ranked and cached in advance as those are indifferent to different users (like Google search).
Now the real problem comes from the second degree relations, i.e., friends of friends, objects (likes, activities, etc) of friends.
Prefix search
Option 1: Trie
Usually when comes to prefix search, this comes on top of my mind. In this case, for each friend I have, there is a Trie structure that contains all his/her friends and objects. Now we do prefix search on each of those Tries and get the result.
Problem:
Those pointers in the Tries are really big
Pointers point to random places: touch the graph randomly, no partition.
Option 2: Sorted Vector of name, ID
For each of the friend, there is a sorted vector structure for his/her friends and objects. Now prefix matches becomes binary search for the range of the prefix matches. There are no random pointers now, so we can store this object with the original user as the key, and partition gets easier.
Problem:
Not good at memory consumption: multiple copies of one user's data
Scales badly when indexing more terms (multiple names for a user)
O(n) insertion: When you inserting a new data, you need to move all consequent data to give space for the new data.
Option 3: Brutal force
Friends lists are stored as adjacency list. For each of the friend, prefix-match by brute force in forward index. For example, Alice has friend Bob. For each of the friend of Bob's, search the friend's index, e.g., Bob has a friend Jon, his last name is "Doe", now if Alice searches "D", Jon Doe should show up.
Since each friend and object data is stored only once, we can achieve near optimal space utilization.
Problem:
Recomputing lots of things, high CPU, cache bandwidth.
Option 4: Filtered force
Using tiny bloom filter summarizing edge names.
Briefly speaking, bloom filter is an m bits bit array. All elements in a set will be mapped to some bits of in the array using some hash function. To check if a number is in the set, all bits after mapping the number using the hash function should be correctly reflected in the array.
In our prefix match case, we can consider there is an array for each friend, say char[26] representing 'a' - 'z'. Now if there is a prefix starts with 'c', but when we search one of Alice's friend 'Bob', we found that no 'c' in 'Bob' array, we can easily filter out Bob from our search. This may not guarantee the final result has all correct results, but all incorrect results will be filtered out. This approach requires extra space for the array for each friend, but we can increase CPU performance. Plus, it's easy to cache since we can easily cache those friends and objects that mismatches our prefixes.
Merging, ranking and returnning
The last step is to merge the FOF, OOF results and Global results with some ranking and return to user. There are lots of things that should be considered in ranking, and think loud to your interviewer