http://www.infoq.com/presentations/Big-Data-in-Real-Time-at-Twitter
http://www.slideshare.net/nkallen/q-con-3770885/8-Original_Implementationid_userid_text_createdat20
Twitter materializes (in memory) the items in each of the followers' inboxes
Original Implementation
Relational
• Single table, vertically scaled
• Master-Slave replication and Memcached for read throughput.
PARTITION
Partition by time
Queries try each partition in order until enough data is accumulated
LOCALITY
Problems w/ solution
• Write throughput
T-Bird Implementation
Partition by primary key
Finding recent tweets by user_id queries N partitions
T-Flock
Partition user_id index by user id
Principles
• Partition and index
• Index and partition
• Exploit locality (in this case, temporal locality)
• New tweets are requested most frequently, so usually only 1 partition is checked
The three data problems
• Tweets
• Timelines
• Social graphs
Timelines
Original Implementation
SELECT * FROM tweets
WHERE user_id IN
(SELECT source_id
FROM followers
WHERE destination_id = ?)
ORDER BY created_at DESC
LIMIT 20
Crazy slow if you have lots of friends or indices can’t be kept in RAM
OFF-LINE VS. ONLINE COMPUTATION
Current Implementation
• Sequences stored in Memcached
• Fanout off-line, but has a low latency SLA
• Truncate at random intervals to ensure bounded length
• On cache miss, merge user timelines
Social Graph
Intersection: Deliver to people who follow both @aplusk and @foursquare
Forward Backward
• Partitioned by user id
• Edges stored in “forward” and “backward” directions
• Indexed by time
• Indexed by element (for set algebra)
• Denormalized cardinality
Challenges
• Data consistency in the presence of failures
• Write operations are idempotent: retry until success
• Last-Write Wins for edges
• (with an ordering relation on State for time conflicts)
• Other commutative strategies for mass-writes
• It is not possible to pre-compute set algebra queries
• Partition, replicate, index.
Many efficiency and scalability problems are solved the same way
Principles
• All engineering solutions are transient
• Nothing’s perfect but some solutions are good enough for a while
• Scalability solutions aren’t magic. They involve partitioning, indexing, and replication
• All data for real-time queries MUST be in memory.
Disk is for writes only.
• Some problems can be solved with pre-computation, but a lot can’t
• Exploit locality where possible
http://highscalability.com/blog/2012/1/17/paper-feeding-frenzy-selectively-materializing-users-event-f.html
The best policy is to decide whether to push or pull events on a per producer/consumer basis. This technique minimizes system cost both for workloads with a high query rate and those with a high event rate. It also exposes a knob, the push threshold, that we can tune to reduce latency in return for higher system cost.
Near real-time event streams are becoming a key feature of many popular web applications. Many web sites allow users to create a personalized feed by selecting one or more event streams they wish to follow.
Examples include Twitter and Facebook, which allow a user to follow other users' activity, and iGoogle and My Yahoo, which allow users to follow selected RSS streams. How can we efficiently construct a web page showing the latest events from a user's feed?
Constructing such a feed must be fast so the page loads quickly, yet reflects recent updates to the underlying event streams. The wide fanout of popular streams (those with many followers) and high skew (fanout and update rates vary widely) make it difficult to scale such applications.
We associate feeds with consumers and event streams with producers.
We demonstrate that the best performance results from selectively materializing each consumer's feed:
events from high-rate producers are retrieved at query time, while events from lower-rate producers are materialized in advance.
A formal analysis of the problem shows the surprising result that we can minimize global cost by making local decisions about each producer/consumer pair, based on the ratio between a given producer's update rate (how often an event is added to the stream) and a given consumer's view rate (how often the feed is viewed). Our experimental results, using Yahoo!'s web-scale database PNUTS, shows that this hybrid strategy results in the lowest system load (and hence improves scalability) under a variety of workloads.
http://stackoverflow.com/questions/1819446/how-is-twitters-mysql-database-architecture-designed-try-your-best
http://www.infoq.com/news/2009/06/Twitter-Architecture
http://highscalability.com/blog/2013/7/8/the-architecture-twitter-uses-to-deal-with-150m-active-users.html
http://www.infoq.com/presentations/Twitter-Timeline-Scalability
maintains persistent connections with end clients
⇢processes tweet & social graph events
⇢event-based “router”
Fast Data in the Era of Big Data: Twitter’s Real- Time Related Query Suggestion Architecture
Develop a real time query suggestion system
Real Time Query Suggestion
• Good related query suggestions provide:
• Topicality
• Temporality
• Topicality: capture same topic
• Temporality: capture temporal connection
• #SCOTUS suggestions: healthcare and #aca
• Marissa Mayer example
Real Time Query Suggestion
• Time constrain to include news breaks
• When is the best time to make suggestions ?
• Too early: No enough evidences
• Too late: User experience
http://blog.sina.com.cn/s/blog_46d0a3930100fc2v.html
Twitter 工程师认为,一个用户体验良好的网站,当一个用户请求到达以后,应该在平均500ms以内完成回应。而Twitter的理想,是达到200ms- 300ms的反应速度[17]。因此在网站架构上,Twitter大规模地,多层次多方式地使用缓存

1. 用户表:用户ID,姓名,登录名和密码,状态(在线与否)。
2. 短信表:短信ID,作者ID,正文(定长,140字),时间戳。
3. 用户关系表,记录追与被追的关系:用户ID,他追的用户IDs (Following),追他的用户IDs (Be followed)。
有没有必要把这几个核心的数据库表统统存放到缓存中去?Twitter的做法是把这些表拆解,把其中读写最频繁的列放进缓存。
1. Vector Cache and Row Cache
具 体来说,Twitter工程师认为最重要的列是IDs。即新发表的短信的IDs,以及被频繁阅读的热门短信的IDs,相关作者的IDs,以及订阅这些作者 的读者的IDs。把这些IDs存放进缓存 (Stores arrays of tweet pkeys [14])。在Twitter文献中,把存放这些IDs的缓存空间,称为Vector Cache [14]。
Twitter工程师认为,读取最频繁的内容是这些IDs,而短信的正文在其次。所以他们决定,在优先保证Vector Cache所需资源的前提下,其次重要的工作才是设立Row Cache,用于存放短信正文。
命中率(Hit Rate or Hit Ratio)是测量缓存效果的最重要指标。如果一个或者多个用户读取100条内容,其中99条内容存放在缓存中,那么缓存的命中率就是99%。命中率越高,说明缓存的贡献越大。
设立Vector Cache和Row Cache后,观测实际运行的结果,发现Vector Cache的命中率是99%,而Row Cache的命中率是95%,证实了Twitter工程师早先押注的,先IDs后正文的判断。
Vector Cache和Row Cache,使用的工具都是开源的MemCached [15]。
2. Fragment Cache and Page Cache
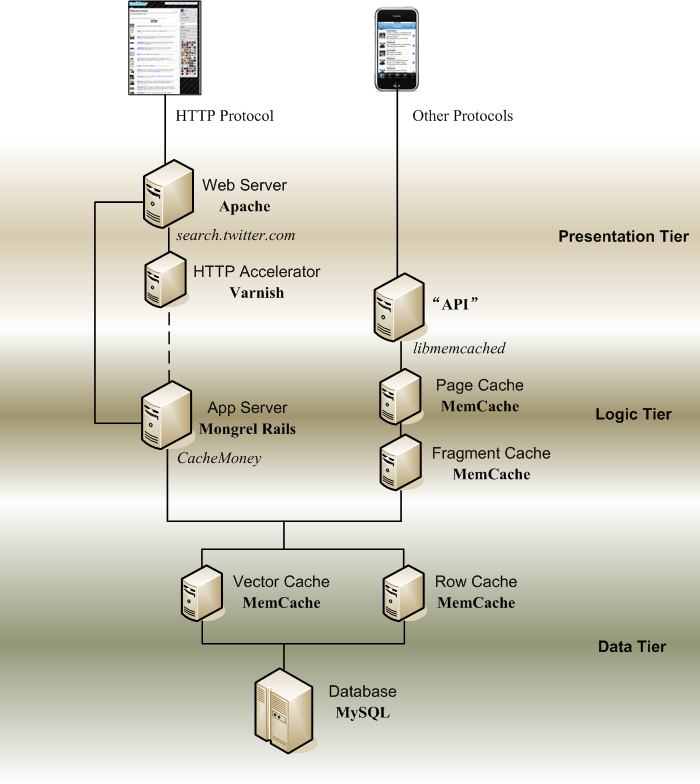
前文说到,访问Twitter网站的,不仅仅是浏览器,而且还有手机,还有像QQ那样的电脑桌面工具,另外还有各式各样的网站插件,以便把其它网站联系到 Twitter.com上来[12]。接待这两类用户的,是以Apache Web Server为门户的Web通道,以及被称为“API”的通道。其中API通道受理的流量占总流量的80%-90% [16]。
所以,继Vector Cache和Row Cache以后,Twitter工程师们把进一步建筑缓存的工作,重点放在如何提高API通道的反应速度上。
读者页面的主体,显示的是一条又一条短信。不妨把整个页面分割成若干局部,每个局部对应一条短信。所谓Fragment,就是指页面的局部。除短信外,其它内容例如Twitter logo等等,也是Fragment。如果一个作者拥有众多读者,那么缓存这个作者写的短信的布局页面(Fragment),就可以提高网站整体的读取效率。这就是Fragment Cache的使命。
对于一些人气很旺的作者,读者们不仅会读他写的短信,而且会访问他的主页,所以,也有必要缓存这些人气作者的个人主页。这就是Page Cache的使命。
观测实际运行的结果,Fragment Cache的命中率高达95%,而Page Cache的命中率只有40%。虽然Page Cache的命中率低,但是它的内容是整个个人主页,所以占用的空间却不小。为了防止Page Cache争夺Fragment Cache的空间,在物理部署时,Twitter工程师们把Page Cache分离到不同的机器上去。
3. HTTP Accelerator
解决了API通道的缓存问题,接下去Twitter工程师们着手处理Web通道的缓存问题。经过分析,他们认为Web通道的压力,主要来自于搜索。尤其是面临突发事件时,读者们会搜索相关短信,而不理会这些短信的作者,是不是自己“追”的那些作者。
要降低搜索的压力,不妨把搜索关键词,及其对应的搜索结果,缓存起来。Twitter工程师们使用的缓存工具,是开源项目Varnish [18]。
比较有趣的事情是,通常把Varnish部署在Web Server之外,面向Internet的位置。这样,当用户访问网站时,实际上先访问Varnish,读取所需内容。只有在Varnish没有缓存相应内容时,用户请求才被转发到Web Server上去。而Twitter的部署,却是把Varnish放在Apache Web Server内侧[19]。原因是Twitter的工程师们觉得Varnish的操作比较复杂,为了降低Varnish崩溃造成整个网站瘫痪的可能性,他们便采取了这种古 怪而且保守的部署方式。
当用户发表一条短信的时候,执行以下五个步骤,
1. 把该短信记录到“短信表” 中去。
2. 从“用户关系表”中取出追他的用户的IDs。
3. 有些追他的用户目前在线,另一些可能离线。在线与否的状态,可以在“用户表”中查到。过滤掉那些离线的用户的IDs。
4. 把那些追他的并且目前在线的用户的IDs,逐个推进一个队列(Queue)中去。
5. 从这个队列中,逐个取出那些追他的并且目前在线的用户的IDs,并且更新这些人的主页,也就是添加最新发表的这条短信。
以上这五个步骤,都由逻辑层(Logic Tier)负责。前三步容易解决,都是简单的数据库操作。最后两步,需要用到一个辅助工具,队列。队列的意义在于,分离了任务的产生与任务的执行。
为什么要使用消息队列?[14]的解释是“隔离用户请求与相关操作,以便烫平流量高峰 (Move operations out of the synchronous request cycle, amortize load over time)”。
其中洪峰时刻,Twitter网站每秒钟收到350条新短信,这个流量洪峰维持了大约5分钟。根据统计,平均每个Twitter用户被120人“追”,这就 是说,这350条短信,平均每条都要发送120次 [16]。这意味着,在这5分钟的洪峰时刻,Twitter网站每秒钟需要发送350 x 120 = 42,000条短信。
面对洪峰,如何才能保证网站不崩溃?办法是迅速接纳,但是推迟服务
如何实施隔离呢?当一位用户访问Twitter网站时,接待他的是Apache Web Server。Apache做的事情非常简单,它把用户的请求解析以后,转发给Mongrel Rails Sever,由Mongrel负责实际的处理。而Apache腾出手来,迎接下一位用户。这样就避免了在洪峰期间,用户连接不上Twitter网站的尴尬 局面。
虽然Apache的工作简单,但是并不意味着Apache可以接待无限多的用户。原因是Apache解析完用户请求,并且转发给 Mongrel Server以后,负责解析这个用户请求的进程(process),并没有立刻释放,而是进入空循环,等待Mongrel Server返回结果。这样,Apache能够同时接待的用户数量,或者更准确地说,Apache能够容纳的并发的连接数量(concurrent connections),实际上受制于Apache能够容纳的进程数量。Apache系统内部的进程机制参见Figure 5,其中每个Worker代表一个进程。
Apache能够容纳多少个并发连接呢?[22]的实验结果是4,000个,参见Figure 6。如何才能提高Apache的并发用户容量呢?一种思路是不让连接受制于进程。不妨把连接作为一个数据结构,存放到内存中去,释放进程,直到 Mongrel Server返回结果时,再把这个数据结构重新加载到进程上去。
事实上Yaws Web Server[24],就是这么做的[23]。所以,Yaws能够容纳80,000以上的并发连接,这并不奇怪。但是为什么Twitter用 Apache,而不用Yaws呢?或许是因为Yaws是用Erlang语言写的,而Twitter工程师对这门新语言不熟悉 (But you need in house Erlang experience [17])。
通过让Apache进程空循环的办法,迅速接纳用户的访问,推迟服务,说白了是个缓兵之计,目的是让用户不至于收到“HTTP 503”错误提示,“503错误”是指“服务不可用(Service Unavailable)”,也就是网站拒绝访问。
大禹治水,重在疏导。真正的抗洪能力,体现在蓄洪和泄洪两个方面。蓄洪容易理解,就是建水库,要么建一个超大的水库,要么造众多小水库。泄洪包括两个方面,1. 引流,2. 渠道。
对于Twitter系统来说,庞大的服务器集群,尤其是以MemCached为主的众多的缓存,体现了蓄洪的容量。引流的手段是Kestrel消息队列,用于传递控制指令。渠道是机器与机器之间的数据传输通道,尤其是通往MemCached的数据通道。渠道的优劣,在于是否通畅
Twitter系统的抗洪措施,体现在有效地控制数据流,保证在洪峰到达时,能够及时把数据疏散到多个机器上去,从而避免压力过度集中,造成整个系统的瘫痪
假设有两个作者,通过浏览器,在Twitter网站上发表短信。有一个读者,也通过浏览器,访问网站并阅读他们写的短信。
1. 作者的浏览器与网站建立连接,Apache Web Server分配一个进程(Worker Process)。作者登录,Twitter查找作者的ID,并作为Cookie,记忆在HTTP邮包的头属性里。
2. 浏览器上传作者新写的短信(Tweet),Apache收到短信后,把短信连同作者ID,转发给Mongrel Rails Server。然后Apache进程进入空循环,等待Mongrel的回复,以便更新作者主页,把新写的短信添加上去。
3. Mongrel收到短信后,给短信分配一个ID,然后把短信ID与作者ID,缓存到Vector MemCached服务器上去。
4. Mongrel通知Kestrel消息队列服务器,为每个作者及读者开设一个队列,队列的名称中隐含用户ID。如果Kestrel服务器中已经存在这些队列,那就延用以往的队列。
5. 同一台Mongrel Server,或者另一台Mongrel Server,在处理某个Kestrel队列中的消息前,从这个队列的名称中解析出相应的用户ID,这个用户,既可能是读者,也可能是作者。
6. Mongrel把更新后的作者的主页,传递给正在空循环的Apache的进程。该进程把作者主页主动传送(push)给作者的浏览器。
变买为租,应对洪峰,这是一个不错的思路。但是租来的计算资源怎么用,又是一个大问题。查看一下[35],不难发现Twitter把租赁来的计算资源,大部分用于增加Apache Web Server,而Apache是Twitter整个系统的最前沿的环节。
为什么Twitter很少把租赁来的计算资源,分配给Mongrel Rails Server,MemCached Servers,Varnish HTTP Accelerators等等其它环节?在回答这个问题以前,我们先复习一下前一章“数据流与控制流”的末尾,Twitter从写到读的6个步骤。
这6个步骤的前2步说到,每个访问Twitter网站的浏览器,都与网站保持长连接。目的是一旦有人发表新的短信,Twitter网站在500ms以内,把新短信push给他的读者。问题是在没有更新的时候,每个长连接占用一个Apache的进程,而这个进程处于空循环。所以,绝大多数Apache进程,在绝大多数时间里,处于空循环,因此占用了大量资源。
事实上,通过Apache Web Servers的流量,虽然只占Twitter总流量的10%-20%,但是Apache却占用了Twitter整个服务器集群的50%的资源[16]。 所以,从旁观者角度来看,Twitter将来势必罢黜Apache。但是目前,当Twitter分配计算资源时,迫不得已,只能优先保证Apache的需 求。
Twitter materializes (in memory) the items in each of the followers' inboxes
Original Implementation
Relational
• Single table, vertically scaled
• Master-Slave replication and Memcached for read throughput.
PARTITION
Partition by time
Queries try each partition in order until enough data is accumulated
LOCALITY
Problems w/ solution
• Write throughput
T-Bird Implementation
Partition by primary key
Finding recent tweets by user_id queries N partitions
T-Flock
Partition user_id index by user id
Principles
• Partition and index
• Index and partition
• Exploit locality (in this case, temporal locality)
• New tweets are requested most frequently, so usually only 1 partition is checked
The three data problems
• Tweets
• Timelines
• Social graphs
Timelines
Original Implementation
SELECT * FROM tweets
WHERE user_id IN
(SELECT source_id
FROM followers
WHERE destination_id = ?)
ORDER BY created_at DESC
LIMIT 20
Crazy slow if you have lots of friends or indices can’t be kept in RAM
OFF-LINE VS. ONLINE COMPUTATION
Current Implementation
• Sequences stored in Memcached
• Fanout off-line, but has a low latency SLA
• Truncate at random intervals to ensure bounded length
• On cache miss, merge user timelines
Social Graph
Intersection: Deliver to people who follow both @aplusk and @foursquare
Forward Backward
• Partitioned by user id
• Edges stored in “forward” and “backward” directions
• Indexed by time
• Indexed by element (for set algebra)
• Denormalized cardinality
Challenges
• Data consistency in the presence of failures
• Write operations are idempotent: retry until success
• Last-Write Wins for edges
• (with an ordering relation on State for time conflicts)
• Other commutative strategies for mass-writes
• It is not possible to pre-compute set algebra queries
• Partition, replicate, index.
Many efficiency and scalability problems are solved the same way
Principles
• All engineering solutions are transient
• Nothing’s perfect but some solutions are good enough for a while
• Scalability solutions aren’t magic. They involve partitioning, indexing, and replication
• All data for real-time queries MUST be in memory.
Disk is for writes only.
• Some problems can be solved with pre-computation, but a lot can’t
• Exploit locality where possible
http://highscalability.com/blog/2012/1/17/paper-feeding-frenzy-selectively-materializing-users-event-f.html
The best policy is to decide whether to push or pull events on a per producer/consumer basis. This technique minimizes system cost both for workloads with a high query rate and those with a high event rate. It also exposes a knob, the push threshold, that we can tune to reduce latency in return for higher system cost.
Near real-time event streams are becoming a key feature of many popular web applications. Many web sites allow users to create a personalized feed by selecting one or more event streams they wish to follow.
Examples include Twitter and Facebook, which allow a user to follow other users' activity, and iGoogle and My Yahoo, which allow users to follow selected RSS streams. How can we efficiently construct a web page showing the latest events from a user's feed?
Constructing such a feed must be fast so the page loads quickly, yet reflects recent updates to the underlying event streams. The wide fanout of popular streams (those with many followers) and high skew (fanout and update rates vary widely) make it difficult to scale such applications.
We associate feeds with consumers and event streams with producers.
We demonstrate that the best performance results from selectively materializing each consumer's feed:
events from high-rate producers are retrieved at query time, while events from lower-rate producers are materialized in advance.
A formal analysis of the problem shows the surprising result that we can minimize global cost by making local decisions about each producer/consumer pair, based on the ratio between a given producer's update rate (how often an event is added to the stream) and a given consumer's view rate (how often the feed is viewed). Our experimental results, using Yahoo!'s web-scale database PNUTS, shows that this hybrid strategy results in the lowest system load (and hence improves scalability) under a variety of workloads.
http://stackoverflow.com/questions/1819446/how-is-twitters-mysql-database-architecture-designed-try-your-best
MySQL is not used for backup as mention in the previous answer but for actually storing the data.
They have developed their own database called FlockDB(graph database) which uses mySQL as back-end database along with other mechanisms for consistency,indexing etc.
More information about FlockDB and source code here:
But they have optimized their MySQL database schema in a way to perform extremely well with their queries.
More information about the schema here:
This is a diagram that might explain Twitter's architecture: 
http://www.infoq.com/news/2009/06/Twitter-Architecture
The first architectural change was to create a write-through Vector Cache containing an array of tweet IDs which are serialized 64 bit integers. This cache has a 99% hit rate.
The second change was adding another write-through Row Cache containing database records: users and tweets. This one has a 95% hit rate and it is using Nick Kallen’s Rails plug-in calledCache Money. Nick is a Systems Architect at Twitter.
The third change was introducing a read-through Fragment Cache containing serialized versions of the tweets accessed through API clients which could be packaged in JSON, XML or Atom, with the same 95% hit rate. The fragment cache “consumes the vectors directly, and if a serialized fragment is currently cached it doesn’t load the actual row for the tweet you are trying to see so it short-circuits the database the vast majority of times”, said Evan.
Yet another change was creating a separate cache pool for the page cache. According to Evan, the page cache pool uses a generational key scheme rather than direct invalidation because clients can
The MQ is meant to take the peak and disperse it over time so they would not have to add lots of extra hardware. http://highscalability.com/blog/2013/7/8/the-architecture-twitter-uses-to-deal-with-150m-active-users.html
http://www.infoq.com/presentations/Twitter-Timeline-Scalability
- Twitter is primarily a consumption mechanism, not a production mechanism. 300K QPS are spent reading timelines and only 6000 requests per second are spent on writes.
- Outliers, those with huge follower lists, are becoming a common case. Sending a tweet from a user with a lot of followers, that is with a large fanout, can be slow. Twitter tries to do it under 5 seconds, but it doesn’t always work, especially when celebrities tweet and tweet each other, which is happening more and more. One of the consequences is replies can arrive before the original tweet is received. Twitter is changing from doing all the work on writes to doing more work on reads for high value users.
- Trying to figure out how to merge the read and write paths. Not fanning out the high value users anymore. For people like Taylor Swift don’t bother with fanout anymore, instead merge in her timeline at read time. Balances read and write paths. Saves 10s of percents of computational resources.
- Your home timeline sits in a Redis cluster and has a maximum of 800 entries.
- Twitter knows a lot about you from who you follow and what links you click on. Much can be implied by the implicit social contract when bidirectional follows don’t exist.
====
The Challenge
- At 150 million users with 300K QPS for timelines (home and search) naive materialization can be slow.
- Naive materialization is a massive select statement over all of Twitter. It was tried and died.
- Solution is a write based fanout approach. Do a lot of processing when tweets arrive to figure out where tweets should go. This makes read time access fast and easy. Don’t do any computation on reads. With all the work being performed on the write path ingest rates are slower than the read path, on the order of 4000 QPS.
- The Platform Services group is responsible for the core scalable infrastructure of Twitter.
- They run things called the Timeline Service, Tweet Service, User Service, Social Graph Service, all the machinery that powers the Twitter platform.
- Contract with product teams is that they don’t have to worry about scale.
- Work on capacity planning, architecting scalable backend systems, constantly replacing infrastructure as the site grows in unexpected ways.
- Twitter has an architecture group. Concerned with overall holistic architecture of Twitter. Maintains technical debt list (what they want to get rid of).
Push Me Pull Me
- People are creating content on Twitter all the time. The job of Twitter is to figure out how to syndicate the content out. How to send it to your followers.
- The real challenge is the real-time constraint. Goal is to have a message flow to a user in no more than 5 seconds.
- Delivery means gathering content and exerting pressure on the Internet to get it back out again as fast as possible.
- Delivery is to in-memory timeline clusters, push notifications, emails that are triggered, all the iOS notifications as well as Blackberry and Android, SMSs.
Two main types of timelines: user timeline and home timeline.
- A user timeline is all the tweets a particular user has sent.
- A home timeline is a temporal merge of all the user timelines of the people are you are following.
- Business rules are applied. @replies of people that you don’t follow are stripped out. Retweets from a user can be filtered out.
High Level For Pull Based Timelines
- Tweet comes in over a write API. It goes through load balancers and a TFE (Twitter Front End) and other stuff that won’t be addressed.
- This is a very directed path. Completely precomputed home timeline. All the business rules get executed as tweets come in.
- Immediately the fanout process occurs. Tweets that come in are placed into a massive Redis cluster. Each tweet is replicated 3 times on 3 different machines. At Twitter scale many machines fail a day.
- Fanout queries the social graph service that is based on Flock. Flock maintains the follower and followings lists.
- Flock returns the social graph for a recipient and starts iterating through all the timelines stored in the Redis cluster.
- The Redis cluster has a couple of terabytes of RAM.
- Pipelined 4k destinations at a time
- Native list structure are used inside Redis.
- Let’s say you tweet and you have 20K followers. What the fanout daemon will do is look up the location of all 20K users inside the Redis cluster.
- Then it will start inserting the Tweet ID of the tweet into all those lists throughout the Redis cluster. So for every write of a tweet as many as 20K inserts are occurring across the Redis cluster.
- What is being stored is the tweet ID of the generated tweet, the user ID of the originator of the tweet, and 4 bytes of bits used to mark if it’s a retweet or a reply or something else.
- Your home timeline sits in a Redis cluster and is 800 entries long. If you page back long enough you’ll hit the limit. RAM is the limiting resource determining how long your current tweet set can be.
- Every active user is stored in RAM to keep latencies down.
- Active user is someone who has logged into Twitter within 30 days, which can change depending on cache capacity or Twitter’s usage.
- If you are not an active user then the tweet does not go into the cache.
- Only your home timelines hit disk.
- If you fall out of the Redis cluster then you go through a process called reconstruction.
- Query against the social graph service. Figure out who you follow. Hit disk for every single one of them and then shove them back into Redis.
- t’s MySQL handling disk storage via Gizzard, which abstracts away SQL transactions and provides global replication.
- By replicating 3 times if a machine has a problem then they won’t have to recreate the timelines for all the timelines on that machine per datacenter.
- If a tweet is actually a retweet then a pointer is stored to the original tweet.
- When you query for your home timeline the Timeline Service is queried. The Timeline Service then only has to find one machine that has your home timeline on it.
- Effectively running 3 different hash rings because your timeline is in 3 different places.
- They find the first one they can get to fastest and return it as fast as they can.
- The tradeoff is fanout takes a little longer, but the read process is fast. About 2 seconds from a cold cache to the browser. For an API call it’s about 400 msec.
- Since the timeline only contains tweet IDs they must “hydrate” those tweets, that is find the text of the tweets. Given an array of IDs they can do a multiget and get the tweets in parallel from T-bird.
- Gizmoduck is the user service and Tweetypie is the tweet object service. Each service has their own caches. The user cache is a memcache cluster that has the entire user base in cache. Tweetypie has about the last month and half of tweets stored in its memcache cluster. These are exposed to internal customers.
- Some read time filtering happens at the edge. For example, filtering out Nazi content in France, so there’s read time stripping of the content before it is sent out.
High Level For Search
- Opposite of pull. All computed on the read path which makes the write path simple.
- As a tweet comes in, the Ingester tokenizes and figures out everything they want to index against and stuffs it into a single Early Bird machine. Early Bird is a modified version of Lucene. The index is stored in RAM.
- In fanout a tweet may be stored in N home timelines of how many people are following you, in Early Bird a tweet is only stored in one Early Bird machine (except for replication).
- Blender creates the search timeline. It has to scatter-gather across the datacenter. It queries every Early Bird shard and asks do you have content that matches this query? If you ask for “New York Times” all shards are queried, the results are returned, sorted, merged, and reranked.
- Rerank is by social proof, which means looking at the number of retweets, favorites, and replies.
- The activity information is computed on a write basis, there’s an activity timeline. As you are favoriting and replying to tweets an activity timeline is maintained, similar to the home timeline, it is a series of IDs of pieces of activity, so there’s favorite ID, a reply ID, etc.
- All this is fed into the Blender. On the read path it recomputes, merges, and sorts. Returning what you see as the search timeline.
- Discovery is a customized search based on what they know about you. And they know a lot because you follow a lot of people, click on links, that information is used in the discovery search. It reranks based on the information it has gleaned about you.
maintains persistent connections with end clients
⇢processes tweet & social graph events
⇢event-based “router”
Fast Data in the Era of Big Data: Twitter’s Real- Time Related Query Suggestion Architecture
Develop a real time query suggestion system
Real Time Query Suggestion
• Good related query suggestions provide:
• Topicality
• Temporality
• Topicality: capture same topic
• Temporality: capture temporal connection
• #SCOTUS suggestions: healthcare and #aca
• Marissa Mayer example
Real Time Query Suggestion
• Time constrain to include news breaks
• When is the best time to make suggestions ?
• Too early: No enough evidences
• Too late: User experience
http://blog.sina.com.cn/s/blog_46d0a3930100fc2v.html
Twitter 工程师认为,一个用户体验良好的网站,当一个用户请求到达以后,应该在平均500ms以内完成回应。而Twitter的理想,是达到200ms- 300ms的反应速度[17]。因此在网站架构上,Twitter大规模地,多层次多方式地使用缓存
1. 用户表:用户ID,姓名,登录名和密码,状态(在线与否)。
2. 短信表:短信ID,作者ID,正文(定长,140字),时间戳。
3. 用户关系表,记录追与被追的关系:用户ID,他追的用户IDs (Following),追他的用户IDs (Be followed)。
有没有必要把这几个核心的数据库表统统存放到缓存中去?Twitter的做法是把这些表拆解,把其中读写最频繁的列放进缓存。
1. Vector Cache and Row Cache
具 体来说,Twitter工程师认为最重要的列是IDs。即新发表的短信的IDs,以及被频繁阅读的热门短信的IDs,相关作者的IDs,以及订阅这些作者 的读者的IDs。把这些IDs存放进缓存 (Stores arrays of tweet pkeys [14])。在Twitter文献中,把存放这些IDs的缓存空间,称为Vector Cache [14]。
Twitter工程师认为,读取最频繁的内容是这些IDs,而短信的正文在其次。所以他们决定,在优先保证Vector Cache所需资源的前提下,其次重要的工作才是设立Row Cache,用于存放短信正文。
命中率(Hit Rate or Hit Ratio)是测量缓存效果的最重要指标。如果一个或者多个用户读取100条内容,其中99条内容存放在缓存中,那么缓存的命中率就是99%。命中率越高,说明缓存的贡献越大。
设立Vector Cache和Row Cache后,观测实际运行的结果,发现Vector Cache的命中率是99%,而Row Cache的命中率是95%,证实了Twitter工程师早先押注的,先IDs后正文的判断。
Vector Cache和Row Cache,使用的工具都是开源的MemCached [15]。
2. Fragment Cache and Page Cache
前文说到,访问Twitter网站的,不仅仅是浏览器,而且还有手机,还有像QQ那样的电脑桌面工具,另外还有各式各样的网站插件,以便把其它网站联系到 Twitter.com上来[12]。接待这两类用户的,是以Apache Web Server为门户的Web通道,以及被称为“API”的通道。其中API通道受理的流量占总流量的80%-90% [16]。
所以,继Vector Cache和Row Cache以后,Twitter工程师们把进一步建筑缓存的工作,重点放在如何提高API通道的反应速度上。
读者页面的主体,显示的是一条又一条短信。不妨把整个页面分割成若干局部,每个局部对应一条短信。所谓Fragment,就是指页面的局部。除短信外,其它内容例如Twitter logo等等,也是Fragment。如果一个作者拥有众多读者,那么缓存这个作者写的短信的布局页面(Fragment),就可以提高网站整体的读取效率。这就是Fragment Cache的使命。
对于一些人气很旺的作者,读者们不仅会读他写的短信,而且会访问他的主页,所以,也有必要缓存这些人气作者的个人主页。这就是Page Cache的使命。
观测实际运行的结果,Fragment Cache的命中率高达95%,而Page Cache的命中率只有40%。虽然Page Cache的命中率低,但是它的内容是整个个人主页,所以占用的空间却不小。为了防止Page Cache争夺Fragment Cache的空间,在物理部署时,Twitter工程师们把Page Cache分离到不同的机器上去。
3. HTTP Accelerator
解决了API通道的缓存问题,接下去Twitter工程师们着手处理Web通道的缓存问题。经过分析,他们认为Web通道的压力,主要来自于搜索。尤其是面临突发事件时,读者们会搜索相关短信,而不理会这些短信的作者,是不是自己“追”的那些作者。
要降低搜索的压力,不妨把搜索关键词,及其对应的搜索结果,缓存起来。Twitter工程师们使用的缓存工具,是开源项目Varnish [18]。
比较有趣的事情是,通常把Varnish部署在Web Server之外,面向Internet的位置。这样,当用户访问网站时,实际上先访问Varnish,读取所需内容。只有在Varnish没有缓存相应内容时,用户请求才被转发到Web Server上去。而Twitter的部署,却是把Varnish放在Apache Web Server内侧[19]。原因是Twitter的工程师们觉得Varnish的操作比较复杂,为了降低Varnish崩溃造成整个网站瘫痪的可能性,他们便采取了这种古 怪而且保守的部署方式。
当用户发表一条短信的时候,执行以下五个步骤,
1. 把该短信记录到“短信表” 中去。
2. 从“用户关系表”中取出追他的用户的IDs。
3. 有些追他的用户目前在线,另一些可能离线。在线与否的状态,可以在“用户表”中查到。过滤掉那些离线的用户的IDs。
4. 把那些追他的并且目前在线的用户的IDs,逐个推进一个队列(Queue)中去。
5. 从这个队列中,逐个取出那些追他的并且目前在线的用户的IDs,并且更新这些人的主页,也就是添加最新发表的这条短信。
以上这五个步骤,都由逻辑层(Logic Tier)负责。前三步容易解决,都是简单的数据库操作。最后两步,需要用到一个辅助工具,队列。队列的意义在于,分离了任务的产生与任务的执行。
为什么要使用消息队列?[14]的解释是“隔离用户请求与相关操作,以便烫平流量高峰 (Move operations out of the synchronous request cycle, amortize load over time)”。
其中洪峰时刻,Twitter网站每秒钟收到350条新短信,这个流量洪峰维持了大约5分钟。根据统计,平均每个Twitter用户被120人“追”,这就 是说,这350条短信,平均每条都要发送120次 [16]。这意味着,在这5分钟的洪峰时刻,Twitter网站每秒钟需要发送350 x 120 = 42,000条短信。
面对洪峰,如何才能保证网站不崩溃?办法是迅速接纳,但是推迟服务
如何实施隔离呢?当一位用户访问Twitter网站时,接待他的是Apache Web Server。Apache做的事情非常简单,它把用户的请求解析以后,转发给Mongrel Rails Sever,由Mongrel负责实际的处理。而Apache腾出手来,迎接下一位用户。这样就避免了在洪峰期间,用户连接不上Twitter网站的尴尬 局面。
虽然Apache的工作简单,但是并不意味着Apache可以接待无限多的用户。原因是Apache解析完用户请求,并且转发给 Mongrel Server以后,负责解析这个用户请求的进程(process),并没有立刻释放,而是进入空循环,等待Mongrel Server返回结果。这样,Apache能够同时接待的用户数量,或者更准确地说,Apache能够容纳的并发的连接数量(concurrent connections),实际上受制于Apache能够容纳的进程数量。Apache系统内部的进程机制参见Figure 5,其中每个Worker代表一个进程。
Apache能够容纳多少个并发连接呢?[22]的实验结果是4,000个,参见Figure 6。如何才能提高Apache的并发用户容量呢?一种思路是不让连接受制于进程。不妨把连接作为一个数据结构,存放到内存中去,释放进程,直到 Mongrel Server返回结果时,再把这个数据结构重新加载到进程上去。
事实上Yaws Web Server[24],就是这么做的[23]。所以,Yaws能够容纳80,000以上的并发连接,这并不奇怪。但是为什么Twitter用 Apache,而不用Yaws呢?或许是因为Yaws是用Erlang语言写的,而Twitter工程师对这门新语言不熟悉 (But you need in house Erlang experience [17])。
通过让Apache进程空循环的办法,迅速接纳用户的访问,推迟服务,说白了是个缓兵之计,目的是让用户不至于收到“HTTP 503”错误提示,“503错误”是指“服务不可用(Service Unavailable)”,也就是网站拒绝访问。
大禹治水,重在疏导。真正的抗洪能力,体现在蓄洪和泄洪两个方面。蓄洪容易理解,就是建水库,要么建一个超大的水库,要么造众多小水库。泄洪包括两个方面,1. 引流,2. 渠道。
对于Twitter系统来说,庞大的服务器集群,尤其是以MemCached为主的众多的缓存,体现了蓄洪的容量。引流的手段是Kestrel消息队列,用于传递控制指令。渠道是机器与机器之间的数据传输通道,尤其是通往MemCached的数据通道。渠道的优劣,在于是否通畅
Twitter系统的抗洪措施,体现在有效地控制数据流,保证在洪峰到达时,能够及时把数据疏散到多个机器上去,从而避免压力过度集中,造成整个系统的瘫痪
假设有两个作者,通过浏览器,在Twitter网站上发表短信。有一个读者,也通过浏览器,访问网站并阅读他们写的短信。
1. 作者的浏览器与网站建立连接,Apache Web Server分配一个进程(Worker Process)。作者登录,Twitter查找作者的ID,并作为Cookie,记忆在HTTP邮包的头属性里。
2. 浏览器上传作者新写的短信(Tweet),Apache收到短信后,把短信连同作者ID,转发给Mongrel Rails Server。然后Apache进程进入空循环,等待Mongrel的回复,以便更新作者主页,把新写的短信添加上去。
3. Mongrel收到短信后,给短信分配一个ID,然后把短信ID与作者ID,缓存到Vector MemCached服务器上去。
4. Mongrel通知Kestrel消息队列服务器,为每个作者及读者开设一个队列,队列的名称中隐含用户ID。如果Kestrel服务器中已经存在这些队列,那就延用以往的队列。
5. 同一台Mongrel Server,或者另一台Mongrel Server,在处理某个Kestrel队列中的消息前,从这个队列的名称中解析出相应的用户ID,这个用户,既可能是读者,也可能是作者。
6. Mongrel把更新后的作者的主页,传递给正在空循环的Apache的进程。该进程把作者主页主动传送(push)给作者的浏览器。
变买为租,应对洪峰,这是一个不错的思路。但是租来的计算资源怎么用,又是一个大问题。查看一下[35],不难发现Twitter把租赁来的计算资源,大部分用于增加Apache Web Server,而Apache是Twitter整个系统的最前沿的环节。
为什么Twitter很少把租赁来的计算资源,分配给Mongrel Rails Server,MemCached Servers,Varnish HTTP Accelerators等等其它环节?在回答这个问题以前,我们先复习一下前一章“数据流与控制流”的末尾,Twitter从写到读的6个步骤。
这6个步骤的前2步说到,每个访问Twitter网站的浏览器,都与网站保持长连接。目的是一旦有人发表新的短信,Twitter网站在500ms以内,把新短信push给他的读者。问题是在没有更新的时候,每个长连接占用一个Apache的进程,而这个进程处于空循环。所以,绝大多数Apache进程,在绝大多数时间里,处于空循环,因此占用了大量资源。
事实上,通过Apache Web Servers的流量,虽然只占Twitter总流量的10%-20%,但是Apache却占用了Twitter整个服务器集群的50%的资源[16]。 所以,从旁观者角度来看,Twitter将来势必罢黜Apache。但是目前,当Twitter分配计算资源时,迫不得已,只能优先保证Apache的需 求。