Apache Storm does not have any state managing capabilities. It instead utilizes Apache ZooKeeper to manage its cluster state such as message acknowledgements, processing status etc. This enables Storm to start right from where it left even after the restart.
Since Storm's master node (called Nimbus) is a Thrift service, one can create and submit processing logic graph (called topology) in any programming language.
- Nimbus Service on Master Node - Nimbus is a daemon that runs on the master node of Storm cluster. It is responsible for distributing the code among the worker nodes, assigning input data sets to machines for processing and monitoring for failures.Nimbus service is an Apache Thrift service enabling you to submit the code in any programming language. This way, you can always utilize the language that you are proficient in, without the need of learning a new language to utilize Apache Storm.
Nimbus service relies on Apache ZooKeeper service to monitor the message processing tasks as all the worker nodes update their tasks status in Apache ZooKeeper service. - Supervisor Service on Worker Node - All the workers nodes in Storm cluster run a daemon called Supervisor. Supervisor service receives the work assigned to a machine by Nimbus service. Supervisor manages worker processes to complete the tasks assigned by Nimbus. Each of these worker processes executes a subset of topology.
- Topology - Topology, in simple terms, is a graph of computation. Each node in a topology contains processing logic, and links between nodes indicate how data should be passed around between nodes. A Topology typically runs distributively on multiple workers processes on multiple worker nodes.
- Spout - A Topology starts with a spout, source of streams. A stream is made of unbounded sequence of tuples. A spout may read tuples off a messaging framework and emit them as stream of messages or it may connect to twitter API and emit a stream of tweets.
- Bolt - A Bolt represents a node in a topology. It defines smallest processing logic within a topology. Output of a bolt can be fed into another bolt as input in a topology.
- Scalable - Storm scales to massive numbers of messages per second. To scale a topology, all you have to do is add machines and increase the parallelism settings of the topology. As an example of Storm's scale, one of Storm's initial applications processed 1,000,000 messages per second on a 10 node cluster, including hundreds of database calls per second as part of the topology. Storm's usage of Zookeeper for cluster coordination makes it scale to much larger cluster sizes.
- Guarantees no data loss - A realtime system must have strong guarantees about data being successfully processed. A system that drops data has a very limited set of use cases. Storm guarantees that every message will be processed, and this is in direct contrast with other systems like S4.
- Extremely robust - Unlike systems like Hadoop, which are notorious for being difficult to manage, Storm clusters just work. It is an explicit goal of the Storm project to make the user experience of managing Storm clusters as painless as possible.
- Fault-tolerant - If there are faults during execution of your computation, Storm will reassign tasks as necessary. Storm makes sure that a computation can run forever (or until you kill the computation).
- Programming language agnostic - Robust and scalable realtime processing shouldn't be limited to a single platform. Storm topologies and processing components can be defined in any language, making Storm accessible to nearly anyone.
http://blog.jobbole.com/93813/
Storm是twitter开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。Storm有很多使用场景:如实时分析,在线机器学习,持续计算,分布式 RPC,ETL等等。Storm支持水平扩展, 具有高容错性,保证每个消息都会得到处理,而且处理速度很快(在一个小集群中,每个结点每秒可以处理数以百万计的消息)。
2.1 基础部件

1)Nimbus 负责在集群里面发送代码,分配工作给机器,并且监控状态。 全局只有一个。
2)Supervisor 会监听分配给它那台机器的工作,根据需要启动/关闭工作进程Worker。
3) Zookeeper是Storm重点依赖的外部资源。 Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。
4)Storm ui 是storm的监控界面,能清楚的看到所有逻辑节点的处理情况。
Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。并且,nimbus进程和supervisor都是快速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死nimbus和supervisor进程, 然后再重启它们,它们可以继续工作, 就好像什么都没有发生过似的。这个设计使得storm不可思议的稳定
2.2 逻辑单元
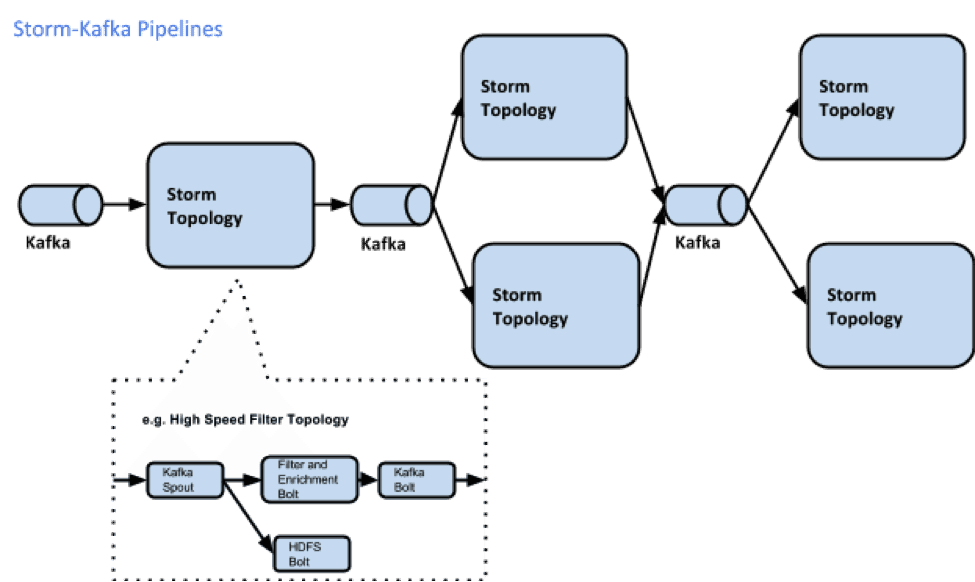
Storm提交运行的程序称为Topology,结构如下图所示:

Topology由Spout和Bolt构成。Spout是发出Tuple的结点,Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。
Tuple是Topology处理的最小的消息单位,也就是一个任意对象的数组。每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型。总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类型。你也可以使用你自己定义的类型来作为值类型, 只要你实现对应的序列化器(serializer)。
每个tuple都由两种状态:fail和ack。Storm里面有一类特殊的task称为acker, 他们负责跟踪spout发出的每一个tuple的tuple树。当acker发现一个tuple树已经处理完成了。它会发送一个消息给产生这个tuple的那个task。
4. storm的监控
虽然storm的ui的信息展示非常全面,但它毕竟是一个被动的信息展示页面,对于storm集群,我们还是需要做更加完善的监控和报警。
4.1 原则
1)Zookeeper是fail-fast的系统,只要出现什么错误就会退出,所以一定要监控
2)Zookeeper运行过程中会生成很多日志和快照文件,必须定期清理
3)对于每个进程都要有监控!storm是一个fail-fast系统,出现什么不可预知的错误的时候它都会退出的 。
4)除了对于storm的流量监控,还需要对业务的处理情况(qps,时延等)进行监控
4.2 主要功能
1)对zookeeper进行mock,看是否正常,如果down了需要及时重启。
2)监控supervisor数目是否正确,当supervisor挂掉的时候会发送警告。
3)监控nimbus是否正常运行,monitor会尝试连接nimbus,如果连接失败就认为nimbus挂掉。
4)监控topology是否正常运行,包括它是否正常部署,是否有运行中的任务。
5)对worker的日志进行统计,监控处理消息的时间与消息产生时间的时间间隔
4.3 实现方式
1)对于zookeeper,和woker的日志统计,可以通过一些简单shell程序来定期运行。
2)对于nimbus、topology和supervisor,基本的原理很简单,对supervisor和topology的监控是通过zookeeper来间接地监控,通过定期查看path是否存在。对nimbus的监控是每次起一个短连接连上去,连不上去即认为挂掉。我们便可以使用thrift的python客户端来获取cluster的信息,然后与监控和报警系统打通
Storm Applied: Strategies for real-time event processingBatch processing
Stream processing
Micro-batch processing within a stream
But unlike a stream processor that allows you access to every data point within it, a micro-batch processor groups the incoming data into batches in some fashion and gives you a batch at a time.
What’s interesting about Spark is that it allows caching of intermediate (or final) results in memory (with overflow to disk as needed). This ability can be highly useful for processes that run repeatedly over the same data sets and can make use of the previous calculations in an algorithmically meaningful manner.
A Storm topology is a graph of computation where the nodes represent some individual computations and the edges represent the data being passed between nodes.
Tuple
The nodes in our topology send data between one another in the form of tuples. A tuple is an ordered list of values, where each value is assigned a name. A node can create and then (optionally) send tuples to any number of nodes in the graph. The process of sending a tuple to be handled by any number of nodes is called emitting a tuple.
A tuple is an ordered list of values and Storm provides mechanisms for assigning names to the values within this list;
Spout
A spout is the source of a stream in the topology. Spouts normally read data from an external data source and emit tuples into the topology. Spouts can listen to message queues for incoming messages, listen to a database for changes, or listen to any other source of a feed of data.
Spouts don’t perform any processing; they simply act as a source of streams, reading from a data source and emitting tuples to the next type of node in a topology: the bolt.
a bolt accepts a tuple from its input stream, performs some computation or transformation—filtering, aggregation, or a join, perhaps—on that tuple, and then optionally emits a new tuple (or tuples) to its output stream(s).
A topology consists of nodes and edges.
Nodes represent either spouts or bolts.
Edges represent streams of tuples between these spouts and bolts.
A tuple is an ordered list of values, where each value is assigned a name.
A stream is an unbounded sequence of tuples between a spout and a bolt or between two bolts.
A spout is the source of a stream in a topology, usually listening to some sort of live feed of data.
A bolt accepts a stream of tuples from a spout or another bolt, typically performing some sort of computation or transformation on these input tuples. The bolt can then optionally emit new tuples that serve as the input stream to another bolt in the topology.
Each spout and bolt will have one or many individual instances that perform all of this processing in parallel.
Stream grouping
Shuffle grouping - tuples are emitted to instances of bolts at random
Using a shuffle grouping will guarantee that each bolt instance should receive a relatively equal number of tuples, thus spreading the load across all bolt instances.
Fields grouping
A fields grouping ensures that tuples with the same value for a particular field name are always emitted to the same instance of a bolt.
The order of the names in the Fields constructor must match the order of the values emitted in the tuple via the Values class.
nextTuple is the method Storm calls when it’s ready for the spout to read and emit a new tuple and is usually invoked periodically as determined by Storm
Wiring everything together to form the topology
TopologyBuilder— This class is used to piece together spouts and bolts, defining the streams and stream groupings between them.
Config— This class is used for defining topology-level configuration.
StormTopology— This class is what TopologyBuilder builds and is what’s submitted to the cluster to be run.
LocalCluster— This class simulates a Storm cluster in-process on our local machine, allowing us to easily run our topologies for testing purposes.