http://stackoverflow.com/questions/1936462/java-linkedhashmap-get-first-or-last-entry
http://bookshadow.com/weblog/2016/10/27/java-linked-hash-map-get-first-and-get-last/
http://stackoverflow.com/questions/2923856/is-the-order-guaranteed-for-the-return-of-keys-and-values-from-a-linkedhashmap-o
In HashMap, the data structure is based on array and linked list. An entry finds its location in the array based on its hash value. If an array element is already occupied, the new entry replaces the old entry and the old entry is linked to the new one.
In HashMap, there is no control on the iteration order.
In LinkedHashMap, the iteration order is defined, either by the insertion order or access order.

Below is the
 Entry
Entry

Java LinkedHashMap源码解析
HashSet 内部用一个HashMap对象存储数据,更具体些,只用到了key,value全部为一dummy对象
LinkedHashMap是key键有序的HashMap的一种实现。它除了使用哈希表这个数据结构,使用双向链表来保证key的顺序.
增加节点
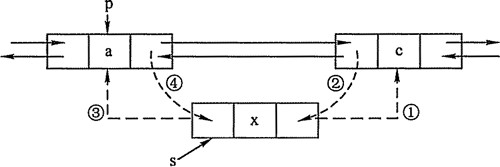 增加节点
增加节点
上图中的c节点相当于下面代码中的existingEntry,要插入的是x节点
The semantics of
LinkedHashMap are still those of a Map, rather than that of a LinkedList. It retains insertion order, yes, but that's an implementation detail, rather than an aspect of its interface.
The quickest way to get the "first" entry is still
entrySet().iterator().next(). Getting the "last" entry is possible, but will entail iterating over the whole entry set by calling .next() until you reach the last. while (iterator.hasNext()) { lastElement = iterator.next() }
edit: However, if you're willing to go beyond the JavaSE API, Apache Commons Collections has its own
LinkedMap implementation, which has methods like firstKey and lastKey, which do what you're looking for. The interface is considerably richer.
获取LinkedHashMap中的头部元素(最早添加的元素):
时间复杂度O(1)
- 1
- 2
- 3
获取LinkedHashMap中的末尾元素(最近添加的元素):
时间复杂度O(n)
http://stackoverflow.com/questions/31788380/iterate-over-linkedhashmap-in-reverseList<Entry<Foo,Bar>> list = new ArrayList<Entry<Foo,Bar>>(map.entries());
for (int i = list.size() - 1; i >= 0; i--) {
Entry<Foo,Bar> entry = list.get(i);
}
Obviously, the trade off here is that you have to copy the whole map into the array list. If your map is too big (whatever is too big), you might have performance and memory problems.
This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (insertion-order).
So, yes,
keySet(), values(), and entrySet() (the three collection views mentioned) return values in the order the internal linked list uses. And yes, the JavaDoc for Map and LinkedHashMapguarantee it.The Map interface provides three collection views, which allow a map's contents to be viewed as a set of keys, collection of values, or set of key-value mappings. The order of a map is defined as the order in which the iterators on the map's collection views return their elements. Some map implementations, like theTreeMapclass, make specific guarantees as to their order; others, like theHashMapclass, do not.
-- Map
the iteration over the map is also done faster using a LinkedHashMap than a HashMap.
Don't get confused with
LinkedHashMap.keySet() and LinkedHashMap.entrySet() returning Set and hence it should not guarantee ordering !Set is an interface with HashSet,TreeSet etc beings its implementations. The HashSetimplementation of Set interface does not guarantees ordering. But TreeSet does. Also LinkedHashSet does.
Therefore it depends on how
Set has been implemented in LinkedHashMap to know whether the returning Set reference will guarantee ordering or not. I went through the source code of LinkedHashMap, it looks like this:private final class KeySet extends AbstractSet<K> {...}
public abstract class AbstractSet<E> extends AbstractCollection<E> implements Set<E> {...}
Thus LinkedHashMap/HashMap has its own implementation of
Set i.e. KeySet. Thus don't confuse this with HashSet.
Also, the order is maintained by how the elements are inserted into the bucket. Look at the
http://javarticles.com/2012/06/linkedhashmap.htmladdEntry(..) method of LinkedHashMap and compare it with that of HashMap which highlights the main difference between HashMap and LinkedHashMap.LinkedHashMap is a HashMap that also defines the iteration ordering using an additional data structure, a double linked list. By default, the iteration order is same as insertion-order. It can also be the order in which its entries were last accessed so it can be easily extended to buildLRU cache.In HashMap, the data structure is based on array and linked list. An entry finds its location in the array based on its hash value. If an array element is already occupied, the new entry replaces the old entry and the old entry is linked to the new one.
In HashMap, there is no control on the iteration order.
In LinkedHashMap, the iteration order is defined, either by the insertion order or access order.
LinkedHashMap differs from HashMap in that it maintains a doubly-linked list running through all of its entries. The below one is a modified example of the above data structure. It defines the iteration ordering based on the order in which keys were inserted into the map. In order to do so, the entry element is extended to keep track of the after and before element. A zero size LinkedHashMap contains just the Head element with before and after pointing to itself.
Below is the
HashMap data structure:
LinkedHashMap's Entry extends the HashMap's Entry so it also inherits the same properties key, value, hash and the next Entry sharing the index. Other than these, it also has couple of additional properties to maintain the double-linked list, after and before entries.
it also maintains a double-linked list which is circularly linked via the sentinel node called head. Each node contains references to the previous and to the next node . A new node is always added to the end of the list. In order to do so, the last node’s and the header node’s links have to be adjusted.
- The new node’s next reference will point to the head.
- The new node’s previous reference will point to the current last node.
- The current last node’s next reference will point to the new node instead of head.
- Head’s previous reference will point to the new node.
Performance is likely to be just slightly below that of
http://stackoverflow.com/questions/3020601/how-is-the-implementation-of-linkedhashmap-different-from-hashmapHashMap, due to the added expense of maintaining the linked list.
LinkedHashMap will take more memory. Each entry in a normal
HashMap just has the key and the value. Each LinkedHashMap entry has those references and references to the next and previous entries. There's also a little bit more housekeeping to do, although that's usually irrelevant.HashSet 内部用一个HashMap对象存储数据,更具体些,只用到了key,value全部为一dummy对象
|
|
可以看到,LinkedHashMap是HashMap的一子类,它根据自身的特性修改了HashMap的内部某些方法的实现.
LinkedHashMap是key键有序的HashMap的一种实现。它除了使用哈希表这个数据结构,使用双向链表来保证key的顺序.
LinkedHashMap的出现就是为了平衡这些因素,使得
能够以O(1)时间复杂度增加查找元素,又能够保证key的有序性
此外,LinkedHashMap提供了两种key的顺序:
- 访问顺序(access order)。非常实用,可以使用这种顺序实现LRU(Least Recently Used)缓存
- 插入顺序(insertion orde)。同一key的多次插入,并不会影响其顺序
private static class Entry<K,V> extends HashMap.Entry<K,V> {// These fields comprise the doubly linked list used for iteration.//每个节点包含两个指针,指向前继节点与后继节点Entry<K,V> before, after;Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {super(hash, key, value, next);}/*** Removes this entry from the linked list.*///删除一个节点时,需要把//1. 前继节点的后继指针 指向 要删除节点的后继节点//2. 后继节点的前继指针 指向 要删除节点的前继节点private void remove() {before.after = after;after.before = before;}/*** Inserts this entry before the specified existing entry in the list.*///在某节点前插入节点private void addBefore(Entry<K,V> existingEntry) {after = existingEntry;before = existingEntry.before;before.after = this;after.before = this;}/*** This method is invoked by the superclass whenever the value* of a pre-existing entry is read by Map.get or modified by Map.set.* If the enclosing Map is access-ordered, it moves the entry* to the end of the list; otherwise, it does nothing.*/void recordAccess(HashMap<K,V> m) {LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;// 如果需要key的访问顺序,需要把// 当前访问的节点删除,并把它插入到双向链表的起始位置if (lm.accessOrder) {lm.modCount++;remove();addBefore(lm.header);}}void recordRemoval(HashMap<K,V> m) {remove();}}
增加节点
增加节点上图中的c节点相当于下面代码中的existingEntry,要插入的是x节点
|
|
void addEntry(int hash, K key, V value, int bucketIndex) {super.addEntry(hash, key, value, bucketIndex);// Remove eldest entry if instructedEntry<K,V> eldest = header.after;//如果有必要移除最老的节点,那么就移除。LinkedHashMap默认removeEldestEntry总是返回false//也就是这里if里面的语句永远不会执行//这里removeEldestEntry主要是给LinkedHashMap的子类留下的一个钩子//子类完全可以根据自己的需要重写removeEldestEntry,后面我会举个现实中的例子🌰if (removeEldestEntry(eldest)) {removeEntryForKey(eldest.key);}}/*** This override differs from addEntry in that it doesn't resize the* table or remove the eldest entry.*/void createEntry(int hash, K key, V value, int bucketIndex) {HashMap.Entry<K,V> old = table[bucketIndex];Entry<K,V> e = new Entry<>(hash, key, value, old);table[bucketIndex] = e;//这里把新增的Entry加到了双向链表的header的前面,成为新的headere.addBefore(header);size++;}
更高效的LinkedHashIterator
由于元素之间用双向链表连接起来了,所以在遍历元素时只需遍历双向链表即可,这比HashMap中的遍历方式要高效。
private abstract class LinkedHashIterator<T> implements Iterator<T> {Entry<K,V> nextEntry = header.after;Entry<K,V> lastReturned = null;/*** The modCount value that the iterator believes that the backing* List should have. If this expectation is violated, the iterator* has detected concurrent modification.*/int expectedModCount = modCount;//由于采用环型双向链表,所以可以用header.after == header 来判断双向链表是否为空public boolean hasNext() {return nextEntry != header;}public void remove() {if (lastReturned == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();LinkedHashMap.this.remove(lastReturned.key);lastReturned = null;expectedModCount = modCount;}Entry<K,V> nextEntry() {if (modCount != expectedModCount)throw new ConcurrentModificationException();if (nextEntry == header)throw new NoSuchElementException();Entry<K,V> e = lastReturned = nextEntry;//在访问下一个节点时,直接使用当前节点的后继指针即可nextEntry = e.after;return e;}}
除了LinkedHashIterator利用了双向链表遍历的优势外,下面的两个方法也利用这个优势加速执行。
void transfer(HashMap.Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e = header.after; e != header; e = e.after) {if (rehash)e.hash = (e.key == null) ? 0 : hash(e.key);int index = indexFor(e.hash, newCapacity);e.next = newTable[index];newTable[index] = e;}}public boolean containsValue(Object value) {// Overridden to take advantage of faster iteratorif (value==null) {for (Entry e = header.after; e != header; e = e.after)if (e.value==null)return true;} else {for (Entry e = header.after; e != header; e = e.after)if (value.equals(e.value))return true;}return false;}
JDK String.hashCode()
LinkedHashMap
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
JDK 8 Hashmap.hash
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
JDK 7 Hashmap.hash
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
HashMap
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
LinkedHashMap
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}