https://colobu.com/2015/01/07/Protobuf-language-guide/
https://developers.google.com/protocol-buffers/docs/proto3
https://developers.google.com/protocol-buffers/docs/proto
protobuf allows you to be performant in all of the following criterias
Parsing efficiency
Upgrading messages and adding new fields
Ignoring/Deprecating fields
Having a minimum payload depending on the data, not the structure
Applying hierarchical data
If you have a message with more than 16 fields, and some of them are optional, don’t forget to place the optional ones at the end of the message.
optional int32 old_field = 1 [deprecated=true];
Since all fields are already optional by default, proto3 got rid of optional.
message Film {
message Character {
string name = 1;
int64 birth = 2;
}
string title = 1;
string director = 2;
string producer = 3;
optional string release_date = 4;
repeated Character characters = 5;
}
if Character needs to be used elsewhere it may be imported as follows:
message OtherFilm {
repeated Film.Character characters = 1;
}
map<string, Character> roles = 1;
https://www.servercoder.com/2018/01/10/protobuf-usages/
Thrift, Protobuf and Avro all support schema evolution: you can change the schema, you can have producers and consumers with different versions of the schema at the same time, and it all continues to work. That is an extremely valuable feature when you’re dealing with a big production system, because it allows you to update different components of the system independently, at different times, without worrying about compatibility.
Protocol Buffers
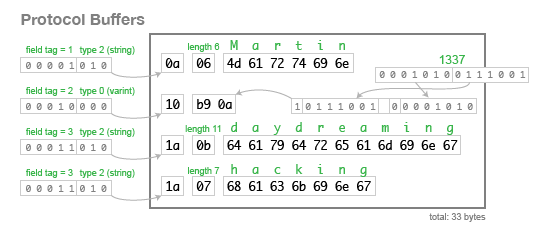 This approach of using a tag number to represent each field is simple and effective.
This approach of using a tag number to represent each field is simple and effective.
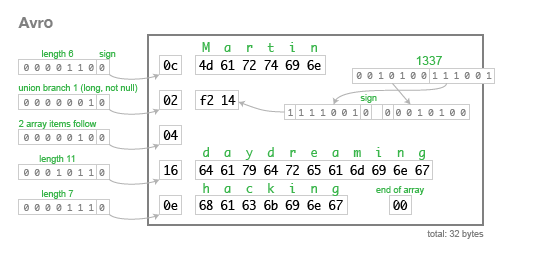
Avro
Thrift
it’s not just a data serialization library, but also an entire RPC framework. It also has a somewhat different culture: whereas Avro and Protobuf standardize a single binary encoding, Thriftembraces a whole variety of different serialization formats (which it calls “protocols”).
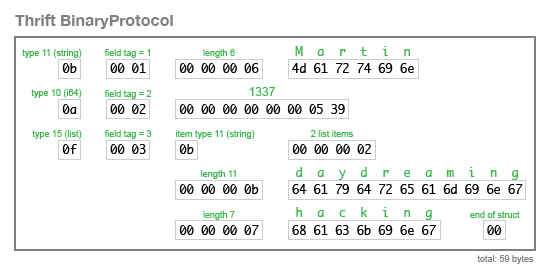
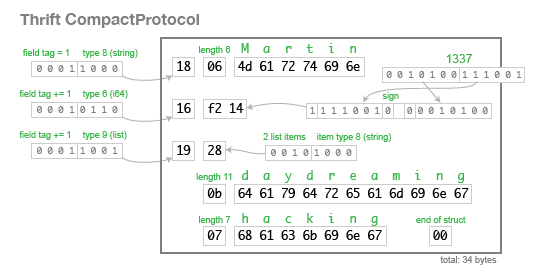
THRIFT AND PROTOCOL BUFFERS
Thrift
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
Protocol Buffers:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}

Thrift has two different binary encoding formats called BinaryProtocol and CompactProtocol respectively
Field tags are like aliases for fields—they are a compact way of saying what field we’re talking about, without having to spell out the field name.

CompactProtocol packs the field type and tag number into a single byte, and by using variable-length integers. Rather than using a full 8 bytes for the number 1337, it is encoded in two bytes, using the top bit of each byte to indicate whether there are still more bytes to come. This means numbers between -64 and 63 are encoded in one byte, numbers between -8192 and 8191 are encoded in two bytes, etc. Bigger numbers use more bytes.

each field was marked either required or optional, but this makes no difference to how the field is encoded (nothing in the binary data indicates whether a field was required). The difference is simply that required enables a runtime check that fails if the field is not set, which can be useful for catching bugs.
Field tags and schema evolution
You can change the name of a field in the schema, since the encoded data never refers to field names, but you cannot change a field’s tag, since that would make all existing encoded data invalid.
You can add new fields to the schema, provided that you give each field a new tag number. If old code (which doesn’t know about the new tag numbers you added) tries to read data written by new code, including new a field with a tag number it doesn’t recognize, it can simply ignore that field. The datatype annotation allows the parser to determine how many bytes it needs to skip. This maintains forward compatibility: old code can read records that were written by new code.
What about backward compatibility? As long as each field has a unique tag number, new code can always read old data, because the tag numbers still have the same meaning. The only detail is that if you add a new field, you cannot make it required. If you were to add a field and make it required, that check would fail if new code reads data written by old code, because the old code did not write the new field that you added. Therefore, to maintain backward compatibility, every field you add after the initial deployment of the schema must be optional.
you can only remove a field that is optional (a required field can never be removed), and you can never use the same tag number again (because you may still have data written somewhere that includes the old tag number, and that field must be ignored by new code).
Data types and schema evolution
What about changing the datatype of a field? That may be possible—check the documentation for details—but there is a risk that values lose precision or get truncated. For example, say you change a 32-bit integer into a 64-bit integer. New code can easily read data written by old code, because the parser can fill in any missing bits with zero. However, if old code reads data written by new code, the old code is still using a 32-bit variable to hold the value. If the decoded 64-bit value won’t fit in 32 bits, it will be truncated.
In PB: it’s ok to change an optional (single-valued) field into a repeated (multi-valued) field. New code reading old data sees a list with zero or one elements (depending on whether the field was present); old code reading new data sees only the last element of the list.
Thrift has a dedicated list datatype, which is parameterized with the datatype of the list elements. This does not allow the same evolution from single-valued to multi-valued as Protocol Buffers does, but it has the advantage of supporting nested lists.
Avro has two schema languages: one (Avro IDL) intended for human editing, and one (based on JSON) that is more easily machine-readable.
Avro IDL
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}

there are no tag numbers in the schema.
To parse the binary data, you go through the fields in the order that they appear in the schema, and use the schema to tell you the datatype of each field. This means that the binary data can only be decoded correctly if the code reading the data is using the exact same schema as the code that wrote the data. Any mismatch in the schema between the reader and the writer would mean incorrectly decoded data.
the writer’s schema and the reader’s schema don’t have to be the same—they only need to be compatible. When data is decoded (read), the Avro library resolves the differences by looking at the writer’s schema and the reader’s schema side-by-side, and translating the data from the writer’s schema into the reader’s schema.
it’s no problem if the writer’s schema and the reader’s schema have their fields in a different order, because the schema resolution matches up the fields by field name. If a field on the writer’s side doesn’t have a matching field on the reader’s side, it is ignored. If a field on the reader’s side doesn’t have a matching field on the writer’s side, it is filled in with a default value declared in the reader’s schema.
To maintain compatibility, you may only add or remove a field that has a default value.
if you want to allow a field to be null, you have to use a union type. For example, union { null, long, string } field; indicates that field can be a number, or a string, or null. You can only use null as a default value if it is one of the branches of the union. This is a little more verbose than having everything nullable by default, but it helps prevent bugs by being explicit about what can and cannot be null.
Changing the datatype of a field is possible, provided that Avro can convert the type. Changing the name of a field is possible but a little tricky: the reader’s schema can contain aliases for field names, so it can match an old writer’s schema field names against the aliases. This means that changing a field name is backward compatible but not forward compatible. Similarly, adding a branch to a union type is backward compatible but not forward compatible.
the writer of that file can just include the writer’s schema once at the beginning of the file. Avro specifies a file format (object container files) to do this.
When two processes are communicating over a bidirectional network connection, they can negotiate the schema version on connection setup, and then continue using that schema for the lifetime of the connection. The Avro RPC protocol does this.
Dynamically generated schemas
Code generation and dynamically typed languages
If you have an object container file (which embeds the writer’s schema), you can simply open it using the Avro library, and look at the data in the same way as you could look at a JSON file. The file is self-describing since it includes all the necessary metadata.
https://spring.io/blog/2015/03/22/using-google-protocol-buffers-with-spring-mvc-based-rest-services
Protocol Buffers is a language and platform neutral mechanism for serialization and deserialization of structured data, which is proclaimed by Google, its creator, to be much faster, smaller and simpler than other types of payloads, such as XML and JSON.
protoc --java_out=java resources/baeldung.proto
https://dzone.com/articles/exposing-microservices-over-rest-protocol-buffers
https://dzone.com/articles/exposing-microservices-over-rest-protocol-buffers
https://blog.wearewizards.io/using-protobuf-instead-of-json-to-communicate-with-a-frontend
Tools like Protobuf have a few advantages over JSON:
smaller in size
typed
offer a common interface for all your services, you can just update your .proto or .thrift and share those with the services using it, as long as there is a library for that language
var saveProtobuf = function(_contact) {
var contact = new Contact({
first_name: _contact['firstName'],
last_name: _contact['lastName'],
});
var req = {
method: 'POST',
url: '/api/contacts',
responseType: 'arraybuffer',
transformRequest: function(r) { return r;},
data: contact.toArrayBuffer(),
headers: {
'Content-Type': 'binary/octet-stream'
}
};
$http(req).success(function(data) {
var msg = AddressBook.decode(data);
$scope.contacts = msg.contacts;
});
};
https://auth0.com/blog/beating-json-performance-with-protobuf/
- deprecated (field option): 如果该选项被设置为true,表明该字段已经被弃用了,在新代码中不建议使用。在多数语言中,这并没有实际的含义。在java中,它将会变成一个 @Deprecated注释。也许在将来,其它基于语言声明的代码在生成时也会如此使用,当使用该字段时,编译器将自动报警。如:
Changing a field name will not affected protobuf encoding or compatibility between applications that use proto definitions which differ only by field names.
The binary protobuf encoding is based on tag numbers, so that is what you need to preserve.
You can even change a field type to some extent (check the type table at https://developers.google.com/protocol-buffers/docs/encoding#structure) providing its wire type stays the same, but that requires additional considerations whether, for example, changing
uint32to uint64 is safe from the point of view of your application code and for some definition of 'better' is better that simply defining a new field.
Changing a field name will affect json representation, if you use that feature.
https://developers.google.com/protocol-buffers/docs/proto
protobuf allows you to be performant in all of the following criterias
Parsing efficiency
Upgrading messages and adding new fields
Ignoring/Deprecating fields
Having a minimum payload depending on the data, not the structure
Applying hierarchical data
If you have a message with more than 16 fields, and some of them are optional, don’t forget to place the optional ones at the end of the message.
optional int32 old_field = 1 [deprecated=true];
message Film {
message Character {
string name = 1;
int64 birth = 2;
}
string title = 1;
string director = 2;
string producer = 3;
optional string release_date = 4;
repeated Character characters = 5;
}
if Character needs to be used elsewhere it may be imported as follows:
message OtherFilm {
repeated Film.Character characters = 1;
}
map<string, Character> roles = 1;
GRPC:
service Starwars {
rpc GetFilm(GetFilmRequest) returns (GetFilmResponse);
}
除了rest接约定俗称采用json以外,我们大部分采用protobuf的原因如下:
- 速度更快
- 空间更小
- 浮点数的精度支持不好,尤其是json
- xml、json都是文本型的,如果想存储二进制数据,必须先将其转为文本数据,比如使用base64编码
- 安全。json不同语言有各种各样的解析库,代码实现者信息安全经验良莠不齐,大部分库都有远程执行漏洞。而protobuf由谷歌官方维护,能很大程度上保证安全,一旦出现安全隐患也会很快更新。
尽量使用proto3
相比于proto2,proto3更简洁,不需要用户指定required、optional关键字,这点除了开发更方便以外,对于前后兼容也是非常有帮助的,我将在下一条建议中说明。
版本号
有很多从json或其他协议转过来的人,还会保留以前那套协议版本号的做法。事实上,这样的做法非常恶心,代码里面会有大量的版本判断和处理。protobuf的设计初衷就是为了避免出现这样恶心的代码的。
存储大量字符串
有些人会使用protobuf存储大量字符串,更有甚者可能会将json放入protobuf中。
如果有心人看过protobuf序列化之后的数据,会发现protobuf对字符串数据是直接拷贝的。所以使用protobuf存储字符串,并没有达到优化空间的目的。
https://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html如果有心人看过protobuf序列化之后的数据,会发现protobuf对字符串数据是直接拷贝的。所以使用protobuf存储字符串,并没有达到优化空间的目的。
Thrift, Protobuf and Avro all support schema evolution: you can change the schema, you can have producers and consumers with different versions of the schema at the same time, and it all continues to work. That is an extremely valuable feature when you’re dealing with a big production system, because it allows you to update different components of the system independently, at different times, without worrying about compatibility.
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}Protocol Buffers
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}
When we encode the data above using this schema, it uses 33 bytes, as follows:
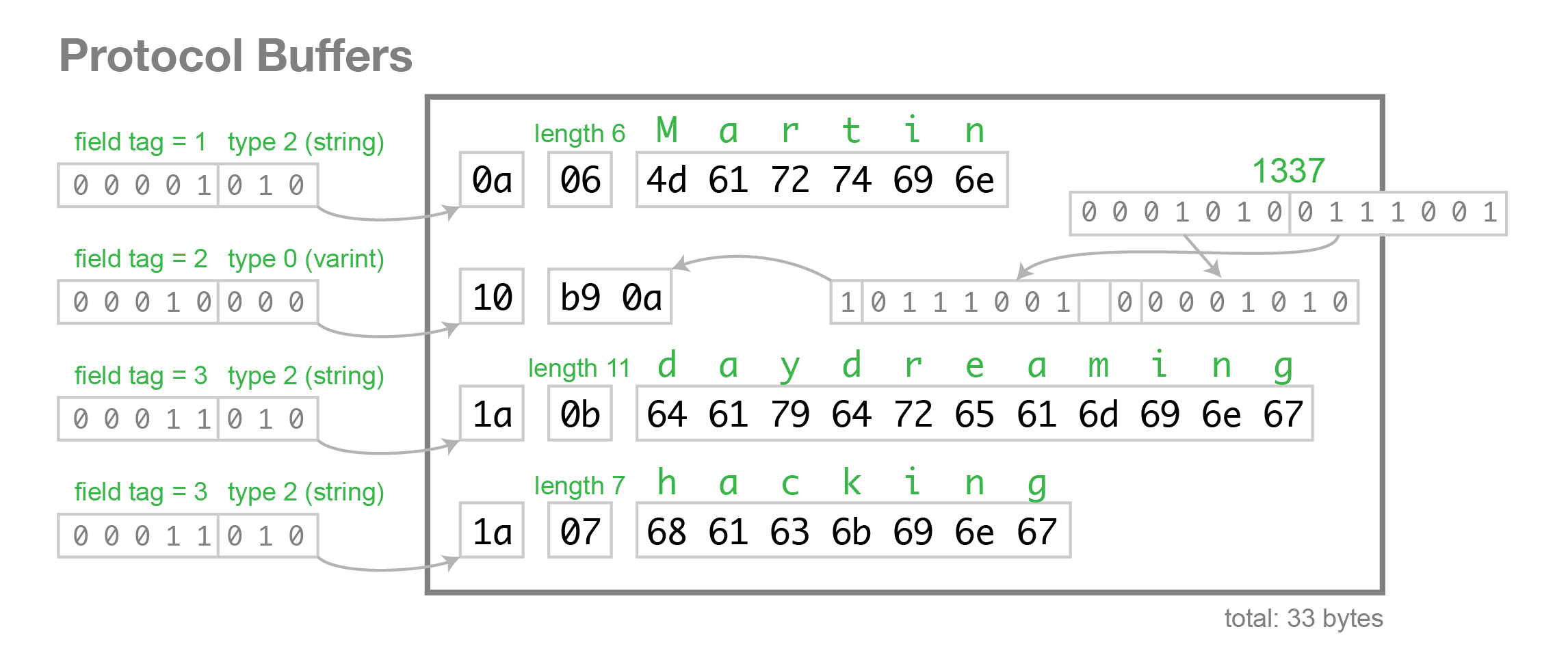
- There is no difference in the encoding between
optional,requiredandrepeatedfields (except for the number of times the tag number can appear). This means that you can change a field fromoptionaltorepeatedand vice versa (if the parser is expecting anoptionalfield but sees the same tag number multiple times in one record, it discards all but the last value).requiredhas an additional validation check, so if you change it, you risk runtime errors (if the sender of a message thinks that it’s optional, but the recipient thinks that it’s required). - An
optionalfield without a value, or arepeatedfield with zero values, does not appear in the encoded data at all — the field with that tag number is simply absent. Thus, it is safe to remove that kind of field from the schema. However, you must never reuse the tag number for another field in future, because you may still have data stored that uses that tag for the field you deleted. - You can add a field to your record, as long as it is given a new tag number. If the Protobuf parser parser sees a tag number that is not defined in its version of the schema, it has no way of knowing what that field is called. But it does roughly know what type it is, because a 3-bit type code is included in the first byte of the field. This means that even though the parser can’t exactly interpret the field, it can figure out how many bytes it needs to skip in order to find the next field in the record.
- You can rename fields, because field names don’t exist in the binary serialization, but you can never change a tag number.
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
…or in an IDL:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}Thrift
it’s not just a data serialization library, but also an entire RPC framework. It also has a somewhat different culture: whereas Avro and Protobuf standardize a single binary encoding, Thriftembraces a whole variety of different serialization formats (which it calls “protocols”).
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
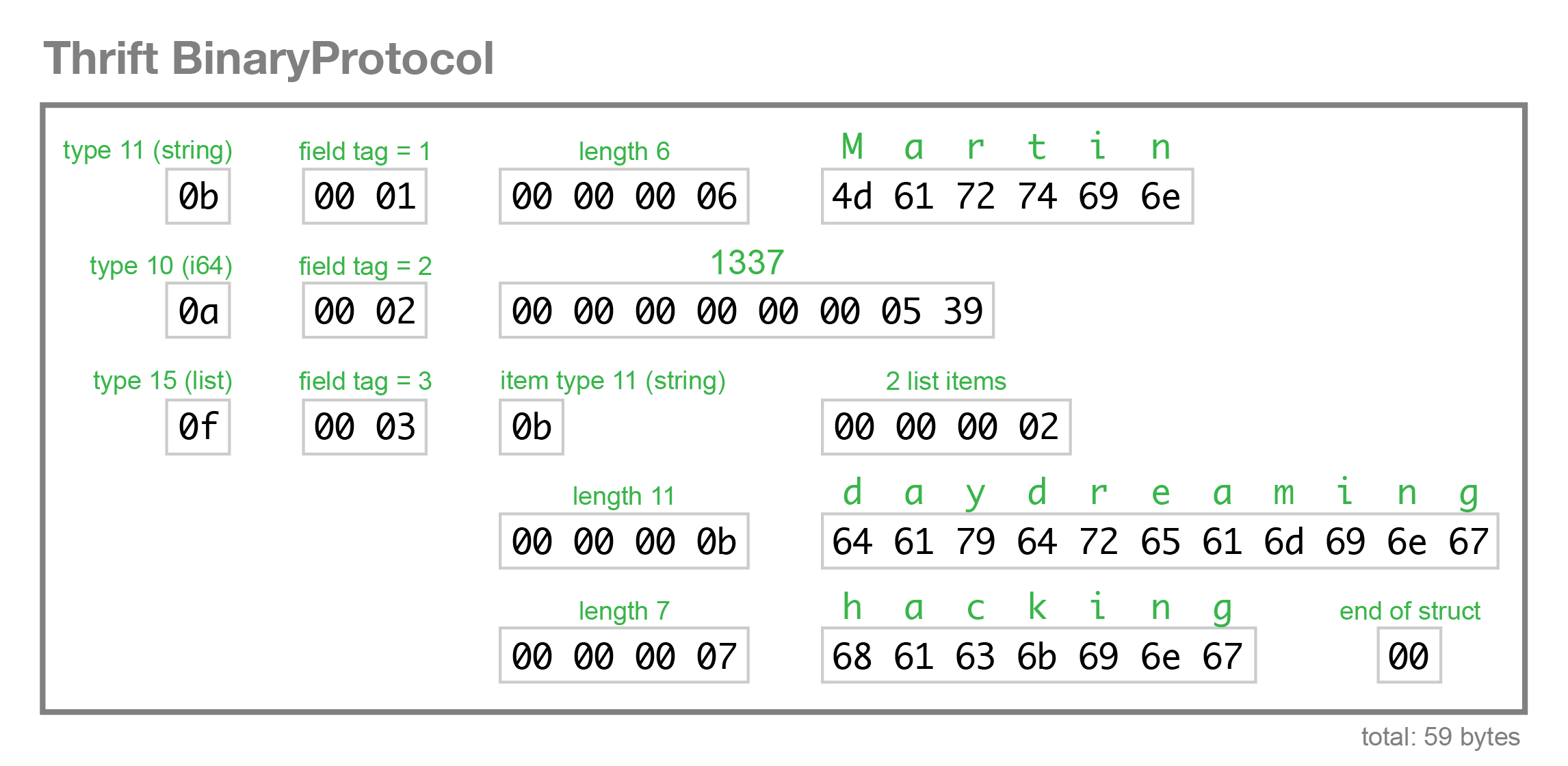
The BinaryProtocol encoding is very straightforward, but also fairly wasteful (it takes 59 bytes to encode our example record):
The CompactProtocol encoding is semantically equivalent, but uses variable-length integers and bit packing to reduce the size to 34 bytes:
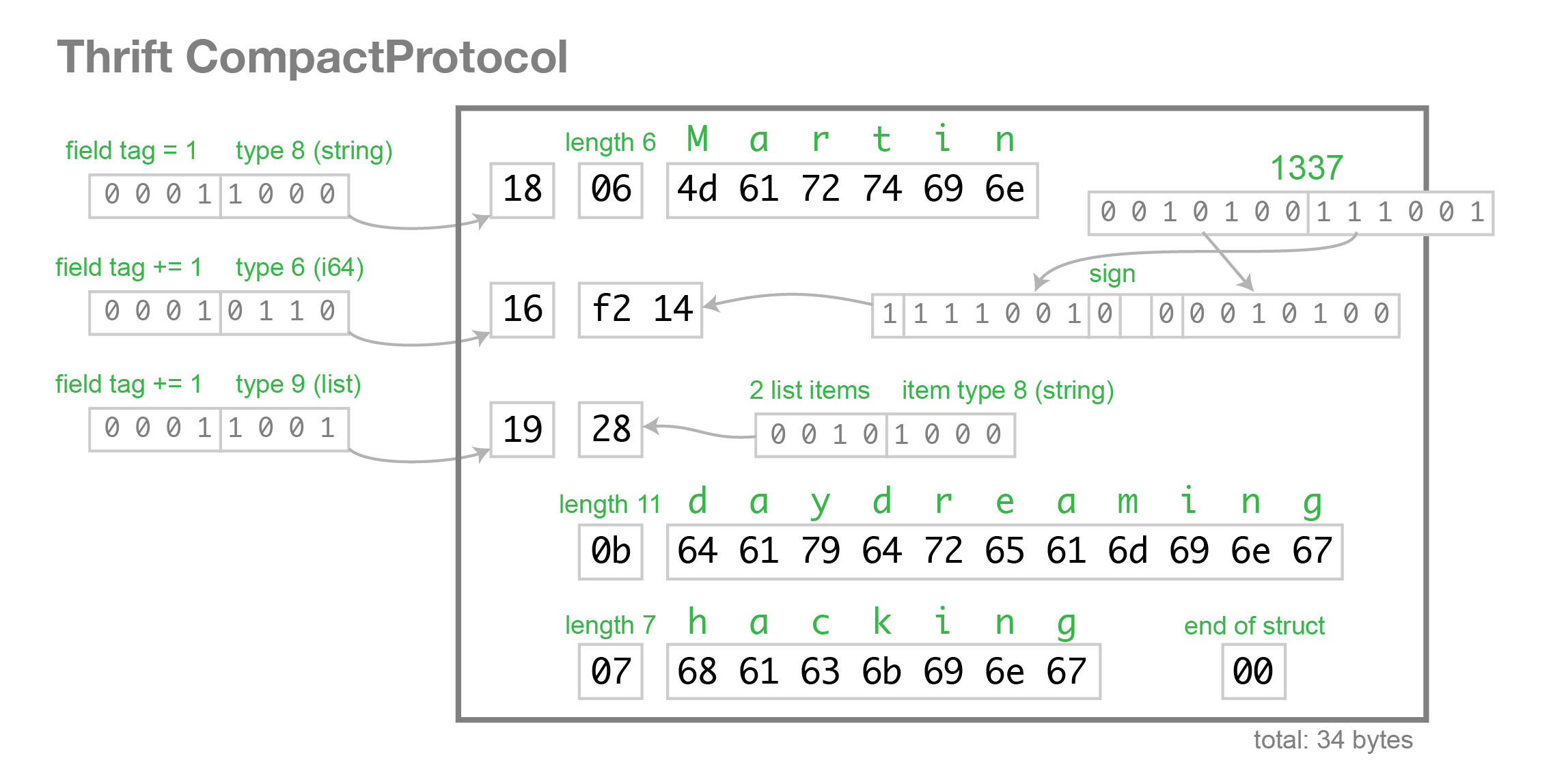
As you can see, Thrift’s approach to schema evolution is the same as Protobuf’s: each field is manually assigned a tag in the IDL, and the tags and field types are stored in the binary encoding, which enables the parser to skip unknown fields. Thrift defines an explicit list type rather than Protobuf’s repeated field approach, but otherwise the two are very similar.
In terms of philosophy, the libraries are very different though. Thrift favours the “one-stop shop” style that gives you an entire integrated RPC framework and many choices (withvarying cross-language support), whereas Protocol Buffers and Avro appear to follow much more of a “do one thing and do it well” style.
http://stackoverflow.com/questions/27782092/whats-the-best-practice-to-for-thrift-file-api-versioning
Thrift supports soft versioning, so it is perfectly valid to do a version 2 of your service which looks like this:
service Api {
void invoke(1: string optional_arg1, 2: i32 optional_arg2) throws (1: MyError e)
i32 number_of_invokes()
}
Since the newly added arguments are technically optional, an arbitrary clients request may or may not contain them, or may contain only parts of them (e.g. specify
arg1 but not arg2). The exception is a bit different, old clients will raise some kind of generic unexpected exception or similar.
It is even possible to remove an outdated function entirely, in this case old clients will get an exception whenever they try to call the (now non-existing) removed function.
All of the above is similarly is true with regard to adding member fields to structures, exceptions etc. Instead of removing declarations from the IDL file, it is recommended to comment out old removed member fields and functions to prevent people from re-using old field IDs, old function names or old enum values in later versions.
struct foobar {
// API 1.0 fields
1: i32 foo
//2: i32 bar - obsolete with API 2.0
// API 2.0 fields
3: i32 baz
}
Furthermore, in some cases your API will undergo breaking changes, intentionally without being backwards compatible. In that case, it is recommened to set the new service at a different endpoint.
Alternatively, the multiplex protocol introduced with Thrift 0.9.2 can be used to offer multiple services and/or service versions over the same endpoint (i.e. socket, http URI, ...)
Designing Data-Intensive ApplicationsTHRIFT AND PROTOCOL BUFFERS
Thrift
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
Protocol Buffers:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}

Thrift has two different binary encoding formats called BinaryProtocol and CompactProtocol respectively
Field tags are like aliases for fields—they are a compact way of saying what field we’re talking about, without having to spell out the field name.

CompactProtocol packs the field type and tag number into a single byte, and by using variable-length integers. Rather than using a full 8 bytes for the number 1337, it is encoded in two bytes, using the top bit of each byte to indicate whether there are still more bytes to come. This means numbers between -64 and 63 are encoded in one byte, numbers between -8192 and 8191 are encoded in two bytes, etc. Bigger numbers use more bytes.

each field was marked either required or optional, but this makes no difference to how the field is encoded (nothing in the binary data indicates whether a field was required). The difference is simply that required enables a runtime check that fails if the field is not set, which can be useful for catching bugs.
Field tags and schema evolution
You can change the name of a field in the schema, since the encoded data never refers to field names, but you cannot change a field’s tag, since that would make all existing encoded data invalid.
You can add new fields to the schema, provided that you give each field a new tag number. If old code (which doesn’t know about the new tag numbers you added) tries to read data written by new code, including new a field with a tag number it doesn’t recognize, it can simply ignore that field. The datatype annotation allows the parser to determine how many bytes it needs to skip. This maintains forward compatibility: old code can read records that were written by new code.
What about backward compatibility? As long as each field has a unique tag number, new code can always read old data, because the tag numbers still have the same meaning. The only detail is that if you add a new field, you cannot make it required. If you were to add a field and make it required, that check would fail if new code reads data written by old code, because the old code did not write the new field that you added. Therefore, to maintain backward compatibility, every field you add after the initial deployment of the schema must be optional.
you can only remove a field that is optional (a required field can never be removed), and you can never use the same tag number again (because you may still have data written somewhere that includes the old tag number, and that field must be ignored by new code).
Data types and schema evolution
What about changing the datatype of a field? That may be possible—check the documentation for details—but there is a risk that values lose precision or get truncated. For example, say you change a 32-bit integer into a 64-bit integer. New code can easily read data written by old code, because the parser can fill in any missing bits with zero. However, if old code reads data written by new code, the old code is still using a 32-bit variable to hold the value. If the decoded 64-bit value won’t fit in 32 bits, it will be truncated.
In PB: it’s ok to change an optional (single-valued) field into a repeated (multi-valued) field. New code reading old data sees a list with zero or one elements (depending on whether the field was present); old code reading new data sees only the last element of the list.
Thrift has a dedicated list datatype, which is parameterized with the datatype of the list elements. This does not allow the same evolution from single-valued to multi-valued as Protocol Buffers does, but it has the advantage of supporting nested lists.
Avro has two schema languages: one (Avro IDL) intended for human editing, and one (based on JSON) that is more easily machine-readable.
Avro IDL
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}

there are no tag numbers in the schema.
To parse the binary data, you go through the fields in the order that they appear in the schema, and use the schema to tell you the datatype of each field. This means that the binary data can only be decoded correctly if the code reading the data is using the exact same schema as the code that wrote the data. Any mismatch in the schema between the reader and the writer would mean incorrectly decoded data.
the writer’s schema and the reader’s schema don’t have to be the same—they only need to be compatible. When data is decoded (read), the Avro library resolves the differences by looking at the writer’s schema and the reader’s schema side-by-side, and translating the data from the writer’s schema into the reader’s schema.
it’s no problem if the writer’s schema and the reader’s schema have their fields in a different order, because the schema resolution matches up the fields by field name. If a field on the writer’s side doesn’t have a matching field on the reader’s side, it is ignored. If a field on the reader’s side doesn’t have a matching field on the writer’s side, it is filled in with a default value declared in the reader’s schema.
To maintain compatibility, you may only add or remove a field that has a default value.
if you want to allow a field to be null, you have to use a union type. For example, union { null, long, string } field; indicates that field can be a number, or a string, or null. You can only use null as a default value if it is one of the branches of the union. This is a little more verbose than having everything nullable by default, but it helps prevent bugs by being explicit about what can and cannot be null.
Changing the datatype of a field is possible, provided that Avro can convert the type. Changing the name of a field is possible but a little tricky: the reader’s schema can contain aliases for field names, so it can match an old writer’s schema field names against the aliases. This means that changing a field name is backward compatible but not forward compatible. Similarly, adding a branch to a union type is backward compatible but not forward compatible.
the writer of that file can just include the writer’s schema once at the beginning of the file. Avro specifies a file format (object container files) to do this.
When two processes are communicating over a bidirectional network connection, they can negotiate the schema version on connection setup, and then continue using that schema for the lifetime of the connection. The Avro RPC protocol does this.
Dynamically generated schemas
Code generation and dynamically typed languages
If you have an object container file (which embeds the writer’s schema), you can simply open it using the Avro library, and look at the data in the same way as you could look at a JSON file. The file is self-describing since it includes all the necessary metadata.
https://spring.io/blog/2015/03/22/using-google-protocol-buffers-with-spring-mvc-based-rest-services
- Protocol Buffers offer backward compatibility for free. Each field is numbered in a Protocol Buffer, so you don’t have to change the behavior of the code going forward to maintain backward compatability with older clients. Clients that don’t know about new fields won’t bother trying to parse them.
- Protocol Buffers provide a natural place to specify validation using the
required,optional, andrepeatedkeywords. Each client enforces these constraints in their own way.
Protocol Buffers is a language and platform neutral mechanism for serialization and deserialization of structured data, which is proclaimed by Google, its creator, to be much faster, smaller and simpler than other types of payloads, such as XML and JSON.
protoc --java_out=java resources/baeldung.proto
https://dzone.com/articles/exposing-microservices-over-rest-protocol-buffers
ProtobufHttpMessageConverter protobufHttpMessageConverter() {
return new ProtobufHttpMessageConverter();
}
RestTemplate restTemplate(ProtobufHttpMessageConverter hmc) {
return new RestTemplate(Arrays.asList(hmc));
}
(value = "/accounts/{number}", produces = "application/x-protobuf")
https://dzone.com/articles/exposing-microservices-over-rest-protocol-buffers
https://blog.wearewizards.io/using-protobuf-instead-of-json-to-communicate-with-a-frontend
Tools like Protobuf have a few advantages over JSON:
smaller in size
typed
offer a common interface for all your services, you can just update your .proto or .thrift and share those with the services using it, as long as there is a library for that language
By default, this is more compact than JSON by quite a bit but once I turned on GZIP, the difference became much smaller: 851B for ProtoBuf and 942B for JSON.
$scope.getContactsProtobuf = function() {
$scope.contacts = [];
var req = {
method: 'GET',
url: '/api/contacts',
responseType: 'arraybuffer'
};
$http(req).success(function(data) {
var msg = AddressBook.decode(data);
$scope.contacts = msg.contacts;
});
};
var contact = new Contact({
first_name: _contact['firstName'],
last_name: _contact['lastName'],
});
var req = {
method: 'POST',
url: '/api/contacts',
responseType: 'arraybuffer',
transformRequest: function(r) { return r;},
data: contact.toArrayBuffer(),
headers: {
'Content-Type': 'binary/octet-stream'
}
};
$http(req).success(function(data) {
var msg = AddressBook.decode(data);
$scope.contacts = msg.contacts;
});
};
https://auth0.com/blog/beating-json-performance-with-protobuf/
- Non-human readability. JSON, as exchanged on text format and with simple structure, is easy to be read and analyzed by humans. This is not the case with a binary format.
Schemas Are Awesome