https://github.com/pinterest/secor
Secor is a service persisting Kafka logs to Amazon S3, Google Cloud Storage and Openstack Swift.
Kafka: The Definitive Guide
For efficiency, messages are written into Kafka in batches. A batch is just a collection of messages, all of which are being produced to the same topic and partition.
Batches are also typically compressed.
Many Kafka developers favor the use of Apache Avro. Avro provides a compact serialization format, schemas that are separate from the message payloads and that do not require generated code when they change, as well as strong data typing and schema evolution, with both backwards and forwards compatibility.
A consistent data format is important in Kafka, as it allows writing and reading messages to be decoupled.
By using well-defined schemas, and storing them in a common repository, the messages in Kafka can be understood without coordination.
Messages in Kafka are categorized into topics. The closest analogy for a topic is a database table, or a folder in a filesystem.
Topics are additionally broken down into a number of partitions.
as a topic generally has multiple partitions, there is no guarantee of time-ordering of messages across the entire topic, just within a single partition.
Partitions are also the way that Kafka provides redundancy and scalability.
Each partition can be hosted on a different server, which means that a single topic can be scaled horizontally across multiple servers to provide for performance far beyond the ability of a single server.
In some cases, the producer will direct messages to specific partitions. This is typically done using the message key and a partitioner that will generate a hash of the key and map it to a specific partition. This assures that all messages produced with a given key will get written to the same partition.
The consumer keeps track of which messages it has already consumed by keeping track of the offset of messages.
The offset is another bit of metadata, an integer value that continually increases, that Kafka adds to each message as it is produced. Each message within a given partition has a unique offset.
By storing the offset of the last consumed message for each partition, either in Zookeeper or in Kafka itself, a consumer can stop and restart without losing its place.
Consumers work as part of a consumer group. This is one or more consumers that work together to consume a topic. The group assures that each partition is only consumed by one member.
consumers can horizontally scale to consume topics with a large number of messages. Additionally, if a single consumer fails, the remaining members of the group will rebalance the partitions being consumed to take over for the missing member.
A single Kafka server is called a broker. The broker receives messages from producers, assigns offsets to them, and commits the messages to storage on disk. It also services consumers, responding to fetch requests for partitions and responding with the messages that have been committed to disk.
Depending on the specific hardware and its performance characteristics, a single broker can easily handle thousands of partitions and millions of messages per second.
Kafka brokers are designed to operate as part of a cluster. Within a cluster of brokers, one will also function as the cluster controller (elected automatically from the live members of the cluster).
The controller is responsible for administrative operations, including assigning partitions to brokers and monitoring for broker failures.
A partition is owned by a single broker in the cluster, and that broker is called the leader for the partition. A partition may be assigned to multiple brokers, which will result in the partition being replicated. This provides redundancy of messages in the partition, such that another broker can take over leadership if there is a broker failure. However, all consumers and producers operating on that partition must connect to the leader.
Mirror Maker is simply a Kafka consumer and producer, linked together with a queu. Messages are consumed from one Kafka cluster and produced to another
Why Kafka?
Multiple Producers
Multiple Consumers
Kafka is designed for multiple consumers to read any single stream of messages without interfering with each other. This is in opposition to many queuing systems where once a message is consumed by one client, it is not available to any other client. At the same time, multiple Kafka consumers can choose to operate as part of a group and share a stream, assuring that the entire group processes a given message only once.
Disk-based Retention
durable message retention means that consumers do not always need to work in real time
Scalable
High Performance
https://miafish.wordpress.com/2015/03/06/kafka/
the whole modelproducers write data to brokers(kafka)
comsumers read data from brokers(kafka).
 topic, partitions and replicas
topic, partitions and replicas
Data is stored in topics
topics are split into partitions, which are replicated.
partition: ordered + immutable sequence of messages that is continually appended to




https://kafka.apache.org/08/design.html
Don't fear the filesystem!
rather than maintain as much as possible in-memory and flush it all out to the filesystem in a panic when we run out of space, we invert that. All data is immediately written to a persistent log on the filesystem without necessarily flushing to disk. In effect this just means that it is transferred into the kernel's pagecache.
Furthermore we are building on top of the JVM, and anyone who has spent any time with Java memory usage knows two things:
The persistent data structure used in messaging systems are often a per-consumer queue with an associated BTree or other general-purpose random access data structures to maintain metadata about messages. BTrees are the most versatile data structure available, and make it possible to support a wide variety of transactional and non-transactional semantics in the messaging system. They do come with a fairly high cost, though: Btree operations are O(log N). Normally O(log N) is considered essentially equivalent to constant time, but this is not true for disk operations. Disk seeks come at 10 ms a pop, and each disk can do only one seek at a time so parallelism is limited. Hence even a handful of disk seeks leads to very high overhead. Since storage systems mix very fast cached operations with very slow physical disk operations, the observed performance of tree structures is often superlinear as data increases with fixed cache--i.e. doubling your data makes things much worse then twice as slow.
Intuitively a persistent queue could be built on simple reads and appends to files as is commonly the case with logging solutions. This structure has the advantage that all operations are O(1) and reads do not block writes or each other. This has obvious performance advantages since the performance is completely decoupled from the data size—one server can now take full advantage of a number of cheap, low-rotational speed 1+TB SATA drives.
in Kafka, instead of attempting to deleting messages as soon as they are consumed, we can retain messages for a relative long period (say a week). This leads to a great deal of flexibility for consumers
Efficiency
Problems: too many small I/O operations, and excessive byte copying.
our protocol is built around a "message set" abstraction that naturally groups messages together. This allows network requests to group messages together and amortize the overhead of the network roundtrip rather than sending a single message at a time. The server in turn appends chunks of messages to its log in one go, and the consumer fetches large linear chunks at a time.
This simple optimization produces orders of magnitude speed up. Batching leads to larger network packets, larger sequential disk operations, contiguous memory blocks, and so on, all of which allows Kafka to turn a bursty stream of random message writes into linear writes that flow to the consumers.
byte copying:
The message log maintained by the broker is itself just a directory of files, each populated by a sequence of message sets that have been written to disk in the same format used by the producer and consumer. Maintaining this common format allows optimization of the most important operation: network transfer of persistent log chunks. Modern unix operating systems offer a highly optimized code path for transferring data out of pagecache to a socket; in Linux this is done with the sendfile system call.
To understand the impact of sendfile, it is important to understand the common data path for transfer of data from file to socket:
We expect a common use case to be multiple consumers on a topic. Using the zero-copy optimization above, data is copied into pagecache exactly once and reused on each consumption instead of being stored in memory and copied out to kernel space every time it is read. This allows messages to be consumed at a rate that approaches the limit of the network connection.
This combination of pagecache and sendfile means that on a Kafka cluster where the consumers are mostly caught up you will see no read activity on the disks whatsoever as they will be serving data entirely from cache.
Kafka supports this by allowing recursive message sets. A batch of messages can be clumped together compressed and sent to the server in this form. This batch of messages will be written in compressed form and will remain compressed in the log and will only be decompressed by the consumer.
4.4 The Producer
Load balancing
Asynchronous send
4.5 The Consumer
Push vs. pull
data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as scribe and flume follow a very different push based path where data is pushed downstream. There are pros and cons to both approaches. However a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems.
data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as scribe and flume follow a very different push based path where data is pushed downstream. There are pros and cons to both approaches. However a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems.
You could imagine other possible designs which would be only pull, end-to-end. The producer would locally write to a local log, and brokers would pull from that with consumers pulling from them. A similar type of "store-and-forward" producer is often proposed. This is intriguing but we felt not very suitable for our target use cases which have thousands of producers. Our experience running persistent data systems at scale led us to feel that involving thousands of disks in the system across many applications would not actually make things more reliable and would be a nightmare to operate. And in practice we have found that we can run a pipeline with strong SLAs at large scale without a need for producer persistence.
This is likely why quorum algorithms more commonly appear for shared cluster configuration such as Zookeeper but are less common for primary data storage. For example in HDFS the namenode's high-availability feature is built on a majority-vote-based journal, but this more expensive approach is not used for the data itself.
Instead of majority vote, Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not considered committed until all in-sync replicas have received the write. This ISR set is persisted to zookeeper whenever it changes. Because of this, any replica in the ISR is eligible to be elected leader. This is an important factor for Kafka's usage model where there are many partitions and ensuring leadership balance is important. With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages.
The ability to commit without the slowest servers is an advantage of the majority vote approach.
Kafka does not require that crashed nodes recover with all their data intact.
we do not want to require the use of fsync on every write for our consistency guarantees as this can reduce performance by two to three orders of magnitude. Our protocol for allowing a replica to rejoin the ISR ensures that before rejoining, it must fully re-sync again even if it lost unflushed data in its crash.
Unclean leader election: What if they all die?
Wait for a replica in the ISR to come back to life and choose this replica as the leader (hopefully it still has all its data).
Choose the first replica (not necessarily in the ISR) that comes back to life as the leader.
This is a simple tradeoff between availability and consistency. If we wait for replicas in the ISR, then we will remain unavailable as long as those replicas are down. If such replicas were destroyed or their data was lost, then we are permanently down. If, on the other hand, a non-in-sync replica comes back to life and we allow it to become the leader, then its log becomes the source of truth even though it is not guaranteed to have every committed message. In our current release we choose the second strategy and favor choosing a potentially inconsistent replica when all replicas in the ISR are dead. In the future, we would like to make this configurable to better support use cases where downtime is preferable to inconsistency.
Replica Management
We attempt to balance partitions within a cluster in a round-robin fashion to avoid clustering all partitions for high-volume topics on a small number of nodes. Likewise we try to balance leadership so that each node is the leader for a proportional share of its partitions.
It is also important to optimize the leadership election process as that is the critical window of unavailability.
A naive implementation of leader election would end up running an election per partition for all partitions a node hosted when that node failed. Instead, we elect one of the brokers as the "controller". This controller detects failures at the broker level and is responsible for changing the leader of all affected partitions in a failed broker. The result is that we are able to batch together many of the required leadership change notifications which makes the election process far cheaper and faster for a large number of partitions. If the controller fails, one of the surviving brokers will become the new controller.
5. Implementation
5.1 API Design
Producer APIs
kafka.producer.Producer provides the ability to batch multiple produce requests (producer.type=async), before serializing and dispatching them to the appropriate kafka broker partition. The size of the batch can be controlled by a few config parameters. As events enter a queue, they are buffered in a queue, until either queue.time or batch.size is reached. A background thread (kafka.producer.async.ProducerSendThread) dequeues the batch of data and lets the kafka.producer.DefaultEventHandler serialize and send the data to the appropriate kafka broker partition.
The zookeeper based broker discovery and load balancing can be used by specifying the zookeeper connection url through the zk.connect config parameter. For some applications, however, the dependence on zookeeper is inappropriate. In that case, the producer can take in a static list of brokers through the broker.list config parameter. Each produce requests gets routed to a random broker partition in this case. If that broker is down, the produce request fails.
provides software load balancing through an optionally user-specified Partitioner -partitioner.class
Consumer APIs
The low-level "simple" API maintains a connection to a single broker and has a close correspondence to the network requests sent to the server. This API is completely stateless, with the offset being passed in on every request, allowing the user to maintain this metadata however they choose.
The high-level API hides the details of brokers from the consumer and allows consuming off the cluster of machines without concern for the underlying topology. It also maintains the state of what has been consumed. The high-level API also provides the ability to subscribe to topics that match a filter expression (i.e., either a whitelist or a blacklist regular expression).
5.2 Network Layer - NIO Server
The sendfile implementation is done by giving the MessageSet interface a writeTo method. This allows the file-backed message set to use the more efficient transferTo implementation instead of an in-process buffered write. The threading model is a single acceptor thread and N processor threads which handle a fixed number of connections each. This design has been pretty thoroughly tested elsewhere and found to be simple to implement and fast. The protocol is kept quite simple to allow for future implementation of clients in other languages.
5.3 Messages
Messages consist of a fixed-size header and variable length opaque byte array payload. The header contains a format version and a CRC32 checksum to detect corruption or truncation.
5.5 Log
A log for a topic named "my_topic" with two partitions consists of two directories (namely my_topic_0 and my_topic_1) populated with data files containing the messages for that topic. The format of the log files is a sequence of "log entries""; each log entry is a 4 byte integer N storing the message length which is followed by the N message bytes. Each message is uniquely identified by a 64-bit integer offset giving the byte position of the start of this message in the stream of all messages ever sent to that topic on that partition. The on-disk format of each message is given below. Each log file is named with the offset of the first message it contains. So the first file created will be 00000000000.kafka, and each additional file will have an integer name roughly S bytes from the previous file where S is the max log file size given in the configuration.
The exact binary format for messages is versioned and maintained as a standard interface so message sets can be transfered between producer, broker, and client without recopying or conversion when desirable.
we decided to use a simple per-partition atomic counter which could be coupled with the partition id and node id to uniquely identify a message; this makes the lookup structure simpler, though multiple seeks per consumer request are still likely.
Reads
Reads are done by giving the 64-bit logical offset of a message and an S-byte max chunk size.
This will return an iterator over the messages contained in the S-byte buffer. S is intended to be larger than any single message, but in the event of an abnormally large message, the read can be retried multiple times, each time doubling the buffer size, until the message is read successfully.
Deletes
To avoid locking reads while still allowing deletes that modify the segment list we use a copy-on-write style segment list implementation that provides consistent views to allow a binary search to proceed on an immutable static snapshot view of the log segments while deletes are progressing.
A message entry is valid if the sum of its size and offset are less than the length of the file AND the CRC32 of the message payload matches the CRC stored with the message. In the event corruption is detected the log is truncated to the last valid offset.
Broker Node Registry
This is a list of all present broker nodes, each of which provides a unique logical broker id which identifies it to consumers (which must be given as part of its configuration).
The purpose of the logical broker id is to allow a broker to be moved to a different physical machine without affecting consumers.
Each broker registers itself under the topics it maintains and stores the number of partitions for that topic.
Consumers and Consumer Groups
Consumers of topics also register themselves in Zookeeper, in order to balance the consumption of data and track their offsets in each partition for each broker they consume from.
Multiple consumers can form a group and jointly consume a single topic. Each consumer in the same group is given a shared group_id.
The consumers in a group divide up the partitions as fairly as possible, each partition is consumed by exactly one consumer in a consumer group.
Consumer Id Registry
In addition to the group_id which is shared by all consumers in a group, each consumer is given a transient, unique consumer_id (of the form hostname:uuid) for identification purposes.
Consumer Offset Tracking
Consumers track the maximum offset they have consumed in each partition. This value is stored in a zookeeper directory
/consumers/[group_id]/offsets/[topic]/[partition_id] --> offset_counter_value ((persistent node)
============
Kafka can be compared with Scribe or Flume as it is useful for processing activity stream data; but from the architecture perspective, it is closer to traditional messaging systems such as ActiveMQ or RabitMQ.
export KAFKA_HOME=/Users/yyuan/jyuan/src/apache/kafka/kafka_2.11-0.8.2.1
five main components:
Topic: A topic is a category or feed name to which messages are published by the message producers. In Kafka, topics are partitioned and each partition is represented by the ordered immutable sequence of messages. A Kafka cluster maintains the partitioned log for each topic.
Each message in the partition is assigned a unique sequential ID called the offset.
Broker: A Kafka cluster consists of one or more servers where each one may have one or more server processes running and is called the broker.
Topics are created within the context of broker processes.
Zookeeper: ZooKeeper serves as the coordination interface between the Kafka broker and consumers.
ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchical name space of data registers (we call these registers znodes), much like a file system.
Producers: Producers publish data to the topics by choosing the appropriate partition within the topic. For load balancing, the allocation of messages to the topic partition can be done in a round-robin fashion or using a custom defined function.
Consumer: Consumers are the applications or processes that subscribe to topics and process the feed of published messages.
Starting zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
Starting the Kafka broker
bin/kafka-server-start.sh config/server.properties
Creating a Kafka topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafkatopic
bin/kafka-topics.sh --list --zookeeper localhost:2181
Starting a producer to send messages
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafkatopic
Starting a consumer to consume messages
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic kafkatopic --from-beginning
A single node – multiple broker clusters
bin/kafka-server-start.sh config/server-1.properties
bin/kafka-server-start.sh config/server-2.properties
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic replicated-kafkatopic
bin/kafka-console-producer.sh --broker-list localhost:9092, localhost:9093 --topic replicated-kafkatopic
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic replicated-kafkatopic
Kafka Design
a producer publishes messages to a Kafka topic (synonymous with "messaging queue"). A topic is also considered as a message category or feed name to which messages are published. Kafka topics are created on a Kafka broker acting as a Kafka server. Kafka brokers also store the messages if required. Consumers then subscribe to the Kafka topic (one or more) to get the messages. Here, brokers and consumers use Zookeeper to get the state information and to track message offsets, respectively.
In Kafka topics, every partition is mapped to a logical log file that is represented as a set of segment files of equal sizes. Every partition is an ordered, immutable sequence of messages; each time a message is published to a partition, the broker appends the message to the last segment file. These segment files are flushed to disk after configurable numbers of messages have been published or after a certain amount of time has elapsed. Once the segment file is flushed, messages are made available to the consumers for consumption.
All the message partitions are assigned a unique sequential number called the offset, which is used to identify each message within the partition. Each partition is optionally replicated across a configurable number of servers for fault tolerance.
Each partition available on either of the servers acts as the leader and has zero or more servers acting as followers. Here the leader is responsible for handling all read and write requests for the partition while the followers asynchronously replicate data from the leader. Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader and always persist the latest ISR set to ZooKeeper. In if the leader fails, one of the followers (in-sync replicas) will automatically become the new leader. In a Kafka cluster, each server plays a dual role; it acts as a leader for some of its partitions and also a follower for other partitions. This ensures the load balance within the Kafka cluster.
each consumer is represented as a process and these processes are organized within groups called consumer groups.
A message within a topic is consumed by a single process (consumer) within the consumer group
Consumers always consume messages from a particular partition sequentially and also acknowledge the message offset. This acknowledgement implies that the consumer has consumed all prior messages. Consumers issue an asynchronous pull request containing the offset of the message to be consumed to the broker and get the buffer of bytes.
brokers are stateless, which means the message state of any consumed message is maintained within the message consumer, and the Kafka broker does not maintain a record of what is consumed by whom.
Kafka defines the time-based SLA (service level agreement) as a message retention policy.
The fundamental backbone of Kafka is message caching and storing on the fiesystem. In Kafka, data is immediately written to the OS kernel page. Caching and flushing of data to the disk are configurable.
Kafka provides longer retention of messages even after consumption, allowing consumers to re-consume, if required.
Kafka uses a message set to group messages to allow lesser network overhead.
Unlike most messaging systems, where metadata of the consumed messages are kept at the server level, in Kafka the state of the consumed messages is maintained at the consumer level. This also addresses issues such as:
In Kafka, producers and consumers work on the traditional push-and-pull model, where producers push the message to a Kafka broker and consumers pull the message from the broker.
Kafka does not have any concept of a master and treats all the brokers as peers. This approach facilitates addition and removal of a Kafka broker at any point, as the metadata of brokers are maintained in Zookeeper and shared with consumers.
Producers also have an option to choose between asynchronous or synchronous mode to send messages to a broker.
Message compression
the lead broker is responsible for serving the messages for a partition by assigning unique logical offsets to every message before it is appended to the logs. In the case of compressed data, the lead broker has to decompress the message set in order to assign offsets to the messages inside the compressed message set. Once offsets are assigned, the leader again compresses the data and then appends it to the disk.
ByteBufferMessageSet
Message compression techniques are very useful for mirroring data across datacenters using Kafka, where large amounts of data get transferred from active to passive datacenters in the compressed format.
Replication in Kafka
replication guarantees that the message will be published and consumed even in the case of broker failure
In replication, each partition of a message has n replicas and can afford n-1 failures to guarantee message delivery. Out of the n replicas, one replica acts as the lead replica for the rest of the replicas. Zookeeper keeps the information about the lead replica and the current follower in-sync replicas (ISR). The lead replica maintains the list of all in-sync follower replicas.
Producers
The producer connects to any of the alive nodes and requests metadata about the leaders for the partitions of a topic. This allows the producer to put the message directly to the lead broker for the partition.
The Kafka producer API exposes the interface for semantic partitioning by allowing the producer to specify a key to partition by and using this to hash to a partition. Thus, the producer can completely control which partition it publishes messages to; for example, if customer ID is selected as a key, then all data for a given customer will be sent to the same partition. This also allows data consumers to make locality assumptions about customer data.
kafka.javaapi.producer.Producer
The default message partitioner is based on the hash of the key.
Properties props = new Properties();
props.put("metadata.broker.list","localhost:9092, localhost:9093, localhost:9094");
props.put("serializer.class","kafka.serializer.StringEncoder");
props.put("request.required.acks", "1");
ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String> (config);
By default, the producer works in the "fire and forget" mode and is not informed in the case of message loss.
props.put("partitioner.class", "kafka.examples.ch4.SimplePartitioner");
Consumers
The consumer subscribes to the message consumption from a specific topic on the Kafka broker. The consumer then issues a fetch request to the lead broker to consume the message partition by specifying the message offset (the beginning position of the message offset). Therefore, the Kafka consumer works in the pull model and always pulls all available messages after its current position in the Kafka log (the Kafka internal data representation).
http://www.allenlipeng47.com/blog/index.php/2016/02/04/kafka-study-summary/

For example, a partition has below 4 segments.


Avoid Random Disk Access
Kafka writes everything into disk instead of memory. Wait a moment, isn’t memory supposed to be faster than disk? Typically it’s the case for Random Disk Access. But for sequential access, the difference is much smaller.
 no zero copy
no zero copy
 zero copy
https://toutiao.io/posts/508935/app_preview
zero copy
https://toutiao.io/posts/508935/app_preview

上图就展示了Kafka是如何写入数据的,每一个Partition其实都是一个文件,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
这种方法有一个缺陷——没有办法删除数据,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据。

通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
mmap其实是Linux中的一个函数就是用来实现内存映射的,谢谢Java NIO,它给我提供了一个mappedbytebuffer类可以用来实现内存映射
插件支持:现在不少活跃的社区已经开发出不少插件来拓展Kafka的功能,如用来配合Storm、Hadoop、flume相关的插件。
http://segmentfault.com/a/1190000003922549
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+data+structures+in+Zookeeper
Apache Kafka Cookbook
Using Logstash
input {
kafka {
zk_connect =>"localhost:2181"
topic_id =>"mytesttopic"
consumer_id =>"myconsumerid"
group_id =>"mylogstash"
fetch_message_max_bytes => 1048576
}
}
output {
elasticsearch {
host => localhost
}
}
Integrating Spark with Kafka
Apache Spark has a very simple utility class that can be used to create the data stream to be read from Kafka.
SparkConf sparkConf = new SparkConf().setAppName("MySparkTest");
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.seconds(10));
Next we create the Hashset for the topic and Kafka consumer parameters.
HashSet<String> topicsSet = new HashSet<String>();
topicsSet.add("mytesttopic");
HashMap<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("metadata.broker.list", "localhost:9092");
Now we can create a direct Kafka stream with brokers and topics
JavaPairInputDStream<String, String> messages = KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParams,
topicsSet
);
Now with this stream you can run your regular data processing algorithms.
Integrating Storm with Kafka
Storm has a built in KafkaSpout that can be used to easily ingest data from Kafka to the Storm topology.
First we have to create the ZkHosts object with the ZooKeeper address in host:port format.
BrokerHosts hosts = new ZkHosts("127.0.0.1:2181");
Next we need to create the SpoutConfig object that will contain the parameters needed for KafkaSpout. We also declare the scheme for the KafkaSpout config.
SpoutConfig kafkaConf = new SpoutConfig(hosts, "mytesttopic", "/brokers", "mytest");
kafkaConf.scheme = new SchemeAsMultiScheme(new StringScheme());
Using this info we create a KafkaSpout object.
KafkaSpout kafkaSpout = new KafkaSpout(kafkaConf);
Now we can build that topology with this spout and get it up-and-running.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", kafkaSpout, 10);
After this, you can connect any number of Storm bolts to do the required data processing for you.
> bin/plugin -install kafka-river -url https://github.com/mariamhakobyan/elasticsearch-river-kafka/releases/download/v1.2.1/elasticsearch-river-kafka-1.2.1-plugin.zip
> curl -XPUT 'localhost:9200/_river/kafka-river/_meta' -d '
{
"type" : "kafka",
"kafka" : {
"zookeeper.connect" : "localhost:2181",
"zookeeper.connection.timeout.ms" : 10000,
"topic" : "mytesttopic",
"message.type" : "string"
},
"index" : {
"index" : "kafka-index",
"type" : "status",
"bulk.size" : 100,
"concurrent.requests" : 1,
"action.type" : "index",
"flush.interval" : "12h"
},
"statsd": {
"host" : "localhost",
"prefix" : "kafka.river",
"port" : 8125,
"log.interval" : 10
}
}'
Integrating SolrCloud with Kafka - using flume
Flume is a reliable, highly available, distributed service for collecting, aggregating, and moving large amounts of log data into any data storage solution that you might use. Your ,data destination might be any of HDFS, Kafka, Hive, or any of the various sinks that Flume supports. You can also use Flume to transfer your data from one Kafka node to another Kafka node.
What Flume has is a source (where the data is being read from), a channel (through which data passes between the source and sink), and a sink (where the data is pushed to).
flume1.sources = kafka-source-1
flume1.channels = mem-channel-1
flume1.sinks = solr-sink-1
flume1.sources.kafka-source-1.type = org.apache.flume.source.kafka.KafkaSource
flume1.sources.kafka-source-1.zookeeperConnect = localhost:2181
flume1.sources.kafka-source-1.topic = srctopic
flume1.sources.kafka-source-1.batchSize = 100
flume1.sources.kafka-source-1.channels = mem-channel-1
flume1.channels.mem-channel-1.type = memory
flume1.sinks.solr-sink-1.channel = mem-channel-1
flume1.sinks.solr-sink-1.type = org.apache.flume.sink.solr.morphline.MorphlineSolrSink
flume1.sinks.solr-sink-1.batchSize = 100
flume1.sinks.solr-sink-1.batchDurationMillis = 1000
flume1.sinks.solr-sink-1.morphlineFile = /etc/flume-ng/conf/morphline.conf
flume1.sinks.solr-sink-1.morphlineId = morphline1
Next you need to run Flume using the configuration file created earlier.
> flume-ng agent --conf-file flume.conf --name flume1
http://stackoverflow.com/questions/30655361/does-kafka-support-priority-for-topic-or-message
joining two streams (of any kind) requires both to be partitioned on the join key using the same number of partitions. Thus, you would need to over partition the lower rate stream with the larger number of partitions from the high rate stream. This repartitioning will happen automatically in the next release of Kafka 0.10.1.0 (should be release this or next week); currently, you need to create a topic manually with the correct number of partitions before you start your Kafka Streams application and repartition before the join using
KStreamBuilder builder = new KStreamBuilder();
KStream<String, Long> longs = builder.stream(
Serdes.String(), Serdes.Long(), "longs");
// In one ktable, count by key on a ten second tumbling window.
KTable<Windowed<String>, Long> longCounts =
longs.countByKey(TimeWindows.of("longCounts", 10000L),
Serdes.String());
// In another ktable, sum the values on a ten second tumbling window.
KTable<Windowed<String>, Long> longSums =
longs.reduceByKey((v1, v2) -> v1 + v2,
TimeWindows.of("longSums", 10000L),
Serdes.String(),
Serdes.Long());
// We can join the two tables to get the average.
KTable<Windowed<String>, Double> longAvgs =
longSums.join(longCounts,
(sum, count) ->
sum.doubleValue()/count.doubleValue());
// Finally, sink to the long-avgs topic.
longAvgs.toStream((wk, v) -> wk.key())
.to(Serdes.String(),
Serdes.Double(),
"long-avgs");
https://stackoverflow.com/questions/39586635/why-kafka-is-pull-based-instead-of-push-based
Secor is a service persisting Kafka logs to Amazon S3, Google Cloud Storage and Openstack Swift.
Kafka: The Definitive Guide
For efficiency, messages are written into Kafka in batches. A batch is just a collection of messages, all of which are being produced to the same topic and partition.
Batches are also typically compressed.
Many Kafka developers favor the use of Apache Avro. Avro provides a compact serialization format, schemas that are separate from the message payloads and that do not require generated code when they change, as well as strong data typing and schema evolution, with both backwards and forwards compatibility.
A consistent data format is important in Kafka, as it allows writing and reading messages to be decoupled.
By using well-defined schemas, and storing them in a common repository, the messages in Kafka can be understood without coordination.
Messages in Kafka are categorized into topics. The closest analogy for a topic is a database table, or a folder in a filesystem.
Topics are additionally broken down into a number of partitions.
as a topic generally has multiple partitions, there is no guarantee of time-ordering of messages across the entire topic, just within a single partition.
Partitions are also the way that Kafka provides redundancy and scalability.
Each partition can be hosted on a different server, which means that a single topic can be scaled horizontally across multiple servers to provide for performance far beyond the ability of a single server.
In some cases, the producer will direct messages to specific partitions. This is typically done using the message key and a partitioner that will generate a hash of the key and map it to a specific partition. This assures that all messages produced with a given key will get written to the same partition.
The consumer keeps track of which messages it has already consumed by keeping track of the offset of messages.
The offset is another bit of metadata, an integer value that continually increases, that Kafka adds to each message as it is produced. Each message within a given partition has a unique offset.
By storing the offset of the last consumed message for each partition, either in Zookeeper or in Kafka itself, a consumer can stop and restart without losing its place.
Consumers work as part of a consumer group. This is one or more consumers that work together to consume a topic. The group assures that each partition is only consumed by one member.
consumers can horizontally scale to consume topics with a large number of messages. Additionally, if a single consumer fails, the remaining members of the group will rebalance the partitions being consumed to take over for the missing member.
A single Kafka server is called a broker. The broker receives messages from producers, assigns offsets to them, and commits the messages to storage on disk. It also services consumers, responding to fetch requests for partitions and responding with the messages that have been committed to disk.
Depending on the specific hardware and its performance characteristics, a single broker can easily handle thousands of partitions and millions of messages per second.
Kafka brokers are designed to operate as part of a cluster. Within a cluster of brokers, one will also function as the cluster controller (elected automatically from the live members of the cluster).
The controller is responsible for administrative operations, including assigning partitions to brokers and monitoring for broker failures.
A partition is owned by a single broker in the cluster, and that broker is called the leader for the partition. A partition may be assigned to multiple brokers, which will result in the partition being replicated. This provides redundancy of messages in the partition, such that another broker can take over leadership if there is a broker failure. However, all consumers and producers operating on that partition must connect to the leader.
Mirror Maker is simply a Kafka consumer and producer, linked together with a queu. Messages are consumed from one Kafka cluster and produced to another
Why Kafka?
Multiple Producers
Multiple Consumers
Kafka is designed for multiple consumers to read any single stream of messages without interfering with each other. This is in opposition to many queuing systems where once a message is consumed by one client, it is not available to any other client. At the same time, multiple Kafka consumers can choose to operate as part of a group and share a stream, assuring that the entire group processes a given message only once.
Disk-based Retention
durable message retention means that consumers do not always need to work in real time
Scalable
High Performance
https://miafish.wordpress.com/2015/03/06/kafka/
the whole modelproducers write data to brokers(kafka)
comsumers read data from brokers(kafka).
Data is stored in topics
topics are split into partitions, which are replicated.
partition: ordered + immutable sequence of messages that is continually appended to
Offset: messages in the partitions are each assigned a unique (per partition) and sequential id called the offset.
Consumers track their pointers via (offset, partition, topic) tuples Consumer group C1
Zookeeper will maintain the leader and replicas.
Replicas: backups of a partition. they exist solely to prevent data loss.
Here is a graph for relationship of consumer group and paritions. A two server Kafka cluster hosting four partitions(P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
what are the advantages of kafka
- distributed system which is very easy to scale out
- offers high throughput for both publishing and subscribing
- support multi-subscribers and automatically balances the consumers during failure
- low latency
https://kafka.apache.org/08/design.html
Don't fear the filesystem!
rather than maintain as much as possible in-memory and flush it all out to the filesystem in a panic when we run out of space, we invert that. All data is immediately written to a persistent log on the filesystem without necessarily flushing to disk. In effect this just means that it is transferred into the kernel's pagecache.
Furthermore we are building on top of the JVM, and anyone who has spent any time with Java memory usage knows two things:
- The memory overhead of objects is very high, often doubling the size of the data stored (or worse).
- Java garbage collection becomes increasingly fiddly and slow as the in-heap data increases.
The persistent data structure used in messaging systems are often a per-consumer queue with an associated BTree or other general-purpose random access data structures to maintain metadata about messages. BTrees are the most versatile data structure available, and make it possible to support a wide variety of transactional and non-transactional semantics in the messaging system. They do come with a fairly high cost, though: Btree operations are O(log N). Normally O(log N) is considered essentially equivalent to constant time, but this is not true for disk operations. Disk seeks come at 10 ms a pop, and each disk can do only one seek at a time so parallelism is limited. Hence even a handful of disk seeks leads to very high overhead. Since storage systems mix very fast cached operations with very slow physical disk operations, the observed performance of tree structures is often superlinear as data increases with fixed cache--i.e. doubling your data makes things much worse then twice as slow.
Intuitively a persistent queue could be built on simple reads and appends to files as is commonly the case with logging solutions. This structure has the advantage that all operations are O(1) and reads do not block writes or each other. This has obvious performance advantages since the performance is completely decoupled from the data size—one server can now take full advantage of a number of cheap, low-rotational speed 1+TB SATA drives.
in Kafka, instead of attempting to deleting messages as soon as they are consumed, we can retain messages for a relative long period (say a week). This leads to a great deal of flexibility for consumers
Efficiency
Problems: too many small I/O operations, and excessive byte copying.
our protocol is built around a "message set" abstraction that naturally groups messages together. This allows network requests to group messages together and amortize the overhead of the network roundtrip rather than sending a single message at a time. The server in turn appends chunks of messages to its log in one go, and the consumer fetches large linear chunks at a time.
This simple optimization produces orders of magnitude speed up. Batching leads to larger network packets, larger sequential disk operations, contiguous memory blocks, and so on, all of which allows Kafka to turn a bursty stream of random message writes into linear writes that flow to the consumers.
byte copying:
The message log maintained by the broker is itself just a directory of files, each populated by a sequence of message sets that have been written to disk in the same format used by the producer and consumer. Maintaining this common format allows optimization of the most important operation: network transfer of persistent log chunks. Modern unix operating systems offer a highly optimized code path for transferring data out of pagecache to a socket; in Linux this is done with the sendfile system call.
To understand the impact of sendfile, it is important to understand the common data path for transfer of data from file to socket:
- The operating system reads data from the disk into pagecache in kernel space
- The application reads the data from kernel space into a user-space buffer
- The application writes the data back into kernel space into a socket buffer
- The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network
We expect a common use case to be multiple consumers on a topic. Using the zero-copy optimization above, data is copied into pagecache exactly once and reused on each consumption instead of being stored in memory and copied out to kernel space every time it is read. This allows messages to be consumed at a rate that approaches the limit of the network connection.
End-to-end Batch Compression
Of course the user can always compress its messages one at a time without any support needed from Kafka, but this can lead to very poor compression ratios as much of the redundancy is due to repetition between messages of the same type. Efficient compression requires compressing multiple messages together rather than compressing each message individually.Kafka supports this by allowing recursive message sets. A batch of messages can be clumped together compressed and sent to the server in this form. This batch of messages will be written in compressed form and will remain compressed in the log and will only be decompressed by the consumer.
4.4 The Producer
Load balancing
Asynchronous send
4.5 The Consumer
Push vs. pull
data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as scribe and flume follow a very different push based path where data is pushed downstream. There are pros and cons to both approaches. However a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems.
data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as scribe and flume follow a very different push based path where data is pushed downstream. There are pros and cons to both approaches. However a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems.
You could imagine other possible designs which would be only pull, end-to-end. The producer would locally write to a local log, and brokers would pull from that with consumers pulling from them. A similar type of "store-and-forward" producer is often proposed. This is intriguing but we felt not very suitable for our target use cases which have thousands of producers. Our experience running persistent data systems at scale led us to feel that involving thousands of disks in the system across many applications would not actually make things more reliable and would be a nightmare to operate. And in practice we have found that we can run a pipeline with strong SLAs at large scale without a need for producer persistence.
Consumer Position
Most messaging systems keep metadata about what messages have been consumed on the broker. since the broker knows what is consumed it can immediately delete it, keeping the data size small.
Our topic is divided into a set of totally ordered partitions, each of which is consumed by one consumer at any given time. This means that the position of consumer in each partition is just a single integer, the offset of the next message to consume. This makes the state about what has been consumed very small, just one number for each partition. This state can be periodically checkpointed. This makes the equivalent of message acknowledgements very cheap.
Offline Data Load
we parallelize the data load by splitting the load over individual map tasks, one for each node/topic/partition combination, allowing full parallelism in the loading. Hadoop provides the task management, and tasks which fail can restart without danger of duplicate data—they simply restart from their original position.
4.6 Message Delivery Semantics
the durability guarantees for publishing a message and the guarantees when consuming a message.
it is possible to allow the producer to generate a sort of "primary key" that makes retrying the produce request idempotent. We hope to add this in a future Kafka version.
For uses which are latency sensitive we allow the producer to specify the durability level it desires. If the producer specifies that it wants to wait on the message being committed this can take on the order of 10 ms. However the producer can also specify that it wants to perform the send completely asynchronously or that it wants to wait only until the leader (but not necessarily the followers) have the message.
All replicas have the exact same log with the same offsets. The consumer controls its position in this log.
Client
It can read the messages, then save its position in the log, and finally process the messages. - at most once
It can read the messages, process the messages, and finally save its position. - at-least-once. In many cases messages have a primary key and so the updates are idempotent (receiving the same message twice just overwrites a record with another copy of itself).
exactly once
The classic way of achieving this would be to introduce a two-phase commit between the storage for the consumer position and the storage of the consumers output. But this can be handled more simply and generally by simply letting the consumer store its offset in the same place as its output. This is better because many of the output systems a consumer might want to write to will not support a two-phase commit.
our Hadoop ETL that populates data in HDFS stores its offsets in HDFS with the data it reads so that it is guaranteed that either data and offsets are both updated or neither is.
So effectively Kafka guarantees at-least-once delivery by default and allows the user to implement at most once delivery by disabling retries on the producer and committing its offset prior to processing a batch of messages. Exactly-once delivery requires co-operation with the destination storage system but Kafka provides the offset which makes implementing this straight-forward.
4.7 Replication
The unit of replication is the topic partition. Under non-failure conditions, each partition in Kafka has a single leader and zero or more followers. The total number of replicas including the leader constitute the replication factor. All reads and writes go to the leader of the partition. Typically, there are many more partitions than brokers and the leaders are evenly distributed among brokers. The logs on the followers are identical to the leader's log.
or Kafka node liveness has two conditions
A node must be able to maintain its session with Zookeeper (via Zookeeper's heartbeat mechanism)
If it is a slave it must replicate the writes happening on the leader and not fall "too far" behind
The leader keeps track of the set of "in sync" nodes. If a follower dies, gets stuck, or falls behind, the leader will remove it from the list of in sync replicas. The definition of, how far behind is too far, is controlled by the replica.lag.max.messages configuration and the definition of a stuck replica is controlled by the replica.lag.time.max.ms configuration.
A message is considered "committed" when all in sync replicas for that partition have applied it to their log. Only committed messages are ever given out to the consumer. This means that the consumer need not worry about potentially seeing a message that could be lost if the leader fails. Producers, on the other hand, have the option of either waiting for the message to be committed or not, depending on their preference for tradeoff between latency and durability. This preference is controlled by the request.required.acks setting that the producer uses.
The guarantee that Kafka offers is that a committed message will not be lost, as long as there is at least one in sync replica alive, at all times.
Kafka will remain available in the presence of node failures after a short fail-over period, but may not remain available in the presence of network partitions.
Replicated Logs: Quorums, ISRs, and State Machines (Oh my!)
When the leader does die we need to choose a new leader from among the followers. But followers themselves may fall behind or crash so we must ensure we choose an up-to-date follower. The fundamental guarantee a log replication algorithm must provide is that if we tell the client a message is committed, and the leader fails, the new leader we elect must also have that message. This yields a tradeoff: if the leader waits for more followers to acknowledge a message before declaring it committed then there will be more potentially electable leaders.
If you choose the number of acknowledgements required and the number of logs that must be compared to elect a leader such that there is guaranteed to be an overlap, then this is called a Quorum.
A common approach to this tradeoff is to use a majority vote for both the commit decision and the leader election. This is not what Kafka does, but let's explore it anyway to understand the tradeoffs. Let's say we have 2f+1 replicas. If f+1 replicas must receive a message prior to a commit being declared by the leader, and if we elect a new leader by electing the follower with the most complete log from at least f+1 replicas, then, with no more than f failures, the leader is guaranteed to have all committed messages. This is because among any f+1 replicas, there must be at least one replica that contains all committed messages. That replica's log will be the most complete and therefore will be selected as the new leader.
There are a rich variety of algorithms in this family including Zookeeper's Zab, Raft, and Viewstamped Replication. The most similar academic publication we are aware of to Kafka's actual implementation is PacificA from Microsoft.
The downside of majority vote is that it doesn't take many failures to leave you with no electable leaders. To tolerate one failure requires three copies of the data, and to tolerate two failures requires five copies of the data.
The downside of majority vote is that it doesn't take many failures to leave you with no electable leaders. To tolerate one failure requires three copies of the data, and to tolerate two failures requires five copies of the data.
Instead of majority vote, Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not considered committed until all in-sync replicas have received the write. This ISR set is persisted to zookeeper whenever it changes. Because of this, any replica in the ISR is eligible to be elected leader. This is an important factor for Kafka's usage model where there are many partitions and ensuring leadership balance is important. With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages.
The ability to commit without the slowest servers is an advantage of the majority vote approach.
Kafka does not require that crashed nodes recover with all their data intact.
we do not want to require the use of fsync on every write for our consistency guarantees as this can reduce performance by two to three orders of magnitude. Our protocol for allowing a replica to rejoin the ISR ensures that before rejoining, it must fully re-sync again even if it lost unflushed data in its crash.
Unclean leader election: What if they all die?
Wait for a replica in the ISR to come back to life and choose this replica as the leader (hopefully it still has all its data).
Choose the first replica (not necessarily in the ISR) that comes back to life as the leader.
This is a simple tradeoff between availability and consistency. If we wait for replicas in the ISR, then we will remain unavailable as long as those replicas are down. If such replicas were destroyed or their data was lost, then we are permanently down. If, on the other hand, a non-in-sync replica comes back to life and we allow it to become the leader, then its log becomes the source of truth even though it is not guaranteed to have every committed message. In our current release we choose the second strategy and favor choosing a potentially inconsistent replica when all replicas in the ISR are dead. In the future, we would like to make this configurable to better support use cases where downtime is preferable to inconsistency.
Replica Management
We attempt to balance partitions within a cluster in a round-robin fashion to avoid clustering all partitions for high-volume topics on a small number of nodes. Likewise we try to balance leadership so that each node is the leader for a proportional share of its partitions.
It is also important to optimize the leadership election process as that is the critical window of unavailability.
A naive implementation of leader election would end up running an election per partition for all partitions a node hosted when that node failed. Instead, we elect one of the brokers as the "controller". This controller detects failures at the broker level and is responsible for changing the leader of all affected partitions in a failed broker. The result is that we are able to batch together many of the required leadership change notifications which makes the election process far cheaper and faster for a large number of partitions. If the controller fails, one of the surviving brokers will become the new controller.
5. Implementation
5.1 API Design
Producer APIs
kafka.producer.Producer provides the ability to batch multiple produce requests (producer.type=async), before serializing and dispatching them to the appropriate kafka broker partition. The size of the batch can be controlled by a few config parameters. As events enter a queue, they are buffered in a queue, until either queue.time or batch.size is reached. A background thread (kafka.producer.async.ProducerSendThread) dequeues the batch of data and lets the kafka.producer.DefaultEventHandler serialize and send the data to the appropriate kafka broker partition.
The zookeeper based broker discovery and load balancing can be used by specifying the zookeeper connection url through the zk.connect config parameter. For some applications, however, the dependence on zookeeper is inappropriate. In that case, the producer can take in a static list of brokers through the broker.list config parameter. Each produce requests gets routed to a random broker partition in this case. If that broker is down, the produce request fails.
provides software load balancing through an optionally user-specified Partitioner -partitioner.class
Consumer APIs
The low-level "simple" API maintains a connection to a single broker and has a close correspondence to the network requests sent to the server. This API is completely stateless, with the offset being passed in on every request, allowing the user to maintain this metadata however they choose.
The high-level API hides the details of brokers from the consumer and allows consuming off the cluster of machines without concern for the underlying topology. It also maintains the state of what has been consumed. The high-level API also provides the ability to subscribe to topics that match a filter expression (i.e., either a whitelist or a blacklist regular expression).
5.2 Network Layer - NIO Server
The sendfile implementation is done by giving the MessageSet interface a writeTo method. This allows the file-backed message set to use the more efficient transferTo implementation instead of an in-process buffered write. The threading model is a single acceptor thread and N processor threads which handle a fixed number of connections each. This design has been pretty thoroughly tested elsewhere and found to be simple to implement and fast. The protocol is kept quite simple to allow for future implementation of clients in other languages.
5.3 Messages
Messages consist of a fixed-size header and variable length opaque byte array payload. The header contains a format version and a CRC32 checksum to detect corruption or truncation.
5.5 Log
A log for a topic named "my_topic" with two partitions consists of two directories (namely my_topic_0 and my_topic_1) populated with data files containing the messages for that topic. The format of the log files is a sequence of "log entries""; each log entry is a 4 byte integer N storing the message length which is followed by the N message bytes. Each message is uniquely identified by a 64-bit integer offset giving the byte position of the start of this message in the stream of all messages ever sent to that topic on that partition. The on-disk format of each message is given below. Each log file is named with the offset of the first message it contains. So the first file created will be 00000000000.kafka, and each additional file will have an integer name roughly S bytes from the previous file where S is the max log file size given in the configuration.
The exact binary format for messages is versioned and maintained as a standard interface so message sets can be transfered between producer, broker, and client without recopying or conversion when desirable.
we decided to use a simple per-partition atomic counter which could be coupled with the partition id and node id to uniquely identify a message; this makes the lookup structure simpler, though multiple seeks per consumer request are still likely.
Reads
Reads are done by giving the 64-bit logical offset of a message and an S-byte max chunk size.
This will return an iterator over the messages contained in the S-byte buffer. S is intended to be larger than any single message, but in the event of an abnormally large message, the read can be retried multiple times, each time doubling the buffer size, until the message is read successfully.
Deletes
To avoid locking reads while still allowing deletes that modify the segment list we use a copy-on-write style segment list implementation that provides consistent views to allow a binary search to proceed on an immutable static snapshot view of the log segments while deletes are progressing.
A message entry is valid if the sum of its size and offset are less than the length of the file AND the CRC32 of the message payload matches the CRC stored with the message. In the event corruption is detected the log is truncated to the last valid offset.
Broker Node Registry
This is a list of all present broker nodes, each of which provides a unique logical broker id which identifies it to consumers (which must be given as part of its configuration).
The purpose of the logical broker id is to allow a broker to be moved to a different physical machine without affecting consumers.
Each broker registers itself under the topics it maintains and stores the number of partitions for that topic.
Consumers and Consumer Groups
Consumers of topics also register themselves in Zookeeper, in order to balance the consumption of data and track their offsets in each partition for each broker they consume from.
Multiple consumers can form a group and jointly consume a single topic. Each consumer in the same group is given a shared group_id.
The consumers in a group divide up the partitions as fairly as possible, each partition is consumed by exactly one consumer in a consumer group.
Consumer Id Registry
In addition to the group_id which is shared by all consumers in a group, each consumer is given a transient, unique consumer_id (of the form hostname:uuid) for identification purposes.
Consumer Offset Tracking
Consumers track the maximum offset they have consumed in each partition. This value is stored in a zookeeper directory
/consumers/[group_id]/offsets/[topic]/[partition_id] --> offset_counter_value ((persistent node)
============
Kafka can be compared with Scribe or Flume as it is useful for processing activity stream data; but from the architecture perspective, it is closer to traditional messaging systems such as ActiveMQ or RabitMQ.
export KAFKA_HOME=/Users/yyuan/jyuan/src/apache/kafka/kafka_2.11-0.8.2.1
five main components:
Topic: A topic is a category or feed name to which messages are published by the message producers. In Kafka, topics are partitioned and each partition is represented by the ordered immutable sequence of messages. A Kafka cluster maintains the partitioned log for each topic.
Each message in the partition is assigned a unique sequential ID called the offset.
Broker: A Kafka cluster consists of one or more servers where each one may have one or more server processes running and is called the broker.
Topics are created within the context of broker processes.
Zookeeper: ZooKeeper serves as the coordination interface between the Kafka broker and consumers.
ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchical name space of data registers (we call these registers znodes), much like a file system.
Producers: Producers publish data to the topics by choosing the appropriate partition within the topic. For load balancing, the allocation of messages to the topic partition can be done in a round-robin fashion or using a custom defined function.
Consumer: Consumers are the applications or processes that subscribe to topics and process the feed of published messages.
Starting zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
Starting the Kafka broker
bin/kafka-server-start.sh config/server.properties
Creating a Kafka topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafkatopic
bin/kafka-topics.sh --list --zookeeper localhost:2181
Starting a producer to send messages
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafkatopic
Starting a consumer to consume messages
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic kafkatopic --from-beginning
A single node – multiple broker clusters
bin/kafka-server-start.sh config/server-1.properties
bin/kafka-server-start.sh config/server-2.properties
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic replicated-kafkatopic
bin/kafka-console-producer.sh --broker-list localhost:9092, localhost:9093 --topic replicated-kafkatopic
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic replicated-kafkatopic
Kafka Design
a producer publishes messages to a Kafka topic (synonymous with "messaging queue"). A topic is also considered as a message category or feed name to which messages are published. Kafka topics are created on a Kafka broker acting as a Kafka server. Kafka brokers also store the messages if required. Consumers then subscribe to the Kafka topic (one or more) to get the messages. Here, brokers and consumers use Zookeeper to get the state information and to track message offsets, respectively.
In Kafka topics, every partition is mapped to a logical log file that is represented as a set of segment files of equal sizes. Every partition is an ordered, immutable sequence of messages; each time a message is published to a partition, the broker appends the message to the last segment file. These segment files are flushed to disk after configurable numbers of messages have been published or after a certain amount of time has elapsed. Once the segment file is flushed, messages are made available to the consumers for consumption.
All the message partitions are assigned a unique sequential number called the offset, which is used to identify each message within the partition. Each partition is optionally replicated across a configurable number of servers for fault tolerance.
Each partition available on either of the servers acts as the leader and has zero or more servers acting as followers. Here the leader is responsible for handling all read and write requests for the partition while the followers asynchronously replicate data from the leader. Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader and always persist the latest ISR set to ZooKeeper. In if the leader fails, one of the followers (in-sync replicas) will automatically become the new leader. In a Kafka cluster, each server plays a dual role; it acts as a leader for some of its partitions and also a follower for other partitions. This ensures the load balance within the Kafka cluster.
each consumer is represented as a process and these processes are organized within groups called consumer groups.
A message within a topic is consumed by a single process (consumer) within the consumer group
Consumers always consume messages from a particular partition sequentially and also acknowledge the message offset. This acknowledgement implies that the consumer has consumed all prior messages. Consumers issue an asynchronous pull request containing the offset of the message to be consumed to the broker and get the buffer of bytes.
brokers are stateless, which means the message state of any consumed message is maintained within the message consumer, and the Kafka broker does not maintain a record of what is consumed by whom.
Kafka defines the time-based SLA (service level agreement) as a message retention policy.
The fundamental backbone of Kafka is message caching and storing on the fiesystem. In Kafka, data is immediately written to the OS kernel page. Caching and flushing of data to the disk are configurable.
Kafka provides longer retention of messages even after consumption, allowing consumers to re-consume, if required.
Kafka uses a message set to group messages to allow lesser network overhead.
Unlike most messaging systems, where metadata of the consumed messages are kept at the server level, in Kafka the state of the consumed messages is maintained at the consumer level. This also addresses issues such as:
In Kafka, producers and consumers work on the traditional push-and-pull model, where producers push the message to a Kafka broker and consumers pull the message from the broker.
Kafka does not have any concept of a master and treats all the brokers as peers. This approach facilitates addition and removal of a Kafka broker at any point, as the metadata of brokers are maintained in Zookeeper and shared with consumers.
Producers also have an option to choose between asynchronous or synchronous mode to send messages to a broker.
Message compression
the lead broker is responsible for serving the messages for a partition by assigning unique logical offsets to every message before it is appended to the logs. In the case of compressed data, the lead broker has to decompress the message set in order to assign offsets to the messages inside the compressed message set. Once offsets are assigned, the leader again compresses the data and then appends it to the disk.
ByteBufferMessageSet
Message compression techniques are very useful for mirroring data across datacenters using Kafka, where large amounts of data get transferred from active to passive datacenters in the compressed format.
Replication in Kafka
replication guarantees that the message will be published and consumed even in the case of broker failure
In replication, each partition of a message has n replicas and can afford n-1 failures to guarantee message delivery. Out of the n replicas, one replica acts as the lead replica for the rest of the replicas. Zookeeper keeps the information about the lead replica and the current follower in-sync replicas (ISR). The lead replica maintains the list of all in-sync follower replicas.
Producers
The producer connects to any of the alive nodes and requests metadata about the leaders for the partitions of a topic. This allows the producer to put the message directly to the lead broker for the partition.
The Kafka producer API exposes the interface for semantic partitioning by allowing the producer to specify a key to partition by and using this to hash to a partition. Thus, the producer can completely control which partition it publishes messages to; for example, if customer ID is selected as a key, then all data for a given customer will be sent to the same partition. This also allows data consumers to make locality assumptions about customer data.
kafka.javaapi.producer.Producer
The default message partitioner is based on the hash of the key.
Properties props = new Properties();
props.put("metadata.broker.list","localhost:9092, localhost:9093, localhost:9094");
props.put("serializer.class","kafka.serializer.StringEncoder");
props.put("request.required.acks", "1");
ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String> (config);
By default, the producer works in the "fire and forget" mode and is not informed in the case of message loss.
props.put("partitioner.class", "kafka.examples.ch4.SimplePartitioner");
Consumers
The consumer subscribes to the message consumption from a specific topic on the Kafka broker. The consumer then issues a fetch request to the lead broker to consume the message partition by specifying the message offset (the beginning position of the message offset). Therefore, the Kafka consumer works in the pull model and always pulls all available messages after its current position in the Kafka log (the Kafka internal data representation).
http://www.allenlipeng47.com/blog/index.php/2016/02/04/kafka-study-summary/
- A topic may has many partitions.
- A partition has to be fit in a server.
- Partitions are distributed and replicated over servers.
- Each partition has a leader server. If the leader server fails, then one of the follower will become leader.
Partition, Segment:
- For a partition, it is physically stored by many segment.
For example, a partition has below 4 segments.
For one segment, the index and log file relationship are like:

Basically, as long as we have offset in partition, then we can find the segment, offset in segment, then the message.
Basically, as long as we have offset in partition, then we can find the segment, offset in segment, then the message.
Consumer, Partition and Stream
- If there are 10 partitions for a topic and 3 consumer instances (C1,C2,C3 started in that order) all belonging to the same Consumer Group, we can have different consumption models that allow read parallelism as below
- Each consumer uses a single stream.In this model, when C1 starts all 10 partitions of the topic are mapped to the same stream and C1 starts consuming from that stream. When C2 starts, Kafka rebalances the partitions between the two streams. So, each stream will be assigned to 5 partitions(depending on the rebalance algorithm it might also be 4 vs 6) and each consumer consumes from its stream. Similarly, when C3 starts, the partitions are again rebalanced between the 3 streams. Note that in this model, when consuming from a stream assigned to more than one partition, the order of messages will be jumbled between partitions.
- Each consumer uses more than one stream (say C1 uses 3, C2 uses 3 and C3 uses 4).In this model, when C1 starts, all the 10 partitions are assigned to the 3 streams and C1 can consume from the 3 streams concurrently using multiple threads. When C2 starts, the partitions are rebalanced between the 6 streams and similarly when C3 starts, the partitions are rebalanced between the 10 streams. Each consumer can consume concurrently from multiple streams. Note that the number of streams and partitions here are equal. In case the number of streams exceed the partitions, some streams will not get any messages as they will not be assigned any partitions.
Deliver guarantee
- If a consumer fails, and another consumer continues the partition. Kafka doesn’t guarantee that the message only commits once.
- If the application requires only one commit, application should design the logic by itself.
Acknowledge Offset
- If the consumer acknowledges a particular message offset, it implies that the consumer has received all messages prior to that offset in the partition.
Below are the links where I studied from:
http://research.microsoft.com/en-us/um/people/srikanth/netdb11/netdb11papers/netdb11-final12.pdf
http://tech.meituan.com/kafka-fs-design-theory.html
http://stackoverflow.com/questions/23136500/how-kafka-broadcast-to-many-consumer-groups
http://searene.me/2017/07/09/Why-is-Kafka-so-fast/http://research.microsoft.com/en-us/um/people/srikanth/netdb11/netdb11papers/netdb11-final12.pdf
http://tech.meituan.com/kafka-fs-design-theory.html
http://stackoverflow.com/questions/23136500/how-kafka-broadcast-to-many-consumer-groups
Avoid Random Disk Access
Kafka writes everything into disk in order and consumers fetch data in order too. So disk access always works sequentially instead of randomly. Due to characteristics of disks, sequential access is much faster than random access. Here is a comparison:
| hardware | linear writes | random writes |
|---|---|---|
| 6 * 7200rpm SATA RAID-5 | 300MB/s | 50KB/s |
But still, memory is faster than Sequential Disk Access, why not choose memory? Because Kafka runs on JVM, which gives us two disadvantages.
- The memory overhead of objects is very high, often doubling the size of the data stored(or even higher).
- Garbage Collection happens every now and then, so creating objects in memory is very expensive as in-heap data increases because we will need more time to collect useless data.
So writing to file systems may be better than writing to memory. Even better, we can utilize MMAP(memory mapped files) to make it faster.
Basically MMAP(Memory Mapped Files) can map the file contents from disk into memory. And when we write something into the mapped memory, the OS will flush the change into disk some time later. So everything is faster because we are using memory here. Why not using memory directly? As we have learned previously, Kafka runs on JVM, if we write data into memory directly, the memory overhead would be high and GC would happen frequently. So we use MMAP here to avoid it.
When consumers fetch data from Kafka servers, those data will be copied from the Kernel Context into the Application Context. Then they will be sent from the Application Context to the Kernel Context while being sent to the socket, like this.
no zero copy
As you can see, it’s redundant to copy data between the Kernel Context and the Application Context. Can we avoid it? Yes, using Zero Copy we can copy data directly from the Kernel Context to the Kernel Context.
zero copyBatch Data
Kafka only sends data when
batch.size is reached instead of one by one. Assuming the bandwidth is 10MB/s, sending 10MB data in one go is much faster than sending 10000 messages one by one(assuming each message takes 100 bytes).生产者(写入数据)
生产者(producer)是负责向Kafka提交数据的,我们先分析这一部分。
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafak采用了两个技术,顺序写入和MMFile。
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafak采用了两个技术,顺序写入和MMFile。
顺序写入
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最“讨厌”随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
上图就展示了Kafka是如何写入数据的,每一个Partition其实都是一个文件,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
这种方法有一个缺陷——没有办法删除数据,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据。
这个offset是由客户端SDK负责保存的,Kafka的Broker完全无视这个东西的存在;一般情况下SDK会把它保存到zookeeper里面。(所以需要给Consumer提供zookeeper的地址)。
如果不删除硬盘肯定会被撑满,所以Kakfa提供了两种策略来删除数据。一是基于时间,二是基于partition文件大小。具体配置可以参看它的配置文档。
如果不删除硬盘肯定会被撑满,所以Kakfa提供了两种策略来删除数据。一是基于时间,二是基于partition文件大小。具体配置可以参看它的配置文档。
Memory Mapped Files
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
Memory Mapped Files(后面简称mmap)也被翻译成内存映射文件,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
Memory Mapped Files(后面简称mmap)也被翻译成内存映射文件,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
mmap其实是Linux中的一个函数就是用来实现内存映射的,谢谢Java NIO,它给我提供了一个mappedbytebuffer类可以用来实现内存映射
Kafka是如何耍赖的
想到了吗?Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把“文件”发送给消费者。这就是秘诀所在,比如:10W的消息组合在一起是10MB的数据量,然后Kafka用类似于发文件的方式直接扔出去了,如果消费者和生产者之间的网络非常好(只要网络稍微正常一点10MB根本不是事。。。家里上网都是100Mbps的带宽了),10MB可能只需要1s。所以答案是——10W的TPS,Kafka每秒钟处理了10W条消息。
可能你说:不可能把整个文件发出去吧?里面还有一些不需要的消息呢?是的,Kafka作为一个“高级作弊分子”自然要把作弊做的有逼格。Zero Copy对应的是sendfile这个函数(以Linux为例),这个函数接受
可能你说:不可能把整个文件发出去吧?里面还有一些不需要的消息呢?是的,Kafka作为一个“高级作弊分子”自然要把作弊做的有逼格。Zero Copy对应的是sendfile这个函数(以Linux为例),这个函数接受
- out_fd作为输出(一般及时socket的句柄)
- in_fd作为输入文件句柄
- off_t表示in_fd的偏移(从哪里开始读取)
- size_t表示读取多少个
没错,Kafka是用mmap作为文件读写方式的,它就是一个文件句柄,所以直接把它传给sendfile;偏移也好解决,用户会自己保持这个offset,每次请求都会发送这个offset。(还记得吗?放在zookeeper中的);数据量更容易解决了,如果消费者想要更快,就全部扔给消费者。如果这样做一般情况下消费者肯定直接就被压死了;所以Kafka提供了的两种方式——Push,我全部扔给你了,你死了不管我的事情;Pull,好吧你告诉我你需要多少个,我给你多少个。
Kafka速度的秘诀在于,它把所有的消息都变成一个的文件。通过mmap提高I/O速度,写入数据的时候它是末尾添加所以速度最优;读取数据的时候配合sendfile直接暴力输出。阿里的RocketMQ也是这种模式,只不过是用Java写的。
单纯的去测试MQ的速度没有任何意义,Kafka这种“暴力”、“流氓”、“无耻”的做法已经脱了MQ的底裤,更像是一个暴力的“数据传送器”。所以对于一个MQ的评价只以速度论英雄,世界上没人能干的过Kafka,我们设计的时候不能听信网上的流言蜚语——“Kafka最快,大家都在用,所以我们的MQ用Kafka没错”。在这种思想的作用下,你可能根本不会关心“失败者”;而实际上可能这些“失败者”是更适合你业务的MQ。
http://blog.csdn.net/suifeng3051/article/details/48053965插件支持:现在不少活跃的社区已经开发出不少插件来拓展Kafka的功能,如用来配合Storm、Hadoop、flume相关的插件。
http://segmentfault.com/a/1190000003922549
一个partition只能被一个消费者消费(但是一个消费者可以同时消费多个partition。),所以,运行的partition的数量要大于运行的comsumer的数量,否则就会有消费者消费不到数据。另一方面,建议partition的数量大于broker 的数量。这样leader partition 的数据就能均匀的分布在各个broker中,最终使得集群负载均衡。
(如果小于会怎样样,会造成比较集中的存储在单个broker之中吗。)。注意:kafka需要为每个partition分配一些内存来缓存消息数据,如果parttion数量越大,分配更大的heap space。
利用文件系统并且依靠页缓存比维护一个内存缓存或者其他结构要好。而事实上,数据被传输到内核页,稍后会被刷新。这里加上了一个配置项来控制让系统的用户来控制数据在什么时候被刷新到物理硬盘上。https://cwiki.apache.org/confluence/display/KAFKA/Kafka+data+structures+in+Zookeeper
Apache Kafka Cookbook
Using Logstash
input {
kafka {
zk_connect =>"localhost:2181"
topic_id =>"mytesttopic"
consumer_id =>"myconsumerid"
group_id =>"mylogstash"
fetch_message_max_bytes => 1048576
}
}
output {
elasticsearch {
host => localhost
}
}
Integrating Spark with Kafka
Apache Spark has a very simple utility class that can be used to create the data stream to be read from Kafka.
SparkConf sparkConf = new SparkConf().setAppName("MySparkTest");
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.seconds(10));
Next we create the Hashset for the topic and Kafka consumer parameters.
HashSet<String> topicsSet = new HashSet<String>();
topicsSet.add("mytesttopic");
HashMap<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put("metadata.broker.list", "localhost:9092");
Now we can create a direct Kafka stream with brokers and topics
JavaPairInputDStream<String, String> messages = KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParams,
topicsSet
);
Now with this stream you can run your regular data processing algorithms.
Integrating Storm with Kafka
Storm has a built in KafkaSpout that can be used to easily ingest data from Kafka to the Storm topology.
First we have to create the ZkHosts object with the ZooKeeper address in host:port format.
BrokerHosts hosts = new ZkHosts("127.0.0.1:2181");
Next we need to create the SpoutConfig object that will contain the parameters needed for KafkaSpout. We also declare the scheme for the KafkaSpout config.
SpoutConfig kafkaConf = new SpoutConfig(hosts, "mytesttopic", "/brokers", "mytest");
kafkaConf.scheme = new SchemeAsMultiScheme(new StringScheme());
Using this info we create a KafkaSpout object.
KafkaSpout kafkaSpout = new KafkaSpout(kafkaConf);
Now we can build that topology with this spout and get it up-and-running.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", kafkaSpout, 10);
After this, you can connect any number of Storm bolts to do the required data processing for you.
> bin/plugin -install kafka-river -url https://github.com/mariamhakobyan/elasticsearch-river-kafka/releases/download/v1.2.1/elasticsearch-river-kafka-1.2.1-plugin.zip
> curl -XPUT 'localhost:9200/_river/kafka-river/_meta' -d '
{
"type" : "kafka",
"kafka" : {
"zookeeper.connect" : "localhost:2181",
"zookeeper.connection.timeout.ms" : 10000,
"topic" : "mytesttopic",
"message.type" : "string"
},
"index" : {
"index" : "kafka-index",
"type" : "status",
"bulk.size" : 100,
"concurrent.requests" : 1,
"action.type" : "index",
"flush.interval" : "12h"
},
"statsd": {
"host" : "localhost",
"prefix" : "kafka.river",
"port" : 8125,
"log.interval" : 10
}
}'
Integrating SolrCloud with Kafka - using flume
Flume is a reliable, highly available, distributed service for collecting, aggregating, and moving large amounts of log data into any data storage solution that you might use. Your ,data destination might be any of HDFS, Kafka, Hive, or any of the various sinks that Flume supports. You can also use Flume to transfer your data from one Kafka node to another Kafka node.
What Flume has is a source (where the data is being read from), a channel (through which data passes between the source and sink), and a sink (where the data is pushed to).
flume1.sources = kafka-source-1
flume1.channels = mem-channel-1
flume1.sinks = solr-sink-1
flume1.sources.kafka-source-1.type = org.apache.flume.source.kafka.KafkaSource
flume1.sources.kafka-source-1.zookeeperConnect = localhost:2181
flume1.sources.kafka-source-1.topic = srctopic
flume1.sources.kafka-source-1.batchSize = 100
flume1.sources.kafka-source-1.channels = mem-channel-1
flume1.channels.mem-channel-1.type = memory
flume1.sinks.solr-sink-1.channel = mem-channel-1
flume1.sinks.solr-sink-1.type = org.apache.flume.sink.solr.morphline.MorphlineSolrSink
flume1.sinks.solr-sink-1.batchSize = 100
flume1.sinks.solr-sink-1.batchDurationMillis = 1000
flume1.sinks.solr-sink-1.morphlineFile = /etc/flume-ng/conf/morphline.conf
flume1.sinks.solr-sink-1.morphlineId = morphline1
Next you need to run Flume using the configuration file created earlier.
> flume-ng agent --conf-file flume.conf --name flume1
I also faced same problem that you have.Solution is very simple.Create topics in kafka queue,Let say:
1) high_priority_queue
2) medium_priority_queue
3) low_priority_queue
Publish high priority message in high_priority_queue and medium priority message in medium_priority_queue.
Now you can create kafka consumer and open stream for all topic.
val props = new Properties()
props.put("group.id", groupId)
props.put("zookeeper.connect", zookeeperConnect)
val config = new ConsumerConfig(props)
val connector = Consumer.create(config)
val topicWithStreamCount = Map(
"high_priority_queue" -> 1,"medium_priority_queue" -> 1,"low_priority_queue" -> 1)
val streamsMap = connector.createMessageStreams(topicWithStreamCount)
//this is scala code
You get stream of each topic.Now you can first read high_priority topic if topic does not have any message then fallback on medium_priority_queue topic. if medium_priority_queue is empty then read low_priority queue.
http://docs.confluent.io/current/streams/concepts.html
A KTable is an abstraction of a changelog stream, where each data record represents an update. More precisely, the value in a data record is interpreted as an “UPDATE” of the last value for the same record key, if any (if a corresponding key doesn’t exist yet, the update will be considered an INSERT). Using the table analogy, a data record in a changelog stream is interpreted as an UPSERT aka INSERT/UPDATE because any existing row with the same key is overwritten. Also,
A KTable is an abstraction of a changelog stream, where each data record represents an update. More precisely, the value in a data record is interpreted as an “UPDATE” of the last value for the same record key, if any (if a corresponding key doesn’t exist yet, the update will be considered an INSERT). Using the table analogy, a data record in a changelog stream is interpreted as an UPSERT aka INSERT/UPDATE because any existing row with the same key is overwritten. Also,
null values are interpreted in a special way: a record with a null value represents a “DELETE” or tombstone for the record’s key.
Windowing operations are available in the Kafka Streams DSL. When working with windows, you can specify a retention period for the window. This retention period controls how long Kafka Streams will wait for out-of-order or late-arriving data records for a given window. If a record arrives after the retention period of a window has passed, the record is discarded and will not be processed in that window.
https://blog.codecentric.de/en/2017/02/crossing-streams-joins-apache-kafka/
There are two main abstractions in the Streams API. A KStream is a stream of key-value pairs – basically a close model of a Kafka topic. The records in a KStream either come directly from a topic or have gone through some kind of transformation – it has for example a filter-method that takes a predicate and returns another KStream that only contains those elements that satisfy the predicate. KStreams are stateless, but they allow for aggregation by turning them into the other core abstraction – KTable – which is often describe as “changelog stream”.
A KTable statefully holds the latest value for a given message key and reacts automatically to newly incoming messages.
A nice example is perhaps counting visits to a website by unique IP addresses. Let’s assume we have a Kafka topic containing messages of the following type: (key=IP, value=timestamp). A KStream contains all visits by all IPs, even if the IP is recurring. A count on such a KStream sums up all visits to a site including duplicates. A KTable on the other hand only contains the latest message and a count on the KTable represents the number of distinct IP addresses that visited the site.
A nice example is perhaps counting visits to a website by unique IP addresses. Let’s assume we have a Kafka topic containing messages of the following type: (key=IP, value=timestamp). A KStream contains all visits by all IPs, even if the IP is recurring. A count on such a KStream sums up all visits to a site including duplicates. A KTable on the other hand only contains the latest message and a count on the KTable represents the number of distinct IP addresses that visited the site.
KTables and KStreams can also be windowed. Regarding the example, this means we could add a time dimensions to our stateful operations. To enable windowing, Kafka 0.10 changed the Kafka message format to include a timestamp. This timestamp can either be CreateTime or AppendTime. CreateTime is set by the producer and can be be set manually or automatically. AppendTime is the time a message is appended to the log by the broker. Next up: joins.
// write to intermediate topic
locations.to(Serdes.String(), new LocationSerde(), "location_topic_aux");
// build KTable from intermediate topic
KTable<String, Location> table = builder.table("location_topic_aux", "store");This is the simplest approach with regard to the code. However, it has the disadvantages that (a) you need to manage an additional topic and that (b) it results in additional network traffic because data is written to and re-read from Kafka.
There is one alternative, using a "dummy-reduce":
KStreamBuilder builder = new KStreamBuilder();
KStream<String, Long> stream = ...; // some computation that creates the derived KStream
KTable<String, Long> table = stream.groupByKey().reduce(
new Reducer<Long>() {
@Override
public Long apply(Long aggValue, Long newValue) {
return newValue;
}
},
"dummy-aggregation-store");This approach is somewhat more complex with regard to the code compared to option 1 but has the advantage that (a) no manual topic management is required and (b) re-reading the data from Kafka is not necessary.
Overall, you need to decide by yourself, which approach you like better:
https://github.com/confluentinc/examples/issues/74In option 2, Kafka Streams will create an internal changelog topic to back up the KTable for fault tolerance. Thus, both approaches require some additional storage in Kafka and result in additional network traffic. Overall, it’s a trade-off between slightly more complex code in option 2 versus manual topic management in option 1.
joining two streams (of any kind) requires both to be partitioned on the join key using the same number of partitions. Thus, you would need to over partition the lower rate stream with the larger number of partitions from the high rate stream. This repartitioning will happen automatically in the next release of Kafka 0.10.1.0 (should be release this or next week); currently, you need to create a topic manually with the correct number of partitions before you start your Kafka Streams application and repartition before the join using
through(...).
Kafka Streams will keep all windows open in parallel -- windows are only deleted after their retention time passed. You can set retention time via
Windows#until(...). Keeping all windows open all the time has the advantage that late arriving out-of-order data can be processed easily. (see http://docs.confluent.io/current/streams/concepts.html#windowing)https://gist.github.com/timothyrenner/a99c86b2d6ed2c22c8703e8c7760af3aFor left joins, if the record in the right streams arrives after the corresponding record in the left stream => does it mean that those two could never be joined ?
KStreamBuilder builder = new KStreamBuilder();
KStream<String, Long> longs = builder.stream(
Serdes.String(), Serdes.Long(), "longs");
// In one ktable, count by key on a ten second tumbling window.
KTable<Windowed<String>, Long> longCounts =
longs.countByKey(TimeWindows.of("longCounts", 10000L),
Serdes.String());
// In another ktable, sum the values on a ten second tumbling window.
KTable<Windowed<String>, Long> longSums =
longs.reduceByKey((v1, v2) -> v1 + v2,
TimeWindows.of("longSums", 10000L),
Serdes.String(),
Serdes.Long());
// We can join the two tables to get the average.
KTable<Windowed<String>, Double> longAvgs =
longSums.join(longCounts,
(sum, count) ->
sum.doubleValue()/count.doubleValue());
// Finally, sink to the long-avgs topic.
longAvgs.toStream((wk, v) -> wk.key())
.to(Serdes.String(),
Serdes.Double(),
"long-avgs");
https://stackoverflow.com/questions/39586635/why-kafka-is-pull-based-instead-of-push-based
Because Kafka consumers pull data from the topic, different consumers can consume the messages at different pace. Kafka also supports different consumption model. You can have one consumer processing the messages at real-time and another consumer processing the messages in batch mode.
The other reason could be that kafka was designed not only for single consumer like hadoop. Different consumers can have diverse needs and capabilities.
Though pull based systems have some deficiencies like resources wasting due to polling regularly etc
- Pull is better in dealing with diversified consumers,
- Consumer can more effectively control the rate of consumption.
- Easier batch implementation . etc...
data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as Scribe and Apache Flume, follow a very different push-based path where data is pushed downstream. There are pros and cons to both approaches. However, a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately, in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems. Previous attempts at building systems in this fashion led us to go with a more traditional pull model.
Another advantage of a pull-based system is that it lends itself to aggressive batching of data sent to the consumer. A push-based system must choose to either send a request immediately or accumulate more data and then send it later without knowledge of whether the downstream consumer will be able to immediately process it. If tuned for low latency, this will result in sending a single message at a time only for the transfer to end up being buffered anyway, which is wasteful. A pull-based design fixes this as the consumer always pulls all available messages after its current position in the log (or up to some configurable max size). So one gets optimal batching without introducing unnecessary latency.
The deficiency of a naive pull-based system is that if the broker has no data the consumer may end up polling in a tight loop, effectively busy-waiting for data to arrive. To avoid this we have parameters in our pull request that allow the consumer request to block in a "long poll" waiting until data arrives (and optionally waiting until a given number of bytes is available to ensure large transfer sizes).
You could imagine other possible designs which would be only pull, end-to-end. The producer would locally write to a local log, and brokers would pull from that with consumers pulling from them. A similar type of "store-and-forward" producer is often proposed. This is intriguing but we felt not very suitable for our target use cases which have thousands of producers. Our experience running persistent data systems at scale led us to feel that involving thousands of disks in the system across many applications would not actually make things more reliable and would be a nightmare to operate. And in practice we have found that we can run a pipeline with strong SLAs at large scale without a need for producer persistence.
Our topic is divided into a set of totally ordered partitions, each of which is consumed by exactly one consumer within each subscribing consumer group at any given time. This means that the position of a consumer in each partition is just a single integer, the offset of the next message to consume. This makes the state about what has been consumed very small, just one number for each partition. This state can be periodically checkpointed. This makes the equivalent of message acknowledgements very cheap.
[读文档] Kafka的一点笔记
在职跳槽,学习系统设计,读点论文和文档,自己记点笔记。只选取了一些我认为可能对面试有用的知识点和可以在系统设计题复用的component。完全不涉及实战经验,配置,具体实现和调优等等。
previous post:
Amazon Dynamo笔记:https://www.1point3acres.com/bbs ... &extra=page%3D1
==========
参考:http://orchome.com/295
Kafka,消息队列中以吞吐量著称,功能上则相对简单,比较适合数据量很大,处理不复杂,也能容忍一定数据丢失的情况。如网站流量追踪,日志聚合,事件采集等等。
基本功能:
Producer针对topic发送消息,每个Topic有多个partition,分布在各个Broker(机器)上。
Consumer Group包含多个Consumer,Group可以订阅Topic,对每一个topic,他的每个partition中的消息会发送到Group中的一个特定Consumer上,不会出现一个partition被Group中多个Consumer接收的情况。
当所有Consumer都在一个group:每个消息只会Consume一次
当所有Consumer各自在一个group:pubsub模式,每个消息会发送给所在topic的所有订阅consumer。
消息都直接持久化在磁盘上,可以适用于both离线操作或在线流处理。
消费者:Pull from Broker:消费者采用pull比较常见,因为如果broker push不容易考虑消费者的能力,有可能会拒绝服务。pull的问题是如果暂时没有数据会轮询,这时我们可以用long pull。有数据的时候也可以用long pull,积累一定量以后一起返回。Consumer metadata:由消费者自己保持和控制,而不是broker。这样的劣势是broker没法通过观察是否所有消费者都已经消费消息来决定是否可以删除,但省去了很多track message status的麻烦(new,sent,acked),也不会出现消费者应答失败而重复发送(但会有其他情况导致发送多次)。同时broker改用ttl决定消息是否删除,不管是否有被消费。另一个优势是消费者可以自行决定回到之前的position重新消费某些消息。
生产者:
客户端控制发送到哪个partition,可以随机,也可以指定partition method,比如根据user id进行partition,同一个user的数据就都在一个partition并保证有序。
消息传递保障:
producer端:
最少一次:如果producer发送失败(没有得到保存到n个replica的应答),则重新发送
刚好一次:在最少一次的基础上,对每个producer有一个ID和序列号,针对他们进行去重。 以上两种都会降低吞吐量,来保证数据不丢失。
最多一次:只发送一次,不管应答,快速,适用于能够容忍一定数据丢失的场景。
consumer端:
最少一次:先读数据,处理数据,再commit offset
最多一次:读数据,commit offset,再来处理
刚好一次:利用消息的primary key来去重。
replica:
每一个分区可以存在多个replica分布在不同broker上,其中一个leader处理所有读写,follower只负责备份和恢复。
利用zookeeper monitor failover。Producer可以选择需要得到多少replica的ack才认为写入成功。
http://orchome.com/295
Kafka的使用场景
在职跳槽,学习系统设计,读点论文和文档,自己记点笔记。只选取了一些我认为可能对面试有用的知识点和可以在系统设计题复用的component。完全不涉及实战经验,配置,具体实现和调优等等。
previous post:
Amazon Dynamo笔记:https://www.1point3acres.com/bbs ... &extra=page%3D1
==========
参考:http://orchome.com/295
Kafka,消息队列中以吞吐量著称,功能上则相对简单,比较适合数据量很大,处理不复杂,也能容忍一定数据丢失的情况。如网站流量追踪,日志聚合,事件采集等等。
基本功能:
Producer针对topic发送消息,每个Topic有多个partition,分布在各个Broker(机器)上。
Consumer Group包含多个Consumer,Group可以订阅Topic,对每一个topic,他的每个partition中的消息会发送到Group中的一个特定Consumer上,不会出现一个partition被Group中多个Consumer接收的情况。
当所有Consumer都在一个group:每个消息只会Consume一次
当所有Consumer各自在一个group:pubsub模式,每个消息会发送给所在topic的所有订阅consumer。
消息都直接持久化在磁盘上,可以适用于both离线操作或在线流处理。
消费者:Pull from Broker:消费者采用pull比较常见,因为如果broker push不容易考虑消费者的能力,有可能会拒绝服务。pull的问题是如果暂时没有数据会轮询,这时我们可以用long pull。有数据的时候也可以用long pull,积累一定量以后一起返回。Consumer metadata:由消费者自己保持和控制,而不是broker。这样的劣势是broker没法通过观察是否所有消费者都已经消费消息来决定是否可以删除,但省去了很多track message status的麻烦(new,sent,acked),也不会出现消费者应答失败而重复发送(但会有其他情况导致发送多次)。同时broker改用ttl决定消息是否删除,不管是否有被消费。另一个优势是消费者可以自行决定回到之前的position重新消费某些消息。
生产者:
客户端控制发送到哪个partition,可以随机,也可以指定partition method,比如根据user id进行partition,同一个user的数据就都在一个partition并保证有序。
消息传递保障:
producer端:
最少一次:如果producer发送失败(没有得到保存到n个replica的应答),则重新发送
刚好一次:在最少一次的基础上,对每个producer有一个ID和序列号,针对他们进行去重。 以上两种都会降低吞吐量,来保证数据不丢失。
最多一次:只发送一次,不管应答,快速,适用于能够容忍一定数据丢失的场景。
consumer端:
最少一次:先读数据,处理数据,再commit offset
最多一次:读数据,commit offset,再来处理
刚好一次:利用消息的primary key来去重。
replica:
每一个分区可以存在多个replica分布在不同broker上,其中一个leader处理所有读写,follower只负责备份和恢复。
利用zookeeper monitor failover。Producer可以选择需要得到多少replica的ack才认为写入成功。
http://orchome.com/295
Kafka的使用场景
https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
https://puncsky.com/hacking-the-software-engineer-interview#designing-a-distributed-logging-system
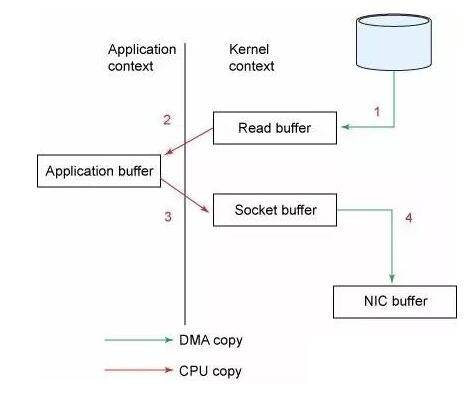
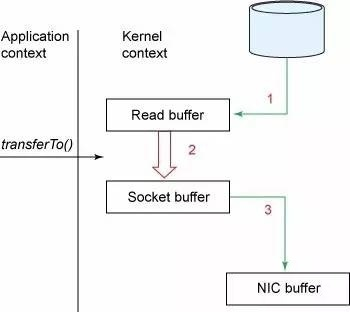
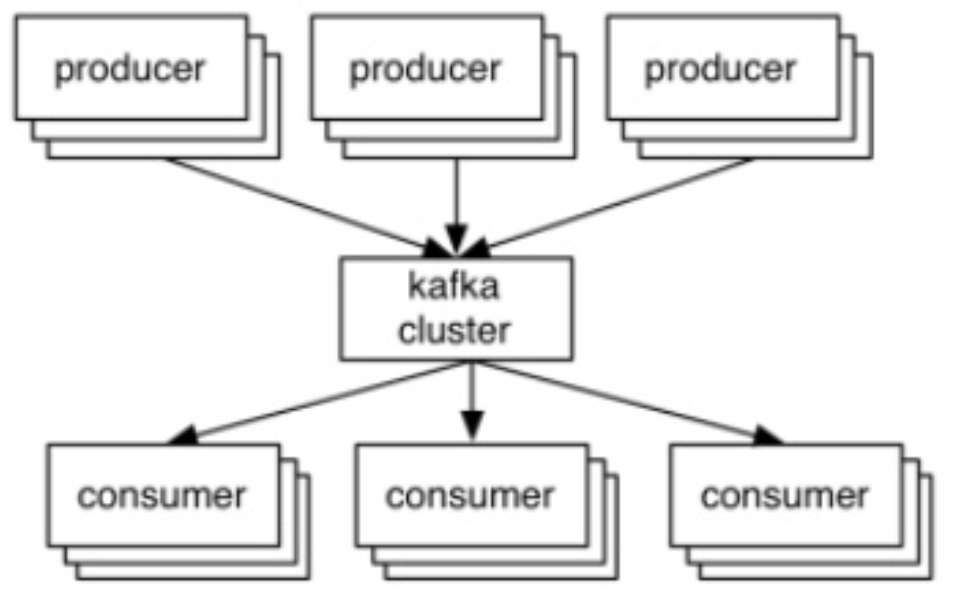
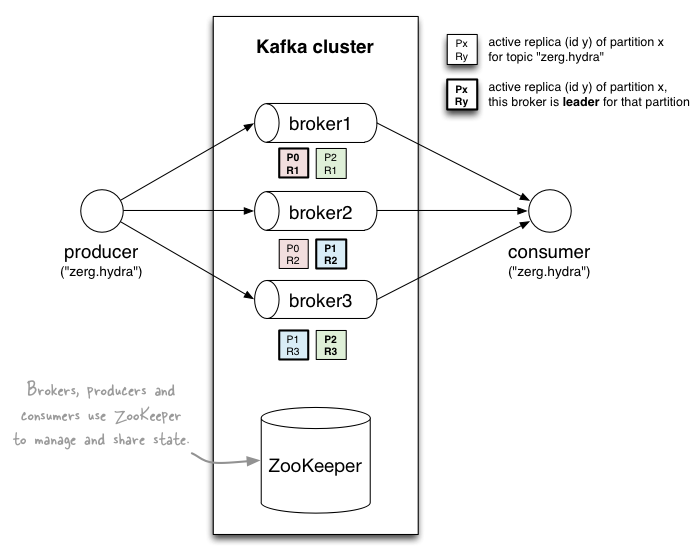
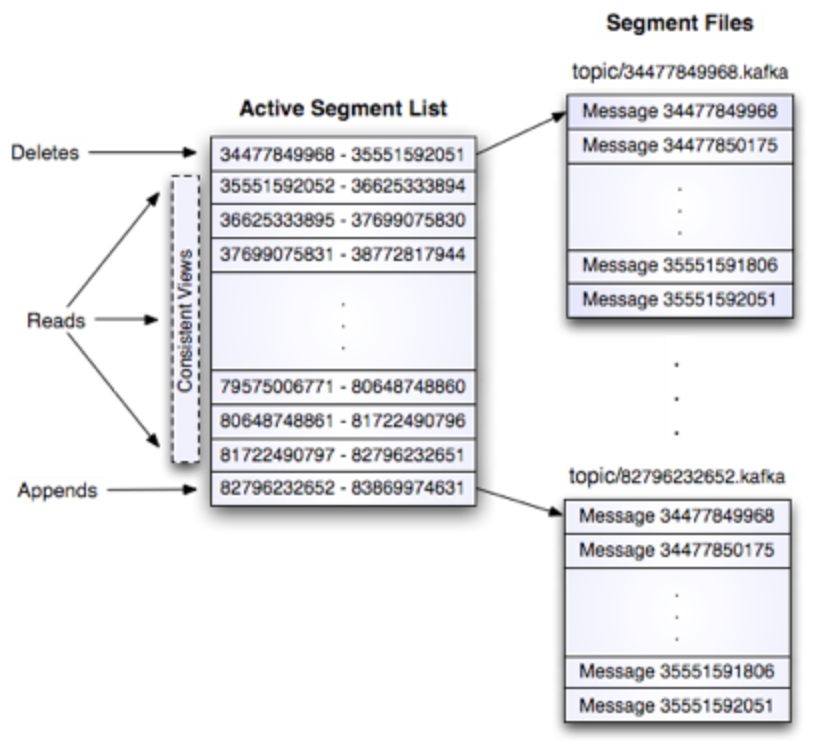
https://puncsky.com/hacking-the-software-engineer-interview#designing-a-distributed-logging-system
Apache Kafka is a distributed streaming platform.
Why use Apache Kafka?
Its abstraction is a queue and it features
- a distributed pub-sub messaging system that resolves N^2 relationships to N. Publishers and subscribers can operate at their own rates.
- super fast with zero-copy technology
- support fault-tolerant data persistence
It can be applied to
- logging by topics
- messaging system
- geo-replication
- stream processing
Why is Kafka so fast?
Kafka is using zero copy in which that CPU does not perform the task of copying data from one memory area to another.
Without zero copy:
With zero copy:
Architecture
Looking from outside, producers write to brokers, and consumers read from brokers.
Data is stored in topics and split into partitions which are replicated.
- Producer publishes messages to a specific topic.
- Write to in-memory buffer first and flush to disk.
- append-only sequence write for fast write.
- Available to read after write to disks.
- Consumer pulls messages from a specific topic.
- use an “offset pointer” (offset as seqId) to track/control its only read progress.
- A topic consists of partitions, load balance, partition (= ordered + immutable seq of msg that is continually appended to)
- Partitions determine max consumer (group) parallelism. One consumer can read from only one partition at the same time.
How to serialize data? Avro
What is its network protocol? TCP
What is a partition’s storage layout? O(1) disk read
How to tolerate fault?
In-sync replica (ISR) protocol. It tolerates (numReplicas - 1) dead brokers. Every partition has one leader and one or more followers.
Total Replicas = ISRs + out-of-sync replicas- ISR is the set of replicas that are alive and have fully caught up with the leader (note that the leader is always in ISR).
- When a new message is published, the leader waits until it reaches all replicas in the ISR before committing the message.
- If a follower replica fails, it will be dropped out of the ISR and the leader then continues to commit new messages with fewer replicas in the ISR. Notice that now, the system is running in an under replicated mode. If a leader fails, an ISR is picked to be a new leader.
- Out-of-sync replica keeps pulling message from the leader. Once catches up with the leader, it will be added back to the ISR.
Is Kafka an AP or CP system in CAP theorem?
Jun Rao says it is CA, because “Our goal was to support replication in a Kafka cluster within a single datacenter, where network partitioning is rare, so our design focuses on maintaining highly available and strongly consistent replicas.”
However, it actually depends on the configuration.
- Out of the box with default config (min.insync.replicas=1, default.replication.factor=1) you are getting AP system (at-most-once).
- If you want to achieve CP, you may set min.insync.replicas=2 and topic replication factor of 3 - then producing a message with acks=all will guarantee CP setup (at-least-once), but (as expected) will block in cases when not enough replicas (<2) are available for particular topic/partition pair.