http://stackoverflow.com/questions/7072924/what-is-the-design-architecture-behind-facebooks-status-update-mechanism
What’s the job?
▪ Fetch recent activity from all your friends
▪ Gather it in a central place
▪ Group into stories
▪ Rank stories by relevance
▪ Send back results
Moving content to your friends
Megafeed
Broadcast writes to your friends
Multifeed
Multi-fetch and aggregate stories at read time
Chose Multifeed
▪ Write amplification makes the storage needs expensive in Megafeed
▪ Developing with read-time aggregation is flexible
▪ Memory and network easier to engineer around
▪ Fan-out reads can be bounded. Writes, often cannot
Challenges for another day
▪ Multi-region
▪ Pushing new code
▪ Ranking
▪ Failure/Disaster Recovery
Today: Focus on Leaf Nodes
▪ In-memory (mostly) databases
▪ Do ~40 requests per feed query
▪ About 50% of the total LOC
Storing Feed
Leaf node indexes
▪ Must store a number of users on each leaf
▪ Once we find a user, we want to scan his/her activity in time order
▪ Want to have an easy way of adding new activity without locking
▪ Most natural data structure is a hashtable to a linked list
First Version
▪ Use basic STL containers
▪ stl::unordered_map<int64_t, list<action*> >
▪ Lots of overhead
▪ Storage overhead due to internal structures, alignment
▪ Tons of pointer dereference, cache invalidation
▪ Memory fragmentation, so CPU usage trends upward
▪ Memory leakage leading to process restarts
A Few Tweaks
▪ Boost:multi_index_container
▪ JEMalloc (c/o) Jason Evans
▪ Slowed memory leakage quite a bit
▪ Boost library performs basically as well as stl with more syntactic
niceness
Memory Pools
▪ Allocate a huge array once (directly via malloc)
▪ Round robin insert actions into it
▪ Fixes memory leaks outside of index structure
▪ Still use stl for index structures
▪ Can “scan” for spaces, use more complicated than round robin
allocator (e.g. keep at least 2 actions per user)
▪ Requires fixed size actions
Moore’s Law to the rescue?
▪ We’re limited on total data size by how much data can be “local”
▪ (i.e. within a single rack)
▪ Memory footprint of new servers almost doubles every year
▪ But… total data and query volume triples each year
▪ User growth
▪ Engagement/user growth
▪ New features, Zuck’s Law
▪ Increasing focus on “needy” users. Few friends, less recent activity
Adding Persistent Storage
▪ Flash SSD technology has continuously matured
▪ Read latency and throughput about 10% of main RAM
▪ Sizes of 1TB or more
▪ Persistent!
▪ How do we incorporate this into our design?
Starting From Scratch
Linux Internals
▪ Under the hood, all memory is managed through the mapping table
▪ Not all pages are mapped to physical RAM
▪ Can be unmapped to the process (SEGV)
▪ Can be unassigned to any physical pages (page fault)
▪ Can be mapped to a page that resides on disk (swap file)
▪ Can be mapped to another file (via mmap() )
Early Thoughts
▪ Linux provides a mechanism for mapping data on disk to RAM
▪ Will use it’s own structures for caching pages, syncing writes
▪ What if we wrote everything on persistent flash and mmapped the
whole thing?
▪ Sounds ideal – let the kernel do the work of picking pages to keep in
RAM, when to flush changes to disk
▪ If the process crashes, restart and mmap yourself back to life
In Reality…
▪ Syncs written pages aggressively
▪ Optimized for spinning disks, not flash
▪ Avoids concurrency
▪ Optimistic read-ahead
▪ Prefers sequential writes
▪ When the kernel does something, it tends to grab locks. End up with
unresponsive servers during syncs
▪ But.. mmap, madvise etc. provide enough flexibility to manage this
ourselves
Next Generation
▪ Mmap large chunks (~1GB) of address space
▪ Some are volatile and writable, others are persistent and read only
▪ Do your own syncing of a volatile chunk to persistent chunk
▪ Keep a separate index into the first action by a user (in a volatile
chunk) and linked list down the rest of the way
▪ Write variable sized actions if you want
▪ When you run out of space, just unmap/delete old data, and set a
global limit so you know not to follow pointers off the end
We find the Multifeed approach to be more flexible, manageable
▪ Feed is not that much code
▪ By using thrift, SMC, other FB infra we have very little glue to write
▪ As a result, we’d rewrite things even without immediate need
▪ Directly using the kernel helps a lot. Good code in there.
▪ We wouldn’t necessarily have written from scratch today
▪ Redis
▪ LevelDB
Facebook News Feed Social data at scale
http://itsumomono.blogspot.com/2015/07/news-feed-approaches-push-vs-pull.html







read more
news feed 整个流程(twitter ,facebook类似但不一样,不一样在哪里),是用
pull还是push,是为每个用户保存一个queue吗?new year时high traffic会出现哪些
特殊情况,怎么解决?
https://code.fb.com/production-engineering/serving-facebook-multifeed-efficiency-performance-gains-through-redesign/
https://ayende.com/blog/161537/querying-your-way-to-madness-the-facebook-timeline
Here is a great presentation that answers your question. In short:
- A particular server ("leaf") stores all feed items for a particular user. So data for each of your friends is stored entirely at a specific destination.
- When you want to view your news feed, one of the aggregator servers sends request to all the leaf servers for your friends and ranks the results. The aggregator knows which servers to send requests to based on the userid of each friend.
This is terribly simplified, of course. This only works because all of it is memcached, the system is designed to minimize latency, some ranking is done at the leaf server that contains the friend's feed items, etc.
You really don't want to be hitting the database for any of this to work at a reasonable speed. FB use MySql mostly as a key-value store; JOINing tables is just impossible at their scale. Then they put memcache servers in front of the databases and application servers.
Having said that, don't worry about scaling problems until you have them (unless, of course, you are worrying about them for the fun of it.) On day one, scaling is the least of your problems.
Facebook News Feed Social data at scaleWhat’s the job?
▪ Fetch recent activity from all your friends
▪ Gather it in a central place
▪ Group into stories
▪ Rank stories by relevance
▪ Send back results
Moving content to your friends
Megafeed
Broadcast writes to your friends
Multifeed
Multi-fetch and aggregate stories at read time
Chose Multifeed
▪ Write amplification makes the storage needs expensive in Megafeed
▪ Developing with read-time aggregation is flexible
▪ Memory and network easier to engineer around
▪ Fan-out reads can be bounded. Writes, often cannot
Challenges for another day
▪ Multi-region
▪ Pushing new code
▪ Ranking
▪ Failure/Disaster Recovery
Today: Focus on Leaf Nodes
▪ In-memory (mostly) databases
▪ Do ~40 requests per feed query
▪ About 50% of the total LOC
Storing Feed
Leaf node indexes
▪ Must store a number of users on each leaf
▪ Once we find a user, we want to scan his/her activity in time order
▪ Want to have an easy way of adding new activity without locking
▪ Most natural data structure is a hashtable to a linked list
First Version
▪ Use basic STL containers
▪ stl::unordered_map<int64_t, list<action*> >
▪ Lots of overhead
▪ Storage overhead due to internal structures, alignment
▪ Tons of pointer dereference, cache invalidation
▪ Memory fragmentation, so CPU usage trends upward
▪ Memory leakage leading to process restarts
A Few Tweaks
▪ Boost:multi_index_container
▪ JEMalloc (c/o) Jason Evans
▪ Slowed memory leakage quite a bit
▪ Boost library performs basically as well as stl with more syntactic
niceness
Memory Pools
▪ Allocate a huge array once (directly via malloc)
▪ Round robin insert actions into it
▪ Fixes memory leaks outside of index structure
▪ Still use stl for index structures
▪ Can “scan” for spaces, use more complicated than round robin
allocator (e.g. keep at least 2 actions per user)
▪ Requires fixed size actions
Moore’s Law to the rescue?
▪ We’re limited on total data size by how much data can be “local”
▪ (i.e. within a single rack)
▪ Memory footprint of new servers almost doubles every year
▪ But… total data and query volume triples each year
▪ User growth
▪ Engagement/user growth
▪ New features, Zuck’s Law
▪ Increasing focus on “needy” users. Few friends, less recent activity
Adding Persistent Storage
▪ Flash SSD technology has continuously matured
▪ Read latency and throughput about 10% of main RAM
▪ Sizes of 1TB or more
▪ Persistent!
▪ How do we incorporate this into our design?
Starting From Scratch
Linux Internals
▪ Under the hood, all memory is managed through the mapping table
▪ Not all pages are mapped to physical RAM
▪ Can be unmapped to the process (SEGV)
▪ Can be unassigned to any physical pages (page fault)
▪ Can be mapped to a page that resides on disk (swap file)
▪ Can be mapped to another file (via mmap() )
Early Thoughts
▪ Linux provides a mechanism for mapping data on disk to RAM
▪ Will use it’s own structures for caching pages, syncing writes
▪ What if we wrote everything on persistent flash and mmapped the
whole thing?
▪ Sounds ideal – let the kernel do the work of picking pages to keep in
RAM, when to flush changes to disk
▪ If the process crashes, restart and mmap yourself back to life
In Reality…
▪ Syncs written pages aggressively
▪ Optimized for spinning disks, not flash
▪ Avoids concurrency
▪ Optimistic read-ahead
▪ Prefers sequential writes
▪ When the kernel does something, it tends to grab locks. End up with
unresponsive servers during syncs
▪ But.. mmap, madvise etc. provide enough flexibility to manage this
ourselves
Next Generation
▪ Mmap large chunks (~1GB) of address space
▪ Some are volatile and writable, others are persistent and read only
▪ Do your own syncing of a volatile chunk to persistent chunk
▪ Keep a separate index into the first action by a user (in a volatile
chunk) and linked list down the rest of the way
▪ Write variable sized actions if you want
▪ When you run out of space, just unmap/delete old data, and set a
global limit so you know not to follow pointers off the end
We find the Multifeed approach to be more flexible, manageable
▪ Feed is not that much code
▪ By using thrift, SMC, other FB infra we have very little glue to write
▪ As a result, we’d rewrite things even without immediate need
▪ Directly using the kernel helps a lot. Good code in there.
▪ We wouldn’t necessarily have written from scratch today
▪ Redis
▪ LevelDB
Facebook News Feed Social data at scale
http://itsumomono.blogspot.com/2015/07/news-feed-approaches-push-vs-pull.html







read more
news feed 整个流程(twitter ,facebook类似但不一样,不一样在哪里),是用
pull还是push,是为每个用户保存一个queue吗?new year时high traffic会出现哪些
特殊情况,怎么解决?
https://code.fb.com/production-engineering/serving-facebook-multifeed-efficiency-performance-gains-through-redesign/
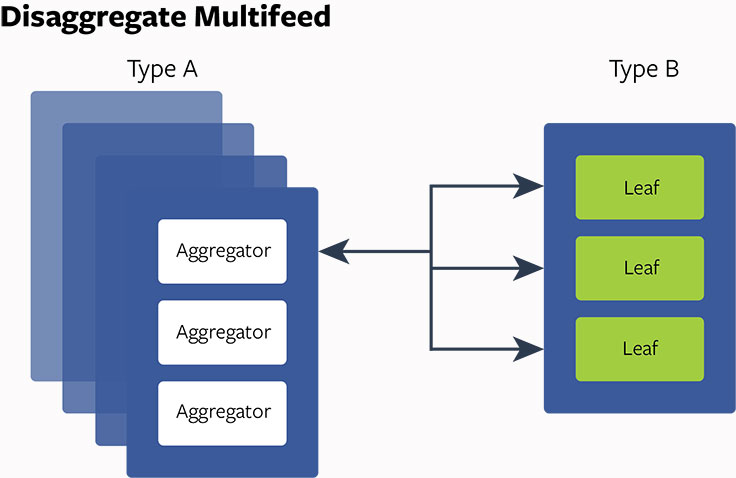
- Aggregator: The query engine that accepts user queries and retrieves News Feed info from backend storage. It also does News Feed aggregation, ranking and filtering, and returns results to clients. The aggregator is CPU intensive but not memory intensive.
- Leaf: The distributed storage layer that indexes most recent News Feed actions and stores them in memory. Usually 20 leaf servers work as a group and make up one full replica containing the index data for all the users. Each leaf serves data retrieval requests coming from aggregators. Each leaf is memory intensive but not CPU intensive.
- Tailer: The input data pipelines directs user actions and feedback into a leaf storage layer in real time.
- Persistent storage: The raw logs and snapshots for reloading a leaf from scratch.
In the past, each Multifeed Aggregator was paired with one leaf, and they co-located on a shared server. Twenty such servers were grouped together, working as one replica and containing users’ News Feed data. Each replica had 20 aggregators and 20 leaves. Upon receiving a request, each aggregator fanned out the request to all the leaves to fetch data, rank and filter data, and return results to clients. We gave the Multifeed server high CPU power and large memory storage. Everything worked with this design, but it had some issues:
- Reliability: It was not uncommon for an aggregator to get a heavy request from a user with a lot of friends, leading to a sudden spike in CPU usage. If the spike is large enough, as the aggregator consumed the CPU, the leaf running on the same server could become unstable. Any aggregator (and its corresponding server) that interacted with the leaf could also become unstable, leading to a cascade of problems within the replica.
- Hardware scalability: We had many replicas in our infrastructure. The capacity was planned based on the CPU demand to serve user requests. We added hundreds of replicas to accommodate the traffic growth over time. Along the way, memory was added, coupled along with each CPU. It became clear that there was memory over-build since it was not the resource needed when more replicas were added.
- Resource waste: Each tailer forwards user actions and feedback to a leaf server. It is the real-time data pipeline for Multifeed. The leaf server spends 10 percent of CPU to execute these real-time updates. The number of replicas we have means we are using unnecessary our CPU resources just keeping our leaf storage up to date.
- Performance: Aggregator and leaf have very different CPU characteristics. Aggregator threads are competing with leaf threads for CPU cache, which leads to cache conflict and resource contention. There are also higher context switches because of many threads running.
With the issues and problems identified, the question then became: How can we build the hardware and change the software product architecture to address these issues? After in-depth investigation and analysis, we decided to implement the disaggregated hardware/software design approach for Multifeed. First, we designed some servers to have intensive CPU capacity (server type A) and some to have large memory storage (server type B). Then we put aggregator on server type A and leaf on server type B, which gave us the ability to optimize the thread config, reduce context switches, enable better NUMA balancing, and also adjust the ratio between aggregators and leaves.
https://rockset.com/blog/aggregator-leaf-tailer-an-architecture-for-live-analytics-on-event-streams/
Aggregator Leaf Tailer (ALT) is the data architecture favored by web-scale companies, like Facebook, LinkedIn, and Google, for its efficiency and scalability.