How Sharding Works
Sharding is a method of splitting and storing a single logical dataset in multiple databases.
Mature solutions likeYoutube’s Vitess and Tumblr’s Jetpants can automate most operational tasks.
However, a particular cross-partition query may be required frequently and efficiently. In this case, data needs to be stored in multiple partitions to support efficient reads. For example, chat messages between two users may be stored twice — partitioned by both senders and recipients. All messages sent or received by a given user are stored in a single partition. In general, many-to-many relationships between partitions may need to be duplicated.
Entity groups can be implemented either algorithmically or dynamically. They are usually implemented dynamically since the total size per group can vary greatly. The same caveats for updating locators and moving data around applies here. Instead of individual tables, an entire entity group needs to be moved together.
Other than sharded RDBMS solutions, Google Megastore is an example of such a system. Megastore is publicly exposed via Google App Engine’s Datastore API.
Google BigTable popularized column-oriented databases amongst the public. Apache HBase is a BigTable-like database implemented on top of Hadoop ecosystem. Apache Cassandra previously described itself as a column database — entries were stored in column families with row and column keys. CQL3, the latest API for Cassandra, presents a flattened data model — (partition key, column key) is simply a composite primary key. Amazon’s Dynamo popularized highly available databases. Amazon DynamoDB is a platform-as-a-service offering of Dynamo. DynamoDB uses (hash key, range key) as its primary key.

Sharding is a method of splitting and storing a single logical dataset in multiple databases.
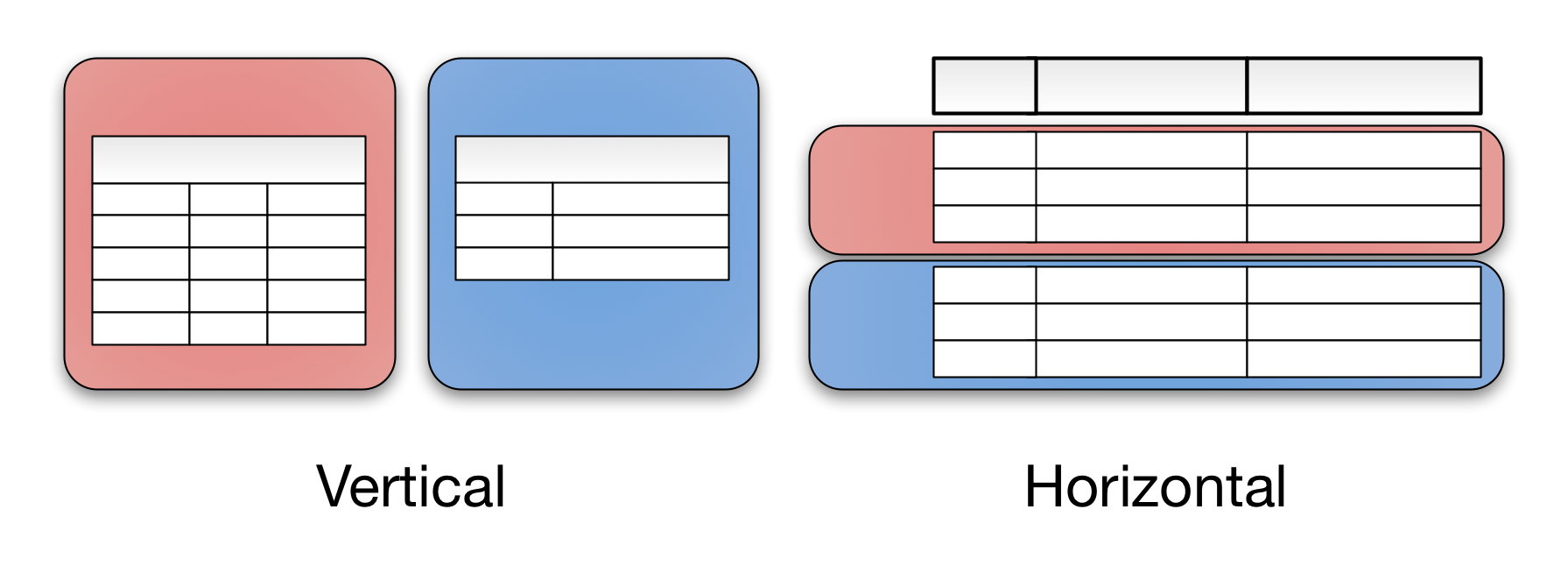
Sharding is also referred as horizontal partitioning. The distinction ofhorizontal vs vertical comes from the traditional tabular view of a database. A database can be split vertically — storing different tables & columns in a separate database, or horizontally — storing rows of a same table in multiple database nodes.
Vertical partitioning is very domain specific. You draw a logical split within your application data, storing them in different databases. It is almost always implemented at the application level — a piece of code routing reads and writes to a designated database.
Operations may need to search through many databases to find the requested data. These are called cross-partition operations and they tend to be inefficient. Hotspots are another common problem — having uneven distribution of data and operations. Hotspots largely counteract the benefits of sharding.
Before you start: you may not need to shard!
Get a more expensive machine.
If your application is bound by read performance, you can add caches or database replicas. They provide additional read capacity without heavily modifying your application.
Vertically partition by functionality. Binary blobs tend to occupy large amounts of space and are isolated within your application. Storing files in S3 can reduce storage burden. Other functionalities such as full text search, tagging, and analytics are best done by separate databases.
Not everything may need to be sharded. Often times, only few tables occupy a majority of the disk space. Very little is gained by sharding small tables with hundreds of rows. Focus on the large tables.
Shard or Partition Key is a portion of primary key which determines how data should be distributed. A partition key allows you to retrieve and modify data efficiently by routing operations to the correct database. Entries with the same partition key are stored in the same node. A logical shard is a collection of data sharing the same partition key. A database node, sometimes referred as a physical shard, contains multiple logical shards.
Case 1 — Algorithmic Sharding - hash(key) % NUM_DB
In algorithmic sharding, the client can determine a given partition’s database without any help. In dynamic sharding, a separate locator service tracks the partitions amongst the nodes.
Resharding data can be challenging. It requires updating the sharding function and moving data around the cluster. Doing both at the same time while maintaining consistency and availability is hard. Clever choice of sharding function can reduce the amount of transferred data. Consistent Hashing is such an algorithm.
Memcached is not sharded on its own, but expects client libraries to distribute data within a cluster. Such logic is fairly easy to implement at the application level.
Case 2— Dynamic Sharding
In dynamic sharding, an external locator service determines the location of entries.
In the example of range-based partition keys, range queries are efficient because the locator service reduces the number of candidate databases. Queries without a partition key will need to search all databases.
HDFS uses a Name Node to store filesystem metadata. Unfortunately, the name node is a single point of failure in HDFS. Apache HBase splits row keys into ranges. The range server is responsible for storing multiple regions. Region information is stored in Zookeeper to ensure consistency and redundancy. In MongoDB, the ConfigServer stores the sharding information, and mongos performs the query routing. ConfigServer uses synchronous replication to ensure consistency. When a config server loses redundancy, it goes into read-only mode for safety. Normal database operations are unaffected, but shards cannot be created or moved.
Case 3 — Entity Groups
The concept of entity groups is very simple. Store related entities in the same partition to provide additional capabilities within a single partition. Specifically:
Queries within a single physical shard are efficient.
Stronger consistency semantics can be achieved within a shard.
This is a popular approach to shard a relational database.
However, a particular cross-partition query may be required frequently and efficiently. In this case, data needs to be stored in multiple partitions to support efficient reads. For example, chat messages between two users may be stored twice — partitioned by both senders and recipients. All messages sent or received by a given user are stored in a single partition. In general, many-to-many relationships between partitions may need to be duplicated.
Entity groups can be implemented either algorithmically or dynamically. They are usually implemented dynamically since the total size per group can vary greatly. The same caveats for updating locators and moving data around applies here. Instead of individual tables, an entire entity group needs to be moved together.
Other than sharded RDBMS solutions, Google Megastore is an example of such a system. Megastore is publicly exposed via Google App Engine’s Datastore API.
Case 4 — Hierarchical keys & Column-Oriented Databases
Column-oriented databases are an extension of key-value stores. They add expressiveness of entity groups with a hierarchical primary key. A primary key is composed of a pair (row key, column key). Entries with the same partition key are stored together. Range queries on columns limited to a single partition are efficient. That’s why a column key is referred as a range key in DynamoDB.
Google BigTable popularized column-oriented databases amongst the public. Apache HBase is a BigTable-like database implemented on top of Hadoop ecosystem. Apache Cassandra previously described itself as a column database — entries were stored in column families with row and column keys. CQL3, the latest API for Cassandra, presents a flattened data model — (partition key, column key) is simply a composite primary key. Amazon’s Dynamo popularized highly available databases. Amazon DynamoDB is a platform-as-a-service offering of Dynamo. DynamoDB uses (hash key, range key) as its primary key.

Whereas with the second example, we will have:
session
.Include<Image>(x=>x.UserId)
.Include(x=>x.CommentsId)
.Load("images/1");