http://blog.gainlo.co/index.php/2016/03/29/design-news-feed-system-part-1-system-design-interview-questions/
In fact, there are a bunch of interesting details about news feed like how to rank feeds, how to optimize publishing etc.
http://www.chepoo.com/feed-architecture-design-analysis.html
发布的时候push给热点用户,再把feed存入热点cache当没收到push的用户登陆后可以到cache里快速pull出相关feed;用户可以先收到push的新feed消息,当想看以前的消息时再去pull出相关的feed。
四、 有效组织feed信息
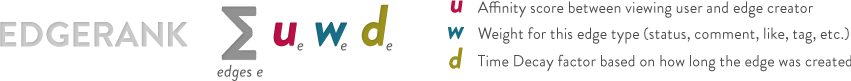
Affinity is a one-way relationship between a User and an Edge. It could be understood as how close of a “relationship” a Brand and a Fan may have. Affinity is built by repeat interactions with a Brand’s Edges.
Actions such as Commenting, Liking, Sharing, Clicking, and even Messaging can influence a User’s Affinity.
Affinity can be based on number of the interactions with your friend, weight of each interaction and time since your last interaction.
Weight is a value system created by Facebook to increase/decrease the value of certain actions within Facebook. Commenting is more involved and therefore deemed more valuable than a Like. In the weighting system, Comments would have a higher value than a Like. In this system all Edges are assigned a value chosen by Facebook. As a general rule, it’s best to assume Edges that take the most time to accomplish tend to weigh more.
Time Decay refers to how long the Edge has been alive; the older it is the less valuable it is. Time Decay is the easiest of the variables to understand. Mathematically it is understood as 1/(Time Since Action). As an Edge ages, it loses value. This helps keep the News Feed fresh with interesting new content, as opposed to lingering old content.
Next is storing this activity.
Ask your interviewer about the use cases of the application.
Our schema would be like this:
id
user_id // user who created the activity
data //may be json object with metadata
edge_rank //calculated using above algo
activity_type // whether its a photo, status, video
source_id //the record that the activity is related to.
created_date //timestamp
We can index on (user_id, created_date) and then perform basic queries.
Publishing the feed
“Push” Model/Fan-out-on-write
As the activity is created publish it to all the recipients. One way is maintain a pub sub model. In which the recepients will be subscribed to the mesaaging queue. Once the activity is generated , its pushed into the queue and the subscribers gets a notification.
2. “Pull” Model/or Fan-out-on-load
This method involves keeping all recent activity data in memory and pulling in (or fanning out) that data at the time a user loads their home page.
Constraints
The push model will start breaking if we have to push the messages to a large audience. Lets say Sachin Tendulkar will have a lot of fans. If this fails there will be a backlog of feeds. An alternative strategy is using different priorities for the fan-out tasks. You simply mark fan-outs to active users as high priority and fan-outs to inactive users as low priority.
The downside of pull model is that the failure scenario is more catastrophic — instead of just delaying updates, you may potentially fail to generate a user’s feed. One workaround is to have a fallback method , e.g get the updates of 10 friends only.
You must be thinking why we chose denormalized activity rather than normalized. So it will also depend on the backend that you are using. The feed with the activities by people you follow either contains the ids of the activities (normalized) or the full activity (denormalized).
Storing id alone will reduce memory usage but add an additional overhead of getting the data based on the id. So if you are building a system in which feed will go to many users , the data will be copied many times and hence memory can be insufficient.
With Redis you need to be careful about memory usage. Cassandra on the other hand has plenty of storage space, but is quite hard to use if you normalize your data.
Interviewer may ask the usage of Redis and Cassandra.
Redis is read-optimized and stores all data in memory. Cassandra is write-optimized data store.
So with redis the following approach can be used:
1.Create your MySQL activity record
2. For each friend of the user who created the activity, push the ID onto their activity list in Redis.
A hybrid approach of pull and push model can also be used.
TODO: http://m.oschina.net/blog/222877
http://www.quora.com/What-are-best-practices-for-building-something-like-a-News-Feed
http://stackoverflow.com/questions/1443960/how-to-implement-the-activity-stream-in-a-social-network
http://www.quora.com/Activity-Streams/What-are-the-scaling-issues-to-keep-in-mind-while-developing-a-social-network-feed
http://www.slideshare.net/nkallen/q-con-3770885/8-Original_Implementationid_userid_text_createdat20
Twitter materializes (in memory) the items in each of the followers' inboxes
http://www.infoq.com/presentations/Big-Data-in-Real-Time-at-Twitter
RELATED: http://massivetechinterview.blogspot.com/2015/12/twitter-architecture-part-2.html
Facebook aggregates the home feed on demand (from in-memory stores called "leaf servers");
http://www.infoq.com/presentations/Scale-at-Facebook
http://highscalability.com/blog/2012/1/17/paper-feeding-frenzy-selectively-materializing-users-event-f.html
https://www.quora.com/Software-Engineering-Best-Practices/What-are-the-best-practices-for-building-something-like-a-News-Feed
* Combination of push (events are pushed to materialized per consumer feeds) and pull (events are pulled from per producer event store) approaches. Purely push or pull model is less versatile.
* The push/pull decision is made locally on per consumer/producer basis. One size doesn't fit all.
* Global and per producer coherency - With global coherency, events are displayed in the global order of timestamp. With per-producer coherency, time sequence is maintained per producer basis.
* Feed diversity - A frequent producer of events may overshadow events from less frequent producers. Feed diversity addresses diversity in favor of absolute sequencing by timestamp alone.
* The paper describes algorithms for optimization based on various factors, such as cost optimization, optimizing query latency, and so on.
* Describes sample implementation on top of PNUTs and provides performance and other matrices.
In fact, there are a bunch of interesting details about news feed like how to rank feeds, how to optimize publishing etc.
To briefly summarize the feature, when users go to their home pages, they will see updates from their friends based on particular order. Feeds can contain images, videos or just text and a user can have a large number of friends.
it’s better to have some high-level ideas by dividing the big problem into subproblem.
For a news feed system, apparently we can divide it into front-end and backend
For backend, three subproblems seem critical to me:
- Data model. We need some schema to store user and feed object. More importantly, there are lots of trade-offs when we try to optimize the system on read/write.
- Feed ranking. Facebook is doing more than ranking chronologically.
- Feed publishing. Publishing can be trivial when there’re only few hundreds of users. But it can be costly when there are millions or even billions of users. So there’s a scale problem here.
Data model
There are two basic objects: user and feed. For user object, we can store userID, name, registration date and so on so forth. And for feed object, there are feedId, feedType, content, metadata etc., which should support images and videos as well.
If we are using a relational database, we also need to model two relations: user-feed relation and friend relation. The former is pretty straightforward. We can create a user-feed table that stores userID and corresponding feedID. For a single user, it can contain multiple entries if he has published many feeds.
For friend relation, adjacency list is one of the most common approaches. If we see all the users as nodes in a giant graph, edges that connect nodes denote friend relation. We can use a friend table that contains two userIDs in each entry to model the edge (friend relation). By doing this, most operations are quite convenient like fetch all friends of a user, check if two people are friends.
In the design above, let’s see what happens when we fetch feeds from all friends of a user.
The system will first get all userIDs of friends from friend table. Then it fetches all feedIDs for each friend from user-feed table. Finally, feed content is fetched based on feedID from feed table. You can see that we need to perform 3 joins, which can affect performance.
A common optimization is to store feed content together with feedID in user-feed table so that we don’t need to join the feed table any more. This approach is called denormalization, which means by adding redundant data, we can optimize the read performance (reducing the number of joins).
The disadvantages are obvious:
- Data redundancy. We are storing redundant data, which occupies storage space (classic time-space trade-off).
- Data consistency. Whenever we update a feed, we need to update both feed table and user-feed table. Otherwise, there is data inconsistency. This increases the complexity of the system.
Remember that there’s no one approach always better than the other (normalization vs denormalization). It’s a matter of whether you want to optimize for read or write.
Ranking
The most straightforward way to rank feeds is by the time it was created. Obviously, Facebook is doing more than that. “Important” feeds are ranked on top.
Before jumping to the ranking algorithm, I’d usually like to ask why do we want to change the ranking? How do we evaluate whether the new ranking algorithm is better? It’s definitely impressive if candidates come up with these questions by themselves.
The reason to have better ranking is not that this seems the right thing to do. Instead, everything should happen for a reason. Let’s say there are several core metrics we care about, e.g. users stickiness, retention, ads revenue etc.. A better ranking system can significantly improve these metrics potentially, which also answers how to evaluate if we are making progress.
So back to the question – how should we rank feeds? A common strategy is to calculate a feed score based on various features and rank feeds by its score, which is one of the most common approaches for all ranking problems.
More specifically, we can select several features that are mostly relevant to the importance of the feed, e.g. share/like/comments numbers, time of the update, whether the feed has images/videos etc.. And then, a score can be computed by these features, maybe a linear combination. This is usually enough for a naive ranking system.
The general idea of ranking is to first select features/signals that are relevant and then figure out how to combine them to calculate a final score. This approach is extremely common among lots of real-world systems.
As you can see that what matters here are two things – features and calculation algorithm. To give you a better idea of it, I’d like to briefly introduce how ranking actually works at Facebook – EdgeRank.
For each news update you have, whenever another user interacts with that feed, they’re creating what Facebook calls an Edge, which includes actions like like and comments.
First of all, let’s take a look at what features are used to evaluate the importance of an update/feed. Edge Rank basically is using three signals: affinity score, edge weight and time decay.
- Affinity score (u). For each news feed, affinity score evaluates how close you are with this user. For instance, you are more likely to care about feed from your close friends instead of someone you just met once.
- Edge weight (e). Edge weight basically reflects importance of each edge. For instance, comments are worth more than likes.
- Time decay (d). The older the story, the less likely users find it interesting.
So how does Facebook rank feeds by these three features? The calculation algorithm is quite straightforward. For each feed you create, multiply these factors for each Edge then add the Edge scores up and you have an update’s EdgeRank. And the higher that is, the more likely your update is to appear in the user’s feed.
Affinity score
We can do exactly the same thing to evaluate affinity score.
Various factors can be used to reflect how close two people are. First of all, explicit interactions like comment, like, tag, share, click etc. are strong signals we should use. Apparently, each type of interaction should have different weight. For instance, comments should be worth much more than likes.
Secondly, we should also track the time factor. Perhaps you used to interact with a friend quite a lot, but less frequent recently. In this case, we should lower the affinity score. So for each interaction, we should also put the time decay factor.
To sum up the ranking section, I hope this common approach for ranking can be one of your takeaways. Also, EdgeRank was first published at 2010 and it can be outdated.
Feed publishing
When a user loads all the feeds from his friends, it can be an extremely costly action. Remember that a user can have thousands of friends and each of them can publish a huge amount of updates especially for high profile users. To load all feeds from friends, the system requires at least two joins (get friends list and feed list.
So how to optimize and scale the feed publishing system?
Basically there are two common approaches here – push and pull.
For a push system, once a user has published a feed, we immediately pushing this feed (actually the pointer to the feed) to all his friends. The advantage is that when fetching feed, you don’t need to go through your friends list and get feeds for each of them. It significantly reduces read operation. However, the downside is also obvious. It increases write operation especially for people with a large number of friends.
For a pull system, feeds are only fetched when users are loading their home pages. So feed data doesn’t need to be sent right after it’s created. You can see that this approach optimizes for write operation, but can be quite slow to fetch data even after using denormalization (check our previous post if you don’t understand this).
Both approaches work well at certain circumstances and it’s always better to understand their pros and cons.
Selective fanout
The process of pushing an activity to all your friends or followers is called a fanout. So the push approach is also called fanout on write, while the pull approach is fanout on load.
Here I’d like to ask if you have any approaches to further optimize the fanout process?
In fact, you can do a combination of both. Specifically, if you are mainly using push model, what you can do is to disable fanout for high profile users and other people can only load their updates during read. The idea is that push operation can be extremely costly for high profile users since they have a lot of friends to notify. By disabling fanout for them, we can save a huge number of resources. Actually Twitter has seen great improvement after adopting this approach.
By the same token, once a user publish a feed, we can also limit the fanout to only his active friends. For non-active users, most of the time the push operation is a waste since they will never come back consuming feeds.
If you follow 80-20 rule, 80% of the cost comes from 20% of features/users. As a result, optimization is really about identifying the bottleneck.
http://www.chepoo.com/feed-architecture-design-analysis.html
发布的时候push给热点用户,再把feed存入热点cache当没收到push的用户登陆后可以到cache里快速pull出相关feed;用户可以先收到push的新feed消息,当想看以前的消息时再去pull出相关的feed。
三、 如何表示feed
每个平台有各式各样的feed消息,考虑到feed消息最终会展示到平台自身、扩展应用以及客户端上,所以对feed格式统一成某种规范而不是发布者随意输出最终展示的文字。同时对图片、视频以及连接等都统一定义。Facebook的实现方式是这样的:
feed是自描述的,即它不是由生产者决定最终格式,也不是前端决定。而是通过template机制来进行。
template在平台中可以由开发者注册,注册时需要定义字段及最终展示样式,如
“{*actor*} 在***游戏中升到 {*credit*} 级”
template在平台中可以由开发者注册,注册时需要定义字段及最终展示样式,如
“{*actor*} 在***游戏中升到 {*credit*} 级”
发布的feed内容仅包含字段数据,也就是变量的值,json格式。
“{“credit”: “80″}”
“{“credit”: “80″}”
前端需要显示feed时候调用feed模板,再替换字段得到feed内容
“Tim 在***游戏中升到 80 级”
“Tim 在***游戏中升到 80 级”
模板需要定义两个,模板标题及模板内容(展示feed详细内容),前端根据需要决定只显示标题还是全部都显示。
“target”, “actor”是系统保留字段,代表目标对象和当前用户,{*actor*}必须放在模板标题开始位置。
“images”, “flash”, “mp3″, “video” 是系统保留字段,无需在模板中定义。但这些内容只会在详细feed界面输出。即只要feed内容里面有这个字段值,界面就会自动显示。
facebook文档中没有规定feed长度限制。
每个开发者最多只能注册100个模板。
“target”, “actor”是系统保留字段,代表目标对象和当前用户,{*actor*}必须放在模板标题开始位置。
“images”, “flash”, “mp3″, “video” 是系统保留字段,无需在模板中定义。但这些内容只会在详细feed界面输出。即只要feed内容里面有这个字段值,界面就会自动显示。
facebook文档中没有规定feed长度限制。
每个开发者最多只能注册100个模板。
四、 有效组织feed信息
2、 去重
很多时候有些feed信息是有重复性的,比如A发表了一篇日志,他的好友B和C看后很喜欢选择分享。当这条feed如果出现在B与C的共同好友里就会出现重复feed信息。
3、 排序
Design a news feed system — Medium
First thing, the candidate should do is ask questions to the interviewer:
- Do you mean like facebook, quora news feed?
- So, it will fetch all feeds or lets say last 100 feeds?
- Will the feed be sorted by created date or some important feeds will be given preferences?
- And many more questions..
The interviewer will not expect you to design a facebook like feed which must would taken months in just 45 minutes. So the idea is ‘Keep it simple’
So lets say, we want to design a news feed system which give some weight-age to each feed.
So here, I will discuss Facebook Edge Rank Algo :
An Edge is basically everything that “happens” in Facebook. Examples of Edges would be status updates, comments, likes, and shares. There are many more Edges than the examples above—any action that happens within Facebook is an Edge.
EdgeRank ranks Edges in the News Feed. EdgeRank looks at all of the Edges that are connected to the User, then ranks each Edge based on importance to the User. Objects with the highest EdgeRank will typically go to the top of the News Feed.
Actions such as Commenting, Liking, Sharing, Clicking, and even Messaging can influence a User’s Affinity.
Affinity can be based on number of the interactions with your friend, weight of each interaction and time since your last interaction.
Weight is a value system created by Facebook to increase/decrease the value of certain actions within Facebook. Commenting is more involved and therefore deemed more valuable than a Like. In the weighting system, Comments would have a higher value than a Like. In this system all Edges are assigned a value chosen by Facebook. As a general rule, it’s best to assume Edges that take the most time to accomplish tend to weigh more.
Time Decay refers to how long the Edge has been alive; the older it is the less valuable it is. Time Decay is the easiest of the variables to understand. Mathematically it is understood as 1/(Time Since Action). As an Edge ages, it loses value. This helps keep the News Feed fresh with interesting new content, as opposed to lingering old content.
Next is storing this activity.
Ask your interviewer about the use cases of the application.
Our schema would be like this:
id
user_id // user who created the activity
data //may be json object with metadata
edge_rank //calculated using above algo
activity_type // whether its a photo, status, video
source_id //the record that the activity is related to.
created_date //timestamp
We can index on (user_id, created_date) and then perform basic queries.
Publishing the feed
“Push” Model/Fan-out-on-write
As the activity is created publish it to all the recipients. One way is maintain a pub sub model. In which the recepients will be subscribed to the mesaaging queue. Once the activity is generated , its pushed into the queue and the subscribers gets a notification.
2. “Pull” Model/or Fan-out-on-load
This method involves keeping all recent activity data in memory and pulling in (or fanning out) that data at the time a user loads their home page.
Constraints
The push model will start breaking if we have to push the messages to a large audience. Lets say Sachin Tendulkar will have a lot of fans. If this fails there will be a backlog of feeds. An alternative strategy is using different priorities for the fan-out tasks. You simply mark fan-outs to active users as high priority and fan-outs to inactive users as low priority.
The downside of pull model is that the failure scenario is more catastrophic — instead of just delaying updates, you may potentially fail to generate a user’s feed. One workaround is to have a fallback method , e.g get the updates of 10 friends only.
You must be thinking why we chose denormalized activity rather than normalized. So it will also depend on the backend that you are using. The feed with the activities by people you follow either contains the ids of the activities (normalized) or the full activity (denormalized).
Storing id alone will reduce memory usage but add an additional overhead of getting the data based on the id. So if you are building a system in which feed will go to many users , the data will be copied many times and hence memory can be insufficient.
With Redis you need to be careful about memory usage. Cassandra on the other hand has plenty of storage space, but is quite hard to use if you normalize your data.
Interviewer may ask the usage of Redis and Cassandra.
Redis is read-optimized and stores all data in memory. Cassandra is write-optimized data store.
So with redis the following approach can be used:
1.Create your MySQL activity record
2. For each friend of the user who created the activity, push the ID onto their activity list in Redis.
A hybrid approach of pull and push model can also be used.
TODO: http://m.oschina.net/blog/222877
http://www.quora.com/What-are-best-practices-for-building-something-like-a-News-Feed
http://stackoverflow.com/questions/1443960/how-to-implement-the-activity-stream-in-a-social-network
http://www.quora.com/Activity-Streams/What-are-the-scaling-issues-to-keep-in-mind-while-developing-a-social-network-feed
http://www.slideshare.net/nkallen/q-con-3770885/8-Original_Implementationid_userid_text_createdat20
Twitter materializes (in memory) the items in each of the followers' inboxes
http://www.infoq.com/presentations/Big-Data-in-Real-Time-at-Twitter
RELATED: http://massivetechinterview.blogspot.com/2015/12/twitter-architecture-part-2.html
Facebook aggregates the home feed on demand (from in-memory stores called "leaf servers");
http://www.infoq.com/presentations/Scale-at-Facebook
http://highscalability.com/blog/2012/1/17/paper-feeding-frenzy-selectively-materializing-users-event-f.html
This can be considered like a view materialization problem in a database. In a database a view is a virtual table defined by a query that can be accessed like a table. Materialization refers to when the data behind the view is created. If a view is a join on several tables and that join is performed when the view is accessed, then performance will be slow. If the view is precomputed access to the view will be fast, but more resources are used, especially considering that the view may never be accessed.
Your wall/inbox/stream is a view on all the people/things you follow. If you never look at your inbox then materializing the view in your inbox is a waste of resources, yet you'll be mad if displaying your inbox takes forever because all your event streams must be read, sorted, and filtered.
The best policy is to decide whether to push or pull events on a per producer/consumer basis. This technique minimizes system cost both for workloads with a high query rate and those with a high event rate. It also exposes a knob, the push threshold, that we can tune to reduce latency in return for higher system cost.
http://www.cse.iitb.ac.in/infolab/Data/Courses/CS632/Papers/p831-silberstein.pdfWe associate feeds with consumers and event streams with producers. We demonstrate that the best performance results from selectively materializing each consumer's feed: events from high-rate producers are retrieved at query time, while events from lower-rate producers are materialized in advance. A formal analysis of the problem shows the surprising result that we can minimize global cost by making local decisions about each producer/consumer pair, based on the ratio between a given producer's update rate (how often an event is added to the stream) and a given consumer's view rate (how often the feed is viewed). Our experimental results, using Yahoo!'s web-scale database PNUTS, shows that this hybrid strategy results in the lowest system load (and hence improves scalability) under a variety of workloads.
https://www.quora.com/Software-Engineering-Best-Practices/What-are-the-best-practices-for-building-something-like-a-News-Feed
* Combination of push (events are pushed to materialized per consumer feeds) and pull (events are pulled from per producer event store) approaches. Purely push or pull model is less versatile.
* The push/pull decision is made locally on per consumer/producer basis. One size doesn't fit all.
* Global and per producer coherency - With global coherency, events are displayed in the global order of timestamp. With per-producer coherency, time sequence is maintained per producer basis.
* Feed diversity - A frequent producer of events may overshadow events from less frequent producers. Feed diversity addresses diversity in favor of absolute sequencing by timestamp alone.
* The paper describes algorithms for optimization based on various factors, such as cost optimization, optimizing query latency, and so on.
* Describes sample implementation on top of PNUTs and provides performance and other matrices.
- Queue and prompt on new activity. Stream in (preferably in real-time) comments and likes.
- All content is not created equal. While reverse chronological delivery is popular, in high volume situations identify signals to leverage in ranking and ordering content in a more intelligent fashion.
Requirements
Usercan subscribe to manyfeeds.- Each feed(basically say espn) will keep publishing multiple
posts(equivalent of an article). - Each post will have some meta data :
url,published_date.
- Each user logs in, and HomePage is displayed.
- A HomePage has top 20 latest posts from what feeds he has subscribed.
- Upon clicking on next, the next 20 results are displayed.
- There's also feeds_page, where you click on a subscribed feed, and it'll display all the posts from that feed (again top 20, pagination)
Feed representation.
A feed is of xml form.. whenever backend polls, let's say (every 1 hour), this xml gets rewritten.
All the posts may remain same, or new posts may be appended based on how the feed_owner updates the xml (in this case espn).
Read full article from Design a news feed system — MediumA feed is of xml form.. whenever backend polls, let's say (every 1 hour), this xml gets rewritten.
All the posts may remain same, or new posts may be appended based on how the feed_owner updates the xml (in this case espn).