http://vitalflux.com/data-handled-linkedin-com/

, LinkedIn engineering team came up with the three-phase data architecture consisting of online, offline and nearline data systems.At a high level, LinkedIn data are stored in following different forms of data systems (look at the diagram below):
- RDBMS
- Oracle
- MySQL (Used as underlying data store by Espresso)
- NoSQL
- Espresso (Home-grown document-oriented NoSQL data storage system)
- Voldemart (Key-value distributed storage system)
- HDFS (Stores the data of Hadoop map-reduce jobs)
- Caching
- Memcached
- Lucene-based Indexes
- Lucene indexes for storing data related with search, social graph etc.
- Also, used by Espresso
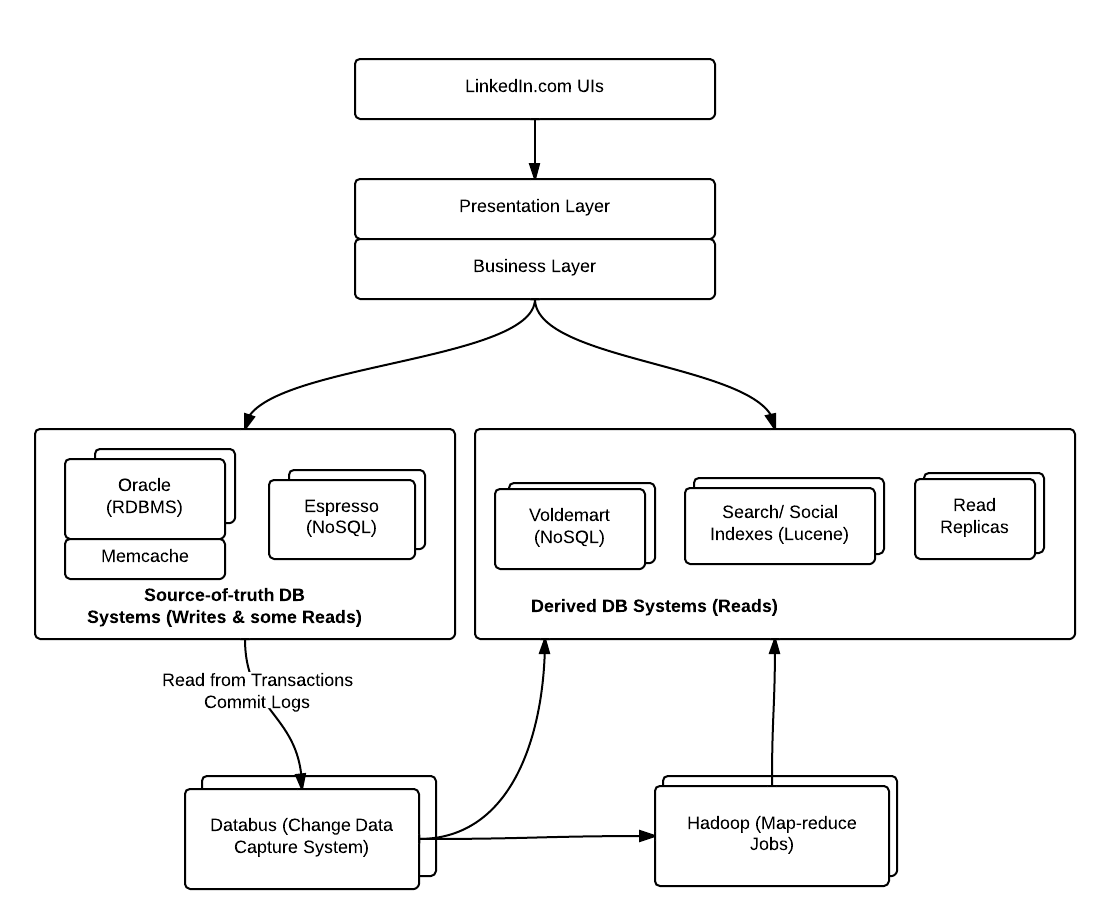
- Different DB systems for writes & reads: One should plan to have two different kind of data systems, one for writes which can be be termed as “source-of-truth” systems and other, all kinds of users’ reads, that could be termed as derived DB systems. Thumb rule is to separate out databases for user-generated writes and users’ reads.
- Derived DB Systems: Users’ read should happen from derived DB systems or Read replicas. Derived DB systems could be created on top of some of the following:
- Lucene indexes
- NoSQL data stores such as Voldemart, Redis, Cassandra, MongoDB etc.
- For users’ reads, one could go out for creating indexes or key-value based data (from systems such as Hadoop map-reduce) from the primary source-of-truth DB systems and update these indexes/derived data (key-value) for every changes occurring as a result of user-generated writes on primary source-of-truth systems.
- One should choose between application-dual writes (writing primary DB and derived DB systems from applciation layer itself) or log mining (for reading transactions commit log from primary data stores using batch jobs) for keeping derived DB systems up-to-date.
- For creating derived data, one may plan to adopt Hadoop based map-reduce jobs which works on main or changed data sets, updates HDFS and notifies the derived data stores such as NoSQL stores such as Voldemart to retrieve the data.
- For data consistency, one may plan to create these data stores as distributed systems where each node in the cluster could again be created based on master-slave node. Each of these nodes could create horizontal data shards.
- For managing maximum uptime of these distributed data stores, one may plan to use cluster management tools such as Apache Helix etc.