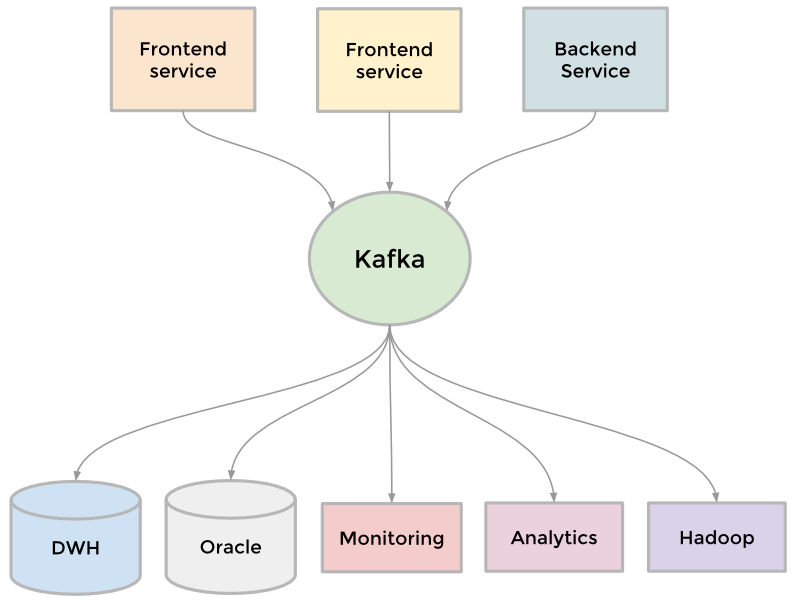
Kafka
Databus,
Voldemart
https://engineering.linkedin.com/voldemort/serving-large-scale-batch-computed-data-project-voldemort
LinkedIn has a number of data-driven features, including People You May Know, Jobs you may be interested in, and LinkedIn Skills. Building these features typically involves two phases: (a) offline computation and (b) online serving.
http://blog.linkedin.com/2009/03/20/project-voldemort-scaling-simple-storage-at-linkedin/
We really like Google’s Bigtable, but we didn’t think it made sense to try to build it if you didn’t have access to a low-latency GFS implementation.
http://blog.linkedin.com/2009/04/01/project-voldemort-part-ii-how-it-works/
Databus,
Voldemart
https://engineering.linkedin.com/voldemort/serving-large-scale-batch-computed-data-project-voldemort
LinkedIn has a number of data-driven features, including People You May Know, Jobs you may be interested in, and LinkedIn Skills. Building these features typically involves two phases: (a) offline computation and (b) online serving.
http://blog.linkedin.com/2009/03/20/project-voldemort-scaling-simple-storage-at-linkedin/
We really like Google’s Bigtable, but we didn’t think it made sense to try to build it if you didn’t have access to a low-latency GFS implementation.
http://blog.linkedin.com/2009/04/01/project-voldemort-part-ii-how-it-works/
With Voldemort we hope to scale both the amount of data we can store and the number of requests for that data. Naturally the only way to do this is to spread both the load and the data across many servers. But spreading across servers creates two key problems:
1. You must find a way to split the data up the data so that no one server has to store everything
2. You must find a way to handle server failures without interrupting service
2. You must find a way to handle server failures without interrupting service
Scaling
The first point is fairly obvious—if you want to handle more requests you need more machines, if you want to handle more data, you need more disks and memory (and servers to hold the disks and memory). But there are still a number of subtleties.
Any system that doesn’t maintain local state, can easily be scaled by just making more copies of it and using a hardware load balance to randomly distribute requests over the machines. Since the whole point of a storage system is to store things, this becomes somewhat more difficult: if we randomly distribute writes then the data will be different on each machine, if we write to every machine then we will potentially have dozens of machines to update on each write.
In order to effectively use all the machines, the data in Voldemort is split-up amongst the servers in such a way that each item is stored on multiple machines (the user specifies how many). This means that you have to first figure out which is the correct server to use. This partitioning is done via a consistent hashing mechanism that let’s any server calculate the location of data without doing any expensive look ups.
This kind of partitioning is commonly done to improve the performance of write requests (since without it, every single server would have to be updated every time you did a write). What is not commonly understood is that this is also required to improve read performance. Memory access is thousands of times faster than disk access, so the ratio of memory to data is the critical factor for accessing the performance of a storage system. By partitioning the data you increase this ratio by shrinking the data on each machine. Another way to think of this is as improving cache locality—if requests are randomly balanced over all machines then “hot” items end up in cache on all servers and the hit ratio is fairly low, by partitioning the storage among machines the cache hit ratio dramatically improves.
Detecting Failure
To handle this problem any distributed system must do some kind of failure detection. Typically this is done by some kind of heart-beat mechanism—each server pings some master co-ordination nodes (or each other) to say “Hi, I am still alive!” In the simple case if a node fails to ping for some time then it is assumed to be dead.
But this raises a few problems, first there aren’t any master nodes in the Voldemort cluster, each node is a peer—so what if one server gets a ping and another does not? Then the servers will have a differing view of who is and is not alive. In fact, maintaining the state about who is alive is the exact same distributed state management problem we were trying to solve in the first place.
The second problem is a bit more existential: what does it mean to be alive? Indeed, just because a server is alive enough to say “hi!” or “ping!” doesn’t mean you are alive enough to correctly service requests with low latency. One solution is to increase the complexity of the ping message to include a variety of metrics on the server’s performance, and then make the prediction as to whether that server is alive or not. But what we do is much simpler. Since Voldemort only has a few types of request (PUT, GET, DELETE, etc.) and since each server is getting hundreds of these requests per second, why invent a new ping request to detect liveness? Instead, since each of these requests has similar performance, it makes sense to simply set an SLA (service level agreement) for the requests and ban servers who cannot meet their SLA (this could be because they are down, because requests are timing out, or many other reasons). Servers that violate this SLA get banned for a short period of time, after which we attempt to restore them (which may lead the them getting banned again).
Dealing With Failure
The redundancy of storage makes the system more resilient to server failure. Since each value is stored N times, you can tolerate as many as N – 1 machine failures without data loss. This causes other problems, though. Since each value is stored in multiple places it is possible that one of these servers will not get updated (say because it is crashed when the update occurs). To help solve this problem Voldemort uses a data versioning mechanism called Vector Clocks that are common in distributed programming. This is an idea we took from Amazon’s Dynamo system. This data versioning allows the servers to detect stale data when it is read and repair it.
The first advantage of this mechanism is that it does not require a consistent view of which servers are working and which are not. If server A cannot get to server C, but server B can get to C that will not break the versioning system. This kind of failure can be especially common in the case of transient failures.
Another advantage relates to challenges faced with expanding data centers. Requests between data centers that are physically remote have much higher latency then requests within a data center (10 or 100x slower depending on geography). With most storage systems it isn’t possible to take concurrent writes across multiple data centers without risk of losing data, since if two updates occur at once, one in each data center, there is no principled way for the storage system to choose between them. By versioning the data you can allow the results to be resolved or the conflict to be given back to the application for resolution.
Video:
Also technically, Voldemort is phenomenal in read speeds. So a user store/a preference store would essentially need much of read speed than write speed.
Sometimes Cassandra can be a over-killer when you just need a key/value pair store.
Kafka became a universal pipeline, built around the concept of a commit log, and was built with speed and scalability in mind.
Super Blocks
Service oriented architectures work well to decouple domains and scale services independently. But there are downsides. Many of our applications fetch many types of different data, in turn making hundreds of downstream calls. This is typically referred to as a “call graph”, or “fanout” when considering all the many downstream calls. For example, any Profile page request fetches much more beyond just profile data including photos, connections, groups, subscription info, following info, long form blog posts, connection degrees from our graph, recommendations, etc. This call graph can be difficult to manage and was only getting more and more unruly.
We introduced the concept of a super block - groupings of backend services with a single access API. This allows us to have a specific team optimize the block, while keeping our call graph in check for each client.
SlideShare - online presentation platform
Pulse - content distribution
Lynda.com - online video educationPulse - content distribution
https://engineering.linkedin.com/blog
Interview Process:
5 different panels:
hiring manager:
provide you with information on the different projects, engineering team culture, challenges, etc.
Ask your career history, your job search (why you’re looking, why is LinkedIn interesting, what technologies are you interested in), and an overview of interesting projects you worked on, and your involvement in these projects
technical communication:
Deep dive into projects you worked, technologies used, and architectural decisions
Make sure you're able to speak of an interesting/challenging project you worked on and be able to explain the challenges faced, lessons learned, and technical details.
They’ll be looking for excitement or interest in the projects you worked on because they want to work alongside engineers who are passionate about what they do.
Start at a high level explaining the project (why was it needed, what was it used for, who would use it, etc), then explain what your team did, then what you were responsible for. Make sure you have a good understanding of the decision that were made and a holistic understanding of the work.
Two of the interviews will focus on coding questions.
Focus on CS fundamentals, data structures, and math (algorithms, graph theory, etc). You won’t be given all the information you need to solve the problem. Instead, you’ll need to ask clarifying questions to identify use cases, edge/corner cases, etc. This is to get a sense of how you approach a problem. It’s going to be a very interactive interview, so ask a lot of questions and only start implementing your solution when you feel you have a good understanding of the problem. If you start struggling with your solution, explain what you did and why so the interviewers are able to give you hints to get you moving along.
1) were you able to come up with a working solution; 2) how complete your code is; 3) cleanliness of code; 4) time to completion; 5) how optimal your solution was (if they ask you if you can optimize your solution, look at your algorithm).
Architecture and Design.
They’ll give you an idea of a module/feature and ask you to architect the system design for it. This is a very abstract problem so make sure to ask a lot of questions in order to gain clarity around system and feature requirements.
They'll want you to architect an entire system from the data center to the UI– what machines/servers/db’s/libraries/etc. What we want to learn here is that you are able to explain why you chose the technologies you chose and that you understand these technologies; the pros and cons; what the tradeoffs are.
think about how your system would scale and distributed computing. We operate in a high traffic environment, so we want to see how familiar you are in this area.
Interview Process:
5 different panels:
hiring manager:
provide you with information on the different projects, engineering team culture, challenges, etc.
Ask your career history, your job search (why you’re looking, why is LinkedIn interesting, what technologies are you interested in), and an overview of interesting projects you worked on, and your involvement in these projects
technical communication:
Deep dive into projects you worked, technologies used, and architectural decisions
Make sure you're able to speak of an interesting/challenging project you worked on and be able to explain the challenges faced, lessons learned, and technical details.
They’ll be looking for excitement or interest in the projects you worked on because they want to work alongside engineers who are passionate about what they do.
Start at a high level explaining the project (why was it needed, what was it used for, who would use it, etc), then explain what your team did, then what you were responsible for. Make sure you have a good understanding of the decision that were made and a holistic understanding of the work.
Two of the interviews will focus on coding questions.
Focus on CS fundamentals, data structures, and math (algorithms, graph theory, etc). You won’t be given all the information you need to solve the problem. Instead, you’ll need to ask clarifying questions to identify use cases, edge/corner cases, etc. This is to get a sense of how you approach a problem. It’s going to be a very interactive interview, so ask a lot of questions and only start implementing your solution when you feel you have a good understanding of the problem. If you start struggling with your solution, explain what you did and why so the interviewers are able to give you hints to get you moving along.
1) were you able to come up with a working solution; 2) how complete your code is; 3) cleanliness of code; 4) time to completion; 5) how optimal your solution was (if they ask you if you can optimize your solution, look at your algorithm).
Architecture and Design.
They’ll give you an idea of a module/feature and ask you to architect the system design for it. This is a very abstract problem so make sure to ask a lot of questions in order to gain clarity around system and feature requirements.
They'll want you to architect an entire system from the data center to the UI– what machines/servers/db’s/libraries/etc. What we want to learn here is that you are able to explain why you chose the technologies you chose and that you understand these technologies; the pros and cons; what the tradeoffs are.
think about how your system would scale and distributed computing. We operate in a high traffic environment, so we want to see how familiar you are in this area.