- Style: Are the variables/parameters declared as final? Are method variables defined close to the code where they’re used or at the start of the method?
- Naming: Do the field/constant/variable/param/class names conform to standards? Are the names overly short?
- Test coverage: Is there a test for this code?
However, having humans looking for these is probably not the best use of time and resources in your organisation, as many of these checks can be automated. There are plenty of tools that can ensure that your code is consistently formatted, that standards around naming and the use of the final keyword are followed, and that common bugs caused by simple programming errors are found. For example, you can run
IntelliJ IDEA’s inspections from the command line, so you don’t have to rely on all team members having the same inspections running in their IDE.
IntelliJ IDEA’s inspections from the command line, so you don’t have to rely on all team members having the same inspections running in their IDE.
Design
- How does the new code fit with the overall architecture?
- Does the code follow SOLID principles, Domain Driven Design and/or other design paradigms the team favours?
- What design patterns are used in the new code? Are these appropriate?
- If the codebase has a mix of standards or design styles, does this new code follow the current practices? Is the code migrating in the correct direction, or does it follow the example of older code that is due to be phased out?
- Is the code in the right place? For example, if the code is related to Orders, is it in the Order Service?
- Could the new code have reused something in the existing code? Does the new code provide something we can reuse in the existing code? Does the new code introduce duplication? If so, should it be refactored to a more reusable pattern, or is this acceptable at this stage?
- Is the code over-engineered? Does it build for reusability that isn’t required now? How does the team balance considerations of reusability with YAGNI?
Readability & Maintainability
- Do the names (of fields, variables, parameters, methods and classes) actually reflect the thing they represent?
- Can I understand what the code does by reading it?
- Can I understand what the tests do?
- Do the tests cover a good subset of cases? Do they cover happy paths and exceptional cases? Are there cases that haven’t been considered?
- Are the exception error messages understandable?
- Are confusing sections of code either documented, commented, or covered by understandable tests (according to team preference)?
Functionality
- Does the code actually do what it was supposed to do? If there are automated tests to ensure correctness of the code, do the tests really test the code meets the agreed requirements?
- Does the code look like it contains subtle bugs, like using the wrong variable for a check, or accidentally using an
andinstead of anor?
Have you thought about…?
- Are there potential security problems with the code?
- Are there regulatory requirements that need to be met?
- For areas that are not covered with automated performance tests, does the new code introduce avoidable performance issues, like unnecessary calls to a database or remote service?
- Does the author need to create public documentation, or change existing help files?
- Have user-facing messages been checked for correctness?
- Are there obvious errors that will stop this working in production? Is the code going to accidentally point at the test database, or is there a hardcoded stub that should be swapped out for a real service?
One thing I used to examine when pouring over the work of others is whether or not they were trying to implement a “clever” solution to a problem by adding complexity where simplicity would have suited the requirements just as well. Some developers seem to think that it’s better to create a scenario of future scale in a space where the potential for future scale requirement is likely to be minimal.
Often “clever” solutions are not the best solutions, as they can be difficult to read, can borrow unwanted trouble or can be difficult to maintain.
Are there tests for this new/amended code?
It would be rare that new code, whether a bug fix or new feature, wouldn’t need a new or updated test to cover it. Even changes for “non-functional” reasons like performance can frequently be proved via a test. If there are no tests included in the code review, as a reviewer the first question you should ask is “why not?”.
Do the tests at least cover confusing or complicated sections of code?
One step beyond simply “is there a test?”, is to answer the question “is the important code actually covered by at least one test?“.
Checking test coverage is certainly something we should be automating. But we can do more than just check for specific percentages in our coverage, we can use coverage tools to ensure the correct areas of code are covered.
In particular, you want to check that all logic branches are covered, and that complex areas of code are covered.Can I understand the tests?
Having tests that provide adequate coverage is one thing, but if I, as a human, can’t understand the tests, they have limited use – what happens when they break? It’ll be hard to know how to fix them.
Do the tests match the requirements?
The reviewer should locate the original requirements and see if:
- The tests, whether they’re unit, end-to-end, or something else, match the requirements. For example, if the requirements are “should allow the special characters ‘#’, ‘!’ and ‘&’ in the password field”, there should be a test using these values in the password field. If the test uses different special characters then it’s not proving the code meets the criteria.
- The tests cover all the criteria mentioned. In our example of special characters, the requirements might go on to say “…and give the user an error message if other special characters are used”. Here, the reviewer should be checking there’s a test for what happens when an invalid character is used.
Can I think of cases that are not covered by the existing tests?
If our new features is, for example, “Give the user the ability to log on to the system”, the reviewer could be thinking “What happens if the user enters null for the username?”, or “What sort of error occurs if the user doesn’t exist in the system?”. If these tests exist in the code being reviewed, then the reviewer has increased confidence that the code itself handles these circumstances. If the tests for these exceptional cases don’t exist, then the reviewer has to go through the code to see if they have been handled.
If the code exists but the tests don’t, it’s up to your team to decide what your policies are – do you make the author add those tests? Or are you satisfied that the code review proved the edge cases were covered?
Are there tests to document the limitations of the code?
It’s not mandatory to express these limitations in an automated test, but if an author has written a test that shows the limits of what they’ve implemented, having a test implies these limits are intentional (and documented) and not merely an oversight.
Are the tests in the code review the right type/level?
For example, is the author doing expensive integration tests where a unit test might suffice? Have they written performance micro-benchmarks that will not run effectively or in a consistent fashion in the CI environment?
Ideally your automated tests will run as quickly as possible, which means that expensive end-to-end tests may not be required to check all types of features. A method that performs some mathematical function, or boolean logic check, seems like a good candidate for a method-level unit test.
Are there tests for security aspects?
As a code reviewer, you should be checking that the original developer has put some thought into the ways his or her code could be used, under which conditions it might break, and dealt with edge cases, possibly “documenting” the expected behaviour (both under normal use and exceptional circumstances) with automated tests.
If the reviewer looks for the existence of tests and checks the correctness of the tests, as a team you can have pretty high confidence that the code works. Moreover, if these tests are run regularly in a CI environment, you can see that the code continues to work – they provide automated regression checking.
Did this piece of functionality have hard performance requirements?
Does the piece of code under review fall under an area that had a previously published SLA? Or do the requirements state the performance characteristics required?
If the original requirements were a bug along the lines of “the login screen is too slow to load”, the original developer should have clarified what would be a suitable loading time – otherwise how can the reviewer or the author be confident that the speed has been sufficiently improved?
If so, is there a test that proves it meets those?
Has the fix/new functionality negatively impacted the results of any existing performance tests?
Calls outside of the service/application are expensive
Calls to the database
Unnecessary network calls
Using resources efficiently/effectively
Does the code use locks to access shared resources? Could this result in poor performance or deadlocks?
Locks are a performance killer and very hard to reason about in a multi-threaded environment. Consider patterns like; having only a single thread that writes/changes values while all other threads are free to read; or using lock free algorithms.
Is there something in the code which could lead to a memory leak?
In Java, some common causes can be: mutable static fields, using ThreadLocal and using a
ClassLoader.
Is there a possibility the memory footprint of the application could grow infinitely?
a memory leak is where unused objects cannot be collected by the garbage collector. If, as a reviewer, you see new values constantly being added to a list or map, question if and when the list or map is discarded or trimmed.
Does the code close connections/streams?
Warning signs a reviewer can easily spotReflection
Timeouts
When you’re reviewing code, you might not know what the correct timeout for an operation is, but you should be thinking “what’s the impact on the rest of the system while this timeout is ticking down?”. As the reviewer you should consider the worst case – is the application blocking while a 5 minute timeout is ticking down? What’s the worst that would happen if this was set to one second? If the author of the code can’t justify the length of a timeout, and you, the reviewer, don’t know the pros and cons of a selected value, then it’s a good time to get someone involved who does understand the implications. Don’t wait for your users to tell you about performance problems.
Parallelism
Does the code use multiple threads to perform a simple operation? Does this add more time and complexity rather than improving performance? With modern Java, this might be more subtle than creating new threads explicitly: does the code use Java 8’s shiny new parallel streams but not benefit from the parallelism? For example, using a parallel stream on a small number of elements, or on a stream which does very simple operations, might be slower than performing the operations on a sequential stream.
CorrectnessIs the code using the correct data structure for a multi-threaded environment?
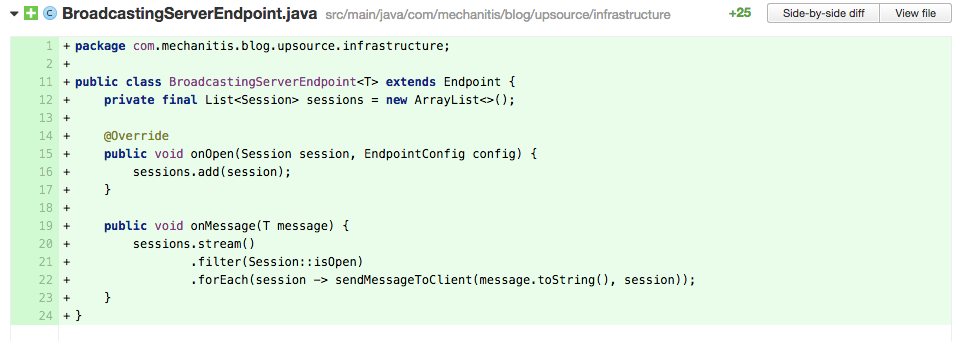
In the code above, the author is using an
ArrayList on line 12 to store all the sessions. However, this code, specifically the onOpen method, is called by multiple threads, so the sessions field needs to be a thread safe data structure. For this case, we have a number of options: we could use a Vector, we could use Collections.synchronizedList() to create a thread safe List, but probably the best selection for this case is to use CopyOnWriteArrayList, since the list will change far less often than it will be read.
Is the code susceptible to race conditions?
Is the code using locks correctly?
Related to race conditions, as a reviewer you should be checking that the code being reviewed is not allowing multiple threads to modify values in a way that could clash. The code might need synchronization, locks, or atomic variables to control changes to blocks of code.
Is the performance test for the code valuable?
It’s easy to write poor microbenchmarks, for example. Or if the test uses data that’s not at all like production data, it might be giving misleading results.
Caching
While caching might be a way to prevent making too many external requests, it comes with its own challenges. If the code under review uses caching, you should look for some common problems, for example, incorrect invalidation of cache items.
Code-level optimisations- Does the code use synchronization/locks when they’re not required? If the code is always run on a single thread, locks are unnecessary overhead.
- Is the code using a thread-safe data structure where it’s not required? For example, can
Vectorbe replaced withArrayList? - Is the code using a data structure with poor performance for the common operations? For example, using a linked list but needing to regularly search for a single item in it.
- Is the code using locks or synchronization when it could use atomic variables instead?
- Could the code benefit from lazy loading?
- Can
ifstatements or other logic be short-circuited by placing the fastest evaluation first? - Is there a lot of string formatting? Could this be more efficient?
- Are the logging statements using string formatting? Are they either protected by an
ifto check logging level, or using a supplier which is evaluated lazily?

In Java 8, these performance gains can be obtained without the boilerplate
if, by using a lambda expression.List
Anti-Pattern: Too Much Searching

Remember that in Java 8, and languages which support more expressive searches, this might not be as obvious as a for-loop, but the problem still remains.
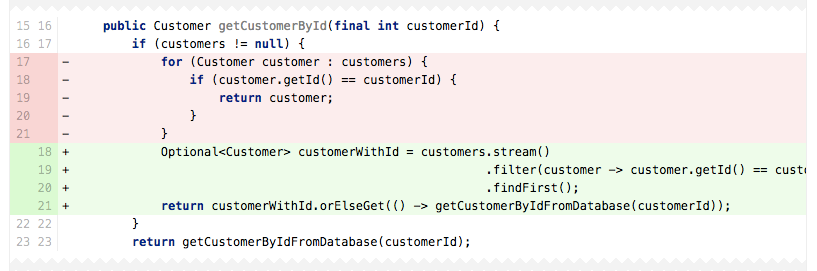
Anti-Pattern: Frequent Reordering
In this case, given that a
TwitterUser is unique and it looks like you want a collection that’s sorted by default, you probably want something like a TreeSet.
Anti-Pattern: Map as global constant
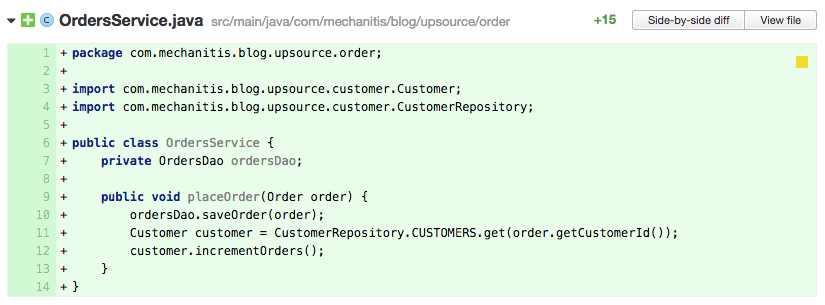
Here, the order service is aware of the data structure used to store customers. In fact, in the code above, the author has made an error – they don’t check to see if the customer is null, so line 12 could cause a
NullPointerException. As the reviewer of this code, you’ll want to suggest hiding this data structure away and providing suitable access methods. That will make these other classes easier to understand, and hide any complexity of managing the map in theCustomerRepository, where it belongs. In addition, if later you change the customers data structure, or you move to using a distributed cache or some other technology, the changes associated with that will be restricted to the CustomerRepository class and not ripple throughout the system. This is the principle of Information Hiding.
Note that this is exactly the sort of issue that should be found during a code review – hiding global constants is hard to do once their use has propagated throughout the system, but it’s easy to catch this when they’re first introduced.
Other Anti-Patterns: Iteration & Reordering
As with lists, if a code author has introduced a lot of sorting of, or iterating over, a map, you might want to suggest an alternative data structure.
Java-specific things to be aware of
In Java, map behaviour usually relies on your implementation of
equals and hashCode for the key and the value. As a reviewer, you should check these methods on the key and value classes to ensure you’re getting the expected behaviour.
Java 8 has added a number of very useful methods to the
Map interface. The getOrDefaultmethod, for example, could simplify the CustomerRepository code at line 11 in the example above.
Because one of the key operations of a set is
contains, as a reviewer you should be checking the implementation of equals on the type contained in the set.- The class you want for a stack implementation in Java (since version 1.6) is Deque. This can act as both a queue and a stack, so reviewers should check that deques are used in a consistent fashion in the code.
- Queues can be bounded or unbounded. Unbounded queues could potentially grow forever, so if reviewing code with this type of data structure, check out the earlier post on performance. Bounded queues can come with their own problems too – when reviewing code, you should look for the conditions under which the queue might become full, and ask what happens to the system under these circumstances.
If you’re using Java 8, remember that many of the collections classes have new methods. As a reviewer you should be aware of these – you should be able to suggest places where the new methods can be used in place of older, more complex code.
- Lots of iterating over the data structure to find some value or values
- Frequent reordering of the data
- Not using methods that provide key features – e.g. push or pop on a stack
- Complex code either reading from or writing to the data structure
In addition, exposing the details of selected data structures, either by providing global access to the structure itself, or by tightly coupling your class’s interface to the operation of an underlying data structure, leads to a brittleness of design, and will be hard to undo later. It’s better to catch these problems early on, for example during a code review, than incur avoidable technical debt.
- Long
if/elsestatements - Casting to a subtype
- Many public methods
- Implemented methods that throw
UnsupportedOperationException
As with all design questions, finding a balance between following these principles and knowingly bending the rules is down to your team’s preferences. But if you see complex code in a code review, you might find that applying one of these principles will provide a simpler, more understandable, solution.
Common problems like SQL Injection or Cross-site Scripting can be found via tools running in your Continuous Integration environment. You can also automate checking for known vulnerabilities in your dependencies via the OWASP Dependency Check tool.
Sometimes “It Depends”
While there are checks that you can feel comfortable with a “yes” or “no” answer, sometimes you want a tool to point out potential problems and then have a human make the decision as to whether this needs to be addressed or not. This is an area where Upsource can really shine. Upsource displays code inspections that a reviewer can use to decide if the code needs to be changed or is acceptable under the current situation.
While there are checks that you can feel comfortable with a “yes” or “no” answer, sometimes you want a tool to point out potential problems and then have a human make the decision as to whether this needs to be addressed or not. This is an area where Upsource can really shine. Upsource displays code inspections that a reviewer can use to decide if the code needs to be changed or is acceptable under the current situation.
if you’re using it for something like session IDs, password reset links, nonces or salts, as a reviewer you might suggest replacing
Random withjava.util.SecureRandom.- Use a few as sources as possible and understand how trustworthy they are
- Use the highest quality library you can
- Track what you use and where, so if new vulnerabilities do become apparent, you can check your exposure.
This means:
- Understanding your sources (e.g. maven central or your own repo vs arbitrarily downloaded jar files)
- Trying not to use 5 different versions of 3 different logging frameworks (for example)
- Being able to view your dependency tree, even if it’s simply through Gradle/Maven
Check if new paths & services need to be authenticated
Does your data need to be encrypted?
Are secrets being managed correctly?
Secrets are things like passwords (user passwords, or passwords to databases or other systems), encryption keys, tokens and so forth. These should never be stored in code, or in configuration files that get checked into the source control system. There are other ways of managing these secrets, for example via a secrets server. When reviewing code, make sure these things don’t accidentally sneak into your VCS.
Secrets are things like passwords (user passwords, or passwords to databases or other systems), encryption keys, tokens and so forth. These should never be stored in code, or in configuration files that get checked into the source control system. There are other ways of managing these secrets, for example via a secrets server. When reviewing code, make sure these things don’t accidentally sneak into your VCS.
Should the code be logging/auditing behaviour? Is it doing so correctly?
Logging and auditing requirements vary by project, with some systems requiring compliance with stricter rules for logging actions and events than others. If you do have guidelines on what needs logging, when and how, then as a code reviewer you should be checking the submitted code meets these requirements. If you do not have a firm set of rules, consider:
Logging and auditing requirements vary by project, with some systems requiring compliance with stricter rules for logging actions and events than others. If you do have guidelines on what needs logging, when and how, then as a code reviewer you should be checking the submitted code meets these requirements. If you do not have a firm set of rules, consider:
- Is the code making any data changes (e.g. add/update/remove)? Should it make a note of the change that was made, by whom, and when?
- Is this code on some performance-critical path? Should it be making a note of start-time and end-time in some sort of performance monitoring system?
- Is the logging level of any logged messages appropriate? A good rule of thumb is that “ERROR” is likely to cause an alert to go off somewhere, possibly on some poor on-call person’s pager – if you do not need this message to wake someone up at 3am, consider downgrading to “INFO” or “DEBUG”. Messages inside loops, or other places that are likely to be output more than once in a row, probably don’t need to be spamming your production log files, therefore are likely to be “DEBUG” level.