http://prismoskills.appspot.com/lessons/System_Design_and_Big_Data/Chapter_02_-_Hadoop_Basics.jsp
Hadoop Architechture
Hadoop divides a file into chunks (typically 64 MB in size) and stores each chunk on a DataNode.
Each chunk is replicated multiple times (typically 3 times) to guard against node failure.
If any node fails, all the chunks in it are automatically copied from other nodes to keep the replication factor same as before.
One node in the Hadoop cluster is called the NameNode.
This node stores only the meta-data for chunks of files and keeps this information in memory.
This helps the NameNode to respond very quickly when it is asked about the whereabouts of a file.
When chunks are needed, the NameNode only provides the location.
Accessing the chunks happens directly from the DataNodes.
Why huge block-sizes?
Lets say, HDFS is storing a 1000Mb file.
With a 4k block size, 256,000 requests will be required to get that file (1 request per block).
In HDFS, those requests go across a network and come with a lot of overhead.
Additionally, each request is processed by the NameNode to figure out the block's physical location.
With 64Mb blocks, the number of requests goes down to 16, which is much much more efficient for network traffic.
It reduces the load on the NameNode and also reduces the meta-data for the entire file, allowing meta-data to be stored in memory.
Thus, for large files, a bigger block size in HDFS is a boon.
Map-Reduce
Conceptually, map-reduce functions look like:
map (key1, value1) ----> list <key2, value2>
reduce (key2, list<value2>) -----> list <key3, value3>
i.e. map takes a key/value as an input and emits a list of key-value pairs.
Hadoop collects all these emitted key-value pairs, groups them by key and calls reduce for each group.
That's why the input to the "reduce" function is one key but multiple values.
Reduce function is free to emit whatever it wants as the same is just flushed to the HDFS.
Each map or reduce job is called a Task.
And all tasks for one map-reduce work make up one Job.
http://prismoskills.appspot.com/lessons/System_Design_and_Big_Data/Chapter_11_-_Flume_vs_Kafka.jsp
"What tool is the best for transporting data/logs across servers in a system?"
Problems targeted by these systems
Flume is designed to ease the ingestion of data from one component to other.
It's focus is mostly on Hadoop although now it has sources and sinks for several other tools also, like Solr.
Kafka on the other hand is a messaging system that can store data for several days (depending on the data size of-course).
Kafka focuses more on the pipe while Flume focuses more on the end-points of the pipe.
That's why Kafka does not provide any sources or sinks specific to any component like Hadoop or Solr.
It just provides a reliable way of getting the data across from one system to another.
Kafka uses partitioning for achieving higher throughput of writes and uses replication for reliability and higher read throughput.
Push / Pull
Flume pushes data while Kafka needs the consumers to pull the data. Due to push nature, Flume needs some work at the consumers' end for replicating data-streams to multiple sinks. With Kafka, each consumer manages its own read pointer, so its relatively easy to replicate channels in Kafka and also much easier to parallelize data-flow into multiple sinks like Solr and Hadoop.
Latest trend is to use both Kafka and Flume together.
KafkaSource and KafkaSink for Flume are available which help in doing so.
The combination of these two gives a very desirable system because Flume's primary effort is to help ingest data into Hadoop and doing this in Kafka without Flume is a significant effort. Also note that Flume by itself is not sufficient for processing streams of data as Flume's primary purpose is not to store and replicate data streams. Hence it would be poor system if it uses only a single one of these two tools.
Persistence storage on disk
Kafka keeps the messages on disk till the time it is configured to keep them.
Thus if a Kafka broker goes offline for a while and comes back, the messages are not lost.
Flume also maintains a write-ahead-log which helps it to restore messages during a crash.
Flume error handling and transactional writes
Flume is meant to pass messages from source to sink (All of which implement Flume interfaces for get and put, thus treating Flume as an adapter). For example, a Flume log reader could send messages to a Flume sink which duplicates the incoming stream to Hadoop Flume Sink and Solr Flume Sink. For a chained system of Flume sources and sinks, Flume achieves reliability by using transactions - a sending Flume client does not close its write transaction unless the receiving client writes the data to its own Write-Ahead-Log and informs the sender about the same. If the receiver does not acknowledge the writing of WAL to the sender, then the sender marks this as a failure. The sender then begins to buffer all such events unless it can no longer hold any more. At this point, it begins to reject writes from its own upstream clients as well.
http://prismoskills.appspot.com/dyn-lessons/System_Design_and_Big_Data/Good_big_data_tools
Hadoop 还包含了一系列技术的扩展系统,这些技术主要包括了Sqoop、Flume、Hive、Pig、Mahout、Datafu和HUE等。
分布式系统还有很多算法和高深理论,比如:Paxos算法(paxos分布式一致性算法--讲述诸葛亮的反穿越),Gossip协议(Cassandra学习笔记之Gossip协议),Quorum (分布式系统),时间逻辑,向量时钟(一致性算法之四: 时间戳和向量图),拜占庭将军问题,二阶段提交等,需要耐心研究。
说大数据的技术还是要先提Google,Google 新三辆马车,Spanner, F1, Dremel
Spanner:高可扩展、多版本、全球分布式外加同步复制特性的谷歌内部数据库,支持外部一致性的分布式事务;设计目标是横跨全球上百个数据中心,覆盖百万台服务器,包含万亿条行记录!(Google就是这么霸气^-^)
F1: 构建于Spanner之上,在利用Spanner的丰富特性基础之上,还提供分布式SQL、事务一致性的二级索引等功能,在AdWords广告业务上成功代替了之前老旧的手工MySQL Shard方案。
Dremel: 一种用来分析信息的方法,它可以在数以千计的服务器上运行,类似使用SQL语言,能以极快的速度处理网络规模的海量数据(PB数量级),只需几秒钟时间就能完成。
一年前,Twitter就已经开始了从Storm迁徙到Heron;半年前,Storm在Twitter内部已经完全被舍弃。换言之,Heron已经很好地在Twitter用于线上运行超过半年。
Heron更适合超大规模的机器, 超过1000台机器以上的集群。 在稳定性上有更优异的表现, 在性能上,表现一般甚至稍弱一些,在资源使用上,可以和其他编程框架共享集群资源,但topology级别会更浪费一些资源
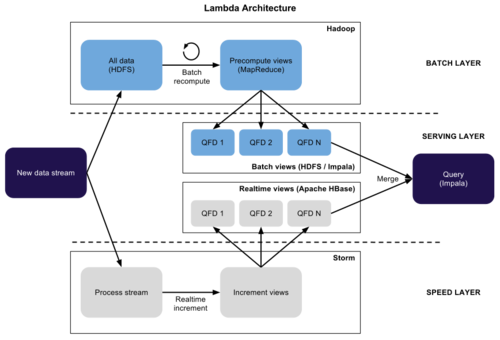
Lambda architecture
Nathan写了文章《如何去打败CAP理论》How to beat the CAP theorem,提出Lambda Architecture,主要思想是对一些延迟高但数据量大的还是采用批处理架构,但对于即时性实时数据使用流式处理框架,然后在之上搭建一个服务层去合并两边的数据流,这种系统能够平衡实时的高效和批处理的Scale,看了觉得脑洞大开,确实很有效,被很多公司采用在生产系统中。
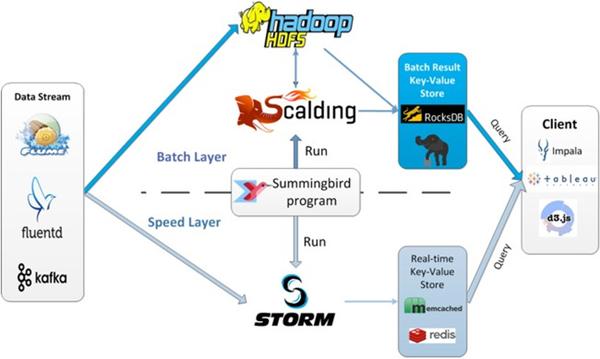
 Summingbird
Summingbird
Lambda架构的问题要维护两套系统,Twitter开发了Summingbird来做到一次编程,多处运行。将批处理和流处理无缝连接,通过整合批处理与流处理来减少它们之间的转换开销。下图就解释了系统运行时。
Hadoop Architechture
Hadoop divides a file into chunks (typically 64 MB in size) and stores each chunk on a DataNode.
Each chunk is replicated multiple times (typically 3 times) to guard against node failure.
If any node fails, all the chunks in it are automatically copied from other nodes to keep the replication factor same as before.
One node in the Hadoop cluster is called the NameNode.
This node stores only the meta-data for chunks of files and keeps this information in memory.
This helps the NameNode to respond very quickly when it is asked about the whereabouts of a file.
When chunks are needed, the NameNode only provides the location.
Accessing the chunks happens directly from the DataNodes.
Why huge block-sizes?
Lets say, HDFS is storing a 1000Mb file.
With a 4k block size, 256,000 requests will be required to get that file (1 request per block).
In HDFS, those requests go across a network and come with a lot of overhead.
Additionally, each request is processed by the NameNode to figure out the block's physical location.
With 64Mb blocks, the number of requests goes down to 16, which is much much more efficient for network traffic.
It reduces the load on the NameNode and also reduces the meta-data for the entire file, allowing meta-data to be stored in memory.
Thus, for large files, a bigger block size in HDFS is a boon.
Map-Reduce
Conceptually, map-reduce functions look like:
map (key1, value1) ----> list <key2, value2>
reduce (key2, list<value2>) -----> list <key3, value3>
i.e. map takes a key/value as an input and emits a list of key-value pairs.
Hadoop collects all these emitted key-value pairs, groups them by key and calls reduce for each group.
That's why the input to the "reduce" function is one key but multiple values.
Reduce function is free to emit whatever it wants as the same is just flushed to the HDFS.
Each map or reduce job is called a Task.
And all tasks for one map-reduce work make up one Job.
Hadoop is the big boss when it comes to dealing with big data that runs into terabytes.
It typically serves two purposes:
Storing humongous amounts of data: This is achieved by partitioning the data among several nodes.
Block-size in Hadoop File System is also much larger (64 or 128 MB) than normal file-systems (64kb).
Bringing computation to data: Traditionally, data is brought to clients for computation.
But data stored in Hadoop is so large that it is more efficient to do the opposite.
This is done by writing map-reduce jobs which run closer to the data stored in the Hadoop.
HDFS (Hadoop Distributed File System): HDFS is responsible for:
Distributing the data across the nodes,
Managing replication for redundancy and
Administrative tasks like adding, removing and recovery of data nodes.
HCatalog: This is a tool that holds location and metadata of the HDFS.
This way it completely abstracts the HDFS details from other Hadoop clients like Pig and Hive.
It provides a table abstraction so that users need not be concerned with where or how their data is stored.
Hive provides SQL like querying capabilities to view data stored in the HDFS.
It has its own query language called HiveQL.
Beeswax is a tool used to interact with Hive. It can take in queries from user to Hive.
Select * from person_table where last_name = "smith";
describe person_table;
select count(*) from person_table; Thus, for SQL programmers, Hive provides this facility to become productive immediately.
Pig is a language used to run MapReduce jobs on Hadoop.
It supports MapReduce programs in several languages including Java.
a = LOAD 'person_table' USING org.apache.hcatalog.pig.HCatLoader();
b = FILTER a BY last_name == 'smith';
c = group b all;
d = foreach c generate AVG(b.age);
dump d;
HBase is an open source, non-relational, distributed database running on top of Hadoop.
Tables in HBase can serve as the input and output for MapReduce jobs run in Hadoop, and may be accessed through Java APIs as well as through REST, Avro or Thrift gateway APIs.
Sqoop is a command-line interface application for transferring data between relational databases and Hadoop.
It supports:
Incremental loads of a single table,
A free form SQL query,
Saved jobs which can be run multiple times to import updates made to a database since the last import.
Imports from Sqoop be used to populate tables in Hive or HBase.
And exports from it can be used to put data from Hadoop into a relational database.
Difference between Pig and Hive
Pig is a scripting language for Hadoop developed at Yahoo! in 2006.
Hive is a SQL like querying language for Hadoop developed parallelly at Facebook.
Pig allows querying too, but its syntax is not SQL like due to which there is some learning curve.
But once you are comfortable with Pig, it provides more power than Hive.
Pig is procedural, so one can write small transformations step by step.
Due to this, Pig is also easier to debug because the results of these small steps can be printed for debugging issues.
Hive is much more suitable for Business Analysts familiar with SQL (as they can quickly write SQL and get away without very fine optimization of their extraction/querying etc.) while Pig is more suitable for software engineers writing very complicated scripts that are not suitable for writing as SQL queries.
"What tool is the best for transporting data/logs across servers in a system?"
Problems targeted by these systems
Flume is designed to ease the ingestion of data from one component to other.
It's focus is mostly on Hadoop although now it has sources and sinks for several other tools also, like Solr.
Kafka on the other hand is a messaging system that can store data for several days (depending on the data size of-course).
Kafka focuses more on the pipe while Flume focuses more on the end-points of the pipe.
That's why Kafka does not provide any sources or sinks specific to any component like Hadoop or Solr.
It just provides a reliable way of getting the data across from one system to another.
Kafka uses partitioning for achieving higher throughput of writes and uses replication for reliability and higher read throughput.
Push / Pull
Flume pushes data while Kafka needs the consumers to pull the data. Due to push nature, Flume needs some work at the consumers' end for replicating data-streams to multiple sinks. With Kafka, each consumer manages its own read pointer, so its relatively easy to replicate channels in Kafka and also much easier to parallelize data-flow into multiple sinks like Solr and Hadoop.
Latest trend is to use both Kafka and Flume together.
KafkaSource and KafkaSink for Flume are available which help in doing so.
The combination of these two gives a very desirable system because Flume's primary effort is to help ingest data into Hadoop and doing this in Kafka without Flume is a significant effort. Also note that Flume by itself is not sufficient for processing streams of data as Flume's primary purpose is not to store and replicate data streams. Hence it would be poor system if it uses only a single one of these two tools.
Persistence storage on disk
Kafka keeps the messages on disk till the time it is configured to keep them.
Thus if a Kafka broker goes offline for a while and comes back, the messages are not lost.
Flume also maintains a write-ahead-log which helps it to restore messages during a crash.
Flume error handling and transactional writes
Flume is meant to pass messages from source to sink (All of which implement Flume interfaces for get and put, thus treating Flume as an adapter). For example, a Flume log reader could send messages to a Flume sink which duplicates the incoming stream to Hadoop Flume Sink and Solr Flume Sink. For a chained system of Flume sources and sinks, Flume achieves reliability by using transactions - a sending Flume client does not close its write transaction unless the receiving client writes the data to its own Write-Ahead-Log and informs the sender about the same. If the receiver does not acknowledge the writing of WAL to the sender, then the sender marks this as a failure. The sender then begins to buffer all such events unless it can no longer hold any more. At this point, it begins to reject writes from its own upstream clients as well.
http://prismoskills.appspot.com/dyn-lessons/System_Design_and_Big_Data/Good_big_data_tools
- collectd gathers statistics about the system it is running on and stores this information to find performance bottlenecks and generate alerts.
- Shiro is an Apache Security Tool that adds users, roles, https and other security features to a website.
- Kibana
http://zhuanlan.zhihu.com/donglaoshi/19962491
Amazon Elastic Map Reduce(EMR):托管的解决方案,运行在由Amazon Elastic Compute Cloud(EC2)和Simple Strorage Service(S3)组成的网络规模的基础设施之上。如果你需要一次性的或不常见的大数据处理,EMR可能会为你节省开支。但EMR是高度优化成与S3中的数据一起工作,会有较高的延时。
分布式系统还有很多算法和高深理论,比如:Paxos算法(paxos分布式一致性算法--讲述诸葛亮的反穿越),Gossip协议(Cassandra学习笔记之Gossip协议),Quorum (分布式系统),时间逻辑,向量时钟(一致性算法之四: 时间戳和向量图),拜占庭将军问题,二阶段提交等,需要耐心研究。
说大数据的技术还是要先提Google,Google 新三辆马车,Spanner, F1, Dremel
Spanner:高可扩展、多版本、全球分布式外加同步复制特性的谷歌内部数据库,支持外部一致性的分布式事务;设计目标是横跨全球上百个数据中心,覆盖百万台服务器,包含万亿条行记录!(Google就是这么霸气^-^)
F1: 构建于Spanner之上,在利用Spanner的丰富特性基础之上,还提供分布式SQL、事务一致性的二级索引等功能,在AdWords广告业务上成功代替了之前老旧的手工MySQL Shard方案。
Dremel: 一种用来分析信息的方法,它可以在数以千计的服务器上运行,类似使用SQL语言,能以极快的速度处理网络规模的海量数据(PB数量级),只需几秒钟时间就能完成。
一年前,Twitter就已经开始了从Storm迁徙到Heron;半年前,Storm在Twitter内部已经完全被舍弃。换言之,Heron已经很好地在Twitter用于线上运行超过半年。
Heron更适合超大规模的机器, 超过1000台机器以上的集群。 在稳定性上有更优异的表现, 在性能上,表现一般甚至稍弱一些,在资源使用上,可以和其他编程框架共享集群资源,但topology级别会更浪费一些资源
Lambda architecture
Nathan写了文章《如何去打败CAP理论》How to beat the CAP theorem,提出Lambda Architecture,主要思想是对一些延迟高但数据量大的还是采用批处理架构,但对于即时性实时数据使用流式处理框架,然后在之上搭建一个服务层去合并两边的数据流,这种系统能够平衡实时的高效和批处理的Scale,看了觉得脑洞大开,确实很有效,被很多公司采用在生产系统中。
SummingbirdLambda架构的问题要维护两套系统,Twitter开发了Summingbird来做到一次编程,多处运行。将批处理和流处理无缝连接,通过整合批处理与流处理来减少它们之间的转换开销。下图就解释了系统运行时。
Apache社区类似于Dremel的开源版本—Drill。一个专为互动分析大型数据集的分布式系统。
Druid在大数据集之上做实时统计分析而设计的开源数据存储。这个系统集合了一个面向列存储的层,一个分布式、shared-nothing的架构,和一个高级的索引结构,来达成在秒级以内对十亿行级别的表进行任意的探索分析。
在Berkeley AMP lab 中有个更宏伟的蓝图,就是BDAS,里面有很多明星项目,除了Spark,还包括:
Mesos:一个分布式环境的资源管理平台,它使得Hadoop、MPI、Spark作业在统一资源管理环境下执行。它对Hadoop2.0支持很好。Twitter,Coursera都在使用。
Tachyon:是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和MapReduce那样。项目发起人李浩源说目前发展非常快,甚至比Spark当时还要惊人,已经成立创业公司Tachyon Nexus.
BlinkDB:也很有意思,在海量数据上运行交互式 SQL 查询的大规模并行查询引擎。它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。
https://hadoopecosystemtable.github.io/
Druid在大数据集之上做实时统计分析而设计的开源数据存储。这个系统集合了一个面向列存储的层,一个分布式、shared-nothing的架构,和一个高级的索引结构,来达成在秒级以内对十亿行级别的表进行任意的探索分析。
在Berkeley AMP lab 中有个更宏伟的蓝图,就是BDAS,里面有很多明星项目,除了Spark,还包括:
Mesos:一个分布式环境的资源管理平台,它使得Hadoop、MPI、Spark作业在统一资源管理环境下执行。它对Hadoop2.0支持很好。Twitter,Coursera都在使用。
Tachyon:是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和MapReduce那样。项目发起人李浩源说目前发展非常快,甚至比Spark当时还要惊人,已经成立创业公司Tachyon Nexus.
BlinkDB:也很有意思,在海量数据上运行交互式 SQL 查询的大规模并行查询引擎。它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。
https://hadoopecosystemtable.github.io/