https://puncsky.com/hacking-the-software-engineer-interview#data-stores-todo
https://rockset.com/blog/aggregator-leaf-tailer-an-architecture-for-live-analytics-on-event-streams/
https://www.mapr.com/developercentral/lambda-architecture
http://lambda-architecture.net/

it was noted that using a flexible streaming framework such asApache Samza could provide some of the same benefits as batch processing without the latency. Such a streaming framework could allow for collecting and processing arbitrarily large windows of data, accommodate blocking, and handle state.
https://www.infoq.com/articles/lambda-architecture-scalable-big-data-solutions
https://voltdb.com/blog/simplifying-complex-lambda-architecture
one of the more common use cases of Lambda-based applications is log ingestion and accompanying analytics. “Logs” in this context could be general log collection, website clickstream logging, VPN access logs, or the popular Twitter tweet stream collection.
Lambda架构与推荐在电商网站实践
Why lambda architecture?
To solve three problems introduced by big data
- Accuracy (好)
- Latency (快)
- Throughput (多)
e.g. problems with scaling a pageview service in a traditional way
- You start with a traditional relational database.
- Then adding a pub-sub queue.
- Then scaling by horizontal partitioning or sharding
- Fault-tolerance issues begin
- Data corruption happens
The key point is that X-axis dimension alone of the AKF scale cube is not good enough. We should introduce Y-axis / functional decomposition as well. Lambda architecture tells us how to do it for a data system.
What is lambda architecture?
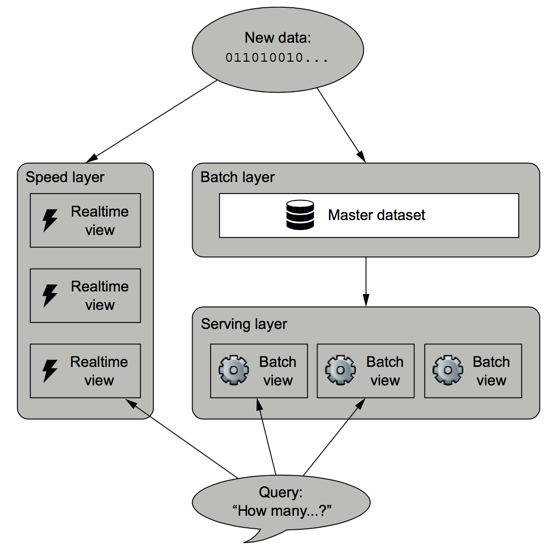
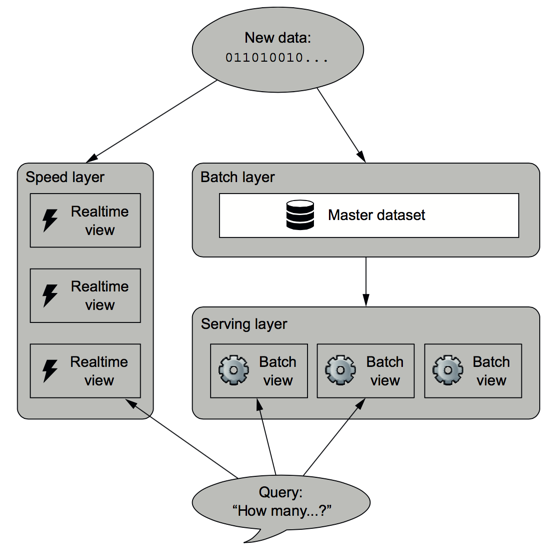
If we define a data system as
Query = function(all data)
Then a lambda architecture is
batch view = function(all data at the batching job's execution time)
realtime view = function(realtime view, new data)
query = function(batch view. realtime view)
Lambda architecture = CQRS (batch layer + serving layer) + speed layer
Traditional Data Processing: Batch and Streaming
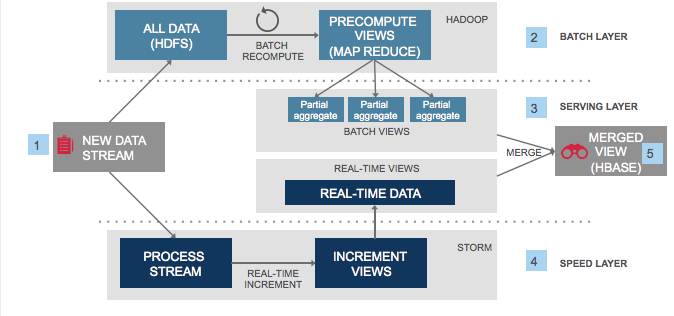
MapReduce, most commonly associated with Apache Hadoop, is a pure batch system that often introduces significant time lag in massaging new data into processed results. To mitigate the delays inherent in MapReduce, the Lambda architecture was conceived to supplement batch results from a MapReduce system with a real-time stream of updates. A serving layer unifies the outputs of the batch and streaming layers, and responds to queries.
The real-time stream is typically a set of pipelines that process new data as and when it is deposited into the system. These pipelines implement windowing queries on new data and then update the serving layer. This architecture has become popular in the last decade because it addresses the stale-output problem of MapReduce systems.
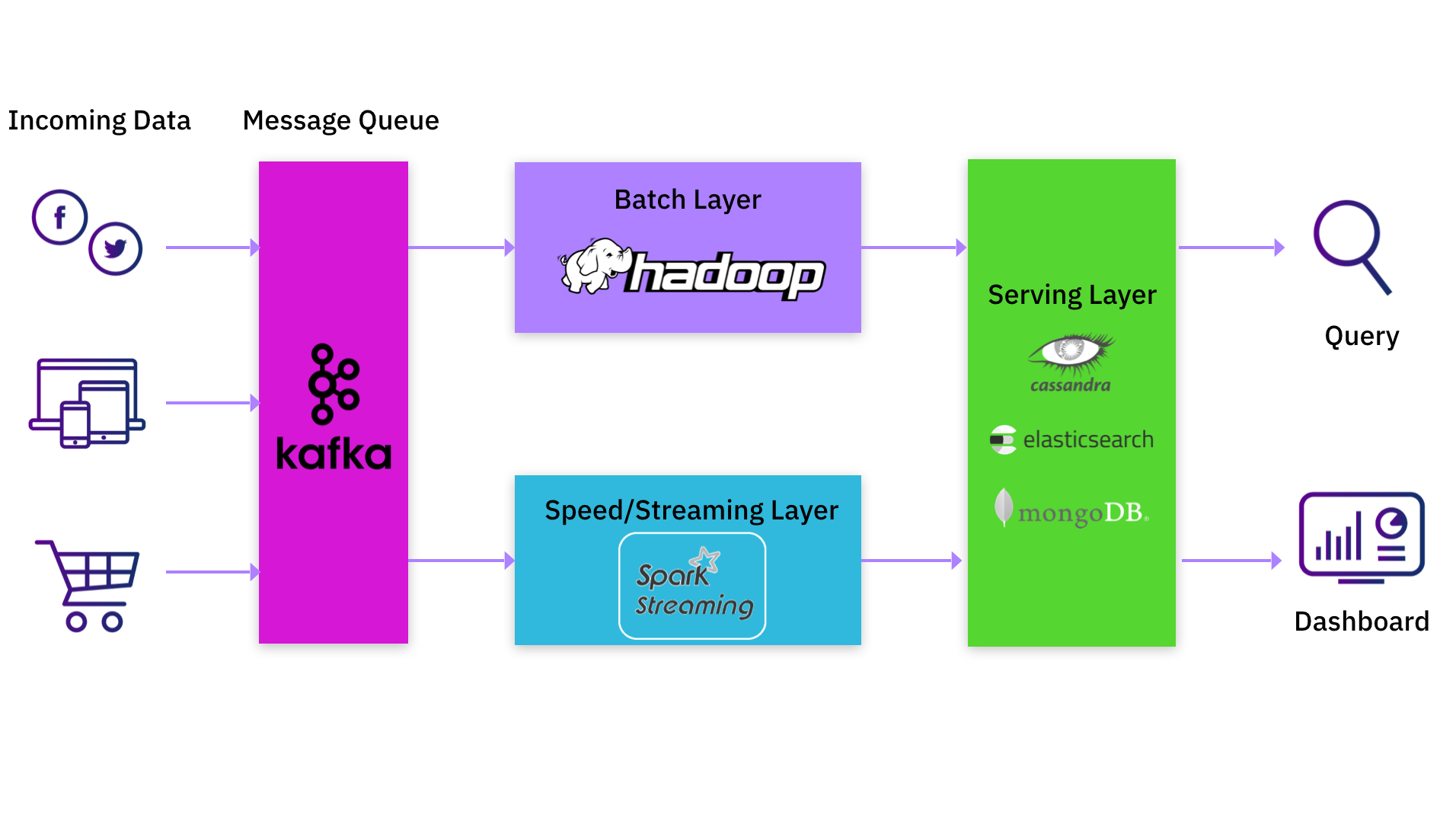
Common Lambda Architectures: Kafka, Spark, and MongoDB/Elasticsearch
If you are a data practitioner, you would probably have either implemented or used a data processing platform that incorporates the Lambda architecture. A common implementation would have large batch jobs in Hadoop complemented by an update stream stored in Apache Kafka. Apache Spark is often used to read this data stream from Kafka, perform transformations, and then write the result to another Kafka log. In most cases, this would not be a single Spark job but a pipeline of Spark jobs. Each Spark job in the pipeline would read data produced by the previous job, do its own transformations, and feed it to the next job in the pipeline. The final output would be written to a serving system like Apache Cassandra, Elasticsearch or MongoDB.
Shortcomings of Lambda Architectures
Being a data practitioner myself, I recognize the value the Lambda architecture offers by allowing data processing in real time. But it isn't an ideal architecture, from my perspective, due to several shortcomings:
The biggest advantage of the Lambda architecture is that data processing occurs when new data arrives in the system, but ironically this is its biggest weakness as well. Most processing in the Lambda architecture happens in the pipeline and not at query time. As most of the complex business logic is tied to the pipeline software, the application developer is unable to make quick changes to the application and has limited flexibility in the ways he or she can use the data. Having to maintain a pipeline just slows you down.
https://www.puncsky.com/notes/83-lambda-architecturebatch view = function(all data at the batching job's execution time)
realtime view = function(realtime view, new data)
query = function(batch view. realtime view)
Lambda architecture = CQRS (batch layer + serving layer) + speed layer
https://www.mapr.com/developercentral/lambda-architecture
- Fault-tolerance against hardware failures and human errors
- Support for a variety of use cases that include low latency querying as well as updates
- Linear scale-out capabilities, meaning that throwing more machines at the problem should help with getting the job done
- Extensibility so that the system is manageable and can accommodate newer features easily
http://lambda-architecture.net/
The LA aims to satisfy the needs for a robust system that is fault-tolerant, both against hardware failures and human mistakes, being able to serve a wide range of workloads and use cases, and in which low-latency reads and updates are required. The resulting system should be linearly scalable, and it should scale out rather than up.
- All data entering the system is dispatched to both the batch layer and the speed layer for processing.
- The batch layer has two functions: (i) managing the master dataset (an immutable, append-only set of raw data), and (ii) to pre-compute the batch views.
- The serving layer indexes the batch views so that they can be queried in low-latency, ad-hoc way.
- The speed layer compensates for the high latency of updates to the serving layer and deals with recent data only.
- Any incoming query can be answered by merging results from batch views and real-time views.
it was noted that using a flexible streaming framework such asApache Samza could provide some of the same benefits as batch processing without the latency. Such a streaming framework could allow for collecting and processing arbitrarily large windows of data, accommodate blocking, and handle state.
https://www.infoq.com/articles/lambda-architecture-scalable-big-data-solutions
https://voltdb.com/blog/simplifying-complex-lambda-architecture
one of the more common use cases of Lambda-based applications is log ingestion and accompanying analytics. “Logs” in this context could be general log collection, website clickstream logging, VPN access logs, or the popular Twitter tweet stream collection.
Log messages often are created at a high velocity. They are immutable and usually are time-tagged or time ordered. This is the "fast data" that is captured and harvested - it is this data that is ingested by both Lambda’s speed layer and batch layer, usually in parallel, by way of message queues and streaming systems (e.g., Kafka and Storm). The ingestion of each log message does not require a response to the entity that delivered the data - it is a one-way data pipeline.
https://www.linkedin.com/pulse/lambda-architecture-practice-bo-yang
Option 1. Hadoop + Spark Streaming + Memory Storage + Columnar Storage
This is the most common implementation, and fits many companies if you have good big data developers.
People use Spark Streaming to compute realtime data and save the latest data in memory storage like Redis or MemSQL.
Then there is hourly batch job to save data into Hadoop using columnar storage format like Parquet. Querying data is a little complex here. People usually build two query systems to query realtime (memory storage) data and historical data separately (columnar storage).
People use Spark Streaming to compute realtime data and save the latest data in memory storage like Redis or MemSQL.
Then there is hourly batch job to save data into Hadoop using columnar storage format like Parquet. Querying data is a little complex here. People usually build two query systems to query realtime (memory storage) data and historical data separately (columnar storage).
Pros: Flexible and Powerful. You can do complicated computation and pre-aggregation before saving to data storage. Also you can use SQL on Hadoop technologies to query historical data easily.
Cons: Complex and high development cost. Also the two query systems for realtime data and historical data is a pain in some cases.
Kudu is a new storage system developed by Cloudera. The purpose is still using Hadoop ecosystem to build Lambda Architecture, but providing a one-fits-all storage solution for both realtime data and historical data. Kudu makes some tradeoff to increase reading throughput while keep ability of fast random access.
Pros: Simple, since there is no need to maintain two storage systems for realtime and historcial data. All data is stored in one system (Kudu), and you will need only one query system based on Kudu. It is also Hadoop friendly.
Cons: Still in beta and not production ready. It will need time to get more mature and stable.
Lambda架构由Storm的作者Nathan Marz提出。 旨在设计出一个能满足实时大数据系统关键特性的架构,具有高容错、低延时和可扩展等特性。
Lambda架构整合离线计算和实时计算,融合不可变性(Immutability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,HBase等各类大数据组件。
Q6:1号店对新登陆用户做什么推荐处理? 主题推荐人工介入量有多大?1号店对其推荐算法出过转化率外,从算法角度会关心哪些指标?
新用户冷启动,采用两个策略
- 数据平滑
- 热销优质商品补充
推荐最重要的是看排序效果,主要是推荐位置的转换率。
Q8:HBase热点问题怎么解决的呢?是分析key的分布,然后写脚本split么?
基本思路一样,写工具检测。重点在request量,不在key的分布。
Q9:批处理层向服务层推送离线计算结果的周期是怎样的?会因数据量大而对线上的HBase造成冲击吗?
目前是一天一次,冲击不大。 1、错峰; 2、bulkload;3、读写分离。