Master: Chubby master consists of multiple replicas, with one of them getting elected as the master using distributed consensus protocol like paxos. All replicas also grant a lease to the master, during which they don’t elect a new master.
Once the master is elected, it is responsible for writing to the database any persistent state that it needed, which is then replicated at other replicas. A write needs to be replicated at majority before being acknowledged back to the client. A read can be served back to the client by the master as long as the lease hasn’t expired — this indicates that there is no other master around.
If the master fails, consensus protocol is again run to elect a new master.
Client: A chubby cell serves thousands of clients, so these clients are connecting to a master for all the coordination needs. Clients use DNS to find the master. Replicas respond to clients issuing DNS queries by redirecting the clients to the current master. Once client finds the master, all requests go to that master. Clients run the locking protocol on application’s behalf and notify application of certain events such as master fail-over has occurred.
File based interface
Chubby exports UNIX file system like APIs. Files and directories are called nodes. There are no links allowed in the system. Nodes can be permanent or ephemeral. Ephemeral nodes go away as no client using the node go away. A file can be opened in a read/write mode indicating the exclusivity. Clients get a handle to the given node. The following metadata is also allocated per node:
Instance number — always increasing for the same name
Content generation number — Increased anytime content is overwritten
Lock generation number — Increases when lock transitions from free to held
There also ACLs on nodes like in a traditional file system for controlling access and an ACL number increases on ACL changes.
Locks, Lock-Delays and Sequencers
A client can create a node/file in a write(exclusive) or read(shared) mode. All the locks are advisory i.e. participating entities need to follow the locking protocol for accesses the distributed critical section. Having a lock on the file, doesn’t prevent unfettered accesses to the file.
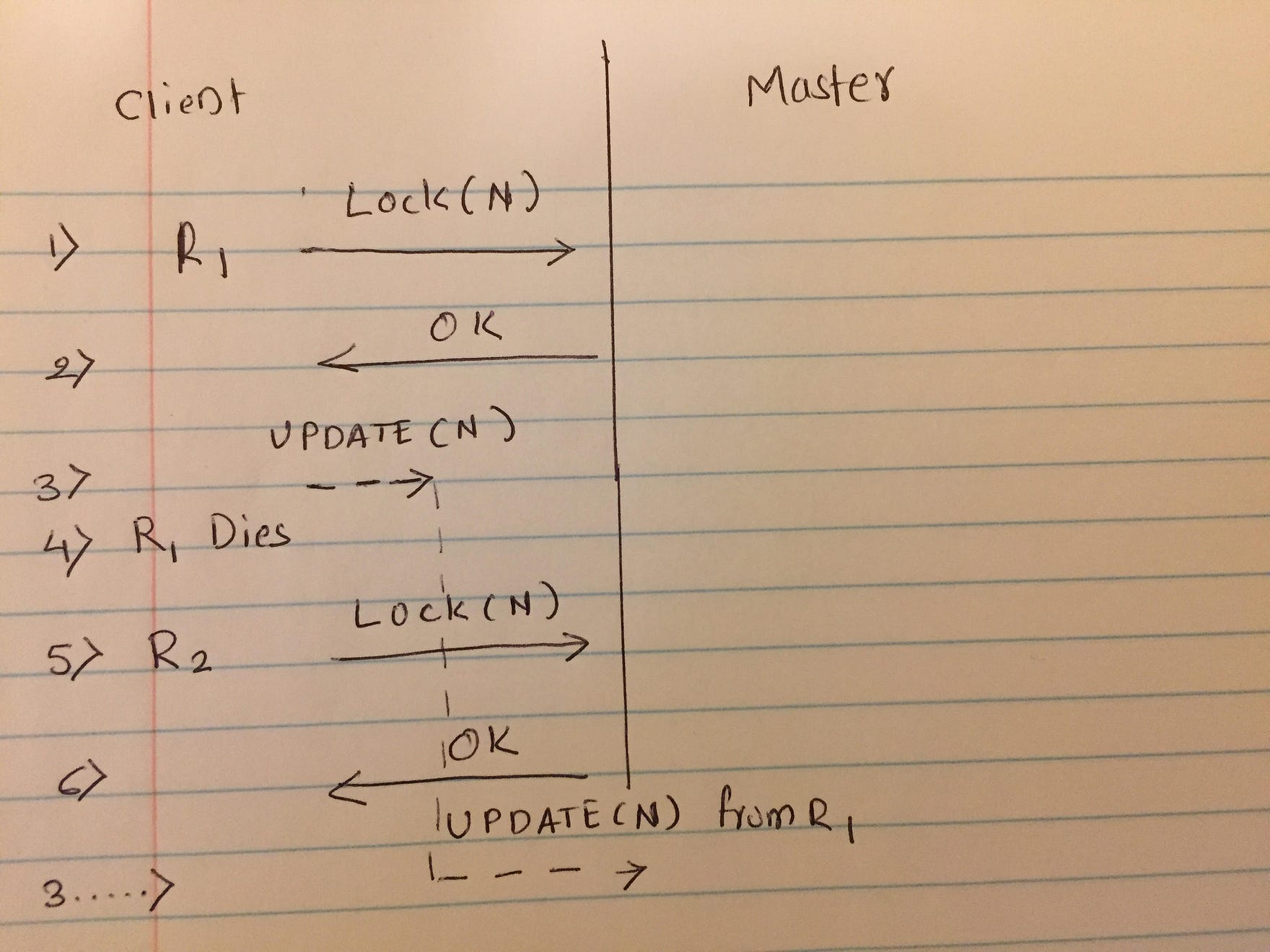
One of the issues with locking in distributed systems is that applications holding locks can die. Consider the following example, where R1 ends up accessing data in an inconsistent manner. In the last step(after 6), update from R1 lands on the master and can corrupt data. R1 does not have a valid lock at that time because it died in step 4 and master then granted the lock on N to client R2 in the meanwhile.
Update from step 3 B=by R1 arrives at master somewhat late. By that time master has already granted the lock on N to another client R2.
One of the ways this is handled is using a lock-delay. When an application holding the lock dies without releasing the lock, for some configurable time, no one else gets a lock on the locks held by the now-defunct application. This makes for a simple and effective(but not perfect) solution where the client can specify the threshold upto which a faulty application can hold a lock.
Another possible solution that Chubby provides is a sequencer based checking. When a client acquires a lock, it can request for sequencer from the chubby master. This is a string that consists of lock name, lock generation number(that changes on every transition from free to held) and the mode of acquisition. This string can be passed on to the modules needing the lock for protected transactions. These modules can check for the validity of the lock using sequencers by checking against the chubby master or using the module’s chubby cache.
Detection of changes using events
Chubby also allows some small aspects of a publish and subscribe mechanisms. Files in chubby also allow for storing a small amount of data which makes it more effective than just for indicating whether a lock was taken or not. As we discussed earlier, clients are interested in knowing when a new master has been elected or when the contents of the lock that they are using have changed. This is accomplished using events and callbacks that are registered at the time of opening of the files. The following events are used:
File contents have changed: Used to describe the new locations for the given service
Child node added to a directory: Used for describe addition of a new replica
Chubby master fail-over: Used for client to go into recovery mode
Invalid Handle: Some communication issues
Electing a primary using Chubby
Using the mechanisms described so far, client can now elect a primary. It is fairly straightforward to do:
All the entities that want to become a master, try to open a file in write mode.
Only one of those get the write mode access and others fail.
The one with write access, then writes its identity to the file
All the others get the file modification event and know about the the current master now.
Primary uses either a sequencer or a lock-delay based mechanism to ensure that out-of-order messages don’t cause inconsistent access and services can confirm if the sequencer for the current master is valid or not.
Caching and KeepAlive calls
Clients keep a cache that be used for reading and is always consistent. For writes, the write is propagated to the master and doesn’t complete until master acknowledges it. Master maintains state information about all the clients and hence can invalidate a client’s cache if someone else writes to the same file. The client that issued the write in such cases is blocked until all invalidations have been sent to the other clients and acknowledged by them.
There are KeepAlive calls that client makes to the master. At any point, for a well behaving client, there will always be one outstanding KeepAlive call at the master. Basically a client acknowledges master’s response by issuing the next KeepAlive call. Server can send some information back as a response of this call at a later time e.g. an invalidation can be sent to the client as response of a prior KeepAlive call. Client will see the response and then invalidate its own cache and then open another KeepAlive call at the master for future communication from the master. Another advantage of this mechanism is that no additional holes need to be punched in the firewalls. Outbound calls from clients are generally allowed and clients don’t need to open and listen on ports for the master to initiate connections to clients.
Sessions
We discussed KeepAlive RPCs in the last section. These establish a client-master chubby session. When a client makes this KeepAlive call to the master, master blocks this call. Master then also assigns a lease to the client. This master lease guarantees that the master won’t unilaterally terminate this session. When the lease is about to expire or if there is some event to which the client is subscribed, master can use this blocked call for sending the information back. In the former case, master may extend the lease or in the later case master can send information such as which files have changed.
Clients cannot be sure if the master is alive and the lease that the client has is still valid. So clients keep a slightly smaller local lease timeout. If this timeout occurs and master hasn’t responded, then client isn’t sure if the master is still around and if its local lease is valid. At this time, client considers that it’s session is in jeopardy and starts the grace period. It also disables its cache. If client heard back from the master during the grace period(45s), then the client can enable the cache once more. If client doesn’t hear back from the master then it is assumed the master is inaccessible and clients return errors back to the application. Applications get informed about both jeopardy andexpired events from the chubby client library.
a. 便于已有系统的移植, 对于系统初期设计没有考虑到分布式一致性问题, 后期如果基于Paxos库, 难度和修改比较大. 而如果基于lock service就容易的多。 b. Chubby不但用于elect master, 并且提供机制公布结果(mechanism for advertising the results), 还能够通过consistent client caching机制(rather than time-based caching)来保证所有client端cache的一致性. 这也是为什么Chubby作为name server非常成功的原因。 c. 基于锁的接口更为程序员所熟悉。 d. 分布式协同算法使用quorums做决策, 如果基于paxos库, 要求用户使用时必须先搭建集群.而基于lock service, 只有一个客户端也能成功取到锁。
a. Chubby锁经常保护由其他服务实现的资源,而不仅仅是与锁关联的文件 b. 不想强迫用户在他们为了调试和管理而访问这些锁定的文件时关闭应用程序 c. 开发者用常规的方式来执行错误检测,例如"lock X is held”, 所以他们从强制检查中受益很少. 意思一般都会先check “lock X is held”, 不会直接访问文件通过强制检查来check lock。