All indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index. If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.
② 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
对于第三点“DB可用性”问题,我们目前采用一主两从的方式,同时分机房部署,Master和Slave之间采用半同步方式[5]同步数据。同时使用公司Atlas数据库中间件(已开源,改名为DBProxy)做主从切换。当然这种方案在一些情况会退化成异步模式,甚至在非常极端情况下仍然会造成数据不一致的情况,但是出现的概率非常小。如果你的系统要保证100%的数据强一致,可以选择使用“类Paxos算法”实现的强一致MySQL方案,如MySQL 5.7前段时间刚刚GA的MySQL Group Replication。但是运维成本和精力都会相应的增加,根据实际情况选型即可。
Ex: Twitter’s Snowflake, a Thrift service that uses Apache ZooKeeper to coordinate nodes and then generates 64-bit unique IDs
Pros:
Snowflake IDs are 64-bits, half the size of a UUID
Can use time as first component and remain sortable
Distributed system that can survive nodes dying
Cons:
Would introduce additional complexity and more ‘moving parts’ (ZooKeeper, Snowflake servers) into our architecture
DB Ticket Servers
Uses the database’s auto-incrementing abilities to enforce uniqueness. Flickr uses this approach, but with two ticket DBs (one on odd numbers, the other on even) to avoid a single point of failure.
Pros:
DBs are well understood and have pretty predictable scaling factors
Cons:
Can eventually become a write bottleneck (though Flickr reports that, even at huge scale, it’s not an issue).
An additional couple of machines (or EC2 instances) to admin
If using a single DB, becomes single point of failure. If using multiple DBs, can no longer guarantee that they are sortable over time.
Of all the approaches above, Twitter’s Snowflake came the closest, but the additional complexity required to run an ID service was a point against it. Instead, we took a conceptually similar approach, but brought it inside PostgreSQL.
Our sharded system consists of several thousand ‘logical’ shards that are mapped in code to far fewer physical shards. Using this approach, we can start with just a few database servers, and eventually move to many more, simply by moving a set of logical shards from one database to another, without having to re-bucket any of our data. We used Postgres’ schemas feature to make this easy to script and administrate.
RingBuffer is an array,each item of that array is called 'slot', every slot keeps a uid or a flag(Double RingBuffer). The size of RingBuffer is 2^n, where n is positive integer and equal or greater than bits of sequence. Assign bigger value to boostPower if you want to enlarge RingBuffer to improve throughput.
Tail & Cursor pointer
Tail Pointer
Represents the latest produced UID. If it catches up with cursor, the ring buffer will be full, at that moment, no put operation should be allowed, you can specify a policy to handle it by assigning property rejectedPutBufferHandler.
Cursor Pointer
Represents the latest already consumed UID. If cursor catches up with tail, the ring buffer will be empty, and any take operation will be rejected. you can also specify a policy to handle it by assigning property rejectedTakeBufferHandler.
CachedUidGenerator used double RingBuffer,one RingBuffer for UID, another for status(if valid for take or put)
Array can improve performance of reading, due to the CUP cache mechanism. At the same time, it brought the side effect of 「False Sharing」, in order to solve it, cache line padding is applied.
RingBuffer filling
Initialization padding During RingBuffer initializing,the entire RingBuffer will be filled.
In-time filling Whenever the percent of available UIDs is less than threshold paddingFactor, the fill task is triggered. You can reassign that threshold in Spring bean configuration.
Periodic filling Filling periodically in a scheduled thread. ThescheduleInterval can be reassigned in Spring bean configuration.
<beanid="cachedUidGenerator"class="com.baidu.fsg.uid.impl.CachedUidGenerator">
<propertyname="workerIdAssigner"ref="disposableWorkerIdAssigner" />
<!-- The config below is option --><!-- Specified bits & epoch as your demand. No specified the default value will be used -->
<propertyname="timeBits"value="29"/>
<propertyname="workerBits"value="21"/>
<propertyname="seqBits"value="13"/>
<propertyname="epochStr"value="2016-09-20"/>
<!-- RingBuffer size, to improve the throughput. --><!-- Default as 3. Sample: original bufferSize=8192, after boosting the new bufferSize= 8192 << 3 = 65536 -->
<propertyname="boostPower"value="3"></property>
<!-- In-time padding, available UIDs percentage(0, 100) of the RingBuffer, default as 50 --><!-- Sample: bufferSize=1024, paddingFactor=50 -> threshold=1024 * 50 / 100 = 512. --><!-- When the rest available UIDs < 512, RingBiffer will be padded in-time -->
<propertyname="paddingFactor"value="50"></property>
<!-- Periodic padding --><!-- Default is disabled. Enable as below, scheduleInterval unit as Seconds. -->
<propertyname="scheduleInterval"value="60"></property>
<!-- Policy for rejecting put on RingBuffer -->
<propertyname="rejectedPutBufferHandler"ref="XxxxYourPutRejectPolicy"></property>
<!-- Policy for rejecting take from RingBuffer -->
<propertyname="rejectedTakeBufferHandler"ref="XxxxYourTakeRejectPolicy"></property>
</bean>
<!-- Disposable WorkerIdAssigner based on Database -->
<beanid="disposableWorkerIdAssigner"class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner" />
UidGenerator is a Java implemented, Snowflake based unique ID generator. It works as a component, and allows users to override workId bits and initialization strategy. As a result, it is much more suitable for virtualization environment, such as docker. Besides these, it overcomes concurrency limitation of Snowflake algorithm by consuming future time; parallels UID produce and consume by caching UID with RingBuffer; eliminates CacheLine pseudo sharing, which comes from RingBuffer, via padding. And finally, it can offer over 6 million QPS per single instance.
** Snowflake algorithm:** An unique id consists of worker node, timestamp and sequence within that timestamp. Usually, it is a 64 bits number(long), and the default bits of that three fields are as follows:
sign(1bit)
The highest bit is always 0.
delta seconds (28 bits)
The next 28 bits, represents delta seconds since a customer epoch(2016-05-20). The maximum time will be 8.7 years.
worker id (22 bits)
The next 22 bits, represents the worker node id, maximum value will be 4.2 million. UidGenerator uses a build-in database based worker id assigner when startup by default, and it will dispose previous work node id after reboot. Other strategy such like 'reuse' is coming soon.
sequence (13 bits)
the last 13 bits, represents sequence within the one second, maximum is 8192 per second by default.
/**
* Get the UIDs in the same specified second under the max sequence
*
* @param currentSecond
* @return UID list, size of {@link BitsAllocator#getMaxSequence()} + 1
*/protectedList<Long>nextIdsForOneSecond(longcurrentSecond){// Initialize result list size of (max sequence + 1)intlistSize=(int)bitsAllocator.getMaxSequence()+1;List<Long>uidList=newArrayList<>(listSize);// Allocate the first sequence of the second, the others can be calculated with the offsetlongfirstSeqUid=bitsAllocator.allocate(currentSecond-epochSeconds,workerId,0L);for(intoffset=0;offset<listSize;offset++){uidList.add(firstSeqUid+offset);}returnuidList;}
public class BufferPaddingExecutor {
/** Whether buffer padding is running */ private final AtomicBoolean running;
/** We can borrow UIDs from the future, here store the last second we have consumed */ private final PaddedAtomicLong lastSecond;
/** RingBuffer & BufferUidProvider */
private final RingBuffer ringBuffer; private final BufferedUidProvider uidProvider;
/** Padding immediately by the thread pool */
private final ExecutorService bufferPadExecutors;
/** Padding schedule thread */
private final ScheduledExecutorService bufferPadSchedule;
/** Schedule interval Unit as seconds */
private long scheduleInterval = DEFAULT_SCHEDULE_INTERVAL;
public BufferPaddingExecutor(RingBuffer ringBuffer, BufferedUidProvider uidProvider, boolean usingSchedule) {
this.running = new AtomicBoolean(false);
this.lastSecond = new PaddedAtomicLong(TimeUnit.MILLISECONDS.toSeconds(System.currentTimeMillis()));
this.ringBuffer = ringBuffer;
this.uidProvider = uidProvider;
// initialize thread pool
int cores = Runtime.getRuntime().availableProcessors();
bufferPadExecutors = Executors.newFixedThreadPool(cores * 2, new NamingThreadFactory(WORKER_NAME));
public void paddingBuffer() {
LOGGER.info("Ready to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);
// is still running if (!running.compareAndSet(false, true)) {
LOGGER.info("Padding buffer is still running. {}", ringBuffer);
return;
}
// fill the rest slots until to catch the cursor
boolean isFullRingBuffer = false;
while (!isFullRingBuffer) {
List<Long> uidList = uidProvider.provide(lastSecond.incrementAndGet());
for (Long uid : uidList) {
isFullRingBuffer = !ringBuffer.put(uid);
if (isFullRingBuffer) {
break;
}
}
}
// not running now running.compareAndSet(true, false);
LOGGER.info("End to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);
}
该用于填充RingBuffer的执行者最主要的执行方法如下
/**
* Padding buffer fill the slots until to catch the cursor
* <p>
* 该方法被即时填充和定期填充所调用
*/publicvoidpaddingBuffer(){LOGGER.info("{} Ready to padding buffer lastSecond:{}. {}",this,lastSecond.get(),ringBuffer);// is still running// 这个是代表填充executor在执行,不是RingBuffer在执行。为免多个线程同时扩容。if(!running.compareAndSet(false,true)){LOGGER.info("Padding buffer is still running. {}",ringBuffer);return;}// fill the rest slots until to catch the cursorbooleanisFullRingBuffer=false;while(!isFullRingBuffer){// 填充完指定SECOND里面的所有UID,直至填满List<Long>uidList=uidProvider.provide(lastSecond.incrementAndGet());for(Longuid:uidList){isFullRingBuffer=!ringBuffer.put(uid);if(isFullRingBuffer){break;}}}// not running nowrunning.compareAndSet(true,false);LOGGER.info("End to padding buffer lastSecond:{}. {}",lastSecond.get(),ringBuffer);}
/**
* Start executors such as schedule
*/publicvoidstart(){if(bufferPadSchedule!=null){bufferPadSchedule.scheduleWithFixedDelay(this::paddingBuffer,scheduleInterval,scheduleInterval,TimeUnit.SECONDS);}}
在take()方法中检测到达到填充阈值时,会进行异步填充。
/**
* Padding buffer in the thread pool
*/publicvoidasyncPadding(){bufferPadExecutors.submit(this::paddingBuffer);}
/** Tail: last position sequence to produce */ private final AtomicLong tail = new PaddedAtomicLong(START_POINT);
/** Cursor: current position sequence to consume */ private final AtomicLong cursor = new PaddedAtomicLong(START_POINT);
/** Threshold for trigger padding buffer*/
private final int paddingThreshold;
private BufferPaddingExecutor bufferPaddingExecutor;
* Put an UID in the ring & tail moved<br>
* We use 'synchronized' to guarantee the UID fill in slot & publish new tail sequence as atomic operations<br>
*
* <b>Note that: </b> It is recommended to put UID in a serialize way, cause we once batch generate a series UIDs and put
* the one by one into the buffer, so it is unnecessary put in multi-threads
*
* @param uid
* @return false means that the buffer is full, apply {@link RejectedPutBufferHandler}
public synchronized boolean put(long uid) {
long currentTail = tail.get();
long currentCursor = cursor.get();
// tail catches the cursor, means that you can't put any cause of RingBuffer is full
long distance = currentTail - (currentCursor == START_POINT ? 0 : currentCursor);
if (distance == bufferSize - 1) {
rejectedPutHandler.rejectPutBuffer(this, uid);
return false;
}
// 1. pre-check whether the flag is CAN_PUT_FLAG
int nextTailIndex = calSlotIndex(currentTail + 1);
if (flags[nextTailIndex].get() != CAN_PUT_FLAG) {
rejectedPutHandler.rejectPutBuffer(this, uid);
return false;
}
// 2. put UID in the next slot
// 3. update next slot' flag to CAN_TAKE_FLAG
// 4. publish tail with sequence increase by one
slots[nextTailIndex] = uid;
flags[nextTailIndex].set(CAN_TAKE_FLAG);
tail.incrementAndGet();
// The atomicity of operations above, guarantees by 'synchronized'. In another word,
// the take operation can't consume the UID we just put, until the tail is published(tail.incrementAndGet())
return true;
}
* Take an UID of the ring at the next cursor, this is a lock free operation by using atomic cursor<p>
*
* Before getting the UID, we also check whether reach the padding threshold,
* the padding buffer operation will be triggered in another thread<br>
* If there is no more available UID to be taken, the specified {@link RejectedTakeBufferHandler} will be applied<br>
public long take() {
// spin get next available cursor
long currentCursor = cursor.get();
long nextCursor = cursor.updateAndGet(old -> old == tail.get() ? old : old + 1);
// check for safety consideration, it never occurs
Assert.isTrue(nextCursor >= currentCursor, "Curosr can't move back");
// trigger padding in an async-mode if reach the threshold
long currentTail = tail.get();
if (currentTail - nextCursor < paddingThreshold) {
LOGGER.info("Reach the padding threshold:{}. tail:{}, cursor:{}, rest:{}", paddingThreshold, currentTail,
nextCursor, currentTail - nextCursor); bufferPaddingExecutor.asyncPadding();
}
// cursor catch the tail, means that there is no more available UID to take
if (nextCursor == currentCursor) {
rejectedTakeHandler.rejectTakeBuffer(this);
}
// 1. check next slot flag is CAN_TAKE_FLAG
int nextCursorIndex = calSlotIndex(nextCursor);
Assert.isTrue(flags[nextCursorIndex].get() == CAN_TAKE_FLAG, "Curosr not in can take status");
// 2. get UID from next slot
// 3. set next slot flag as CAN_PUT_FLAG.
long uid = slots[nextCursorIndex];
flags[nextCursorIndex].set(CAN_PUT_FLAG);
// Note that: Step 2,3 can not swap. If we set flag before get value of slot, the producer may overwrite the
// slot with a new UID, and this may cause the consumer take the UID twice after walk a round the ring
return uid;
}
protected int calSlotIndex(long sequence) {
return (int) (sequence & indexMask);
}
protected void discardPutBuffer(RingBuffer ringBuffer, long uid) {
LOGGER.warn("Rejected putting buffer for uid:{}. {}", uid, ringBuffer);
}
protected void exceptionRejectedTakeBuffer(RingBuffer ringBuffer) {
LOGGER.warn("Rejected take buffer. {}", ringBuffer);
throw new RuntimeException("Rejected take buffer. " + ringBuffer);
}
private PaddedAtomicLong[] initFlags(int bufferSize) {
PaddedAtomicLong[] flags = new PaddedAtomicLong[bufferSize];
for (int i = 0; i < bufferSize; i++) {
flags[i] = new PaddedAtomicLong(CAN_PUT_FLAG);
}
CREATETABLEWORKER_NODE
(
ID BIGINTNOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INTNOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATENOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMPNOT NULL COMMENT 'modified time',
CREATED TIMESTAMPNOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)
COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;
There are two implements of UidGenerator: DefaultUidGenerator, CachedUidGenerator.
For performance sensitive application, CachedUidGenerator is recommended.
There are two implements of UidGenerator: DefaultUidGenerator, CachedUidGenerator.
For performance sensitive application, CachedUidGenerator is recommended.
<!-- DefaultUidGenerator -->
<beanid="defaultUidGenerator"class="com.baidu.fsg.uid.impl.DefaultUidGenerator"lazy-init="false">
<propertyname="workerIdAssigner"ref="disposableWorkerIdAssigner"/>
<!-- Specified bits & epoch as your demand. No specified the default value will be used -->
<propertyname="timeBits"value="29"/>
<propertyname="workerBits"value="21"/>
<propertyname="seqBits"value="13"/>
<propertyname="epochStr"value="2016-09-20"/>
</bean>
<!-- Disposable WorkerIdAssigner based on Database -->
<beanid="disposableWorkerIdAssigner"class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner" />
In some systems, you can just keep incrementing the ID from 1, 2, 3 … N. In other systems, we may need to generate the ID as a random string. Usually, there are few requirements for ID generators:
They cannot be arbitrarily long. Let’s say we keep it within 64 bits.
ID is incremented by date. This gives the system a lot of flexibility, e.g. you can sort users by ID, which is same as ordering by register date.
There can be some other requirements, especially when you want to scale the system to support millions or even billions of users.
Single machine
In the simplest case, we can just keep incrementing ID from 1, 2, 3 … N, which in fact is one of the most popular ways to generate ID in many real life projects. If user A’s ID is larger than user B, then we know that A registered later.
However, this approach is hard to scale. Let’s say after one year there are too many users everyday that we have to scale the database to multiple instances. You’ll see that this approach won’t work because it may generate duplicate IDs for different users.
Multiple machine solution
Since within a single timestamp there can also be multiple users, we could solve this with two approaches.
We assign a server ID to each ID generation server and the final ID is a combination of timestamp and the server ID.
We can also allow multiple requests within a single timestamp on a single server. We can keep a counter on each server, which indicates how many IDs have been generated in the current timestamp. So the final ID is a combination of timestamp, serverID and the counter.
As mentioned previously, the ID cannot be arbitrarily long so that the counter may end up with only 8 bits for instance. In this case, the server can handle 256 requests within a single timestamp at most. If it frequently exceeds this limit, we need to add more instances.
Clock synchronization
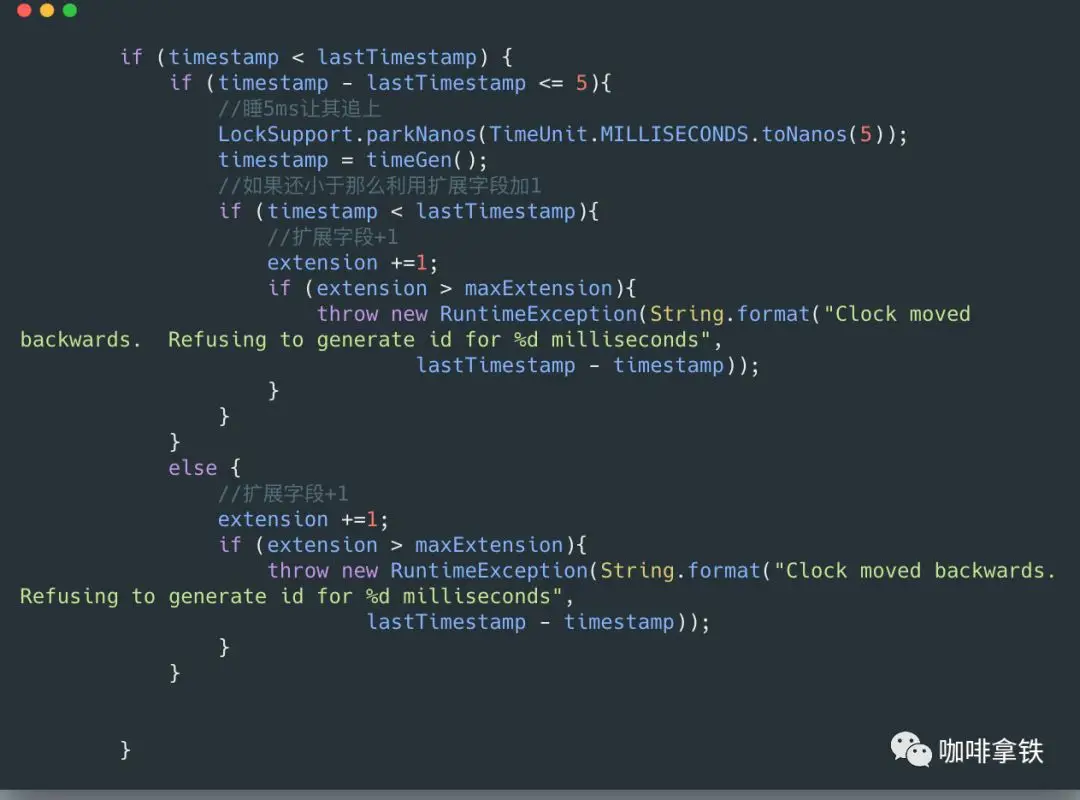
We ignored a crucial problem in the above analysis. In fact, there’s a hidden assumption that all ID generation servers have the same clock to generate the timestamp, which might not be true in distributed systems.
In reality, system clocks can drastically skew in distributed systems, which can cause our ID generators provide duplicate IDs or IDs with incorrect order. Clock synchronization is out of the scope of this discussion, however, it’s important for you to know such issue in this system. There are quite a few ways to solve this issue, check NTP if you want to know more about it.
Write a custom server: This is easy, basically create a service that give a increasing ID. But very hard to cluster this and behavior in case of a failure is complicated.
"A timestamp, worker number and sequence number": Twitter Guys created solution based on "a timestamp, worker number and sequence number" (this is kind of that we use as well, except that ran few dedicated servers for this)http://engineering.twitter.com/2010/06/announcing-snowflake.html
IMHO, "a timestamp, worker number and sequence number" is the best option. Only downside of this is that this assumes that broker nodes are loosely synced in time. Only other option I see is Zookeeper.
You can also use Zookeeper. It provides methods for creating sequence nodes (appended to znode names, thou I prefer using version numbers of the nodes). Be careful with this one thou: if you don't want missed numbers in your sequence, it may not be what you want.
2) token-ring All nodes in this system are connected as a loop. This design is similar to the previous one, except for the master node is the one which has the token. A nice point is that it avoids the bottleneck. The details to deal with the failures such as the lost token could borrow from the token-ring network.
On the other hand, I tried to come up with a centralized system with strong consistency using mechanisms such as Paxos, or the quorum-based R/W configuration. Furthermore, one may look at Kafka, a system that implements distributed commit logs.
Write a custom server: This is easy, basically create a service that give a increasing ID. But very hard to cluster this and behavior in case of a failure is complicated.
"A timestamp, worker number and sequence number": Twitter Guys created solution based on "a timestamp, worker number and sequence number" (this is kind of that we use as well, except that ran few dedicated servers for this)http://engineering.twitter.com/2010/06/announcing-snowflake.html
IMHO, "a timestamp, worker number and sequence number" is the best option. Only downside of this is that this assumes that broker nodes are loosely synced in time. Only other option I see is Zookeeper.