https://mp.weixin.qq.com/s/F944TaR8y3M71SmMqb0Iew
X. Wide Column Database
https://www.dataversity.net/wide-column-database/#
Wide Column Databases, or Column Family Databases, refers to a category of NoSQL databases that works well for storing enormous amounts of data that can be collected. Its architecture uses persistent, sparse matrix, multi-dimensional mapping (row-value, column-value, and timestamp) in a tabular format meant for massive scalability (over and above the petabyte scale).
http://maxivak.com/rdbms-vs-nosql-databases/
Key-Value Store – It has a Big Hash Table of keys & values {Example- Riak, Amazon S3 (Dynamo)}
https://ayende.com/blog/4500/that-no-sql-thing-column-family-databases
Some of the difference is storing data by rows (relational) vs. storing data by columns (column family databases). But a lot of the difference is conceptual in nature
https://dzone.com/articles/a-primer-on-open-source-nosql-databases
Key Value Database
Key-Value database allows the user to store data in simple <key> : <value> format, where key is used to retrieve the value from the table.
 DynamoDB
DynamoDB
Redis
HBase
Document-oriented Database
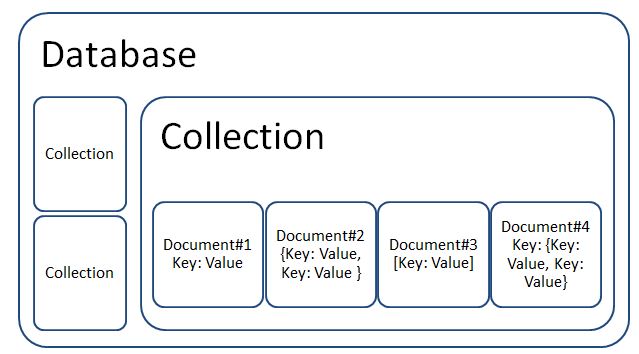
The table which contains a group of documents is called as a "Collection".
The Database contains many Collections. A Collection contains many documents. Each document might contain a JSON document or XML document or YAML or even a Word Document.Document databases are suitable for Web based applications and applications exposing RESTful services.
Example
MongoDB
CouchBaseDB
Brewer's CAP-Theorem
CAP theorem recommends properties for any shared-data systems. They are: Consistency, Availability & Partition. It also recommends that to be qualified as a shared-data system, a database must support at most two of these properties.
A.2.1 Consistency
In a distributed database system, all the nodes must see the same data at the same time.
A.2.2 Availability
The database system must be available to service a request received. Basically, the DBMS must be a high available system.
A.2.3 Partition Tolerance
The database system must continue to operate despite arbitrary partitioning due to network failures.
http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
http://blog.jobbole.com/1344/
https://en.wikipedia.org/wiki/Multi-master_replication
If one master fails, other masters continue to update the database.
Masters can be located in several physical sites, i.e. distributed across the network.
Disadvantages
Most multi-master replication systems are only loosely consistent, i.e. lazy and asynchronous, violating ACID properties.
Eager replication systems are complex and increase communication latency.
Issues such as conflict resolution can become intractable as the number of nodes involved rises and latency increases.
http://dataconomy.com/sql-vs-nosql-need-know/
如何用消息系统避免分布式事务?
 3 使用消息队列来避免分布式事务
3 使用消息队列来避免分布式事务
3.1 如何可靠保存凭证(消息)
http://docs.oracle.com/cd/B28359_01/server.111/b28326/repmaster.htm
Storm Applied: Strategies for real-time event processing
“Which one of these NoSQL solutions should I pick?” This is the wrong approach. Instead, ask yourself questions about the functionality you’re implementing and the requirements they impose on any data storage solution.
http://stackoverflow.com/questions/3010224/mongodb-vs-redis-vs-cassandra-for-a-fast-write-temporary-row-storage-solution
http://www.datastax.com/wp-content/themes/datastax-2014-08/files/NoSQL_Benchmarks_EndPoint.pdf
NoSQL和SQL的选用
https://www.jiuzhang.com/qa/1836/
我对nosql选择的理解是如果期待较容易的获得更高的写负荷与高可用(sharding & node transform),并且数据结构化不强可能添加新column的情况,选择nosql就是最佳选择。同时找出那些需要强事务性的安排在sql中。
TODO
https://loonytek.com/2017/05/04/why-analytic-workloads-are-faster-on-columnar-databases/
Analytic workloads comprise of operations like scans, joins, aggregations etc. These operations are concerned with data retrieval, some computations over the values stored in table cells, and predicate evaluation. Such operations typically touch a very large number of rows but only a few columns in the table. As far as I understand, this is the fundamental difference between analytic queries and OLTP-style operations
1. Organization of Data
4. Late Materialization
X. Wide Column Database
https://www.dataversity.net/wide-column-database/#
Wide Column Databases, or Column Family Databases, refers to a category of NoSQL databases that works well for storing enormous amounts of data that can be collected. Its architecture uses persistent, sparse matrix, multi-dimensional mapping (row-value, column-value, and timestamp) in a tabular format meant for massive scalability (over and above the petabyte scale).
Good Wide Column Database use cases include:
- Sensor Logs [Internet of Things (IOT)]
- User preferences
- Geographic information
- Reporting systems
- Time Series Data
- Logging and other write heavy applications
Wide Column Databases are not the preferred choice for applications with ad-hoc query patterns, high level aggregations and changing database requirements. This type of data store does not keep good data lineage.
A wide column store is a type of NoSQL database. It uses tables, rows, and columns, but unlike a relational database, the names and format of the columns can vary from row to row in the same table. A wide column store can be interpreted as a two-dimensional key-value store.[1]
As such two-level structures do not use a columnar data layout, wide column stores such as Bigtable and Apache Cassandra are not column stores in the original sense of the term. In genuine column stores, a columnar data layout is adopted such that each column is stored separately on disk. Wide column stores do often support the notion of column families that are stored separately. However, each such column family typically contains multiple columns that are used together, similar to traditional relational database tables. Within a given column family, all data is stored in a row-by-row fashion, such that the columns for a given row are stored together, rather than each column being stored separately. Wide column stores that support column families are also known as column family databases.
- Strong Consistency: all clients see the same version of the data, even on updates to the dataset – e. g. by means of the two-phase commit protocol (XA transactions), and ACID,
- High Availability: all clients can always find at least one copy of the requested data, even if some of the machines in a cluster is down,
- Partition-tolerance: the total system keeps its characteristic even when being deployed on different servers, transparent to the client.
Many of the NOSQL databases above all have loosened up the requirements on Consistency in order to achieve better Availability and Partitioning. This resulted in systems know as BASE (Basically Available, Soft-state, Eventually consistent). These have no transactions in the classical sense and introduce constraints on the data model to enable better partition schemes
When to use NoSQL
NoSQL can be good when you have the following requirements:
- You plan to deploy a large-scale, high-concurrency database (hundreds of GB, thousands of users);
- Which doesn’t need ACID guarantees;
- Or relationships or constraints;
- Stores a fairly narrow set of data (the equivalent of 5-10 tables in SQL);
- Will be running on commodity hardware (i.e. Amazon EC2);
- Needs to be implemented on a very low budget and “scaled out.”
It is good for most of web sites. For example, Google and Twitter fit very neatly into these requirements. Does it really matter if a few tweets are lost or delayed
When to use SQL Databases (RDBMSs)
Most business systems have very different requirements from web sites like:
- Medium-to-large-scale databases (10-100 GB) with fairly low concurrency (hundreds of users at most);
- ACID (especially the A and C – Atomicity and Consistency) is a hardrequirement;
- Data is highly correlated (hierarchies, master-detail, histories);
- Has to store a wide assortment of data – hundreds or thousands of tables are not uncommon in a normalized schema (more for denormalization tables, data warehouses, etc.);
- Run on high-end hardware;
- Lots of capital available.
High-end SQL databases (SQL Server, Oracle, Teradata, Vertica, etc.) are designed for vertical scaling, they like being on machines with lots and lots of memory, fast I/O through SANs and SSDs, and the occasional horizontal scaling through clustering (HA) and partitioning (HC).
Consistent, Available (CA) Systems have trouble with partitions and typically deal with it with replication. Examples of CA systems include:
- Traditional RDBMSs like Postgres, MySQL, etc (relational)
- Vertica (column-oriented)
- Aster Data (relational)
- Greenplum (relational)
Consistent, Partition-Tolerant (CP) Systems have trouble with availability while keeping data consistent across partitioned nodes. Examples of CP systems include:
- BigTable (column-oriented/tabular)
- Hypertable (column-oriented/tabular)
- HBase (column-oriented/tabular)
- MongoDB (document-oriented)
- Terrastore (document-oriented)
- Redis (key-value)
- Scalaris (key-value)
- MemcacheDB (key-value)
- Berkeley DB (key-value)
Available, Partition-Tolerant (AP) Systems achieve “eventual consistency” through replication and verification. Examples of AP systems include:
- Dynamo (key-value)
- Voldemort (key-value)
- Tokyo Cabinet (key-value)
- KAI (key-value)
- Cassandra (column-oriented/tabular)
- CouchDB (document-oriented)
- SimpleDB (document-oriented)
- Riak (document-oriented)
Key-Value Store – It has a Big Hash Table of keys & values {Example- Riak, Amazon S3 (Dynamo)}
- Riak and Amazon’s Dynamo are the most popular key-value store NoSQL databases.
- Document-based Store- It stores documents made up of tagged elements. {Example- CouchDB}
The data which is a collection of key value pairs is compressed as a document store quite similar to a key-value store, but the only difference is that the values stored (referred to as “documents”) provide some structure and encoding of the managed data. XML, JSON (Java Script Object Notation), BSON (which is a binary encoding of JSON objects) are some common standard encodings.
One key difference between a key-value store and a document store is that the latter embeds attribute metadata associated with stored content, which essentially provides a way to query the data based on the contents. For example, in the above example, one could search for all documents in which “City” is “Noida” that would deliver a result set containing all documents associated with any “3Pillar Office” that is in that particular city.
Apache CouchDB is an example of a document store. CouchDB uses JSON to store data, JavaScript as its query language using MapReduce and HTTP for an API. Data and relationships are not stored in tables as is a norm with conventional relational databases but in fact are a collection of independent documents.
The fact that document style databases are schema-less makes adding fields to JSON documents a simple task without having to define changes first.
- Couchbase and MongoDB are the most popular document based databases.
- Column-based Store- Each storage block contains data from only one column, {Example- HBase, Cassandra}
In column-oriented NoSQL database, data is stored in cells grouped in columns of data rather than as rows of data. Columns are logically grouped into column families. Column families can contain a virtually unlimited number of columns that can be created at runtime or the definition of the schema. Read and write is done using columns rather than rows.
In comparison, most relational DBMS store data in rows, the benefit of storing data in columns, is fast search/ access and data aggregation. Relational databases store a single row as a continuous disk entry. Different rows are stored in different places on disk while Columnar databases store all the cells corresponding to a column as a continuous disk entry thus makes the search/access faster.
For example: To query the titles from a bunch of a million articles will be a painstaking task while using relational databases as it will go over each location to get item titles. On the other hand, with just one disk access, title of all the items can be obtained.
Data Model
- ColumnFamily: ColumnFamily is a single structure that can group Columns and SuperColumns with ease.
- Key: the permanent name of the record. Keys have different numbers of columns, so the database can scale in an irregular way.
- Keyspace: This defines the outermost level of an organization, typically the name of the application. For example, ‘3PillarDataBase’ (database name).
- Column: It has an ordered list of elements aka tuple with a name and a value defined.
The best known examples are Google’s BigTable and HBase & Cassandra that were inspired from BigTable.
BigTable, for instance is a high performance, compressed and proprietary data storage system owned by Google. It has the following attributes:
- Sparse – some cells can be empty
- Distributed – data is partitioned across many hosts
- Persistent – stored to disk
- Multidimensional – more than 1 dimension
- Map – key and value
- Sorted – maps are generally not sorted but this one is
- Google’s BigTable, HBase and Cassandra are the most popular column store based databases.
- Graph-based-A network database that uses edges and nodes to represent and store data. {Example- Neo4J}
Some of the difference is storing data by rows (relational) vs. storing data by columns (column family databases). But a lot of the difference is conceptual in nature
The following concepts are critical to understand how column databases work:
- Column family
- Super columns
- Column
Columns and super columns in a column database are spare, meaning that they take exactly 0 bytes if they don’t have a value in them. Column families are the nearest thing that we have for a table, since they are about the only thing that you need to define upfront. Unlike a table, however, the only thing that you define in a column family is the name and the key sort options (there is no schema).
- Column families – A column family is how the data is stored on the disk. All the data in a single column family will sit in the same file (actually, set of files, but that is close enough). A column family can contain super columns or columns.
- A super column is a dictionary, it is a column that contains other columns (but not other super columns).
- A column is a tuple of name, value and timestamp
CFDB usually offer one of two forms of queries, by key or by key range. This make sense, since a CFDB is meant to be distributed, and the key determine where the actual physical data would be located. This is because the data is stored based on the sort order of the column family, and you have no real way of changing the sorting (except choosing between ascending or descending).
The sort order, unlike in a relational database, isn’t affected by the columns values, but by the column names.
Let assume that in the Users column family, in the row “@ayende”, we have the column “name” set to “Ayende Rahine” and the column “location” set to “Israel”. The CFDB will physically sort them like this in the Users column family file:
@ayende/location = “Israel” @ayende/name = “Ayende Rahien”
This is because the sort “location” is lower than “name”. If we had a super column involved, for example, in the Friends column family, and the user “@ayende” had two friends, they would be physically stored like this in the Friends column family file:
@ayende/friends/arava= 945 @ayende/friends/rose = 14
The reason that CFDB don’t provide joins is that joins require you to be able to scan the entire data set. That requires either someplace that has a view of the whole database (resulting in a bottleneck and a single point of failure) or actually executing a query over all machines in the cluster. Since that number can be pretty high, we want to avoid that.
CFDB don’t provide a way to query by column or value because that would necessitate either an index of the entire data set (or just in a single column family) which in again, not practical, or running the query on all machines, which is not possible. By limiting queries to just by key, CFDB ensure that they know exactly what node a query can run on. It means that each query is running on a small set of data, making them much cheaper.
Key Value Database
Key-Value database allows the user to store data in simple <key> : <value> format, where key is used to retrieve the value from the table.
The table contains many key spaces and each key space can have many identifiers to store key value pairs. The key-space is similar to column in typical RDBMS and the group of identifiers presented under the key-space can be considered as rows.It is suitable for building simple, non-complex, high available applications. Since most of Key Value Databases support in memory storage, can be used for building cache mechanism.
Redis
it supports to add more and more columns and have wider table. Since the table is going to be very broad, it supports to group the column with a family name, call it "Column Family" or "Super Column". The Column Family can also be optional in some of the Column data bases. As per the common philosophy of NoSQL databases, the values to the columns can be sparsely distributed.
The table contains column families (optional). Each column family contains many columns. The values for columns might be sparsely distributed with key-value pairs.The Column oriented databases are alternate to the typical Data warehousing databases (Eg. Teradata) and they are suitable for OLAP kind of application.

Apache CassandraHBase
Document-oriented Database
The table which contains a group of documents is called as a "Collection".
The Database contains many Collections. A Collection contains many documents. Each document might contain a JSON document or XML document or YAML or even a Word Document.Document databases are suitable for Web based applications and applications exposing RESTful services.
Example
MongoDB
CouchBaseDB
Brewer's CAP-Theorem
CAP theorem recommends properties for any shared-data systems. They are: Consistency, Availability & Partition. It also recommends that to be qualified as a shared-data system, a database must support at most two of these properties.
A.2.1 Consistency
In a distributed database system, all the nodes must see the same data at the same time.
A.2.2 Availability
The database system must be available to service a request received. Basically, the DBMS must be a high available system.
A.2.3 Partition Tolerance
The database system must continue to operate despite arbitrary partitioning due to network failures.
http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
http://blog.jobbole.com/1344/
https://en.wikipedia.org/wiki/Multi-master_replication
Multi-master replication is a method of database replication which allows data to be stored by a group of computers, and updated by any member of the group. All members are responsive to client data queries. The multi-master replication system is responsible for propagating the data modifications made by each member to the rest of the group, and resolving any conflicts that might arise between concurrent changes made by different members.
Multi-master replication can be contrasted with master-slave replication, in which a single member of the group is designated as the "master" for a given piece of data and is the only node allowed to modify that data item. Other members wishing to modify the data item must first contact the master node. Allowing only a single master makes it easier to achieve consistency among the members of the group, but is less flexible than multi-master replication.
Multi-master replication can also be contrasted with failover clustering where passive slave servers are replicating the master data in order to prepare for takeover in the event that the master stops functioning. The master is the only server active for client interaction.
AdvantagesIf one master fails, other masters continue to update the database.
Masters can be located in several physical sites, i.e. distributed across the network.
Disadvantages
Most multi-master replication systems are only loosely consistent, i.e. lazy and asynchronous, violating ACID properties.
Eager replication systems are complex and increase communication latency.
Issues such as conflict resolution can become intractable as the number of nodes involved rises and latency increases.
http://www.w3resource.com/mongodb/nosql.php
CAP
Consistency - This means that the data in the database remains consistent after the execution of an operation. For example after an update operation all clients see the same data.
Availability - This means that the system is always on (service guarantee availability), no downtime.
Partition Tolerance - This means that the system continues to function even the communication among the servers is unreliable, i.e. the servers may be partitioned into multiple groups that cannot communicate with one another.
In theoretically it is impossible to fulfill all 3 requirements. CAP provides the basic requirements for a distributed system to follow 2 of the 3 requirements. Therefore all the current NoSQL database follow the different combinations of the C, A, P from the CAP theorem. Here is the brief description of three combinations CA, CP, AP :
CA - Single site cluster, therefore all nodes are always in contact. When a partition occurs, the system blocks.
CP - Some data may not be accessible, but the rest is still consistent/accurate.
AP - System is still available under partitioning, but some of the data returned may be inaccurate.
The BASE
The CAP theorem states that a distributed computer system cannot guarantee all of the following three properties at the same time:
Consistency
Availability
Partition tolerance
A BASE system gives up on consistency.
Basically Available indicates that the system does guarantee availability, in terms of the CAP theorem.
Soft state indicates that the state of the system may change over time, even without input. This is because of the eventual consistency model.
Eventual consistency indicates that the system will become consistent over time, given that the system doesn't receive input during that time.
NoSQL Categories
There are four general types (most common categories) of NoSQL databases. Each of these categories has its own specific attributes and limitations.
Key-value stores
Column-oriented
Graph
Document oriented
Key-value stores
Based on Amazon’s Dynamo paper.
Key value stores allow developer to store schema-less data.
In the key-value storage, database stores data as hash table where each key is unique and the value can be string, JSON, BLOB (basic large object) etc.
A key may be strings, hashes, lists, sets, sorted sets and values are stored against these keys.
Column-oriented databases
Column-oriented databases primarily work on columns and every column is treated individually.
Values of a single column are stored contiguously.
Column stores data in column specific files.
In Column stores, query processors work on columns too.
All data within each column datafile have the same type which makes it ideal for compression.
Column stores can improve the performance of queries as it can access specific column data.
High performance on aggregation queries (e.g. COUNT, SUM, AVG, MIN, MAX).
Example of Column-oriented databases : BigTable, Cassandra, SimpleDB etc.
Graph databases
A graph data structure consists of a finite (and possibly mutable) set of ordered pairs, called edges or arcs, of certain entities called nodes or vertices.
What is a Graph Databases?
A graph database stores data in a graph.
It is capable of elegantly representing any kind of data in a highly accessible way.
A graph database is a collection of nodes and edges
Each node represents an entity (such as a student or business) and each edge represents a connection or relationship between two nodes.
Every node and edge is defined by a unique identifier.
Each node knows its adjacent nodes.
As the number of nodes increases, the cost of a local step (or hop) remains the same.
Index for lookups.
Example of Graph databases : OrientDB, Neo4J, Titan.etc.
Document Oriented databases
A collection of documents
Data in this model is stored inside documents.
A document is a key value collection where the key allows access to its value.
Documents are not typically forced to have a schema and therefore are flexible and easy to change.
Documents are stored into collections in order to group different kinds of data.
Documents can contain many different key-value pairs, or key-array pairs, or even nested documents.
Example of Document Oriented databases : MongoDB, CouchDB etc.
CAP
Consistency - This means that the data in the database remains consistent after the execution of an operation. For example after an update operation all clients see the same data.
Availability - This means that the system is always on (service guarantee availability), no downtime.
Partition Tolerance - This means that the system continues to function even the communication among the servers is unreliable, i.e. the servers may be partitioned into multiple groups that cannot communicate with one another.
In theoretically it is impossible to fulfill all 3 requirements. CAP provides the basic requirements for a distributed system to follow 2 of the 3 requirements. Therefore all the current NoSQL database follow the different combinations of the C, A, P from the CAP theorem. Here is the brief description of three combinations CA, CP, AP :
CA - Single site cluster, therefore all nodes are always in contact. When a partition occurs, the system blocks.
CP - Some data may not be accessible, but the rest is still consistent/accurate.
AP - System is still available under partitioning, but some of the data returned may be inaccurate.
The BASE
The CAP theorem states that a distributed computer system cannot guarantee all of the following three properties at the same time:
Consistency
Availability
Partition tolerance
A BASE system gives up on consistency.
Basically Available indicates that the system does guarantee availability, in terms of the CAP theorem.
Soft state indicates that the state of the system may change over time, even without input. This is because of the eventual consistency model.
Eventual consistency indicates that the system will become consistent over time, given that the system doesn't receive input during that time.
NoSQL Categories
There are four general types (most common categories) of NoSQL databases. Each of these categories has its own specific attributes and limitations.
Key-value stores
Column-oriented
Graph
Document oriented
Key-value stores
Based on Amazon’s Dynamo paper.
Key value stores allow developer to store schema-less data.
In the key-value storage, database stores data as hash table where each key is unique and the value can be string, JSON, BLOB (basic large object) etc.
A key may be strings, hashes, lists, sets, sorted sets and values are stored against these keys.
Column-oriented databases
Column-oriented databases primarily work on columns and every column is treated individually.
Values of a single column are stored contiguously.
Column stores data in column specific files.
In Column stores, query processors work on columns too.
All data within each column datafile have the same type which makes it ideal for compression.
Column stores can improve the performance of queries as it can access specific column data.
High performance on aggregation queries (e.g. COUNT, SUM, AVG, MIN, MAX).
Example of Column-oriented databases : BigTable, Cassandra, SimpleDB etc.
Graph databases
A graph data structure consists of a finite (and possibly mutable) set of ordered pairs, called edges or arcs, of certain entities called nodes or vertices.
What is a Graph Databases?
A graph database stores data in a graph.
It is capable of elegantly representing any kind of data in a highly accessible way.
A graph database is a collection of nodes and edges
Each node represents an entity (such as a student or business) and each edge represents a connection or relationship between two nodes.
Every node and edge is defined by a unique identifier.
Each node knows its adjacent nodes.
As the number of nodes increases, the cost of a local step (or hop) remains the same.
Index for lookups.
Example of Graph databases : OrientDB, Neo4J, Titan.etc.
Document Oriented databases
A collection of documents
Data in this model is stored inside documents.
A document is a key value collection where the key allows access to its value.
Documents are not typically forced to have a schema and therefore are flexible and easy to change.
Documents are stored into collections in order to group different kinds of data.
Documents can contain many different key-value pairs, or key-array pairs, or even nested documents.
Example of Document Oriented databases : MongoDB, CouchDB etc.
http://dataconomy.com/sql-vs-nosql-need-know/
Document Databases
This image from Document Database solution CouchDB sums up the distinction between RDBMS and Document Databases pretty well:Instead of storing data in rows and columns in a table, data is stored in documents, and these documents are grouped together in collections. Each document can have a completely different structure. Document databases include the aforementioned CouchDB and MongoDB.
Key-Value Stores
Data is stored in an associative array of key-value pairs. The key is an attribute name, which is linked to a value. Well-known key value stores include Redis, Voldemort (developed by LinkedIn) and Dynamo (developed by Amazon).
Graph Databases
Used for data whose relations are represented well in a graph. Data is stored in graph structures with nodes (entities), properties (information about the entities) and lines (connections between the entities). Examples of this type of database include Neo4J and InfiniteGraph.
Columnar (or Wide-Column) Databases
Instead of ‘tables’, in columnar databases you have column families, which are containers for rows. Unlike RDBMS, you don’t need to know all of the columns up front, each row doesn’t have to have the same number of columns. Columnar databases are best suited to analysing huge datasets- big names include Cassandra and HBase.
如何用消息系统避免分布式事务?
本质上问题可以抽象为:当一个表数据更新后,怎么保证另一个表的数据也必须要更新成功。
从支付宝转账1万块钱到余额宝的动作分为两步:
- 1)支付宝表扣除1万:update A set amount=amount-10000 where userId=1;
- 2)余额宝表增加1万:update B set amount=amount+10000 where userId=1;
如何确保支付宝余额宝收支平衡呢?
有人说这个很简单嘛,可以用事务解决。
1
2
3
4
5
| Begin transaction update A set amount=amount-10000 where userId=1; update B set amount=amount+10000 where userId=1;End transactioncommit; |
非常正确,如果你使用spring的话一个注解就能搞定上述事务功能。
1
2
3
4
5
| @Transactional(rollbackFor=Exception.class) public void update() { updateATable(); //更新A表 updateBTable(); //更新B表 } |
如果系统规模较小,数据表都在一个数据库实例上,上述本地事务方式可以很好地运行,但是如果系统规模较大,比如支付宝账户表和余额宝账户表显然不会在同一个数据库实例上,他们往往分布在不同的物理节点上,这时本地事务已经失去用武之地。
既然本地事务失效,分布式事务自然就登上舞台。
2 分布式事务—两阶段提交协议
两阶段提交协议(Two-phase Commit,2PC)经常被用来实现分布式事务。一般分为协调器C和若干事务执行者Si两种角色,这里的事务执行者就是具体的数据库,协调器可以和事务执行器在一台机器上。
1) 我们的应用程序(client)发起一个开始请求到TC;
2) TC先将<prepare>消息写到本地日志,之后向所有的Si发起<prepare>消息。以支付宝转账到余额宝为例,TC给A的prepare消息是通知支付宝数据库相应账目扣款1万,TC给B的prepare消息是通知余额宝数据库相应账目增加1w。为什么在执行任务前需要先写本地日志,主要是为了故障后恢复用,本地日志起到现实生活中凭证 的效果,如果没有本地日志(凭证),出问题容易死无对证;
3) Si收到<prepare>消息后,执行具体本机事务,但不会进行commit,如果成功返回<yes>,不成功返回<no>。同理,返回前都应把要返回的消息写到日志里,当作凭证。
4) TC收集所有执行器返回的消息,如果所有执行器都返回yes,那么给所有执行器发生送commit消息,执行器收到commit后执行本地事务的commit操作;如果有任一个执行器返回no,那么给所有执行器发送abort消息,执行器收到abort消息后执行事务abort操作。
注:TC或Si把发送或接收到的消息先写到日志里,主要是为了故障后恢复用。如某一Si从故障中恢复后,先检查本机的日志,如果已收到<commit >,则提交,如果<abort >则回滚。如果是<yes>,则再向TC询问一下,确定下一步。如果什么都没有,则很可能在<prepare>阶段Si就崩溃了,因此需要回滚。
现如今实现基于两阶段提交的分布式事务也没那么困难了,如果使用java,那么可以使用开源软件atomikos(http://www.atomikos.com/)来快速实现。
不过但凡使用过的上述两阶段提交的同学都可以发现性能实在是太差,根本不适合高并发的系统。为什么?
- 1)两阶段提交涉及多次节点间的网络通信,通信时间太长!
- 2)事务时间相对于变长了,锁定的资源的时间也变长了,造成资源等待时间也增加好多!
正是由于分布式事务存在很严重的性能问题,大部分高并发服务都在避免使用,往往通过其他途径来解决数据一致性问题。
3.1 如何可靠保存凭证(消息)
3.1.1 业务与消息耦合的方式
支付宝在完成扣款的同时,同时记录消息数据,这个消息数据与业务数据保存在同一数据库实例里(消息记录表表名为message)。
1
2
3
4
5
| Begin transaction update A set amount=amount-10000 where userId=1; insert into message(userId, amount,status) values(1, 10000, 1);End transactioncommit; |
上述事务能保证只要支付宝账户里被扣了钱,消息一定能保存下来。
当上述事务提交成功后,我们通过实时消息服务将此消息通知余额宝,余额宝处理成功后发送回复成功消息,支付宝收到回复后删除该条消息数据。
3.1.2 业务与消息解耦方式
上述保存消息的方式使得消息数据和业务数据紧耦合在一起,从架构上看不够优雅,而且容易诱发其他问题。为了解耦,可以采用以下方式。
1)支付宝在扣款事务提交之前,向实时消息服务请求发送消息,实时消息服务只记录消息数据,而不真正发送,只有消息发送成功后才会提交事务;
2)当支付宝扣款事务被提交成功后,向实时消息服务确认发送。只有在得到确认发送指令后,实时消息服务才真正发送该消息;
3)当支付宝扣款事务提交失败回滚后,向实时消息服务取消发送。在得到取消发送指令后,该消息将不会被发送;
4)对于那些未确认的消息或者取消的消息,需要有一个消息状态确认系统定时去支付宝系统查询这个消息的状态并进行更新。为什么需要这一步骤,举个例子:假设在第2步支付宝扣款事务被成功提交后,系统挂了,此时消息状态并未被更新为“确认发送”,从而导致消息不能被发送。
优点:消息数据独立存储,降低业务系统与消息系统间的耦合;
缺点:一次消息发送需要两次请求;业务处理服务需要实现消息状态回查接口。
3.2 如何解决消息重复投递的问题
还有一个很严重的问题就是消息重复投递,以我们支付宝转账到余额宝为例,如果相同的消息被重复投递两次,那么我们余额宝账户将会增加2万而不是1万了。
为什么相同的消息会被重复投递?比如余额宝处理完消息msg后,发送了处理成功的消息给支付宝,正常情况下支付宝应该要删除消息msg,但如果支付宝这时候悲剧的挂了,重启后一看消息msg还在,就会继续发送消息msg。
解决方法很简单,在余额宝这边增加消息应用状态表(message_apply),通俗来说就是个账本,用于记录消息的消费情况,每次来一个消息,在真正执行之前,先去消息应用状态表中查询一遍,如果找到说明是重复消息,丢弃即可,如果没找到才执行,同时插入到消息应用状态表(同一事务)。
1
2
3
4
5
6
7
8
| for each msg in queue Begin transaction select count(*) as cnt from message_apply where msg_id=msg.msg_id; if cnt==0 then update B set amount=amount+10000 where userId=1; insert into message_apply(msg_id) values(msg.msg_id); End transaction commit; |
ebay的研发人员其实在2008年就提出了应用消息状态确认表来解决消息重复投递的问题:http://queue.acm.org/detail.cfm?id=1394128。
http://docs.oracle.com/cd/B28359_01/server.111/b28326/repmaster.htm
Storm Applied: Strategies for real-time event processing
“Which one of these NoSQL solutions should I pick?” This is the wrong approach. Instead, ask yourself questions about the functionality you’re implementing and the requirements they impose on any data storage solution.
You should be asking whether your use case requires a data store that supports the following:
- Random reads or random writes
- Sequential reads or sequential writes
- High read throughput or high write throughput
- Whether the data changes or remains immutable once written
- Storage model suitable for your data access patterns
- Column/column-family oriented
- Key-value
- Document oriented
- Schema/schemaless
- Whether consistency or availability is most desirable
http://stackoverflow.com/questions/3010224/mongodb-vs-redis-vs-cassandra-for-a-fast-write-temporary-row-storage-solution
http://www.datastax.com/wp-content/themes/datastax-2014-08/files/NoSQL_Benchmarks_EndPoint.pdf
NoSQL和SQL的选用
https://www.jiuzhang.com/qa/1836/
回到問題, 關於選用 CF NoSQL vs SQL, 這邊分三種 cases 考慮:
1. Data 非常不 relational (require no join or few joins), 這時用 SQL 就有點浪費, 可能會有不必要的 overhead.
2. Date 非常 relational (require lots of joins) 或有大量的 columns 要作 index, 這時用 CF NoSQL 可能要處理大量的 de-normalization, 雖然 disk 便宜, 但 duplicated data 太多的話可能也會爆容量? 而且 update 時要處理 de-norm data 間 consistency 的問題. e.g. 一個 data 可能屬於 (row_key_A, column_key_A) 同時也屬於 (row_key_B, column_key_B), 這樣更新這 data 時就要同時更新這兩個 row.
感覺這種情況選用 SQL 會較佳?
3. 去除以上兩個極端 cases, 通常 data 是介於中間. 這時候感覺用 CF NoSQL 和 SQL是差不多的.
用 SQL 的話, developer 要自己處理 sharding/replication. 不過相對而言, SQL expert 的數量是遠大於 Cassandra/Hbase expert, SQL communities 也相對成熟許多.
1. Data 非常不 relational (require no join or few joins), 這時用 SQL 就有點浪費, 可能會有不必要的 overhead.
2. Date 非常 relational (require lots of joins) 或有大量的 columns 要作 index, 這時用 CF NoSQL 可能要處理大量的 de-normalization, 雖然 disk 便宜, 但 duplicated data 太多的話可能也會爆容量? 而且 update 時要處理 de-norm data 間 consistency 的問題. e.g. 一個 data 可能屬於 (row_key_A, column_key_A) 同時也屬於 (row_key_B, column_key_B), 這樣更新這 data 時就要同時更新這兩個 row.
感覺這種情況選用 SQL 會較佳?
3. 去除以上兩個極端 cases, 通常 data 是介於中間. 這時候感覺用 CF NoSQL 和 SQL是差不多的.
用 SQL 的話, developer 要自己處理 sharding/replication. 不過相對而言, SQL expert 的數量是遠大於 Cassandra/Hbase expert, SQL communities 也相對成熟許多.
面试的时候答 SQL 好还是 NoSQL 好。其实没有固定答案,你要是能都说一遍用 SQL 有什么好处什么坏处,用 NoSQL 做有什么好处什么坏处。这个才是面试官最想看到的。面试官不希望你只有一个答案,他希望看到你的分析过程。
我对nosql选择的理解是如果期待较容易的获得更高的写负荷与高可用(sharding & node transform),并且数据结构化不强可能添加新column的情况,选择nosql就是最佳选择。同时找出那些需要强事务性的安排在sql中。
由于column family把一个column的数据存在一起,所以当你对某一个column query的时候会特别快,比如query 有多少帖子的点击量大于1m:你只需要快速扫过点击量这一列即可
https://loonytek.com/2017/05/04/why-analytic-workloads-are-faster-on-columnar-databases/
Analytic workloads comprise of operations like scans, joins, aggregations etc. These operations are concerned with data retrieval, some computations over the values stored in table cells, and predicate evaluation. Such operations typically touch a very large number of rows but only a few columns in the table. As far as I understand, this is the fundamental difference between analytic queries and OLTP-style operations
1. Organization of Data
The fundamental (and most obvious) difference between column stores and row stores is the way they organize and store table data.
Row-oriented databases store data on a row-by-row basis. Each row has its data stored together (contiguously) in-memory or on-disk or both. Thus its easier to grab some/all columns of a “particular row” given its ROWID. So in a single seek, row’s data can be loaded from disk into memory.
In columnar databases, values of a particular column are stored separately or individually — contiguous layout for values of a given column in-memory or on-disk. If the query touches only few columns, it is relatively faster to load all values of a “particular column” into memory from disk in fewer I/Os and further into CPU cache in fewer instructions.
3. CPU Cache Friendly
The columnar storage format allows better utilization of CPU cache since cache lines are full of related values (same column) that are needed by query executor to run some operations (evaluation, computation etc). In other words, only data that really needs to be examined is brought into cache. Thus looping through values of a column packed into columnar format is faster.
Any query eventually needs to send back the result-set (tuples) to the end user. This should happen regardless of what type (column store or row store) of data store is being used.
4. Late Materialization
5. Compression
Data stored in database tables is usually compressed to optimize disk space storage and I/O during query processing — reduced number of bytes (compressed) will be read off disk into memory and down through the storage hierarchy.
Compression algorithms operate better if the input data is somewhat related (less entropy) and this gives better compression ratios. Columnar format can take advantage of this fact and each column can be compressed individually with a compression scheme most suitable for that column
Different factors can be taken into account when deciding upon a compression scheme to be used for a particular column. Factors like column cardinality, data type, sorted or not etc are important column-level characteristics that can be used to decide the compression method.
The focus is not really on getting best compression ratios. Instead, we should think about schemes that enable faster processing (predicate evaluation, decompression etc) on column values. Columnar format allows us to use simple and efficient compression methods like Run Length Encoding (RLE), Dictionary Encoding, bit-vector encoding, delta encoding etc that may not give the best compression ratios but allow faster decompression.
As an example, dictionary encoding is usually a good choice if the column has low cardinality— limited number of possible unique values. The encoded values (dictionary indexes) can be stored in fewer bits. COUNTRY column in a table can be efficiently represented using dictionary encoding.