http://dcaoyuan.github.io/papers/pdfs/Scalability.pdf
我先简单的将 Scalabilty 的需求分成两种:
• Data Scalability: 单台机器的容量不足以 (经济的) 承载所有资料,所以需要分散。如:NoSQL
• Computing Scalability: 单台机器的运算能力不足以 (经济的) 及时完成运算,所以需要分散。如:科学运算
不管是哪一种需求,在决定采用分散式架构时,就几乎注定要接受一些牺牲:
• 牺牲效率:网路延迟与节点间的协调,都会降低执行效率。
• 牺牲 AP 弹性:有些在单机上能执行的运算,无法轻易在分散式环境中完成。
• 牺牲维护维运能力:分散式架构的问题常常很难重现,也很难追踪。
另外,跟单机系统一样,也有一些系统设计上的 tradeoffs
• CPU 使用效率优化或是 IO 效率优化
• 读取优化或是写入优化
• Throughput 优化或是 Latency 优化
• 资料一致性或是资料可得性
选择了不同的 tradeoff,就会有不同的系统架构。
分散式系统都是特化的,而不是通用的。所以不同的设计决策就会衍生出不同用途的系统。
DAY 3: PARTITION
分散式资料系统的两个问题根源:partition 和 replication。
先谈 partition。当资料放不进一台机器,或是对资料的运算太过耗时,单台机器无法负荷
时,就是考虑 partition 的时候。
partition 就是把资料切割放到多台机器上,首先要考量的,就是要怎麽切资料。
资料有几种常见的切法:
• Round-Robin: 资料轮流进多台机器。好处是 load balance,坏处是不适合有 session
或资料相依性 (need join) 的应用。变型是可以用 thread pool,每个机器固定配几个
thread,这可以避免某个运算耗时过久,而档到後面运算的问题。
• Range: 事先定好每台机器的防守范围,如 key 在 1~1000 到 A 机器。优点是简单,
只需要维护一些 metadata。问题是弹性较差,且会有 hotspot 的问题 (大量资料数值
都集中在某个范围)。MongoDB 在早期版本只支援这种切割方式。
• Hash: 用 Hash 来决定资料要在哪台机器上。简单的 Hash 像是取馀数,但取馀数在
新增机器时会有资料迁移的问题,所以现在大家比较常用 Consistent Hashing 来避
免这个问题。Hash 可以很平均的分布,且只需要非常少的 metadata。但 Hash 规则
不好掌握,比方说我们就很难透过自定 Hash 规则让某几笔资料一定要在一起。大部
分的 Data Store 都是采用 Consistent Hashing。
• Manual: 手动建一个对照表,优点是想要怎麽分配都可以,缺点是要自己控制资料和
负载的均衡,且会有大量 metadata 要维护。
除了切法之外,还要决定用哪个栏位当做切割的 key。
有一个 tradeoff 在读写之间,优化写可能会害到读。
另一个 tradeof f 在 application 之间,比方说一个用户表格资料如果用地区来切割,那就有利於常带地区条件的应用,因为这些应用可以只锁定几个 partition 进行查询,而不用把query 洒到所有机器上。
DAY 4: 为什麽有有些时候不要把 QUERY 洒到所有机器上平行处理?
如果 query 很耗时,那分散的确会比较好;但如果 query 很快 (比方有用到 DB 的 index lookup),那分散会增加效能降低的风险。
Hadoop 的 Map Reduce 就是透过分散提升效率,因为有很多资料要扫,所以分散是值得
的。在这种状况下,效能的增加盖过效能降低的风险。
所谓效能降低的风险是指:因为要所有机器都回传资料後才能完成运算,所以运算时间是Max(各台机器的处理时间)。当机器越多的时候,发生异常的机会越高,导致运算延迟。
在分散式资料系统中,如过查询费时,可以尽量分散;但如果查询很快,请尽量集中在少数机器处理。
DAY 5: 资料切割的 METADATA 管理
有些切割方式,像是 Hashing 的 metadata 量非常少,这是相对容易管的。但有些切割方
式有很多 metadata,且有些方式在每次 insert 都要更新 metadata (bad practice~),那这
就麻烦了。
一个最简单的方式就是有一台机器专门管这些 metadata (meta server, config server...),
若需要 metadata 就来这边问。但明显的这会有单点问题。现在常见的解法是用 Apache Zookeeper (ZK),这是一个维持 cluster 中共同状态的分散式系统,透过 ZK 来维护这些 metadata 是许多分散式系统的普遍作法。ZK 有自己的 HA和 consistency 机制可以保障资料,而且在 production 环境中一次要用 2n+1 (n>0) 个节点 (minumum = 3),只要不要大於 n 个节点挂掉都可以正常服务。
ZK 为了保障资料的一致性,存取资料的手续有点麻烦。所以请不要因为 ZK 好用就让 ZK太过操劳。
当然,如果 metadata 真的很少,又不大会更新的时候,连 ZK 都可以省掉。这就是完全P2P 的系统了,像 Cassandra 就是这种。
DAY 6: REPLICATION
有的系统对於资料一致性读很要求,就会采同步复制,要复制完成後资料写入才会完成。
但这样会很慢,尤其是副本越来越多的时候。
所以比较有效率的作法是非同步复制,但一定会有一段时间不一致。
那有没有折衷作法呢。有的,Quorum 就是一个折衷的作法,R+W>N,你可以控制要
write-efficient 还是 read-efficient,然後牺牲另一个 operation 的效率来换资料的一致性。
另外呢,每更新一笔资料就发一次复本更新是很没有效率的,通常要累积一些更新或隔一
段时间才会 batch update。
常见的复制是有三个副本,除了原本的资料之外,同一个 rack 或 data center 一个副本,
另一个 rack 或 data center 再一个。
那副本允不允许写入呢?多数资料系统是不允许的,也就是说,副本纯粹只是增加 read
concurrency/efficiency/availabilty。同样是副本,同时只有一个 master 副本负责写入,其
他的 slave 副本只负责 read request。
也有允许副本写入的系统,像是 cassandra。多个互相冲突的写入会以写入的 timestamp订输赢 (所以 NTP 是必须的,但 NTP 也不能保证多台机器的时间完全一样),Last writewin。当然在还没协调前会存在有资料不一致的时间,那这就是应用必须要忍受的。
DAY 7: 无强一致性及无法决定执行顺序带来的问题
為了避免這種問題,許多資料系統都只允許在一個節點上寫資料。如果有拆partition,那每個partition內會只有一個master及零至多個slave(replica),只有master能寫資料。再極端一點,有些資料系統為了避免讀到不一致的資料,甚至會只允許在master上讀資料,那這樣replica就完全只是備援的角色,沒有分散讀取的能力。
Day 8: 最終一致性
最終一致性是說,只要資料不再更新,終有個時刻,所有節點會協調出一個一致的狀態。
這的確是很不可靠。之前提到的執行順序的問題,許多系統是利用Vector clock,透過訊息傳遞來歸納出執行的時序。但由於Vector clock需要透過訊息交換logical timestamp,才能整理出時序。所以如果有節點很孤僻不常跟其他人講話,那推敲出來的時序就不精準。實際上,Vector clock不保證能推測出完整時序(total order),只能推測出部分時序(partial order),也就是可能只能推敲出類似這樣的結果:A < D, B < D, C < D,那你說A, B, C的順序呢?很抱歉,因為只有部分時序,所以不知道。
Day 9: CAP Theorem
C (Strong Consistency): 在任何時候,從叢集中的任兩個節點得到的狀態都是一樣的。
A (Availability): 若一個節點沒有壞掉,那它就必須要能正常服務。
P (Partition Tolerance): 若一個叢集因網路問題或節點故障問題,被切割成兩個(或以上)不完整的sub cluster時,系統整體還能正常運作。
假設有兩台節點在不同機器上,如果存入資料的方式是Two-phase commit,亦即所有節點同意後才能存入資料,那麼只要partition發生、或任何一個節點故障,就不能運作,因此就只有C和A。但這樣的系統實在是太脆弱了(記得day 4 把查詢灑到所有機器執行的風險嗎?),所以一般的分散式系統都會要求要有P。
假設有兩台節點在不同機器上,且必須要能容忍Partition,那麼在partition發生時能怎麼做呢?
Keep Availability:兩個節點雖然彼此之間不能溝通,但是既然都活著,就讓他們都正常服務好了。這樣其中一邊的變化不能傳遞至另外一邊,因此可能兩邊資料會不一致 。更糟的狀況是發生裂腦,就兩邊都以為自己是master可以寫入資料,就會產生前兩天提到的時序問題。(No consistency -- A和P)
Keep Consistency: 為了避免之前提到的不一致問題,因此必須停掉其中任一個節點 (No availability -- C和P)
 Day 10: In-Memory data
Day 10: In-Memory data
In-Memory data是想把硬碟當做是磁帶的角色,把資料都放在DRAM (or Flash, 現在暫時先不考慮這個) 裡。單機的DRAM空間有限,所以要搭配一些技巧,像是:資料壓縮、分散式系統等等。
另外一個問題是資料保存的問題。DRAM是Volatile的,也就是機器斷電後資料就不見了,要怎麼讓資料在斷電後不會不見呢?有兩個選項:
(1) persistence: 在硬碟寫change log
(2) replication: 在其他機器建立副本
Day 11: Zookeeper
ZK有幾個常見的用法:
共享Metadata
監控成員節點的狀況 & 維護叢集的成員名單
協助選出叢集中的leader(master)
ZK的資料是以樹狀方式組織,樹的節點叫做znode,可以在znode裡放資料。
由於znode裡的資料是許多成員都關心的,所以ZK有一個notification機制,可以在znode裡的資料更新時通知有事先對該znode註冊watcher的process。
有一種znode叫做ephemeral node,用來監控成員的狀況。這個znode跟建立znode的成員的session狀況是連動的,若session一段時間沒有回報(heartbeat),這個znode節點就會被刪除。因此若有其他成員在此znode上設定watcher,就會在此節點掛掉(即session掛掉時)收到通知。
所有成員都會對master對應的ephemeral node註冊watcher,所以在master失效後,會有成員偵測到而啟動leader election。
Zookeeper能保證global order,因為只有leader能處理寫入要求。Zookeeper在partition發生時仍能維持服務,因為採用了Quorum。所以Zookeeper基本上是偏向CA的分散式系統。
所謂Quorum是指成員數達到最低投票門檻的成員集合。Zookeeper成員有兩者角色,Leader或Follower,一個Quroum裡最多只能有一個Leader,其他都是支持此Leader的Followers。Leader Election的目的就是要選出Quorum中的Leader。
一個Quorum的成員數達到最低投票門檻,一般來說,是指成員數要大於Zookeeper節點的一半數量。比方說總共開了5個Zookeeper節點,Quorum裡最少要有三個成員(3>2.5)。這樣保證了,當叢集被partition成兩半,其中一個partition的節點數是不足以形成Quorum的。若不足以形成Quorum,就不允許對外服務。因此叢集中最多只有一個Quorum可以對外服務,就不會發生inconsistency的狀況。
Day 13: Apache Kafka
Apache Kafka 是一個 Distributed Queue 的實現,很多 Stream Computing 平台都支援 Kafka 作為 data source。
分散式架構,所以天生就是容易擴充的。
基於磁碟空間,且避免隨機存取。
因為儲存空間大,因此Queue裡的資料就算已消耗,也可以不用刪掉。好處包括:其他新加入的consumer可以處理到過去的資料(重要特色)。如果有batch-oriented的consumer (如:Hadoop),可以一次拉取足夠大量的資料,以利batch的處理效率。
對資料的包裝是輕量級的,且可壓縮。避免掉不必要的物件包覆,可以直接以檔案的型式來處理資料。
因為可以直接處理檔案資料,直接用OS的page cache,不需要額外Applicaion Cache來競爭珍貴的記憶體空間。
基本上Kafka是一個broker的角色,仲介producer與consumer。Kafka一般是由多個節點所構成的cluster。
Kafka有自己的producer API和consumer API,produce/consumer client 必須要使用或依照API spec自行實作存取的方式。
一組資料流稱為一個Topic,為避免一個Topic的資料量過大,所以一個Topic可以分成好幾個Partition,每個Partition會在不同的節點上(如果可以的話)。
Producer必須要自己決定要將資料送到哪個partition,在producer API裡有一個參數可以讓使用者指定partition key,然後producer API用hash方式決定partition。
Kafka可以彈性的支援point-to-point和pub/sub兩種Queue mode。主要是透過一個Consumer Group的抽象,每個Consumer Group當做是一個虛擬consumer,但可以由多個實體的consumer組成。一組Point-to-point就是將所有consumer都劃成同一個Consumer Group;而Pub/Sub是將不同Pub的Sub分成不同的Consumer Group
一個重點是,每一個Consumer只會同時bind一個partition,也就是說,一個Consumer只會找一個partition來拉資料。
這帶來一些很重要的暗示,也是Kafka的限制所在,這些限制就下次再講吧。
Consumer Group裡的consumer數量 不能小於 partition 數量。不然就會有partition裡的資料對不到consumer。
若各個consumer消耗資料速度不均,Partition的消耗速度會失衡。也就是有的partition已經消耗到最近的資料,但有的partition還在消耗之前的資料。
搭配上之前所說:「Producer必須要自己決定要將資料送到哪個partition」,所以失衡的狀況無法透過Producer改善,又:「每一個Consumer只會同時bind一個partition」,所以,失衡的狀況無法藉由produer/consumer的round-robin來解決(*)。
基於以上,每個partition實際上可以看成一個獨立的Queue。也就是說,雖然有partition,但沒有所謂跨partition的total order,也就是只能保證各個partition自己的local order。
也就是說,若有一個AP會處理跨partition的資料,AP不能假設會依producer產生的時序取得資料,而只能假設從每個partition裡取得的資料是有按時序的 (Kafka有保證,若Producer先送到Partition的資料,在Partition裡也會排前面)。這就是在Day 3所講到,partition帶來的tradeoff。因此,若有total order需求的AP並不適合用Kafka。
簡單來說,Kafka假設,AP是不需要total order的;抑或是AP只需要by-partition的local order,只要適當的做好partition,那麼就可以維持好時序的資料消耗。
Kafka實際上也倚賴Zookeeper來儲存Partition的metadata
(*) (Update 10/16): Kafka有rebalance功能,若在Consumer group中新增Consumer,會觸動rebalance, 重新分配partition與consumer之間的對應關係。這樣有機會可以解決資料量失衡的問題。
Kafka的replication是以partition做單位,方法也很簡單,就是讓replica去訂閱要追蹤的partition。因為這是Queue,所以直接用訂閱的機制就可以處理掉replication。
在每個replica set裡,只會有一個master,這個master負責所有的讀寫工作,其他的slave都只是作備援,所以不會有Day 7講到的不一致問題。
每個replica set會維持一個ISR (In-Sync Replicas)名單,名單內的replica是與master較為同步。若master掛掉,會從這些ISR中多數決挑選出新的master。這個ISR的名單是會變動的。
在寫入時雖然是以master作為窗口,但預設要等到master的資料同步到所有的ISR,該筆資料才算committed,也才能被consumer所看到。
stream computing的ack還要解決多階段、數量大的ack管理,而Kafka的ack只要確保message deliver semantics。
分散式系統因為有透過網路,所以message deliver都是很難保證的。就像網路,有時候可以允許遺失封包 (UDP),如果不能遺失封包(TCP),就要有重送和檢查重複的機制。
對於Kafka的consumer來說,何時回送ack,就決定了message deliver semantics。
如果在資料收到、但還沒處理前就先送ack,由於機器可能在處理前掛掉,所以不能保證資料一定被處掉到,所以是at-most once semantics。
如果在資料收到且處理完後才送ack,由於機器可能在處理後、且送ack前掛掉,這樣就會重送已處理過的資料,所以是at-least once semantics。
而Apache Kafka現在還沒有內建支援exactly-once semantics。
Day 18: Apache Kafka 與 Stream Computing
至於為什麼 Kafka 適合搭配 Stream Computing呢? 因為 Stream Computing 本質上也是一種可平行處理、易擴充的分散式處理架構,所以也要搭配同樣可平行讀寫、易擴充的data source/data sink才能發揮最大的效能。且Stream Computing的處理過程要求low latency,這是類似於Queue的需求,而非Log aggregation Tool (如: Flume)的需求。
Kafka目前是實現Lambda architecture的要角。因為只有Kafka能同時滿足real-time processing與batch processing對於data source的需求。
對於 Stream Computing 來說,Kafka 可以不只作為 data source/data sink,也可以作為state commit log的sync工具。
Day 20: In-Memory 的技術議題?
In-Memory Computing號稱把Memory 當做Disk,而 Disk當做磁帶,可以省去將資料從 memory持久化到disk 的過程。除非是要 recovery,也無須從disk 讀取資料。因為 disk和memory 的速度是多個數量級的差距,不碰 disk自然有加速效果,但同時也會受限於 Memory大小,必須思考解決之道。
所以 In-Memory computing solution多半會強調資料壓縮能力,能把更多資料存進 Memory。有的solution 還強調他們能更有效運用 CPU,如:降低cache miss 、減少 lock/latch contention等,因為bottleneck 已經不再在 I/O了,所以需要讓CPU能更高效運作。
Day 21: 分散式運算系統
不過Hadoop是設計來處理high throughput的批次應用,相對來說不重視 latency。如果是要處理low latency應用的話就不適合用Hadoop了。
Hadoop是典型的Data parallelism,也就是將資料切成小塊,每一塊平行處理來增加處理時效。當然,這樣的資料平行化精神,你也可以自己將資料灑在多機上,在多機透過multi-thread / multi-process來達成,如果真的還不能達到 latency 要求的話,就要考慮再加上pipeline處理。
用上pipeline的話,要把整個運算過程拆成好幾個步驟,讓上一步驟的單筆資料的產出儘速傳送到下一步驟處理。這就像水在流動一樣,資料循著pipeline往下流。
而Stream Computing結合了Data parallelism與Pipeline,所以更加的複雜。
Day 22: 分散式運算系統的溝通方式
Shared memory: 當做白板來交換資料,缺點是很多人用的話要排隊(lock),效率不好。所以現在也演進出一些比較高效的共享方式,像是樂觀鎖、多版本控制等,但這些都有額外的overhead
Message passing: 所有process間都透過訊息的方式來交換資料,缺點就是Day 7講的,會缺乏global order。
在分散式運算系統也是一樣,如果一個運算的結果需要跟其他節點共享的話,那也需要透過每些溝通方式來達成。基本的思路也是上面這兩種。
Shared data store: 找一個大家都能access到的data store來存資料,這個data store可能是某種分散式資料系統。
Peer Communication: 透過某些高效的通訊協定在各節點間交換訊息,通常是Non-blocking的通訊方式,而且還要用高效能的序列化框架。
Day 24: Stream Computing特性
Stream Computing 是設計給需要 low-latency 的應用。batch processing 因為整批進整批出,有些已處理好的資料也需要等待其他同批資料都處理完才能一次送出,這樣會導致一些不必要的 latency。為了要減少 latency,Stream Computing 將處理顆粒度變小到 record,且將處理過程切分成好幾個階段。透過 pipeline 的方式,只要前一個階段處理完的 record,就可以馬上進入下一個階段,這樣可以避免掉不必要的 latency。
我先简单的将 Scalabilty 的需求分成两种:
• Data Scalability: 单台机器的容量不足以 (经济的) 承载所有资料,所以需要分散。如:NoSQL
• Computing Scalability: 单台机器的运算能力不足以 (经济的) 及时完成运算,所以需要分散。如:科学运算
不管是哪一种需求,在决定采用分散式架构时,就几乎注定要接受一些牺牲:
• 牺牲效率:网路延迟与节点间的协调,都会降低执行效率。
• 牺牲 AP 弹性:有些在单机上能执行的运算,无法轻易在分散式环境中完成。
• 牺牲维护维运能力:分散式架构的问题常常很难重现,也很难追踪。
另外,跟单机系统一样,也有一些系统设计上的 tradeoffs
• CPU 使用效率优化或是 IO 效率优化
• 读取优化或是写入优化
• Throughput 优化或是 Latency 优化
• 资料一致性或是资料可得性
选择了不同的 tradeoff,就会有不同的系统架构。
分散式系统都是特化的,而不是通用的。所以不同的设计决策就会衍生出不同用途的系统。
DAY 3: PARTITION
分散式资料系统的两个问题根源:partition 和 replication。
先谈 partition。当资料放不进一台机器,或是对资料的运算太过耗时,单台机器无法负荷
时,就是考虑 partition 的时候。
partition 就是把资料切割放到多台机器上,首先要考量的,就是要怎麽切资料。
资料有几种常见的切法:
• Round-Robin: 资料轮流进多台机器。好处是 load balance,坏处是不适合有 session
或资料相依性 (need join) 的应用。变型是可以用 thread pool,每个机器固定配几个
thread,这可以避免某个运算耗时过久,而档到後面运算的问题。
• Range: 事先定好每台机器的防守范围,如 key 在 1~1000 到 A 机器。优点是简单,
只需要维护一些 metadata。问题是弹性较差,且会有 hotspot 的问题 (大量资料数值
都集中在某个范围)。MongoDB 在早期版本只支援这种切割方式。
• Hash: 用 Hash 来决定资料要在哪台机器上。简单的 Hash 像是取馀数,但取馀数在
新增机器时会有资料迁移的问题,所以现在大家比较常用 Consistent Hashing 来避
免这个问题。Hash 可以很平均的分布,且只需要非常少的 metadata。但 Hash 规则
不好掌握,比方说我们就很难透过自定 Hash 规则让某几笔资料一定要在一起。大部
分的 Data Store 都是采用 Consistent Hashing。
• Manual: 手动建一个对照表,优点是想要怎麽分配都可以,缺点是要自己控制资料和
负载的均衡,且会有大量 metadata 要维护。
除了切法之外,还要决定用哪个栏位当做切割的 key。
有一个 tradeoff 在读写之间,优化写可能会害到读。
另一个 tradeof f 在 application 之间,比方说一个用户表格资料如果用地区来切割,那就有利於常带地区条件的应用,因为这些应用可以只锁定几个 partition 进行查询,而不用把query 洒到所有机器上。
DAY 4: 为什麽有有些时候不要把 QUERY 洒到所有机器上平行处理?
如果 query 很耗时,那分散的确会比较好;但如果 query 很快 (比方有用到 DB 的 index lookup),那分散会增加效能降低的风险。
Hadoop 的 Map Reduce 就是透过分散提升效率,因为有很多资料要扫,所以分散是值得
的。在这种状况下,效能的增加盖过效能降低的风险。
所谓效能降低的风险是指:因为要所有机器都回传资料後才能完成运算,所以运算时间是Max(各台机器的处理时间)。当机器越多的时候,发生异常的机会越高,导致运算延迟。
在分散式资料系统中,如过查询费时,可以尽量分散;但如果查询很快,请尽量集中在少数机器处理。
DAY 5: 资料切割的 METADATA 管理
有些切割方式,像是 Hashing 的 metadata 量非常少,这是相对容易管的。但有些切割方
式有很多 metadata,且有些方式在每次 insert 都要更新 metadata (bad practice~),那这
就麻烦了。
一个最简单的方式就是有一台机器专门管这些 metadata (meta server, config server...),
若需要 metadata 就来这边问。但明显的这会有单点问题。现在常见的解法是用 Apache Zookeeper (ZK),这是一个维持 cluster 中共同状态的分散式系统,透过 ZK 来维护这些 metadata 是许多分散式系统的普遍作法。ZK 有自己的 HA和 consistency 机制可以保障资料,而且在 production 环境中一次要用 2n+1 (n>0) 个节点 (minumum = 3),只要不要大於 n 个节点挂掉都可以正常服务。
ZK 为了保障资料的一致性,存取资料的手续有点麻烦。所以请不要因为 ZK 好用就让 ZK太过操劳。
当然,如果 metadata 真的很少,又不大会更新的时候,连 ZK 都可以省掉。这就是完全P2P 的系统了,像 Cassandra 就是这种。
DAY 6: REPLICATION
有的系统对於资料一致性读很要求,就会采同步复制,要复制完成後资料写入才会完成。
但这样会很慢,尤其是副本越来越多的时候。
所以比较有效率的作法是非同步复制,但一定会有一段时间不一致。
那有没有折衷作法呢。有的,Quorum 就是一个折衷的作法,R+W>N,你可以控制要
write-efficient 还是 read-efficient,然後牺牲另一个 operation 的效率来换资料的一致性。
另外呢,每更新一笔资料就发一次复本更新是很没有效率的,通常要累积一些更新或隔一
段时间才会 batch update。
常见的复制是有三个副本,除了原本的资料之外,同一个 rack 或 data center 一个副本,
另一个 rack 或 data center 再一个。
那副本允不允许写入呢?多数资料系统是不允许的,也就是说,副本纯粹只是增加 read
concurrency/efficiency/availabilty。同样是副本,同时只有一个 master 副本负责写入,其
他的 slave 副本只负责 read request。
也有允许副本写入的系统,像是 cassandra。多个互相冲突的写入会以写入的 timestamp订输赢 (所以 NTP 是必须的,但 NTP 也不能保证多台机器的时间完全一样),Last writewin。当然在还没协调前会存在有资料不一致的时间,那这就是应用必须要忍受的。
DAY 7: 无强一致性及无法决定执行顺序带来的问题
為了避免這種問題,許多資料系統都只允許在一個節點上寫資料。如果有拆partition,那每個partition內會只有一個master及零至多個slave(replica),只有master能寫資料。再極端一點,有些資料系統為了避免讀到不一致的資料,甚至會只允許在master上讀資料,那這樣replica就完全只是備援的角色,沒有分散讀取的能力。
Day 8: 最終一致性
最終一致性是說,只要資料不再更新,終有個時刻,所有節點會協調出一個一致的狀態。
這的確是很不可靠。之前提到的執行順序的問題,許多系統是利用Vector clock,透過訊息傳遞來歸納出執行的時序。但由於Vector clock需要透過訊息交換logical timestamp,才能整理出時序。所以如果有節點很孤僻不常跟其他人講話,那推敲出來的時序就不精準。實際上,Vector clock不保證能推測出完整時序(total order),只能推測出部分時序(partial order),也就是可能只能推敲出類似這樣的結果:A < D, B < D, C < D,那你說A, B, C的順序呢?很抱歉,因為只有部分時序,所以不知道。
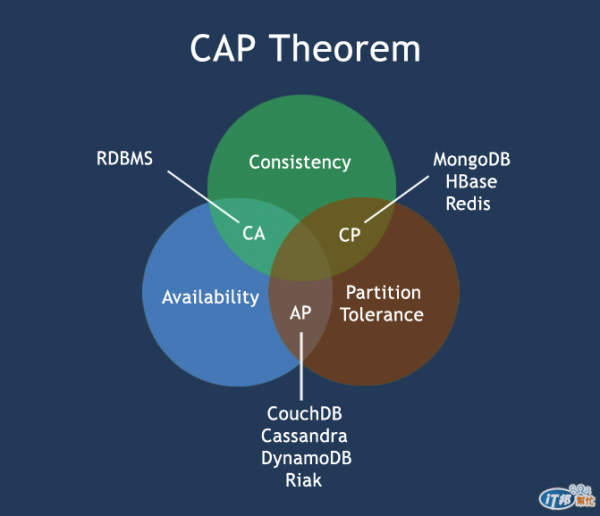
Day 9: CAP Theorem
C (Strong Consistency): 在任何時候,從叢集中的任兩個節點得到的狀態都是一樣的。
A (Availability): 若一個節點沒有壞掉,那它就必須要能正常服務。
P (Partition Tolerance): 若一個叢集因網路問題或節點故障問題,被切割成兩個(或以上)不完整的sub cluster時,系統整體還能正常運作。
假設有兩台節點在不同機器上,如果存入資料的方式是Two-phase commit,亦即所有節點同意後才能存入資料,那麼只要partition發生、或任何一個節點故障,就不能運作,因此就只有C和A。但這樣的系統實在是太脆弱了(記得day 4 把查詢灑到所有機器執行的風險嗎?),所以一般的分散式系統都會要求要有P。
假設有兩台節點在不同機器上,且必須要能容忍Partition,那麼在partition發生時能怎麼做呢?
Keep Availability:兩個節點雖然彼此之間不能溝通,但是既然都活著,就讓他們都正常服務好了。這樣其中一邊的變化不能傳遞至另外一邊,因此可能兩邊資料會不一致 。更糟的狀況是發生裂腦,就兩邊都以為自己是master可以寫入資料,就會產生前兩天提到的時序問題。(No consistency -- A和P)
Keep Consistency: 為了避免之前提到的不一致問題,因此必須停掉其中任一個節點 (No availability -- C和P)
In-Memory data是想把硬碟當做是磁帶的角色,把資料都放在DRAM (or Flash, 現在暫時先不考慮這個) 裡。單機的DRAM空間有限,所以要搭配一些技巧,像是:資料壓縮、分散式系統等等。
另外一個問題是資料保存的問題。DRAM是Volatile的,也就是機器斷電後資料就不見了,要怎麼讓資料在斷電後不會不見呢?有兩個選項:
(1) persistence: 在硬碟寫change log
(2) replication: 在其他機器建立副本
Day 11: Zookeeper
ZK有幾個常見的用法:
共享Metadata
監控成員節點的狀況 & 維護叢集的成員名單
協助選出叢集中的leader(master)
ZK的資料是以樹狀方式組織,樹的節點叫做znode,可以在znode裡放資料。
由於znode裡的資料是許多成員都關心的,所以ZK有一個notification機制,可以在znode裡的資料更新時通知有事先對該znode註冊watcher的process。
有一種znode叫做ephemeral node,用來監控成員的狀況。這個znode跟建立znode的成員的session狀況是連動的,若session一段時間沒有回報(heartbeat),這個znode節點就會被刪除。因此若有其他成員在此znode上設定watcher,就會在此節點掛掉(即session掛掉時)收到通知。
所有成員都會對master對應的ephemeral node註冊watcher,所以在master失效後,會有成員偵測到而啟動leader election。
Zookeeper能保證global order,因為只有leader能處理寫入要求。Zookeeper在partition發生時仍能維持服務,因為採用了Quorum。所以Zookeeper基本上是偏向CA的分散式系統。
所謂Quorum是指成員數達到最低投票門檻的成員集合。Zookeeper成員有兩者角色,Leader或Follower,一個Quroum裡最多只能有一個Leader,其他都是支持此Leader的Followers。Leader Election的目的就是要選出Quorum中的Leader。
一個Quorum的成員數達到最低投票門檻,一般來說,是指成員數要大於Zookeeper節點的一半數量。比方說總共開了5個Zookeeper節點,Quorum裡最少要有三個成員(3>2.5)。這樣保證了,當叢集被partition成兩半,其中一個partition的節點數是不足以形成Quorum的。若不足以形成Quorum,就不允許對外服務。因此叢集中最多只有一個Quorum可以對外服務,就不會發生inconsistency的狀況。
Day 13: Apache Kafka
Apache Kafka 是一個 Distributed Queue 的實現,很多 Stream Computing 平台都支援 Kafka 作為 data source。
分散式架構,所以天生就是容易擴充的。
基於磁碟空間,且避免隨機存取。
因為儲存空間大,因此Queue裡的資料就算已消耗,也可以不用刪掉。好處包括:其他新加入的consumer可以處理到過去的資料(重要特色)。如果有batch-oriented的consumer (如:Hadoop),可以一次拉取足夠大量的資料,以利batch的處理效率。
對資料的包裝是輕量級的,且可壓縮。避免掉不必要的物件包覆,可以直接以檔案的型式來處理資料。
因為可以直接處理檔案資料,直接用OS的page cache,不需要額外Applicaion Cache來競爭珍貴的記憶體空間。
基本上Kafka是一個broker的角色,仲介producer與consumer。Kafka一般是由多個節點所構成的cluster。
Kafka有自己的producer API和consumer API,produce/consumer client 必須要使用或依照API spec自行實作存取的方式。
一組資料流稱為一個Topic,為避免一個Topic的資料量過大,所以一個Topic可以分成好幾個Partition,每個Partition會在不同的節點上(如果可以的話)。
Producer必須要自己決定要將資料送到哪個partition,在producer API裡有一個參數可以讓使用者指定partition key,然後producer API用hash方式決定partition。
Kafka可以彈性的支援point-to-point和pub/sub兩種Queue mode。主要是透過一個Consumer Group的抽象,每個Consumer Group當做是一個虛擬consumer,但可以由多個實體的consumer組成。一組Point-to-point就是將所有consumer都劃成同一個Consumer Group;而Pub/Sub是將不同Pub的Sub分成不同的Consumer Group
一個重點是,每一個Consumer只會同時bind一個partition,也就是說,一個Consumer只會找一個partition來拉資料。
這帶來一些很重要的暗示,也是Kafka的限制所在,這些限制就下次再講吧。
Consumer Group裡的consumer數量 不能小於 partition 數量。不然就會有partition裡的資料對不到consumer。
若各個consumer消耗資料速度不均,Partition的消耗速度會失衡。也就是有的partition已經消耗到最近的資料,但有的partition還在消耗之前的資料。
搭配上之前所說:「Producer必須要自己決定要將資料送到哪個partition」,所以失衡的狀況無法透過Producer改善,又:「每一個Consumer只會同時bind一個partition」,所以,失衡的狀況無法藉由produer/consumer的round-robin來解決(*)。
基於以上,每個partition實際上可以看成一個獨立的Queue。也就是說,雖然有partition,但沒有所謂跨partition的total order,也就是只能保證各個partition自己的local order。
也就是說,若有一個AP會處理跨partition的資料,AP不能假設會依producer產生的時序取得資料,而只能假設從每個partition裡取得的資料是有按時序的 (Kafka有保證,若Producer先送到Partition的資料,在Partition裡也會排前面)。這就是在Day 3所講到,partition帶來的tradeoff。因此,若有total order需求的AP並不適合用Kafka。
簡單來說,Kafka假設,AP是不需要total order的;抑或是AP只需要by-partition的local order,只要適當的做好partition,那麼就可以維持好時序的資料消耗。
Kafka實際上也倚賴Zookeeper來儲存Partition的metadata
(*) (Update 10/16): Kafka有rebalance功能,若在Consumer group中新增Consumer,會觸動rebalance, 重新分配partition與consumer之間的對應關係。這樣有機會可以解決資料量失衡的問題。
Kafka的replication是以partition做單位,方法也很簡單,就是讓replica去訂閱要追蹤的partition。因為這是Queue,所以直接用訂閱的機制就可以處理掉replication。
在每個replica set裡,只會有一個master,這個master負責所有的讀寫工作,其他的slave都只是作備援,所以不會有Day 7講到的不一致問題。
每個replica set會維持一個ISR (In-Sync Replicas)名單,名單內的replica是與master較為同步。若master掛掉,會從這些ISR中多數決挑選出新的master。這個ISR的名單是會變動的。
在寫入時雖然是以master作為窗口,但預設要等到master的資料同步到所有的ISR,該筆資料才算committed,也才能被consumer所看到。
stream computing的ack還要解決多階段、數量大的ack管理,而Kafka的ack只要確保message deliver semantics。
分散式系統因為有透過網路,所以message deliver都是很難保證的。就像網路,有時候可以允許遺失封包 (UDP),如果不能遺失封包(TCP),就要有重送和檢查重複的機制。
對於Kafka的consumer來說,何時回送ack,就決定了message deliver semantics。
如果在資料收到、但還沒處理前就先送ack,由於機器可能在處理前掛掉,所以不能保證資料一定被處掉到,所以是at-most once semantics。
如果在資料收到且處理完後才送ack,由於機器可能在處理後、且送ack前掛掉,這樣就會重送已處理過的資料,所以是at-least once semantics。
而Apache Kafka現在還沒有內建支援exactly-once semantics。
至於為什麼 Kafka 適合搭配 Stream Computing呢? 因為 Stream Computing 本質上也是一種可平行處理、易擴充的分散式處理架構,所以也要搭配同樣可平行讀寫、易擴充的data source/data sink才能發揮最大的效能。且Stream Computing的處理過程要求low latency,這是類似於Queue的需求,而非Log aggregation Tool (如: Flume)的需求。
Kafka目前是實現Lambda architecture的要角。因為只有Kafka能同時滿足real-time processing與batch processing對於data source的需求。
對於 Stream Computing 來說,Kafka 可以不只作為 data source/data sink,也可以作為state commit log的sync工具。
Day 20: In-Memory 的技術議題?
In-Memory Computing號稱把Memory 當做Disk,而 Disk當做磁帶,可以省去將資料從 memory持久化到disk 的過程。除非是要 recovery,也無須從disk 讀取資料。因為 disk和memory 的速度是多個數量級的差距,不碰 disk自然有加速效果,但同時也會受限於 Memory大小,必須思考解決之道。
所以 In-Memory computing solution多半會強調資料壓縮能力,能把更多資料存進 Memory。有的solution 還強調他們能更有效運用 CPU,如:降低cache miss 、減少 lock/latch contention等,因為bottleneck 已經不再在 I/O了,所以需要讓CPU能更高效運作。
Day 21: 分散式運算系統
不過Hadoop是設計來處理high throughput的批次應用,相對來說不重視 latency。如果是要處理low latency應用的話就不適合用Hadoop了。
Hadoop是典型的Data parallelism,也就是將資料切成小塊,每一塊平行處理來增加處理時效。當然,這樣的資料平行化精神,你也可以自己將資料灑在多機上,在多機透過multi-thread / multi-process來達成,如果真的還不能達到 latency 要求的話,就要考慮再加上pipeline處理。
用上pipeline的話,要把整個運算過程拆成好幾個步驟,讓上一步驟的單筆資料的產出儘速傳送到下一步驟處理。這就像水在流動一樣,資料循著pipeline往下流。
而Stream Computing結合了Data parallelism與Pipeline,所以更加的複雜。
Day 22: 分散式運算系統的溝通方式
Shared memory: 當做白板來交換資料,缺點是很多人用的話要排隊(lock),效率不好。所以現在也演進出一些比較高效的共享方式,像是樂觀鎖、多版本控制等,但這些都有額外的overhead
Message passing: 所有process間都透過訊息的方式來交換資料,缺點就是Day 7講的,會缺乏global order。
在分散式運算系統也是一樣,如果一個運算的結果需要跟其他節點共享的話,那也需要透過每些溝通方式來達成。基本的思路也是上面這兩種。
Shared data store: 找一個大家都能access到的data store來存資料,這個data store可能是某種分散式資料系統。
Peer Communication: 透過某些高效的通訊協定在各節點間交換訊息,通常是Non-blocking的通訊方式,而且還要用高效能的序列化框架。
Day 24: Stream Computing特性
Stream Computing 是設計給需要 low-latency 的應用。batch processing 因為整批進整批出,有些已處理好的資料也需要等待其他同批資料都處理完才能一次送出,這樣會導致一些不必要的 latency。為了要減少 latency,Stream Computing 將處理顆粒度變小到 record,且將處理過程切分成好幾個階段。透過 pipeline 的方式,只要前一個階段處理完的 record,就可以馬上進入下一個階段,這樣可以避免掉不必要的 latency。
但因為這種處理方式會增加資料傳遞量,因此 throughput 會比 batch processing 還低。為了解決這樣的問題,Stream Computing 框架都會內建Scalability。每一個階段的處理程式都是可擴充的,也就是可以第一階段用10個thread、第二階段用5個thread之類的。這種用 efficiency 換 scalability ,再用 scalability 彌補 efficiecy 的方式,在分散式系統裡相當常見。
如果是純運算的應用,沒有很多的reference data 或 其他的side effect的話,Stream Computing 有很好的 scalability。但有許多的應用並不是如此,也因此限制了Stream Computing的應用範圍。目前Stream Computing最常被用來算即時的統計 (包含了window count, 如近五分鐘的統計),因為這些統計數字可以單純從input data中算出,且計算結果有對分散式系統友善的單調漸增(monotonic)特性。
如果是其他的應用,牽涉到其他更複雜的參照資料或運算時,就需要再搭配partition或replication等分散式資料系統的處理方式。
Day 25: 選擇Stream Computing框架
Apache Storm
Apache Samza
Apache Spark Streaming
如果希望有sub-second level latency,請選1
如果不想踩太多雷,請選1
如果處理過程要儲存很多狀態,請選2
如果想要深入研究Stream Computing,請選2
如果已經在用Spark,請選3
如果希望programmer-friendly,請選3
Day 26: Stream Computing 框架的組成角色
1. 處理 client 提出的運算要求,將運算工作拆分成小單位(任務)後,將運算工作分派到各個運算節點上
2. 管理運算節點,每台機器需要一個或多個這種角色
3. 運算節點,實際執行運算,並將運算結果透過高效率的方式送交到下一階段的運算節點或中繼站
4. 資料管道,擔任運算節點之間的中繼站,或是輸入資料的中繼站。若是consumer速度慢於producer速度時負責buffer
5. 叢集協調中心,負責協調及交換整體叢集的狀態。
其中 4 和 5 已經介紹過了,一般常用的是 Kafka 和 Zookeeper。
1~3的話,每一種框架有不同的實作方式。
Day 27: 如何追蹤每一個record的處理進度
在Stream Computing,一筆 record 可能會需要同時進行好幾種運算 (如: 更新各種counter, 計算統計值等等)。我們可以把一筆 record 從源頭到完成所有計算看做是一個 有向無循環圖 (Directed Acyclic Graph, DAG) 。
另外,一筆 record 所有運算可能分散在多個點節上處理,不見得每一個 record 只會在一個節點上處理。
接下來我以Storm為例,說明如何在DAG裡追蹤每一個record的處理進度。
每一筆 record 在最源頭會被指派一個 message ID,在每次處理完產生新資料的後續傳送中,都會帶這個ID,以分辨資料的源頭。有可能一筆資料有多個源頭 (如: 經過join之後)。這個 ID 會被用來追蹤,與該 record 相關的所有運算的完成狀況。
在每個階段處理完一筆input data,產生output data往下游送時,會向一個特別的角色(Ackor)發出 ack 或 fail 的回報,並帶有input data與output data的64 bit ID。在正常處理的狀況下,ackor會收到兩次同一個id (一次是產生該資料、一次是該資料處理完),表示該筆資料已經被處理完。由於資料量很多(每個record可以衍生出許多筆資料),所以不可能為每筆資料都維護一個counter。ackor採用的方式是為每一個record維護一個初始值為0的64 bit的value,每次收到一個id回報,就將value <- value XOR id。如果每個id都出現兩次,那麼value又會回到0,就表示該record相關的處理都完成了。
Day 28: 錯誤處理機制
Storm用Ackor將所有收到的ID XOR之後,來偵測一筆record是否已完全被處理。
如果遇到問題的話會怎麼處理。
其中一個常見的問題是:運算節點死掉了。所以Ackor收不到某些data id。這種狀況是用一個 timeout機制來解決,如果一段時間內沒收到該資料的第二個id回傳,就直接宣判該筆record處理失敗,要求資料來源(e.g. Kafka)啟動重傳機制。也因為這樣,Storm不能保證exactly-once semantics (ref. day 17)。可能有些資料處理到一半後才重傳,那前半段就會被處理兩次。如同 day 24 所說,這是pure stream computing的特性,會限制 stream computing 的應用範圍。
其中一個常見的問題是:運算節點死掉了。所以Ackor收不到某些data id。這種狀況是用一個 timeout機制來解決,如果一段時間內沒收到該資料的第二個id回傳,就直接宣判該筆record處理失敗,要求資料來源(e.g. Kafka)啟動重傳機制。也因為這樣,Storm不能保證exactly-once semantics (ref. day 17)。可能有些資料處理到一半後才重傳,那前半段就會被處理兩次。如同 day 24 所說,這是pure stream computing的特性,會限制 stream computing 的應用範圍。
那Ackor死掉要怎麼辦?前面沒講到的是,資料來源也會設timeout,如果Ackor掛了而無法向資料來源發出message的ack,message(record)也會被重送。當然這也是會有不能保證exactly-once semantics的狀況。
那如果資料來源死掉呢?那就真的死掉了。所以像Kafka會需要用replication維持強大的availability,且需要發展stateless的consumer,以便於在錯誤後重啟亦能輕鬆回覆運作。
Day 29: 從Stream到Micro batch
Micro batch 也是集結一段時間的資料再批次處理,只是集結的時間很短,通常是幾秒就集結一次,所以稱為Micro batch。
Micro batch 的好處是可以實現 exactly-once semantics。而 exactly-once semantics 主要牽涉到 state 的更新,我明天會提到這個問題。但micro batch 的壞處在於latency變高了,但如果應用對於latency沒那麼要求 (可容忍秒級的延遲),用Micro batch其實很OK。
Storm有一個延伸框架 Trident,在Storm上多架一層Coordination layer來實現Micro batch。但有點討厭的是,有些 Storm 有的功能 (如: window count),在 Trident 裡還不支援;而且 Trident 和 Storm 的 運算結果是不相通的 (不能混用)。
而 Spark Streaming 本身就是 Micro Batch,因為這是把 Spark 的批次維度縮小後的實作。
Day 30: Stream States & Finale
好了,exactly-once semantics問題解決了,但狀態帶來的另外一個問題是效率問題。雖然Stream Computing有效的分散運算,可是所有狀態更新都集中在同一個地方,還是會變成處理瓶頸。這就是我在前半部談到的分散式資料系統要解決的問題。不過,若運算系統和資料系統是獨立運作的,更新時的network latency會對某些要求低延遲的應用造成傷害。在這方面,Samza有個聰明的解決方法。大家可以去看看。
http://www.w3resource.com/mongodb/nosql.php在Stream Computing,一筆 record 可能會需要同時進行好幾種運算 (如: 更新各種counter, 計算統計值等等)。我們可以把一筆 record 從源頭到完成所有計算看做是一個 有向無循環圖 (Directed Acyclic Graph, DAG) 。
另外,一筆 record 所有運算可能分散在多個點節上處理,不見得每一個 record 只會在一個節點上處理。
接下來我以Storm為例,說明如何在DAG裡追蹤每一個record的處理進度。
每一筆 record 在最源頭會被指派一個 message ID,在每次處理完產生新資料的後續傳送中,都會帶這個ID,以分辨資料的源頭。有可能一筆資料有多個源頭 (如: 經過join之後)。這個 ID 會被用來追蹤,與該 record 相關的所有運算的完成狀況。
在每個階段處理完一筆input data,產生output data往下游送時,會向一個特別的角色(Ackor)發出 ack 或 fail 的回報,並帶有input data與output data的64 bit ID。在正常處理的狀況下,ackor會收到兩次同一個id (一次是產生該資料、一次是該資料處理完),表示該筆資料已經被處理完。由於資料量很多(每個record可以衍生出許多筆資料),所以不可能為每筆資料都維護一個counter。ackor採用的方式是為每一個record維護一個初始值為0的64 bit的value,每次收到一個id回報,就將value <- value XOR id。如果每個id都出現兩次,那麼value又會回到0,就表示該record相關的處理都完成了。
Day 28: 錯誤處理機制
Storm用Ackor將所有收到的ID XOR之後,來偵測一筆record是否已完全被處理。
如果遇到問題的話會怎麼處理。
其中一個常見的問題是:運算節點死掉了。所以Ackor收不到某些data id。這種狀況是用一個 timeout機制來解決,如果一段時間內沒收到該資料的第二個id回傳,就直接宣判該筆record處理失敗,要求資料來源(e.g. Kafka)啟動重傳機制。也因為這樣,Storm不能保證exactly-once semantics (ref. day 17)。可能有些資料處理到一半後才重傳,那前半段就會被處理兩次。如同 day 24 所說,這是pure stream computing的特性,會限制 stream computing 的應用範圍。
其中一個常見的問題是:運算節點死掉了。所以Ackor收不到某些data id。這種狀況是用一個 timeout機制來解決,如果一段時間內沒收到該資料的第二個id回傳,就直接宣判該筆record處理失敗,要求資料來源(e.g. Kafka)啟動重傳機制。也因為這樣,Storm不能保證exactly-once semantics (ref. day 17)。可能有些資料處理到一半後才重傳,那前半段就會被處理兩次。如同 day 24 所說,這是pure stream computing的特性,會限制 stream computing 的應用範圍。
那Ackor死掉要怎麼辦?前面沒講到的是,資料來源也會設timeout,如果Ackor掛了而無法向資料來源發出message的ack,message(record)也會被重送。當然這也是會有不能保證exactly-once semantics的狀況。
那如果資料來源死掉呢?那就真的死掉了。所以像Kafka會需要用replication維持強大的availability,且需要發展stateless的consumer,以便於在錯誤後重啟亦能輕鬆回覆運作。
Day 29: 從Stream到Micro batch
Micro batch 也是集結一段時間的資料再批次處理,只是集結的時間很短,通常是幾秒就集結一次,所以稱為Micro batch。
Micro batch 的好處是可以實現 exactly-once semantics。而 exactly-once semantics 主要牽涉到 state 的更新,我明天會提到這個問題。但micro batch 的壞處在於latency變高了,但如果應用對於latency沒那麼要求 (可容忍秒級的延遲),用Micro batch其實很OK。
Storm有一個延伸框架 Trident,在Storm上多架一層Coordination layer來實現Micro batch。但有點討厭的是,有些 Storm 有的功能 (如: window count),在 Trident 裡還不支援;而且 Trident 和 Storm 的 運算結果是不相通的 (不能混用)。
而 Spark Streaming 本身就是 Micro Batch,因為這是把 Spark 的批次維度縮小後的實作。
Day 30: Stream States & Finale
好了,exactly-once semantics問題解決了,但狀態帶來的另外一個問題是效率問題。雖然Stream Computing有效的分散運算,可是所有狀態更新都集中在同一個地方,還是會變成處理瓶頸。這就是我在前半部談到的分散式資料系統要解決的問題。不過,若運算系統和資料系統是獨立運作的,更新時的network latency會對某些要求低延遲的應用造成傷害。在這方面,Samza有個聰明的解決方法。大家可以去看看。